数据挖掘 | 数据隐私(4) | 差分隐私 | 差分隐私概论(下)(Intro to Differential Privacy 2)
L4-Intro to Differential Privacy
拉普拉斯机制(Laplace Mechanism)
上一节课中,我们讨论了随机响应,这是一种适合于单个位的隐私化。这种算法一般来说并不直接也误差较大。今日所关注的是拉普拉斯机制,可以直接应用于任意一种类型的数字查询。在引入拉普拉斯机制,首先提出一个概念:函数敏感度(sensitivity),一般特指L1敏感度(即基于L1范数的敏感度),定义如下:
定义1
使\(f:\mathcal{X}^n\rightarrow\mathbb{R} ^k\),那么\(f\)的\(\mathcal{l_1}\)-敏感度为:
\]
其中\(X\)和\(X'\)为邻近数据集
后面丢掉\(f\),只使用\(\Delta\)以表示\(\mathcal{l_1}\)-敏感度。
敏感度用于衡量差分隐私的内容是合适而自然的,正因为差分隐私试图掩盖一个个个体的具体分布差距,通过这一敏感度作为上界,就可以衡量该函数应该会发生多大的改变。值得注意的是,我们用的是\(\mathcal{l_1}\)-敏感度,而非\(\mathcal{l_2}\)-敏感度,但是在其他分布例如说高斯机制中会使用。举个例子:\(f=\frac{1}{n}\sum^n_{i=1}X_i \ \ X_i\in\{0,1\}\),很容易算出敏感度为\(1/n\),因为只有一个位被翻转。
定义2
对于位置与规模参数分别为\(0\)与\(b\)的拉普拉斯分布,如下定义其密度函数:
\]
注意到拉普拉斯分布的方差为\(2b^2\)。
如下图所示,拉普拉斯分布本质是两个对称的指数分布,在\(x\in [0,\infty)\)存在正比于\(exp(-cx)\)的密度函数,而拉普拉斯分布则是在\(x\in \mathbb{R}\)存在正比于\(\exp(-c|x|)\)的密度函数。另外高斯分布的尾部要比拉普拉斯分布的稍轻一点,换句话来说就是高斯分布的中心化程度更高。
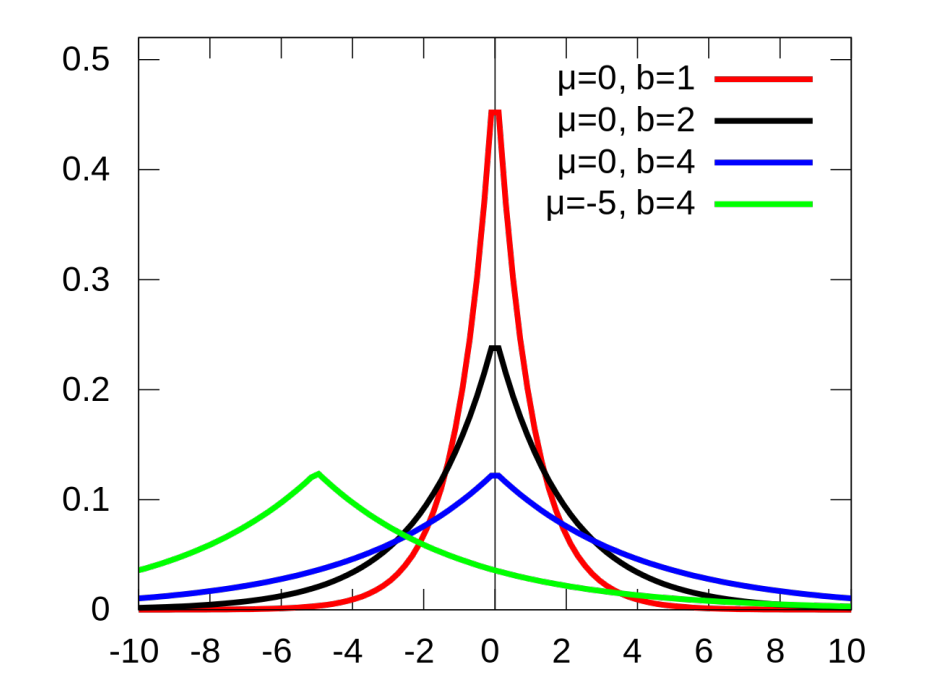
介绍了拉普拉斯分布之后,就可以引入拉普拉斯机制这一概念,原理非常简单:即是按照数据敏感度的程度添加噪音。
定义3
使\(f:\mathcal{X}^n\rightarrow \mathbb{R} ^k\),那么拉普拉斯机制即是
\]
其中\(Y_i\)是独立的拉普拉斯分布,\(Laplace(\Delta/\epsilon)\)的随机变量。
由此我们就可以将其应用于例子中的\(f=\frac{1}{n}\sum^n_{i=1}X_i\),并且\(k=1\)。那么\(\Delta = 1/n\)。为此,对其施加拉普拉机制之后得到\(\tilde p=f(X)+Y\),其中\(Y\)为\(Laplace(1/(\epsilon n))\)。由定义可知,\(\mathbf{E}[\tilde p]=p\),\(\mathbf{Var}[\tilde p]=\mathbf{Var}[Y]=O(1/(\epsilon^2 n^2))\),然后通过切比雪夫不等式就可以得到合理概率界限。对比于\(\epsilon\)-随机响应的精确度\(O(1/(\epsilon\sqrt n))\),可见拉普拉斯机制是二次的,小于\(\epsilon\)-随机响应。
