特征转换之python代码
一、连续型变量
1.1 连续变量无量纲化
(1)无量纲化: 使不同规格尺度的数据转化统一规格尺度(将数据单位统一)
(2)无量纲化方法:标准化, 区间所方法
标准化: 将连续性变量转变为 均值0 标准差1 的变量

代码: #对 Amount字段--均值为0,方差为1标准化
from sklearn import preprocessing
std = preprocessing.StandardScaler() #StandardScaler
Amount = RFM['Amount'].values.reshape(-1,1)
std.fit(Amount)
RFM['Amount_std'] = std.transform(Amount)
RFM.head(5)
区间缩放法:把原始的连续型变量转换为范围在[a,b]或者 [0,1] 之间的变量
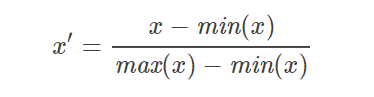
代码: #对 Amount字段--[0,1]区间归一化
from sklearn import preprocessing
MinMaxscaler = preprocessing.MinMaxscaler() #MinMaxscaler
Amount = RFM['Amount'].values.reshape(-1,1)
MinMaxscaler.fit(Amount) #拟合(训练)
RFM['Amount_range'] = MinMaxscaler.transform(Amount)
RFM.head(5)
1.2 连续变量数据变换
数据变换:通过函数变换改变原始数据的分布
目 的: 数据从无关系 -> 有关系
呈偏态分布-->变换后差异拉开
让数据符合模型理论所需要的假设,然后对其分析,例如:变换后数据呈正态分布
数据变化方法:logX,Ine 等 对数函数变换 x′=ln(x)x′=ln(x)
box-cox 变换 :自动寻找最佳正态分布变换函数的方法

代码1: #对 Amount字段--log 变换
import numpy as np
RFM['Amount_log'] = np.log(RFM['Amount'])
RFM,head(5)
代码2: #对 Amount字段--sqrt (平方根) 变换
import numpy as np
RFM['Amount_sqrt'] = np.sqrt(RFM['Amount'])
RFM,head(5)
1.3 连续变量离散化
目的:方便探索数据相关性
减少异常数据对模型的干扰
为模型引入非线性,提升模型预测能力
离散后,可进行特征交叉组合,又M+N 变成 M*N
数据离散化方法:
非监督离散方法:
自定义规则,
等宽方法,
等频/等深方法
非监督离散方法:
#对 Amount字段--自定义区间 离散化
cut_points = [0,200,500,800,1000]
RFM['Amount_bin'] = pd.cut(RFM['Amount'],bin = cut_points)
RFM,head(5)
#对 Amount字段--等宽 离散化
RFM['Amount_width_bin'] = pd.cut(RFM.Amount,20) #分成20等分
RFM,head(5)
grouped = RFM.groupby('Amount_width_bin')
grouped['CardID'].count()
#对 Amount字段--等深 离散化
RFM['Amount_depth_bin'] = pd.qcut(RFM.Amount,5) #分成5人的等分约20%
RFM,head(5)
grouped = RFM.groupby('Amount_depth_bin')
grouped['CardID'].count()
有监督离散方法:决策树 离散化后的目标分类纯度最高(对目标有很好的区分能力) 一种特殊的离散化方法: 二值化: 把连续型变量分割为0/1(是/否) 例如:是否大于18岁(是/否) Rounding(取整): 本质上时一种类似‘等距方法’的离散
二、类别变量编码
类别变量编码:
类别型变量—-编码成—> 数值型变量
目的:
机器学习算法 无法处理类别型变量,必须转换为数值型变量
一定程度起到了扩充特征的作用(构造了新的特征)
one-hot encoding 独热编码
dummy encoding 哑变量编码
label-encoding 标签编码
count-Encoding 频数编码 (可以去量纲化,秩序,归一化)
Target encoding 二分类 用目标变量中的某一类的比例来编码
代码:
import pandas as pd #导入的数据源于 特征构造
trade = pd.read_csv('./data/transaction.txt')
trade['Date'] = pd.to_datetime(trade['Date'])
RFM = trade.groupby('CardID').egg({'Date':'max','CardID':'count','Amount':'sum'})
RFM.head()
--------------Onehot 编码(独热编码)使用pandas------------------
onehot = pd.get_dummies(RFM['CardID']),drop_first = False,prefix = 'Freq'
onehot.head()
from sklearn import preprocessing #使用sklearn 导入OneHotEncoder
onehot = preprocessing.OneHotEncoder() #OneHotEncoder
