Tesseract-ocr 安装与使用
Tesseract(识别引擎),一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
Tesseract-ocr安装很容易,在网上找到下载地址直接下载安装就可以,安装过程中需要 注意的是语言模块(根据自己的需要选择需要安装的语言包,建议安装中文简体和中文繁体),注意记住自己安装的路径
安装完成之后需要配置环境变量,配置完环境变量之后可以在cmd命令行中输入tesseract验证Tesseract-ocr能否使用。
除了需要配置Tesseract-ocr文件的环境变量外,还需要配置Tesseract-ocr文件下的tessdata(语言包)的环境变量。
像下面这样就代表安装成功,并可以使用了。

将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入
tesseract test.png output_1 –l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng(英语)。
原有图片

运行效果如下:

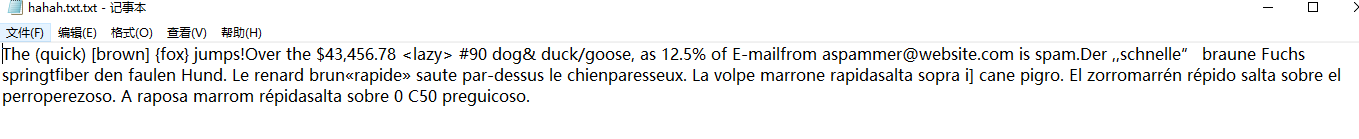
接下来是在python环境中使用Tesseract-ocr
需要安装PIL包和Pillow包以及pytesseract模块
安装完pytesseract模块后,找到该模块,在pytesseract.py文件中修改以下字段为你的Tesseract-OCR文件下的tesseract.exe可执行文件。
tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
错误:pytesseract.pytesseract.TesseractError: (1, 'Error opening data file \\Program Files\\Tesseract-OCR\\tessdata/eng.traineddata')
在py文件中指定tessdata_dir
testdata_dir_config = '--tessdata-dir "C:\\Program Files (x86)\\Tesseract-OCR\\tessdata"'
textCode = pytesseract.image_to_string(img, config=testdata_dir_config)
问题解决
出现这个报错
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
修改pytesseract.py文件里的tesseract_cmd
tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
问题解决
Tesseract-ocr 安装与使用的更多相关文章
- Tesseract OCR 安装尝试
1.简介 Tesseract是一个图像识别项目,将图中的文字识别出来.将一个.jpg .png 等等 的图片作为输入,.txt作为识别内容输出 Tesseract项目GitHub地址 2.安装 你可以 ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- [PyImageSearch] Ubuntu16.04下针对OCR安装Tesseract
今天的博文是安装和使用光学字符识别(OCR)的Tesseract库的两部分系列的第一部分. 本系列的第一部分将着重于在您的机器上安装和配置Tesseract,然后使用tesseract命令将OCR应用 ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- selenium使用笔记(二)——Tesseract OCR
在自动化测试过程中我们经常会遇到需要输入验证码的情况,而现在一般以图片验证码居多.通常我们处理这种情况应该用最简单的方式,让开发给个万能验证码或者直接将验证码这个环节跳过.之前在技术交流群里也跟朋友讨 ...
- alfresco install in linux, and integrated with tesseract ocr
本文描述在Linux系统上安装Alfresco的步骤: 1. 下载安装文件:alfresco-community-5.0.d-installer-linux-x64.bin 2. 增加执行权限并执行: ...
随机推荐
- form表单中多个button按钮必须声明type类型
最近在做一个后台管理系统,发现了一个小bug: 问题描述:form表单中有多个button按钮(以下图为例),如果第一个button不写type属性,那么点击第一个button按钮会触发submit事 ...
- 如何解决angular不自动生成spec.ts文件
"schematics":{ "@schematics/angular:component": { "styleext": ...
- H5的语义化标签(PS: 后续继续补充)
头部信息 <header></header> 区块标签 <figure> <figcaption>123</figcaption> < ...
- 轨迹系列5——验证轨迹GPS坐标转换为本地坐标的四/七参数是否准确的一种方案
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 目前对多个项目轨迹不准确的情况做了排查,发现导致轨迹偏移百分 ...
- .NET性能优化小技巧
.NET 性能优化小技巧 Intro 之前做了短信发送速度的提升,在大师的指导下,发送短信的速度有了极大的提升,学到了一些提升 .NET 性能的一些小技巧 HttpClient 优化 关于使用 Htt ...
- gitbook 入门教程之导出电子书
gitbook 既可以将源码文件单独输出,也可以仅输出单个文件,常见的导出电子书格式主要有三种(ePub, Mobi, PDF),而这三种格式都依赖于系统本身提供的 ebook-convert 工具. ...
- sql server 错误日志errorlog
一 .概述 SQL Server 将某些系统事件和用户定义事件记录到 SQL Server 错误日志和 Microsoft Windows 应用程序日志中. 这两种日志都会自动给所有记录事件加上时间戳 ...
- Checkpoint 和Breakpoint
参考:http://www.cnblogs.com/qiangshu/p/5241699.htmlhttp://www.cnblogs.com/biwork/p/3366724.html 1. Che ...
- cpu iowait高排查的case
在之前的常见的Java问题排查方法一文中,没有写cpu iowait时的排查方法,主要的原因是自己之前也没碰到过什么cpu iowait高的case,很不幸的是在最近一周连续碰到了两起cpu iowa ...
- STM32 FSMC使用笔记
最近在使用STM32的FSMC与FPGA做并行通信总线控制,做一下总结 1,利用FSMC读取写入16位数据时的封装函数如下,不这样使用的话在与FPGA进行通信的过程中可能会出现不可预知的错误. #de ...