定理4
拉普拉斯机制乃是\(\epsilon\)-差分隐私
证明:假若\(X\)与\(Y\)为一对邻近数据集,存在一个数据条目不一致。使得\(p_X(z)\)与\(p_Y(z)\)为点\(z\in\mathbb{R}^k\)的概率密度函数\(M(X)\)与\(M(Y)\)。为此我们需要证明其上界为\(\exp(\epsilon)\),那么对于任意一个\(X\)与\(Y\)的\(z\)
\frac{p_X(z)}{p_Y(z)} & = \frac{\prod^k_{i=1}\exp(-\frac{\epsilon|f(X)_i-z_i|}{\Delta})}
{\prod^k_{i=1}\exp(-\frac{\epsilon|f(Y)_i-z_i|}{\Delta})} \\
& = \prod^k_{i=1}\exp(-\frac{\epsilon(|f(X)_i-z_i|-|f(X)_i-z_i|)}{\Delta}) \\
& \le \prod^k_{i=1}\exp(-\frac{\epsilon|f(X)_i-f(X)_i|}{\Delta}) \\
& = \exp(\frac{\epsilon\sum^k_{i=1}|f(X)_i-f(X)_i|}{\Delta}) \\
& = \exp(\frac{\epsilon||f(X)-f(X)||_1}{\Delta}) \\
& \le \exp(\epsilon)
\end{align}
\]
首先应用三角不等式,然后应用\(\mathcal{l_1}\)-敏感度的定义。
计数查询(Counting Queries)
现在要讨论计数查询的情况了,计数查询也能用非标准化版本的差分隐私来称呼。
首先假若每个个体都拥有一个隐私为\(X_i\in\{0,1\}\),其中定义\(f\)为最终他们的求和。那么敏感度为\(1\),经过\(\epsilon\)-差分隐私的数据就是\(f(X)+\text{Laplace}(1/\epsilon)\)。其误差则为\(O(1/\epsilon)\),独立于数据集的规模。
现在我们考虑多次查询。假若我们拥有\(k\)次查询\(f=(f_1,\dots,f_k)\),都是提前指定好的。最后就会输出一个向量\(f(X) + Y\),其中\(Y_i\)都符合i.i.d条件的拉普拉斯随机变量。现在我们再考虑这个分布的规模系数。对于每个具体的查询\(f_j\)都拥有敏感度 \(1\),但是又要考虑所有查询都是基于一个数据集,也就是说单个查询的改变会影响到多种查询组合。例如说,交换两个个体,二者的位是相反的,那么所有查询都会改变\(1\),因此最终的\(\mathcal{l_1}\)-敏感度为\(k\)。我们再采用数学的方法进行证明:由于\(f(X)=\sum(f_1(X_i\dots,f_k(X_i))\),而临近数据集\(X\)与\(Y\)之间差别在于\(x\)与\(y\),为此\(\mathcal{l_1}\)差分为\(\sum_j|f_j(x)-f_j(y)|\),然后上界可以算出来得到\(\sum_j|f_j(x)-f_j(y)|\le \sum_j 1=k\)。
