Active Learning主动学习
Active Learning主动学习
我们使用一些传统的监督学习方法做分类的时候,往往是训练样本规模越大,分类的效果就越好。但是在现实生活的很多场景中,标记样本的获取是比较困难的,这需要领域内的专家来进行人工标注,所花费的时间成本和经济成本都是很大的。而且,如果训练样本的规模过于庞大,训练的时间花费也会比较多。那么有没有办法,用尽可能少的标注,获取尽可能好的训练结果?主动学习(Active Learning)为我们提供了这种可能。主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精确度。
定义:在某些情况下,没有类标签的数据相当丰富而有类标签的数据相当稀少,并且人工对数据进行标记的成本又相当高昂。在这种情况下,我们可以让学习算法主动地提出要对哪些数据进行标注,之后我们要将这些数据送到专家那里,让他们进行标注,再将这些数据加入到训练样本集中对算法进行训练。这一过程叫做主动学习。
由此我们可以看出,主动学习最主要的就是选择策略。
主动学习的模型如下:
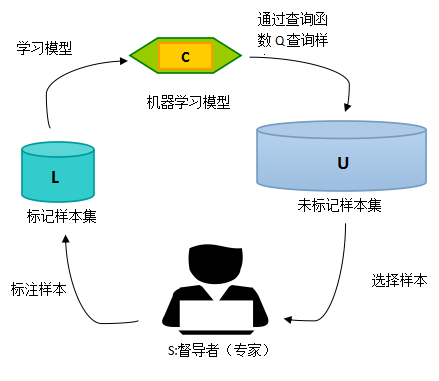
A=(C,Q,S,L,U),其中 C 为一组或者一个分类器,L是用于训练已标注的训练样本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本标注正确的标签.
最开始,先将样本分为少量的已标记样本L,和大量未标记样本U.学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或一批最有用的样本(大多数算法都每次选择一批样本),专家标记,将标记后的样本从U中删除,加入L中,然后利用获得的新知识(所有L)来训练分类器和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则为止。
在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。
不确定性:我们可以借助信息熵的概念来进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。事实上,有些基于不确定性的主动学习查询函数就是使用了信息熵来设计的,比如熵值装袋查询(Entropy query-by-bagging)。所以,不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含的丰富信息量,对我们训练模型来说就是有用的。
差异性:怎么来理解呢?之前说到或查询函数每次迭代中查询一个或者一批样本。我们当然希望所查询的样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性。在每轮迭代抽取单个信息量最大的样本加入训练集的情况下,每一轮迭代中模型都被重新训练,以获得的知识去参与对样本不确定性的评估可以有效地避免数据冗余。但是如果每次迭代查询一批样本,那么就应该想办法来保证样本的差异性,避免数据冗余。
Active Learning主动学习的更多相关文章
- Active Learning 主动学习
Active Learning 主动学习 2015年09月30日 14:49:29 qrlhl 阅读数 21374 文章标签: 算法机器学习 更多 分类专栏: 机器学习 版权声明:本文为博主原创文 ...
- [Active Learning] 01 A Brief Introduction to Active Learning 主动学习简介
目录 什么是主动学习? 主动学习 vs. 被动学习 为什么需要主动学习? 主动学习与监督学习.弱监督学习.半监督学习.无监督学习之间的关系 主动学习的种类 主动学习的一个例子 主动学习工具包 ALiP ...
- 简要介绍Active Learning(主动学习)思想框架,以及从IF(isolation forest)衍生出来的算法:FBIF(Feedback-Guided Anomaly Discovery)
1. 引言 本文所讨论的内容为笔者对外文文献的翻译,并加入了笔者自己的理解和总结,文中涉及到的原始外文论文和相关学习链接我会放在reference里,另外,推荐读者朋友购买 Stephen Boyd的 ...
- Active Learning
怎么办?进行Active Learning主动学习 Active Learning是最近又流行起来了的概念,是一种半监督学习方法. 一种典型的例子是:在没有太多数据的情况下,算法通过不断给出在决策边界 ...
