多个PVSS数据点属性读写的优化处理
注:本译文出自15多年前,尚未用最新软硬件平台进行重新测试,只提供方法论层面的参考,具体性能指标不具备参考意义。
多个PVSS数据点属性读写的优化处理
本文档概述了测试三种读取和写入多个PVSS数据点属性方法速度的结果。原文:https://edms.cern.ch/ui/file/1076836/1/fwConfigsPerformanceAttributes.pdf
目标
这些测试的目的是找到读取和写入大量数据点属性的最快方法。
被测试的三种方法如下:
方法1
一次读取/写入数据点属性。这是通过多次调用dpSetWait 或dpGet 函数来实现的:
dpSetWait(string dp1,< type1 > var1);
dpGet(string dp1,< type1 >&var1);
方法2
一次读取/写入所有数据点属性。这是通过用属性和值的动态数组调用dpSetWait 或dpGet 来实现的。
dpSetWait(dyn_string dpnames,dyn_anytype values);
dpGet(dyn_string dpnames,dyn_anytype&values);
方法3
一次读取/写入所有数据点属性。这是通过调用dpSetWait 或dpGet 来实现的。这与方法2的不同之处在于它不使用动态数组。
dpSetWait(string dp1,<type1> var1,string dp2,<type2> var2,string dp3,<type3> var3,
...
string dpN,<typeN> varN);
dpGet(string dp1,<type1>&var1,string dp2,<type2>&var2,string dp3,<type3>&var3,
...
string dpN,<typeN>&varN);
方法2和3的优点在于,无论您希望编写/读取多少属性,dpSetWait 或dpGet 函数都只会调用一次。使用方法1时,函数会被调用多次,因为要设置属性。测试这些方法背后的动机是调查哪种方法提供了最快的结果。
预计通过只调用一次函数,读/写操作的开销就会减少,并且应该更快地执行。
测试程序
所描述的所有三种方法都用不同数量的属性进行测试。要写入/读取的属性数量为:
| 测试序号 | 属性的个数 |
| 1 | 1 |
| 2 | 10 |
| 3 | 100 |
| 4 | 500 |
| 5 | 1000 |
| 6 | 2000 |
| 7 | 3000 |
| 8 | 4000 |
| 9 | 5000 |
| 10 | 6000 |
| 11 | 7000 |
| 12 | 8000 |
| 13 | 9000 |
| 14 | 10000 |
重复测试以读取和写入两个不同的数据点属性。
第一个属性: _smooth .._ type
第二个属性: _original .._value
编写一个CTRL脚本来自动运行方法1和方法2的测试。这些测试的结果输出到文件进行分析。
方法3的测试无法轻易实现自动化,因为脚本总是为每个新数量的属性进行重新编码以进行读取/写入。避免使用evalScript(),因为使用这个函数可能改变获得的结果。
测试重复3次,结果取平均值以尽量减少发生的任何随机波动的影响。
由于第一个属性(_smooth .._ type )与数据点配置有关,决定在写入属性时测试两个不同的值。这两个值写成如下:
第一个值: DPCONFIG_SMOOTH_SIMPLE_MAIN
第二个值: DPCONFIG_NONE
这样做是为了查看发送一个创建配置的值与删除配置的值之间是否存在显着差异。
对于第二个属性(_original .._ value ),只写入了一个值。这是从rand()函数的值中生成的浮点值。
结果
_smooth .._type 属性