Freq = RFM['CardID'].values.reshape(-1,1)
onehot.fit(Freq)
Freq_onehot = onehot.transform(Freq).toarray()
Freq_onehot
df = pd.DataFrame(Freq_onehot) #将array 转为pandas 的dataframe
df.head()
三、时间型、日期型变量转换
代码:
import pandas as pd
data = pd.DataFrame({'data_time':pd.date_range('1/1/2017 00:00:00',period = 12,freq = 'H'),'data':pd.date_range('2017-1-1',period = 12,freq = 'M')
})
■ data:提取日期型和时间型的特征变量
data['year']= data['data_time'].dt.year
data['month'] = data['data_time'].dt.month
data['day'] = data['data_time'].dt.day
data['hour'] = data['data_time'].dt.hour
data['minute'] = data['data_time'].dt.minute
data['second'] = data['data_time'].dt.second
data['quarter'] = data['data_time'].dt.quarter
data['week'] = data['data_time'].dt.week
data['yearmonth'] = data['data_time'].dt.strftime('%Y-%m')
data['halfyear'] = data['data_time'].mapa(lambda d:'H' if d.month <= 6 else 'H2')
■ data:转换为相对时间特征
import datetime
data['deltaDayToToday'] = (datetime.date.today()-data['date'].dt.date).dt.days #距离今天的间隔(天数)
data['deltaMonthToToday'] = datetime.date.today().month - data['date'].dt.month #距离今天的间隔(月数)
data['daysOfyear'] = data['date'].map(lambda d:366 if d.is_leap_year els 365) #一年过去的进度
data['rateOfyear'] = data['date'].dt.dayofyear/data['daysOfyear']
data.head()
四、 缺失值处理
删除缺失值记录
缺失值替换:
用0替换
平均数替换
众数替换
预测模型替换
构造NaN encoding编码 :
构造一个新的字段来标识是否有缺失(1/0) 任何时候都可使用
import pandas as pd
titanic = pd.read_csv('./data/titanic.csv')
titanic.info()
age_mean = round(titanic['Age'].mean()) #对缺失值进行填充
titanic['Age'].fillna(age_mean,inplace = True) #填充平均年龄
titanic.info()
titanic = pd.read_csv('./data/titanic.csv') #构造缺失值的标志变量(0/1)
titanic.info()
titanic['Age_ismissing'] = 0
titanic.loc[titanic['Age'].isnull(),'Age_ismissing'] = 1
titanic['Age_ismissing'].value_counts()
五、 特征组合
目的:
构造更多更好的特征,提升模型精度(例如:地球仪的经纬密度)
方法:
多个连续变量: 加减乘除运算
多个类别型变量: 所有值交叉组合
import pandas as pd
titanic = pd.read_csv('./data/titanic.csv')
titanic.head()
# 组合特征
titanic['Sex_pclass_combo'] = titanic['Sex']+'_pclass_'+titanic['Pclass'].astype(str)
titanic.Sex_pclass_combo.value_counts()
# onehot编码
Sex_pclass_combo = pd.get_dummies['Sex_pclass_combo'],drop_first = False,prefix = 'onehot'
Sex_pclass_combo.head()
特征转换之python代码的更多相关文章
- 谁动了我的特征?——sklearn特征转换行为全记录
目录 1 为什么要记录特征转换行为?2 有哪些特征转换的方式?3 特征转换的组合4 sklearn源码分析 4.1 一对一映射 4.2 一对多映射 4.3 多对多映射5 实践6 总结7 参考资料 1 ...
- 孤荷凌寒自学python第十四天python代码的书写规范与条件语句及判断条件式
孤荷凌寒自学python第十四天python代码的书写规范与条件语句及判断条件式 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 在我学习过的所有语言中,对VB系的语言比较喜欢,而对C系和J系 ...