- 主动学习——active learning
阅读目录 1. 写在前面 2. 什么是active learning? 3. active learning的基本思想 4. active learning与半监督学习的不同 5. 参考文献 1. ...
- 【主动学习】Variational Adversarial Active Learning
本文记录了博主阅读ICCV2019一篇关于主动学习论文的笔记,第一篇博客,以后持续更新哈哈 论文题目:<Variational AdVersarial Active Learning> 原 ...
- 主动学习(Active Learning)
主动学习简介 在某些情况下,没有类标签的数据相当丰富而有类标签的数据相当稀少,并且人工对数据进行标记的成本又相当高昂.在这种情况下,我们可以让学习算法主动地提出要对哪些数据进行标注,之后我们要将这些数 ...
- Recorder︱深度学习小数据集表现、优化(Active Learning)、标注集网络获取
一.深度学习在小数据集的表现 深度学习在小数据集情况下获得好效果,可以从两个角度去解决: 1.降低偏差,图像平移等操作 2.降低方差,dropout.随机梯度下降 先来看看深度学习在小数据集上表现的具 ...
- [Machine Learning] Active Learning
1. 写在前面 在机器学习(Machine learning)领域,监督学习(Supervised learning).非监督学习(Unsupervised learning)以及半监督学习(Semi ...
随机推荐
- [luoguP1351] 联合权值(Dfs)
传送门 距离为2的点会产生权值,第一问,只需要在dfs的时候把一个点相邻的点都处理出来就行. 具体处理方式看代码,然而这样只处理了一遍,最后在乘2就好了. 第二问只需要处理一个点相邻的点中最大的和次大 ...
- SpringBoot @ConditionalOnBean、@ConditionalOnMissingBean注解源码分析与示例
前言: Spring4推出了@Conditional注解,方便程序根据当前环境或者容器情况来动态注入bean,对@Conditional注解不熟悉的朋友可移步至 Spring @Conditional ...
- 【Tomcat】Tomcat替换猫的图片
参考:网页title上添加图片 直接替换Tomcat安装目录下ROOT下面的favicon.ico图标(名字与前面一样favicon.ico)
- 1267 老鼠的旅行 2012年CCC加拿大高中生信息学奥赛
1267 老鼠的旅行 2012年CCC加拿大高中生信息学奥赛 题目描述 Description You are a mouse that lives in a cage in a large lab ...
- Linux服务管理(Ubuntu服务管理工具sysv-rc-conf)(转)
Linux运行级别 Linux系统任何时候都运行在一个指定的运行级上,并且不同的运行级的程序和服务都不同,所要完成的工作和要达到的目的都不同,系统可以在这些运行级之间进行切换,以完成不同的工作. 运行 ...
- [转]SQL Server编程:SMO介绍
转自:周公 最近在项目中用到了有关SQL Server管理任务方面的编程实现,有了一些自己的心得体会,想在此跟大家分享一下,在工作中用到了SMO/SQL CLR/SSIS等方面的知识,在国内这方面的文 ...
- 【转】java中Thread类方法介绍
原文: java中Thread类方法介绍 http://blog.csdn.net/seapeak007/article/details/53395609 这篇文章找时间分析一下!!!:http:// ...
- 写给小白的JVM学习指南
Java 虚拟机是学习 Java 的基础,也是迈入高级 Java 开发工程师的必备知识点.所以今天这篇文章我们来聊聊如何从零开始学习 Java 虚拟机. 基础 对于刚刚接触 JVM 的同学来说,JVM ...
- <感悟帖>互联网与电子传统行业之经历
依据鄙人浅显的实习.毕业工作经验以及个人思考得此文. 鄙人有幸在BAT中的B实习,以及某电子行业科研机构工作,略有心得.总结例如以下.也算是对自己的一个交待和反省. 鄙人小硕毕业211学校非985,C ...
- Ubuntu 12.04 LTS 无法进入桌面环境
今天开机后,在登陆的时候,进入了登陆界面(选择用户,输入密码的那个界面),输入正确的密码后屏幕跳转了一下,但是很快又回到了登陆界面.然后我就尝试以guest [访客]的身份登陆,发现进入了桌面系统. ...