Flink学习(七) 多流转换算子 拆分合并流
一、Split 和 Select (使用split切分过的流是不能被二次切分的)
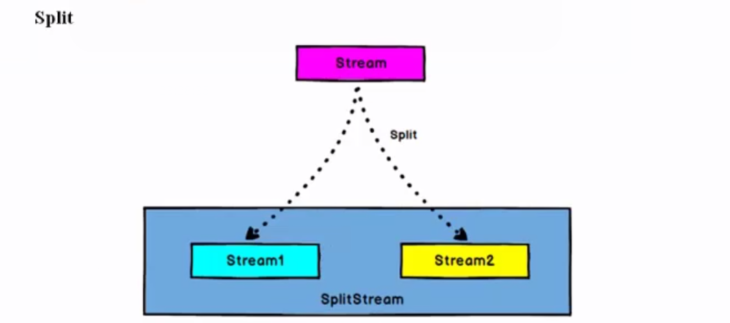
DataStream --> SplitStream : 根据特征把一个DataSteam 拆分成两个或者多个DataStream.
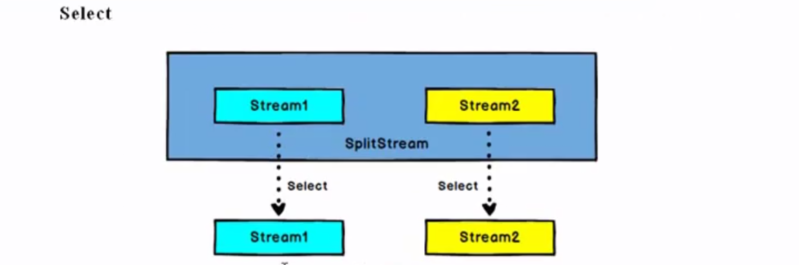
SplitStream --> DataStream:从一个SplitStream中获取一个或者多个DataStream。
二、Connect 和 CoMap / CoFlatMap
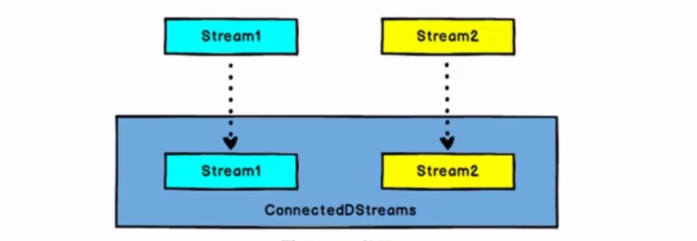
DataStream,DataStream --> ConnectedStream:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持着各自的数据和形式,不发生变化,两个流相互独立。
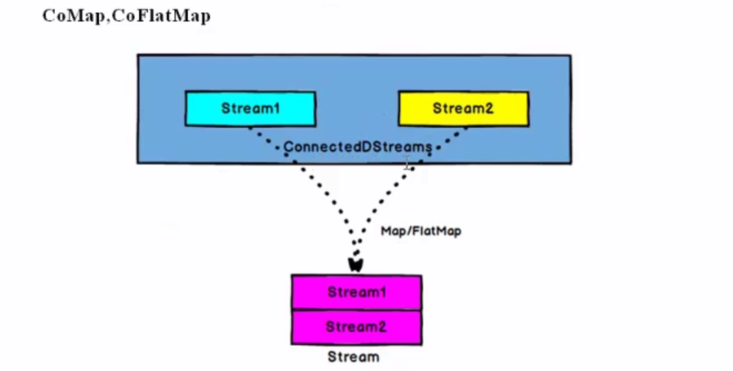
ConnectedStream --> DataStream:作用与 ConnectedStream上,功能与map和Flatmap一样,对 ConnectedStream中的每一个Stream分别进行map和flatmap处理。
三、Union
DataStream --> DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream
注意:Connect 与 Union区别:
1、Union之前两个流的类型必须是一样的,Conect可以不一样,并且Connect之后进行coMap中调整为一样的。
2、Connect只能操作两个流,Union可以操作多个。
综合代码:(可直接运行,数据在注释中)
package com.wyh.streamingApi.Transform import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._ //温度传感器读数样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double) object TransformTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) /**
* sensor_1,1547718199,35.80018327300259
* sensor_6,1547718201,15.402984393403084
* sensor_7,1547718202,6.720945201171228
* sensor_10,1547718205,38.1010676048934444
* sensor_1,1547718199,35.1
* sensor_1,1547718199,31.0
* sensor_1,1547718199,39
*/
val streamFromFile = env.readTextFile("F:\\flink-study\\wyhFlinkSD\\data\\sensor.txt") //基本转换算子和滚动聚合算子=======================================================================================
/**
* map keyBy sum
*/
val dataStream: DataStream[SensorReading] = streamFromFile.map(data => {
val dataArray = data.split(",")
SensorReading(dataArray(0).trim, dataArray(1).trim.toLong, dataArray(2).trim.toDouble)
}) // dataStream.keyBy(0).sum(2).printToErr("keyBy test") //scala强类型语言 只有_.id 可以指定返回类型
val aggStream: KeyedStream[SensorReading, String] = dataStream.keyBy(_.id)
val stream1: DataStream[SensorReading] = aggStream.sum("temperature")
// stream1.printToErr("scala强类型语言") /**
* reduce
*
* 输出当前传感器最新的温度要加10,时间戳是上一次数据的时间加1
*/
aggStream.reduce(new ReduceFunction[SensorReading] {
override def reduce(t: SensorReading, t1: SensorReading): SensorReading = {
SensorReading(t.id, t.timestamp + 1, t1.temperature + 10)
}
}) //.printToErr("reduce test") //多流转换算子====================================================================================================
/**
* 分流
* split select
* DataStream --> SplitStream --> DataStream
*
* 需求:传感器数据按照温度高低(以30度为界),拆分成两个流
*/
val splitStream = dataStream.split(data => {
//盖上戳 后面进行分拣
if (data.temperature > 30) {
Seq("high")
} else if (data.temperature < 10) {
Seq("low")
} else {
Seq("health")
}
}) //根据戳进行分拣
val highStream = splitStream.select("high")
val lowStream = splitStream.select("low")
val healthStream = splitStream.select("health") //可以传多个参数,一起分拣出来
val allStream = splitStream.select("high", "low") // highStream.printToErr("high")
// lowStream.printToErr("low")
// allStream.printToErr("all")