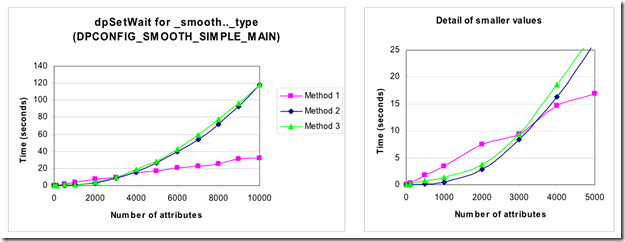
上图显示了通过设置DPCONFIG_SMOOTH_SIMPLE_MAIN 的_smooth .._ type 属性添加许多平滑配置的结果。
首先,注意到方法2和方法3之间的性能差别很小。
可以看出(特别是在右侧显示的较小值的细节中),只涉及dpSetWait 函数(方法2和3)的一次调用的方法对于少量属性更快。但是,对于大量的属性,方法1显着更快。
有人指出,方法1所用的时间随着要设置的属性数量线性增加。而方法2和方法3所花费的时间似乎随着属性数量增加到约2的幂(与≈N 2成比例)成比例地增加。方法1变得最快的点位于正在写入3000个属性的位置。
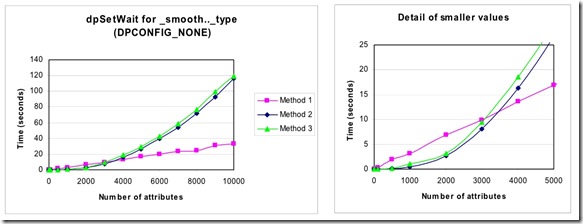
上面的图结果显示,用于通过设置DPCONFIG_NONE 去除许多平滑CONFIGS _smooth .._类型属性。
从这些测试中获得的结果与添加配置的结果非常相似(如前所述)。
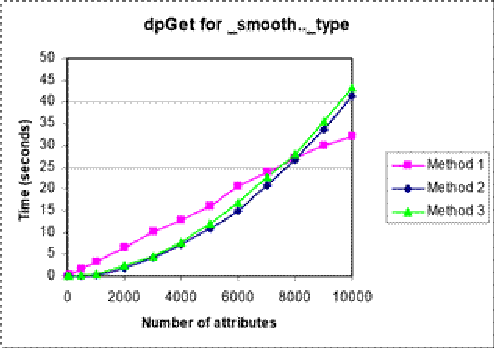
上图显示了读取_smooth .._ type 属性的结果。
对于方法1,读取属性所用的时间与写入属性所用的时间相似。方法2和3阅读属性比写作速度快得多。
与之前方法1相比,其他方法对于少量属性的速度要慢,但对于更多属性,它比其他方法稍快。这一次,方法1成为最快方法的地方大约有8000个属性。
再一次,很明显,方法1遵循线性增长模式,而方法2和3所需的时间与属性数量(N 2)的平方成比例地增加。从这种模式推断,可以预测,在属性数> 10000的情况下,方法2和3将再次变得比方法1慢得多。
_original .._value属性
由于测试这些方法需要大量时间,因此决定方法3不会使用_original .._ value 属性进行测试。从早期的结果中可以看出,它的性能与方法2非常相似。
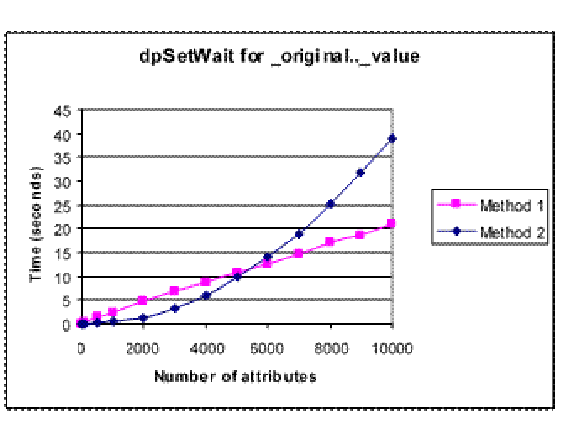
写入_original .._ value 属性的结果再次遵循_smooth .._ type 属性显示的趋势。写入原始.._值属性的时间比平滑配置属性更快。
方法1成为最快的方法的地方大约有5000个属性。
再次,方法2所花费的时间按比例增加到大约N 2,并且对于较大数量的属性而言变得比方法1慢得多。
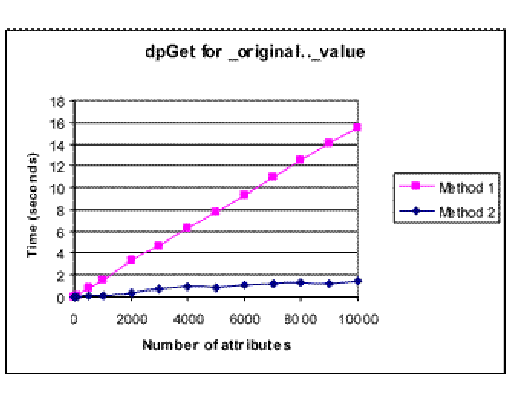
当从_original .._ value 属性获得值时,与其他测试不同,方法2在整个过程中速度最快。
该属性的值被缓存在事件管理器中,并且可以很快读回。从收集的数据中不清楚方法2所用的时间是否与N 2成比例地增加。无论哪种方式,从收集的数据来看,对于大于10000的属性,方法2似乎会比方法1快得多。目前>> 10000的情况还不清楚哪些方法的属性数量会更快。
注意:
测试运行的系统是运行Windows XP的1.4GHz Athlon和256MB RAM。被测试的PVSS版本是PVSS 3.0 RC 1。
测试在具有1GB RAM的2.4GHz Pentium 4机器上重复,再次运行Windows XP,但是这次使用PVSS 3.0 Beta。所得到的操作时间更快,方法2和方法3的性能优于方法1,但性能更高。但是,模式仍与原始测试结果相同(方法1 - 线性,方法2和3 - 多项式)。
结论
预计使用一个dpSetWait 或一个dpGet 函数调用来写入或读取多个属性会比逐个执行更快。
对于较小数量的属性,情况就是这样。方法2和3明显比方法1更快。
然而,由于方法2和方法3所花费的时间与属性数量的平方成正比地增加,在几乎所有情况下,这些方法比读取/写入10000个属性的方法1要慢。
对未来的疑问
是否有推荐的解决方案来读取或写入大量的属性?
