Hadoop Hive概念学习系列之hive的正则表达式初步(六)
说在前面的话
hive的正则表达式,是非常重要!作为大数据开发人员,用好hive,正则表达式,是必须品!
Hive中的正则表达式还是很强大的。数据工作者平时也离不开正则表达式。对此,特意做了个hive正则表达式的小结。所有代码都经过亲测,正常运行。
1.regexp
语法: A REGEXP B
操作类型: strings
描述: 功能与RLIKE相同
select count(*) from olap_b_dw_hotelorder_f where create_date_wid not regexp '\\d{8}'
与下面查询的效果是等效的:
select count(*) from olap_b_dw_hotelorder_f where create_date_wid not rlike '\\d{8}';
2.regexp_extract
语法: regexp_extract(string subject, string pattern, int index)
返回值: string
说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
hive> select regexp_extract('IloveYou','I(.*?)(You)',1) from test1 limit 1;
Total jobs = 1
...
Total MapReduce CPU Time Spent: 7 seconds 340 msec
OK
love
Time taken: 28.067 seconds, Fetched: 1 row(s)
hive> select regexp_extract('IloveYou','I(.*?)(You)',2) from test1 limit 1;
Total jobs = 1
...
OK
You
Time taken: 26.067 seconds, Fetched: 1 row(s)
hive> select regexp_extract('IloveYou','(I)(.*?)(You)',1) from test1 limit 1;
Total jobs = 1
...
OK
I
Time taken: 26.057 seconds, Fetched: 1 row(s)
hive> select regexp_extract('IloveYou','(I)(.*?)(You)',0) from test1 limit 1;
Total jobs = 1
...
OK
IloveYou
Time taken: 28.06 seconds, Fetched: 1 row(s)
hive> select regexp_replace("IloveYou","You","") from test1 limit 1;
Total jobs = 1
...
OK
Ilove
