Lucene的中文分词器
1 什么是中文分词器
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。
而中文的语义比较特殊,很难像英文那样,一个汉字一个汉字来划分。
所以需要一个能自动识别中文语义的分词器。
2. Lucene自带的中文分词器
StandardAnalyzer
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足对中文的需求。
3. 使用中文分词器IKAnalyzer
IKAnalyzer继承Lucene的Analyzer抽象类,使用IKAnalyzer和Lucene自带的分析器方法一样,将Analyzer测试代码改为IKAnalyzer测试中文分词效果。
如果使用中文分词器ik-analyzer,就在索引和搜索程序中使用一致的分词器ik-analyzer。
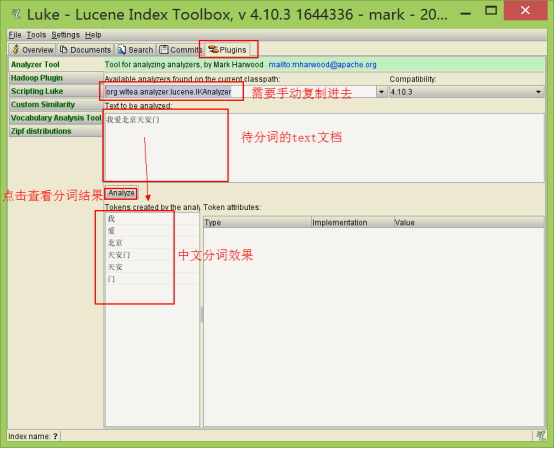
1. 使用luke测试IK中文分词
(1)打开Luke,不要指定Lucene目录。否则看不到效果
(2)在分词器栏,手动输入IkAnalyzer的全路径org.wltea.analyzer.lucene.IKAnalyzer
2. 改造代码,使用IkAnalyzer做分词器
添加jar包
修改分词器代码
|
// 创建中文分词器 Analyzer analyzer = new IKAnalyzer(); |
扩展中文词库
拓展词库的作用:在分词的过程中,保留定义的这些词
①在src或其他source目录下建立自己的拓展词库,mydict.dic文件,里面写入自定义的词
②在src或其他source目录下建立自己的停用词库,ext_stopword.dic文件停用词的作用:在分词的过程中,分词器会忽略这些词。
③在src或其他source目录下建立IKAnalyzer.cfg.xml,内容如下(注意路径对应):
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!-- 用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">mydict.dic</entry> <!-- 用户可以在这里配置自己的扩展停用词字典 --> <entry key="ext_stopwords">ext_stopword.dic</entry> </properties> |
如果想配置扩展词和停用词,就创建扩展词的文件和停用词的文件,文件的编码要是utf-8。
注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。
Lucene的中文分词器的更多相关文章
- Lucene的中文分词器IKAnalyzer
分词器对英文的支持是非常好的. 一般分词经过的流程: 1)切分关键词 2)去除停用词 3)把英文单词转为小写 但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好. 国人林良益写的IK Ana ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
- Lucene 03 - 什么是分词器 + 使用IK中文分词器
目录 1 分词器概述 1.1 分词器简介 1.2 分词器的使用 1.3 中文分词器 1.3.1 中文分词器简介 1.3.2 Lucene提供的中文分词器 1.3.3 第三方中文分词器 2 IK分词器的 ...
- (五)Lucene——中文分词器
1. 什么是中文分词器 对于英文,是安装空格.标点符号进行分词 对于中文,应该安装具体的词来分,中文分词就是将词,切分成一个个有意义的词. 比如:“我的中国人”,分词:我.的.中国.中国人.国人. 2 ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- Lucene索引库维护、搜索、中文分词器
删除索引(文档) 需求 某些图书不再出版销售了,我们需要从索引库中移除该图书. 1 @Test 2 public void deleteIndex() throws Exception { 3 // ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
随机推荐
- 【MySQL大系】《Mysql集群架构》
原文地址(微信):[技术文章]<Mysql集群架构> 本文地址:http://www.cnblogs.com/aiweixiao/p/7258444.html 点击关注微信公众号 1.主要 ...
- HTML基础-------最初概念以及相关语法
HTML概念以及相关语法 HTML HTML是一种类似于(c,java,c++)之类的语言,他是用来描述网页的一种语言.通过各种标签所代表的语义来构建出一个网页,再通过浏览器的渲染功能来实现该网页的各 ...
- sql优化个人总结(全)
sql优化总结--博客 第一次自己写博客,以后要坚持每掌握一个技能点,就要写一篇博客出来,做一个不满足于一个只会写if...else的程序员. 最近三个月入职了一家新的公司,做的是CRM系统,将公司多 ...
- 网络流之最小费用最大流 P1251 餐巾计划问题
题目描述 一个餐厅在相继的 NN 天里,每天需用的餐巾数不尽相同.假设第 ii 天需要 r_iri块餐巾( i=1,2,...,N).餐厅可以购买新的餐巾,每块餐巾的费用为 pp 分;或者把旧餐巾送 ...
- UOJ 275. 【清华集训2016】组合数问题
UOJ 275. [清华集训2016]组合数问题 组合数 $C_n^m $表示的是从 \(n\) 个物品中选出 \(m\) 个物品的方案数.举个例子,从$ (1,2,3)(1,2,3)$ 三个物品中选 ...
- vue笔记未整理
全局组件 局部组件 子组件传值到父组件 父子组件传值 watch跟计算属性差不多,都会有缓存,计算属性优先 计算属性get set 对象 数组 对象 数组 不复用 改变数组 直接修改数组,页面没变化 ...
- SpringCloud-Gateway
在微服务架构中,我们会遇到这样的问题:1.在调用微服务时,需要鉴权,微服务不能任意给外部调用.但是,多个微服务如果都需要同一套鉴权规则,明显会产生冗余,如果鉴权方法需要修改,则需要改动多个地方.2.在 ...
- CentOS7 安装配置 MySQL 5.7
1. 下载 yum 源文件 mysql80-community-release-el7-2.noarch.rpm https://dev.mysql.com/downloads/repo/yum/ 2 ...
- python全局解释器GIL
1.什么是进程: 进程是竞争计算机资源的基本单位.对于单核CPU来讲,同一时间只能有一个进程在运行,所以当我们开启多个应用时,操作系统需要根据进程调度算法去在不同的应用程序之间切换,而不同的进程之间切 ...
- 2019-04-29 EasyWeb下配置Atomikos+SQLServer分布式数据源
初次尝试: 配置Mysql时候使用的是Atomikos+DruidXADataSource,所以觉得配置SQLServer应该也是仅仅配置配置就够了,于是引入JDBC驱动依赖后,配置了文件 sprin ...