为什么方法2和方法3需要多项式时间(在这种情况下与N 2成比例)?如果这些方法可以像目前少数属性一样快并显示方法1的线性行为,那么这将提供一个非常快速的解决方案。
多个PVSS数据点属性读写的优化处理的更多相关文章
- EF CodeFirst系列(4)--- 数据注释属性
EFCodeFirst模式使用的是约定大于配置的编程模式,这种模式利用默认约定根据我们的领域模型建立概念模型.然后我们也可以通过配置领域类来覆盖默认约定. 覆盖默认约定主要用两种手段: 1.数据注释属 ...
- 数据处理:2.异常值处理 & 数据归一化 & 数据连续属性离散化
1.异常值分析 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 异常值分析 → 3σ原则 / 箱型图分析异常值处理方法 → 删除 / 修正填补 ...
- 在Delphi中调用"数据链接属性"对话框设置ConnectionString
项目需要使用"数据链接属性"对话框来设置ConnectionString,查阅了一些资料,解决办法如下: 1.Delphi 在Delphi中比较简单,步骤如下: 方法1: use ...
- Angular4.x 创建组件|绑定数据|绑定属性|数据循环|条件判断|事件|表单处理|双向数据绑定
Angular4.x 创建组件|绑定数据|绑定属性|数据循环|条件判断|事件|表单处理|双向数据绑定 创建 angular 组件 https://github.com/angular/angular- ...
- Python基础 | 数据文件的读写
目录 txt txt的读入 txt的写出 csv xls\xlsx 在线网页数据 常用的工具 爬虫的步骤 pdf pdfrw PyPDF2 提取文档信息 word文档 其他统计软件生成文件 本文总结使 ...
- 在 Istio 中实现 Redis 集群的数据分片、读写分离和流量镜像
Redis 是一个高性能的 key-value 存储系统,被广泛用于微服务架构中.如果我们想要使用 Redis 集群模式提供的高级特性,则需要对客户端代码进行改动,这带来了应用升级和维护的一些困难.利 ...
- 营销MM让我讲MySQL日志顺序读写及数据文件随机读写原理
摘要:你知道吗,MySQL在实际工作时候的两种数据读写机制? 本文分享自华为云社区<MySQL日志顺序读写及数据文件随机读写原理>,作者:JavaEdge . MySQL在实际工作时候的两 ...
- 详解Oracle数据货场中三种优化:分区、维度和物化视图
转 xiewmang 新浪博客 本文主要介绍了Oracle数据货场中的三种优化:对分区的优化.维度优化和物化视图的优化,并给出了详细的优化代码,希望对您有所帮助. 我们在做数据库的项目时,对数据货场的 ...
- [转帖]etcd 在超大规模数据场景下的性能优化
etcd 在超大规模数据场景下的性能优化 阿里系统软件技术 2019-05-27 09:13:17 本文共5419个字,预计阅读需要14分钟. http://www.itpub.net/2019/ ...
随机推荐
- Java虚拟机—垃圾回收算法(整理版)
1.概述 由于垃圾收集算法的实现涉及大量的程序细节.因此本节不打算过多地讨论算法的实现,只是介绍几种算法的思想及其发展过程.主要涉及的算法有标记-清除算法.复制算法.标记-整理算法.分代收集算法. 2 ...
- 基于jeesite的cms系统(七):GlobalException全局异常和部署
关于全局异常: 在业务代码中专注处理业务,而不是返回各种CodeMsg(比如这里只需要知道登录时成功还是失败,其余情况直接抛出异常),可以直接抛出异常,添加一个全局异常类,根据CodeMsg来生成异常 ...
- MYSQL的学习
启动MYSQL :net start mysql或者手动启动,输入密码:mysql -u root -p 先创建数据库在创建表格,创建数据库:create databsse 数据库名称,创建表格:cr ...
- 更改MySQL密码
#安装MySQL5.7参考:https://blog.csdn.net/qq_23033339/article/details/80872136#MYSQL的基础操作参考:https://www.cn ...
- jquery的datatables第二次加载报错
"destroy":true, "scrollX": true, "ordering": false, "sScrollXInne ...
- 二分查找算法的java实现
1.算法思想: 二分查找又称折半查找,它是一种效率较高的查找方法. 时间复杂度:O(nlogn) 二分算法步骤描述: ① 首先在有序序列中确定整个查找区间的中间位置 mid = ( low + ...
- python多任务抓取图片
import re import urllib.request import gevent def download(image_download, images_path,i): headers = ...
- python 列表中[ ]中冒号‘:’的作用
中括号[ ]:用于定义列表或引用列表.数组.字符串及元组中元素位置 list1 = [, ] list2 = [, , , , , , ] print ] print :] 冒号: 用于定义分片. ...
- Unity AssetBundle的生成、加载和热更新
当前使用的是unity2018.2.6版本. 生成AssetBundle 这个版本生成AssetBundle有两种方式,一种是在资源的Inspector面板下边配置AssetBundle名称,然后调用 ...
- codeforces 343D 树剖后odt维护
子树修改+路径修改+单点查询 树链剖分+区间维护即可 由于只有单点查询,我直接用了odt,复杂度还行 #include<bits/stdc++.h> #define endl '\n' # ...