Time taken: 26.063 seconds, Fetched: 1 row(s)
3.regexp_replace
语法: regexp_replace(string A, string B, string C)
返回值: string
说明:将字符串A中的符合Java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似Oracle中的regexp_replace函数。
hive> select regexp_replace("IloveYou","You","") from test1 limit 1;
Total jobs = 1
...
OK
Ilove
Time taken: 26.063 seconds, Fetched: 1 row(s)
hive> select regexp_replace("IloveYou","You","lili") from test1 limit 1;
Total jobs = 1
...
OK
Ilovelili
Hive里的正则表达式
如,https://cwiki.apache.org/confluence/display/Hive/GettingStarted
输入regex可查到
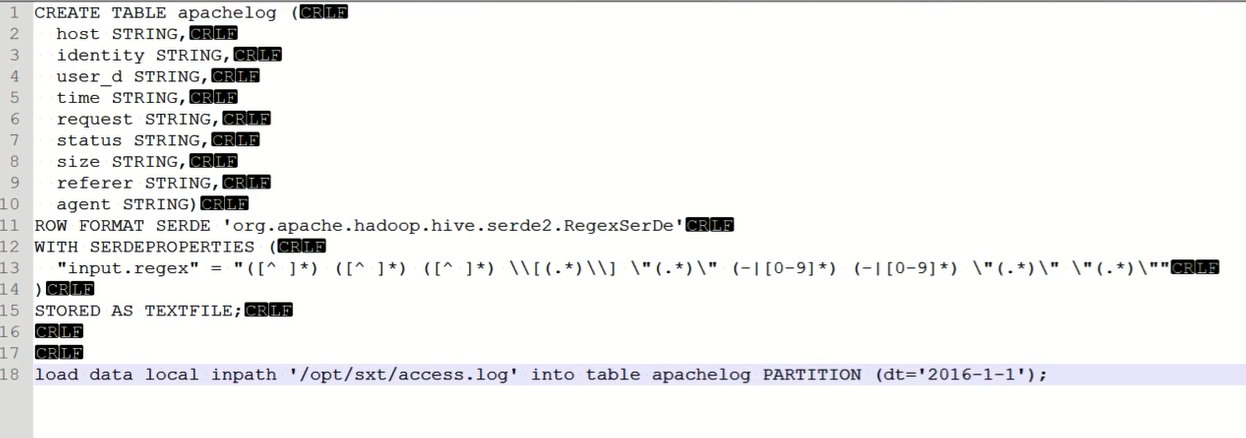
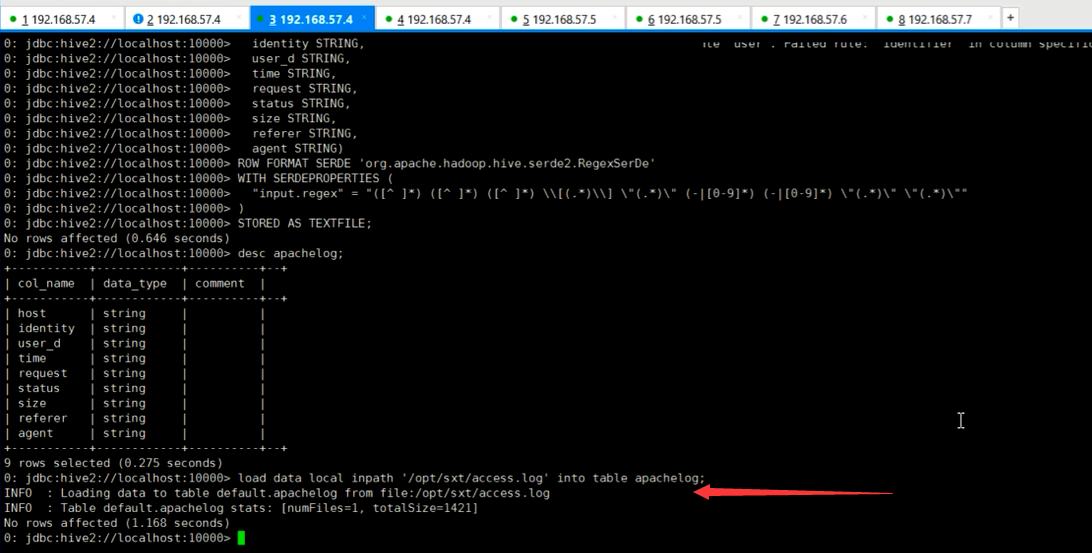
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^]*) \[()\] ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
)
STORED AS TEXTFILE;
下面就是hive里的正则表达式,9个字段,对应定义那边也要9个
"input.regex" = "([^ ]*) ([^ ]*) ([^.]*) \[(.*)\] "(.*)" (-|[0-9]*) (-|[(0-9]*) "(.*)" "(.*)""
([^ ]*) ([^ ]*) ([^.]*) \[(.*)\] "(.*)" (-|[0-9]*) (-|[(0-9]*) "(.*)" "(.*)"
([^ ]*) ([^ ]*) ([^.]*) \\[(.*)\\] "(.*)" (-|[0-9]*) (-|[(0-9]*) \"(.*)\" \"(.*)\"
数据来源,
yarn-root-nodemanager-master.log
或
yarn-spark-nodemanager-master.log
yarn-hadoop-nodemanager-master.log
这里,有个正则表达式的好工具!
RegexBuddy.exe

很好用的这款软件!双击它即可。
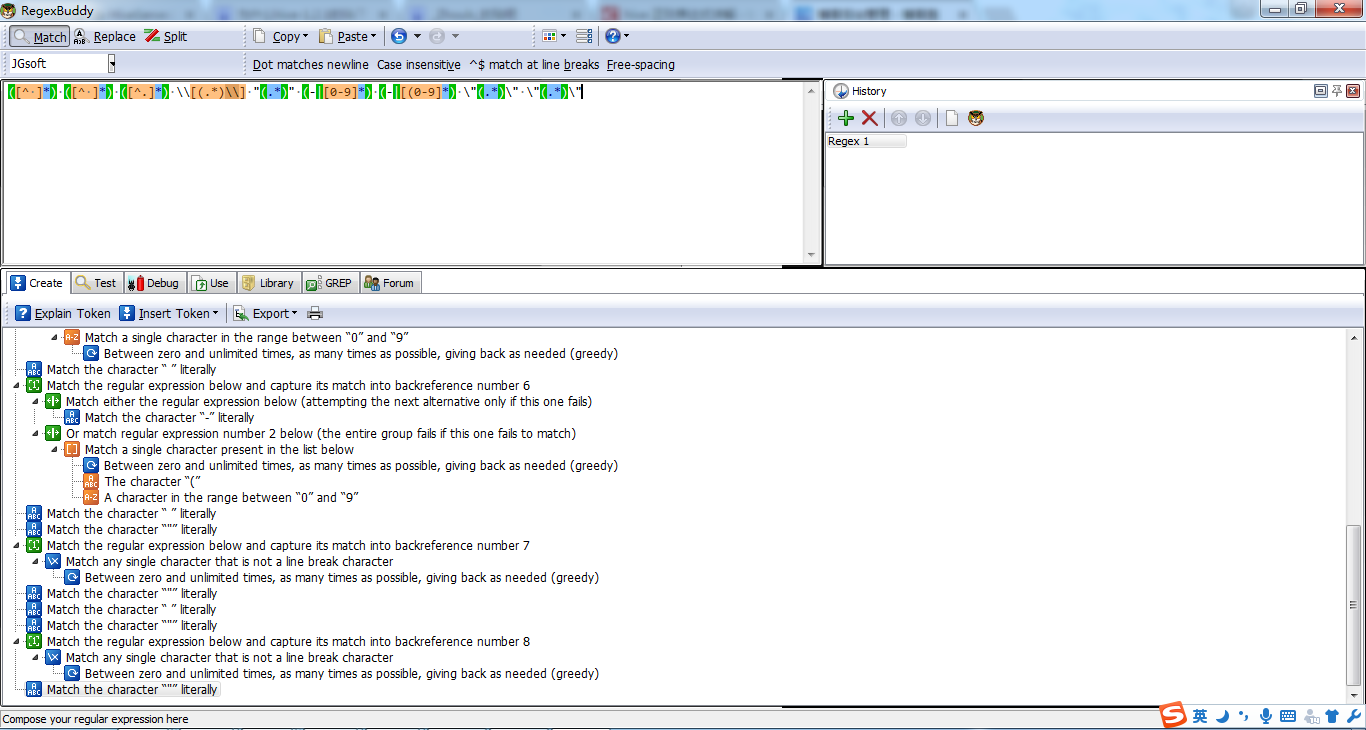
如上图所示颜色,代表我们测试的正则表达式,是正确的!