算出来其敏感度上界\(\Delta=1\),也就得到了噪音\(Y_i\sim\text{Laplace}(k/\epsilon)\),然后添加到每个坐标分量上面,每次计数查询都带上了总规模为\(O(k/\epsilon)\)的误差。
有些地方还是必须注意:第一点,这种处理\(k\)计数查询的方法只适用于提前指定好的查询,也就是说非适应性的查询。第二点,对于 Dinur-Nissim攻击,其中数据分析器进行\(\Omega(n)\)次技术查询,那么管理器带了总量为\(O(\sqrt n)\)的噪音,那么数据分析器
就能重构数据集并且使得其符合\(BNP\)性。而完美采用的策略使得数据分析器查询\(O(n)\)时,加入了\(O(n/\epsilon)\)的噪音,成功保护了隐私。今后还要讨论如何面对更为强大的攻击,以及如何在减少噪音的情况下隐私性不变。
直方图(Histograms)
这里提出一种新的查询方法为直方图查询(histogram query),相比于比较悲观的计数查询(因为计数查询一个改变会影响整个结果),某些特定的数据结构可以让我们的数据查询得到更好的敏感度。这里我们举个带有明确特征的例子:例如说人的年龄(注意是通过向下取整得到离散的数值)。其实类似于计数查询,每个人都只有一个年龄,而我们的查询具体就是“有多少个人其年龄为\(X\)”。函数\(f\)定义为\((f_0,f_1,\dots,f_{k-1})\),其中\(k_i\)就是查询有多少人为\(i\)岁,显然这个函数的\(\mathcal{l_1}\)-敏感度为\(2\),因为改变其中一个人的岁数会导致一个年龄桶总数的下降,另一个年龄桶总数的上升。基于上述内容,拉普拉斯机制的处理方法即是输出\(f(X)+Y\),其中\(Y_i\sim\text{Laplace}(2/\epsilon)\),最终加入的噪音总量则为桶的总量\(k\)
公理5.
对于\(Y\sim\text{Laplace}(b)\),有:
\]
那么对于第\(i\)个桶,其误差显而易见为\(Y_i\)并且符合\(\mathbf{Pr}[|Y_i|\ge2\log(k/\beta)/\epsilon]\le\beta/k\),可以证得对于任意一个桶都有误差\(\ge2\log(k/\beta)/\epsilon\)对于大多数\(\beta\)的取值。换一种说法来说,就是直方图查询的误差是对数复杂度,而计数查询为线性复杂度的误差。
差分隐私的性质(Properties of Differential Privacy)
后处理性(Post-Processing)
只要数据不再被使用,那么经过隐私化的数据将不能再被去隐私化。
定理6.
使\(M:X^n\rightarrow Y\)为\(\epsilon\)-DP算法,以及\(F:Y\rightarrow Z\)为一个随机映射。那么对于\(F\cdot M\)也是\(\epsilon\)-DP。
证明:
\mathbf{Pr}[F(M(X))\in T] & = \mathbf{E}_{f\sim F}[\mathbf{Pr}[M(X)\in f^{-1}(M)]] \\
& \le\mathbf{E}_{f\sim F}[e^{\epsilon}\mathbf{Pr}[M(X')\in f^{-1}(M)]] \\
& = e^{\epsilon}\mathbf{Pr}[F(M(X'))\in T]
\end{align}
\]
群组隐私(Group Privacy)
定理7.