// healthStream.printToErr("healthStream") /**
* 合并 注意: Connect 只能进行两条流进行合并,但是比较灵活,不同流的数据结构可以不一样
* Connect CoMap/CoFlatMap
*
* DataStream --> ConnectedStream --> DataStream
*/
val warningStream = highStream.map(data => (data.id, data.temperature))
val connectedStream = warningStream.connect(lowStream) val coMapDataStream = connectedStream.map(
warningData => (warningData._1, warningData._2, "温度过高报警!!"),
lowData => (lowData.id, lowData.temperature, "温度过低报警===")
) // coMapDataStream.printToErr("合并流") /**
* 合并多条流 注意: 要求数据结构必须要一致,一样
*
* Union DataStream --> DataSteam 就没有一个中间转换操作了
*
*/ val highS = highStream.map(h => (h.id, h.timestamp, h.temperature, "温度过高报警!!"))
val lowS = lowStream.map(l => (l.id, l.timestamp, l.temperature, "温度过低报警==="))
val healthS = healthStream.map(l => (l.id, l.timestamp, l.temperature, "健康")) val unionStream = highS.union(lowS).union(healthS) unionStream.printToErr("union合并") env.execute("transform test")
} }
Flink学习(七) 多流转换算子 拆分合并流的更多相关文章
- Flink实例(五十): Operators(十)多流转换算子(五)coGroup 与union
参考链接:https://mp.weixin.qq.com/s/BOCFavYgvNPSXSRpBMQzBw 需求场景分析 需求场景 需求诱诱诱来了...数据产品妹妹想要统计单个短视频粒度的「点赞,播 ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-数据源(DataSource)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习总结
flink学习总结 1.Flink是什么? Apache Flink 是一个框架和分布式处理引擎,用于处理无界和有界数据流的状态计算. 2.为什么选择Flink? 1.流数据更加真实的反映了我们的生活 ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- php 接收二进制流转换成图片
php 接收二进制流转换成图片,图片类imageUpload.php如下: <?php /** * 图片类 * @author http://blog.csdn.net/haiqiao_2010 ...
- delphi 怎么将一个文件流转换成字符串(String到流,String到文件,相互转化)
//from http://kingron.myetang.com/zsfunc0d.htm (*// 标题:充分利用pascal字符串类型 说明:和PChar不同,string可以保存# ...
- MyBatis学习七:spring和MyBatis整合
<\mybatis\day02\16mybatis和spring整合-sqlSessionFactory配置.avi;> MyBatis学习七:spring和MyBatis整合.逆向工程 ...
随机推荐
- 授权|取消授权MYSQL数据库用户权限
授权 queryusr用户查询test数据库 grant select on test.* to queryusr@'%'; flush PRIVILEGES 收回queryusr用户查询test数据 ...
- 10C++选择结构(4)——教学
一.switch语句 (第25课 成绩等级) 问题:风之巅小学规定,若测试成绩大于或等于90分为"A",大于或等于70分小于90分为"B",大于或等于60分小于 ...
- legend不显示
legend写了对应的data,在series需要填写对应的name
- docker-entrypoint.sh 文件的用处
参考出处很多著名库的 Dockerfile 文件中,通常都是 ENTRYPOINT 字段会是这样: ENTRYPOINT ["docker-entrypoint.sh"]这里我们参 ...
- Ubuntu中文件夹建立软链接方法
1:预备知识 -s 是代号(symbolic)的意思. 这里有两点要注意:第一,ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化:第二,ln的链接又软链 ...
- 解决phpmyadmin导入MYSQL数据库限制大小为50M的问题
有时候想导入的数据库太大.但是遭到的限制 解决phpmyadmin导入MYSQL数据库限制大小为50M的问题 转载于:https://www.cnblogs.com/wesky/p/10609340. ...
- [转]Visual Studio调试模式下添加命令行参数的方法
在VS中向命令行添加参数,即向main()函数传递参数的方法: 右键单击:添加参数的工程-->属性-->配置属性-->调试,在右侧"命令参数"栏输入要添加的参数, ...
- dotnet最小webApi开发实践
dotnet最小webApi开发实践 软件开发过程中,经常需要写一些功能验证代码.通常是创建一个console程序来验证测试,但黑呼呼的方脑袋界面,实在是不讨人喜欢. Web开发目前已是网络世界中的主 ...
- KES的执行计划分析与索引优化
今天我们继续探讨国产数据库KES的相关内容,本次的讨论重点将放在SQL优化的细节上.作为Java开发人员,我们通常并不需要深入了解数据库的底层实现细节,而是更多地关注如何提升应用性能与数据库的交互效率 ...
- UWP 检查是否试用版模式
//老版本的方法: // var check= CurrentAppSimulator.LicenseInformation.IsActive && CurrentAppSimulat ...