Hadoop Hive概念学习系列之hive的正则表达式初步(六)的更多相关文章
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hadoop Hive概念学习系列之hive里如何显示当前数据库及传参(十九)
这个小知识点,看似简单,用处极大. $ hive --hiveconf hive.cli.print.current.db=true $ hive --hiveconf hive.cli.print. ...
- Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例 在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.在hive安装目录下的bin,使用下面命令进行开启: hive -service hives ...
- Hadoop Hive概念学习系列之hive的索引及案例(八)
hive里的索引是什么? 索引是标准的数据库技术,hive 0.7版本之后支持索引.Hive提供有限的索引功能,这不像传统的关系型数据库那样有“键(key)”的概念,用户可以在某些列上创建索引来加速某 ...
- Hadoop Hive概念学习系列之hive的数据压缩(七)
Hive文件存储格式包括以下几类: 1.TEXTFILE 2.SEQUENCEFILE 3.RCFILE 4.ORCFILE 其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直 ...
- Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)
Hive可以通过实现用户定义函数(User-Defined Functions,UDF)进行扩展(事实上,大多数Hive功能都是通过扩展UDF实现的).想要开发UDF程序,需要继承org.apache ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
随机推荐
- [bzoj1692][Usaco2007 Dec]队列变换_后缀数组_贪心
队列变换 bzoj-1692 Usaco-2007 Dec 题目大意:给定一个长度为$n$的字符串.每次从头或尾取出一个字符加到另一个字符串里.要求变换后生成的字符串字典序最小,求字典序最小的字符串. ...
- Word Search(深度搜索DFS,参考)
Given a 2D board and a word, find if the word exists in the grid. The word can be constructed from l ...
- JVM(五):探究类加载过程-上
JVM(五):探究类加载过程-上 本文我们来研究一个Java字节码文件(Class文件)是如何加载入内存中的,在這個过程中涉及类加载过程中的加载,验证,准备,解析(连接),初始化,使用,销毁过程,并探 ...
- crontab not running
there are mutliple ways to describle this issue 1. crontab not running 2. crontab not running and no ...
- laralvel 关系多对多
- 012 router password
Press RETURN to get started! Router>en Router#config t Enter configuration commands, one pe ...
- day2-搭建hdfs分布式集群
1.搭建hdfs分布式集群 4.1 hdfs集群组成结构: 4.2 安装hdfs集群的具体步骤: 一.首先需要准备N台linux服务器 学习阶段,用虚拟机即可! 先准备4台虚拟机:1个namenode ...
- 【cocos2d-x 3.7 飞机大战】 决战南海I (三) 敌机实现
如今来实现敌机类 敌机和我方飞机相似,具有生命值.能够发射子弹.而且有自己的运动轨迹.事实上能够为它们设计一个共同的基类,这样能够更方便扩展. 不同的敌机,应设置不同的标识.属性 // 敌机生命值 c ...
- iOS 代码安全加固--反编译和代码混淆
一.class-dump反编译 1.将打包的ipa反编译下,.ipa改成.zip,并解压 6.右击—显示包内容,找到如下有个白框黑底的 7.将其复制到桌面xx文件夹中,在终端中输入相关命令 cd 进 ...
- C#之快速排序 C#之插入排序 C#之选择排序 C#之冒泡排序
C#之快速排序 算法描述 1.假定数组首位元素为“枢轴”,设定数列首位(begin)与末位(end)索引: 2.由末位索引对应元素与“枢轴”进行比较,如果末位索引对应元素大于“枢轴”元素,对末位索 ...