使\(M:X^n\rightarrow Y\)为\(\epsilon\)-DP算法。其中\(X\)与\(X'\)为在\(k\)个位置不一致的邻近数据集。那么对于所有\(T\subseteq Y\),满足:
\mathbf{Pr}[M(X)\in T] & \le \exp(k\epsilon)\mathbf{Pr}[M(X')\in T]
\end{align}
\]
证明:先使\(X^{(0)}=X\),\(X^{(k)}=X'\),其中二者在\(k\)位置存在差异。那么存在一系列从\(X^{(0)}\)到\(X^{(k)}\)的连续邻近数据集对。那么对于所有\(T\subseteq Y\),满足:
\mathbf{Pr}[M(X^{(0)})\in T] & \le e^\epsilon \mathbf{Pr}[M(X^{(1)})\in T] \\
& \le e^{2\epsilon} \mathbf{Pr}[M(X^{(2)})\in T] \\
& \cdots\\
& \le e^{k\epsilon} \mathbf{Pr}[M(X^{(k)})\in T] \\
\end{align}
\]
基本组合性( (Basic) Composition )
对于\(M=(M_1,\dots,M_k)\),为一系列\(k\)个\(\epsilon\)-DP算法,其输出为\(y=(y_1,\dots,y_k)\),那么满足:
\frac{\mathbf{Pr}[M(X)=y]}{\mathbf{Pr}[M(X')=y]} & =
\prod^k_{i=1}\frac{\mathbf{Pr}[M_i(X)=y_i|(M_1(X),\dots,M_{i-1}(X))=(y_1,\dots,y_k)]}
{\mathbf{Pr}[M_i(X')=y_i|(M_1(X'),\dots,M_{i-1}(X'))=(y_1,\dots,y_k)]} \\
& \le \prod^k_{i=1} \exp(\epsilon) \\
& = \exp(k\epsilon)
\end{align}
\]
数据挖掘 | 数据隐私(4) | 差分隐私 | 差分隐私概论(下)(Intro to Differential Privacy 2)的更多相关文章
- 差分隐私(Differential Privacy)定义及其理解
1 前置知识 本部分只对相关概念做服务于差分隐私介绍的简单介绍,并非细致全面的介绍. 1.1 随机化算法 随机化算法指,对于特定输入,该算法的输出不是固定值,而是服从某一分布. 单纯形(simplex ...
- Mac Mail PGP Setup 如何在苹果电脑上设置安全邮件 良好隐私密码法(英语:Pretty Good Privacy,缩写为PGP)
背景知识 良好隐私密码法(英语:Pretty Good Privacy,缩写为PGP),一套用于讯息加密.验证的应用程序,采用IDEA的散列算法作为加密与验证之用. 关联文献:https://en.w ...
- 洛谷5026 Lycanthropy 差分套差分
题目链接 https://www.luogu.com.cn/problem/P5026 题意 在一个长度为m的序列中,每次给一个下标x,和一个权值v,然后从x-v*3到x-v*2单调递增,从x-v*2 ...
- 【Luogu】P4231三步必杀(差分,差分)
题目链接 郑重宣布我以后真的再也不会信样例了,三种写法都能过 另:谁评的蓝题难度qwq 蓝题有这么恐怖吗 两次差分,第一次差分,前缀和求出增量数组,第二次求出原数组顺便更新答案 看题解之后……第二次差 ...
- P2680 [NOIP2015 提高组] 运输计划 (树上差分-边差分)
P2680 题目的大意就是走完m条路径所需要的最短时间(边权是时间), 其中我们可以把一条边的权值变成0(也就是题目所说的虫洞). 可以考虑二分答案x,找到一条边,使得所有大于x的路径都经过这条边(差 ...
- 树上差分——点差分裸题 P3128 [USACO15DEC]最大流Max Flow
讲解: https://rpdreamer.blog.luogu.org/ci-fen-and-shu-shang-ci-fen #include <bits/stdc++.h> #def ...
