Lucene的中文分词器
1 什么是中文分词器
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。
而中文的语义比较特殊,很难像英文那样,一个汉字一个汉字来划分。
所以需要一个能自动识别中文语义的分词器。
2. Lucene自带的中文分词器
StandardAnalyzer
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足对中文的需求。
3. 使用中文分词器IKAnalyzer
IKAnalyzer继承Lucene的Analyzer抽象类,使用IKAnalyzer和Lucene自带的分析器方法一样,将Analyzer测试代码改为IKAnalyzer测试中文分词效果。
如果使用中文分词器ik-analyzer,就在索引和搜索程序中使用一致的分词器ik-analyzer。
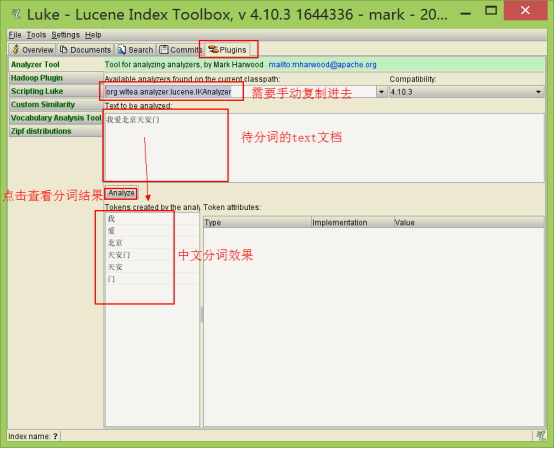
1. 使用luke测试IK中文分词
(1)打开Luke,不要指定Lucene目录。否则看不到效果
(2)在分词器栏,手动输入IkAnalyzer的全路径org.wltea.analyzer.lucene.IKAnalyzer
2. 改造代码,使用IkAnalyzer做分词器
添加jar包
修改分词器代码
|
// 创建中文分词器 Analyzer analyzer = new IKAnalyzer(); |
扩展中文词库
拓展词库的作用:在分词的过程中,保留定义的这些词
①在src或其他source目录下建立自己的拓展词库,mydict.dic文件,里面写入自定义的词
②在src或其他source目录下建立自己的停用词库,ext_stopword.dic文件停用词的作用:在分词的过程中,分词器会忽略这些词。
③在src或其他source目录下建立IKAnalyzer.cfg.xml,内容如下(注意路径对应):
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!-- 用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">mydict.dic</entry> <!-- 用户可以在这里配置自己的扩展停用词字典 --> <entry key="ext_stopwords">ext_stopword.dic</entry> </properties> |
如果想配置扩展词和停用词,就创建扩展词的文件和停用词的文件,文件的编码要是utf-8。
注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。
Lucene的中文分词器的更多相关文章
- Lucene的中文分词器IKAnalyzer
分词器对英文的支持是非常好的. 一般分词经过的流程: 1)切分关键词 2)去除停用词 3)把英文单词转为小写 但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好. 国人林良益写的IK Ana ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
- Lucene 03 - 什么是分词器 + 使用IK中文分词器
目录 1 分词器概述 1.1 分词器简介 1.2 分词器的使用 1.3 中文分词器 1.3.1 中文分词器简介 1.3.2 Lucene提供的中文分词器 1.3.3 第三方中文分词器 2 IK分词器的 ...
- (五)Lucene——中文分词器
1. 什么是中文分词器 对于英文,是安装空格.标点符号进行分词 对于中文,应该安装具体的词来分,中文分词就是将词,切分成一个个有意义的词. 比如:“我的中国人”,分词:我.的.中国.中国人.国人. 2 ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- Lucene索引库维护、搜索、中文分词器
删除索引(文档) 需求 某些图书不再出版销售了,我们需要从索引库中移除该图书. 1 @Test 2 public void deleteIndex() throws Exception { 3 // ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
随机推荐
- Pycharm安装并配置jupyter notebook
Pycharm安装并配置jupyter notebook Pycharm安装并配置jupyter notebook 一: 安装命令jupyter: pip install jupyter 如果缺少依赖 ...
- codeforces 1064套题
a题:题意就是问,3个数字差多少可以构成三角形 思路:两边之和大于第三遍 #include<iostream> #include<algorithm> using namesp ...
- 你不需要 jQuery,但你需要一个 DOM 库
写这篇文章的目的,一方面是介绍一下自己编写的模块化 DOM 库 domq.js,另一方面是希望大家对 jQuery 有一个正确的认识,即使 jQuery 已经逐渐退出历史舞台,但是它的 API 将会以 ...
- 关于 Angular 跨域请求携带 Cookie 的问题
在前端开发调试接口的时候都会遇到跨域请求的问题.传统的方式是使用 Nginx 反向代理解决跨域.比如所有接口都在 a.com 的域下,通过 Nginx 将所有请求代理到 a.com 的域下即可. 使用 ...
- Selenium WebDriver原理(一):Selenium WebDriver 是怎么工作的?
首先我们来看一个经典的例子: 搭出租车 在出租车驾驶中,通常有3个角色: 乘客 : 他告诉出租车司机他想去哪里以及如何到达那里 对出租车司机说: 1.去阳光棕榈园东门 2.从这里转左 3.然后直行 2 ...
- Node.js中的console.log()输出彩色字体
转自:https://www.jianshu.com/p/cca3e72c3ba7 console.log('\033[42;30m DONE \033[40;32m Compiled success ...
- JSON获取地址
JSON获取地址一: https://github.com/stleary/JSON-java JSON获取地址二: http://genson.io/ JSON获取地址一: https://code ...
- 按PEP8风格自动排版Python代码
Autopep8是一个将Python代码自动排版为PEP8风格的小工具.它使用pep8工具来决定代码中的哪部分需要被排版.Autopep8可以修复大部分pep8工具中报告的排版问题. 安装步骤如下: ...
- Fetch API & Async Await
Fetch API & Async Await const fetchJSON = (url = ``) => { return fetch(url, { method: "G ...
- mapper.xml 的配置
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "- ...