- 机器学习完整过程案例分布解析,python代码解析
所谓学习问题,是指观察由n个样本组成的集合,并依据这些数据来预測未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.如果如今有一个O2O领域的 ...
- Python代码编码规范
目录 1. Introduction 介绍 2. A Foolish Consistency is the Hobgoblin of Little Minds 尽信书,则不如无书 3. Code la ...
- 【原创】一段简短的读取libglade的UI文件的Python代码
准备写一个将Glade/GtkBuilder等格式的UI文件转换成C++代码的python程序 首先完成的是将LIBGlade格式读取至内存中 #!/usr/bin/env python # -*- ...
- python代码风格指南:pep8 中文翻译
摘要 本文给出主Python版本标准库的编码约定.CPython的C代码风格参见PEP7.本文和PEP 257 文档字符串标准改编自Guido最初的<Python Style Guide&g ...
- 无需操作系统和虚拟机,直接运行Python代码
Josh Triplett以一个“笑点”开始了他在PyCon 2015上的演讲:移植Python使其无需操作系统运行:他和他的英特尔同事让解释器能够在GRUB引导程序.BIOS或EFI系统上运行.连演 ...
- Python 代码实现模糊查询
Python 代码实现模糊查询 1.导语: 模糊匹配可以算是现代编辑器(如 Eclipse 等各种 IDE)的一个必备特性了,它所做的就是根据用户输入的部分内容,猜测用户想要的文件名,并提供一个推荐列 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 神经网络BP算法C和python代码
上面只显示代码. 详BP原理和神经网络的相关知识,请参阅:神经网络和反向传播算法推导 首先是前向传播的计算: 输入: 首先为正整数 n.m.p.t,分别代表特征个数.训练样本个数.隐藏层神经元个数.输 ...
随机推荐
- 记一次cenos7安装nginx
安装依赖 yum -y install gcc gcc-c++ make libtool zlib zlib-devel openssl openssl-devel pcre pcre-devel 下 ...
- Grid 网格布局备忘录
概述 网格布局(Grid)是最强大的 CSS 布局方案. 它将网页划分成一个个网格,可以任意组合不同的网格,做出各种各样的布局. Grid 布局与 Flex 布局有一定的相似性,都可以指定容器内部多个 ...
- Vue开启Gzip
Vue配置 1.安装 npm install --save-dev compression-webpack-plugin@5.0.0 const CompressionWebpackPlugin = ...
- 【Java】关于Maven仓库地址
仓库 如果你没有配置阿里云仓库镜像源,可以到这里来找 https://mvnrepository.com/ 如果你配置了阿里云仓库镜像源,可以来这里找 https://developer.aliyun ...
- git log 常用方法
• git log --all 查看所有分支的历史• git log --all --graph 查看图形化的 log 地址• git log --oneline 查看单行的简洁历史.• git lo ...
- apache kylin的一些注意事项(解决kylin报错Storage schema reading not supported)
1.目前我所使用的kylin版本为2.6.2,有时在完成一次构建后会出现fail to locate kylin.properties的异常,如图所示 经排查,定位到kylin源码中的 org.apa ...
- Macos 安装md5sum、sha1sum、md5deep、sha1deep
一.安装md5sum和sha1sum 方法一:brew 安装 # brew install md5sha1sum 方法二:编译安装 源码下载地址:http://www.microbrew.org/to ...
- Qt/C++地图坐标纠偏/地球坐标系/火星坐标系/百度坐标系/互相转换/离线函数
一.前言说明 为什么需要地球坐标纠偏这个功能,因为国家安全需要,不允许使用国际标准的地球坐标系,也并不是咱们这边这样,很多国家都是这样处理的,就是本国的地图经纬度坐标都是按照国家标准来的,所以就需要一 ...
- Intellij IDEA如何导入 Maven 项目
Intellij IDEA如何导入 Maven 项目 选择 File->Import Module,选择 Maven 模块路径,如下图所示: 选择"Import module from ...
- Windows应用开发-常用工具集推荐
.NET/WPF开发 Visual Studio 最新版本是VS2022,官网下载:Visual Studio 2022 IDE - 适用于软件开发人员的编程工具 VsColorOutput 控制台 ...