- HDU1529-Casher Emploryment(最最...最经典的差分约束 差分约束-最长路+将环变线)
A supermarket in Tehran is open 24 hours a day every day and needs a number of cashiers to fit its n ...
- [Python数据挖掘]第5章、挖掘建模(下)
四.关联规则 Apriori算法代码(被调函数部分没怎么看懂) from __future__ import print_function import pandas as pd #自定义连接函数,用 ...
- Certified Robustness to Adversarial Examples with Differential Privacy
目录 概 主要内容 Differential Privacy insensitivity Lemma1 Proposition1 如何令网络为-DP in practice Lecuyer M, At ...
- MindArmour差分隐私
MindArmour差分隐私 总体设计 MindArmour的Differential-Privacy模块,实现了差分隐私训练的能力.模型的训练主要由构建训练数据集.计算损失.计算梯度以及更新模型参数 ...
随机推荐
- [双体系练习]Java基础易错点
toCharArray()和split()的区别. toCharArray() 这个方法将一个字符串转换成一个字符数组.每个字符都会成为数组中的一个元素. 返回值:一个包含字符串中所有字符的char数 ...
- 【bug记录】AttributeError: 'CollectReport' object has no attribute 'description'
问题截图 问题原因 有完全重复用例,因为写用例的时候,为了图方便,直接复制的,还没来得及改,然后,用pytest运行的时候,就报这个错误了. 问题解决 去掉重复就行了
- 离线yum安装k8s(直接yum安装k8s)快速部署
问题:如何在没有离线环境上服务器yum安装k8s环境? 环境:准备一台互联网的服务器+离线的服务器 写的比较简便........ 1.互联网服务操作添加阿里云YUM的软件源 cat > /etc ...
- Qt编写地图综合应用59-经纬度坐标纠偏
一.前言 地图应用中都涉及到一个问题就是坐标纠偏的问题,这个问题的是因为根据地方规则保密性要求不允许地图厂商使用标准的GPS坐标,而是要用国家定义的偏移标准,或者在此基础上再做算法运算,所以这就出现了 ...
- 即时通讯技术文集(第28期):IM开发技术合集(Part1) [共18篇]
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第28 期. [- 1 -] 新手入门一篇就够:从零开发移动端IM [链接] http://ww ...
- 即时通讯安全篇(十一):IM聊天系统安全手段之传输内容端到端加密技术
本文由融云技术团队分享,原题"互联网通信安全之端到端加密技术",内容有较多修订和改动. 1.引言 在上篇<IM聊天系统安全手段之通信连接层加密技术>中,分享了关于通信连 ...
- Java中使用JFreeChart生成甘特图
引言 甘特图是一种流行的项目管理工具,用于显示项目的进度和任务分配.它通过条形图显示任务的开始和结束时间,使项目经理能够直观地了解项目的整体情况.在Java开发中,JFreeChart是一个强大的开源 ...
- C# 开发电子印章制作工具 -- 附下载程序
前言 本人在业余时间,开发了一款电子印章制作软件.印章制作软件看似简单,其实不然. 比如对椭圆形印章而言,要求公司名称中的每一个字间隔相等,要求字的方向与椭圆曲线垂直. 要满足这些条件,需要复杂的计算 ...
- Ellyn-Golang调用级覆盖率&方法调用链插桩采集方案
词语解释 Ellyn要解决什么问题? 在应用程序并行执行的情况下,精确获取单个用例.流量.单元测试走过的方法链(有向图).出入参数.行覆盖等运行时数据,经过一定的加工之后,应用在覆盖率.影响面评估.流 ...
- 彻底讲透Spring三级缓存,原理源码深度剖析!
一.前言循环依赖:就是N个类循环(嵌套)引用.通俗的讲就是N个Bean互相引用对方,最终形成闭环.在日常的开发中,我们都会碰到类似如下的代码 @Servicepublic class AService ...