langchain0.3教程:聊天机器人进阶之方法调用
我们思考一个问题:大语言模型是否能帮我们做更多的事情,比如帮我们发送邮件。默认情况下让大模型帮我们发送邮件,大模型会这样回复我们:
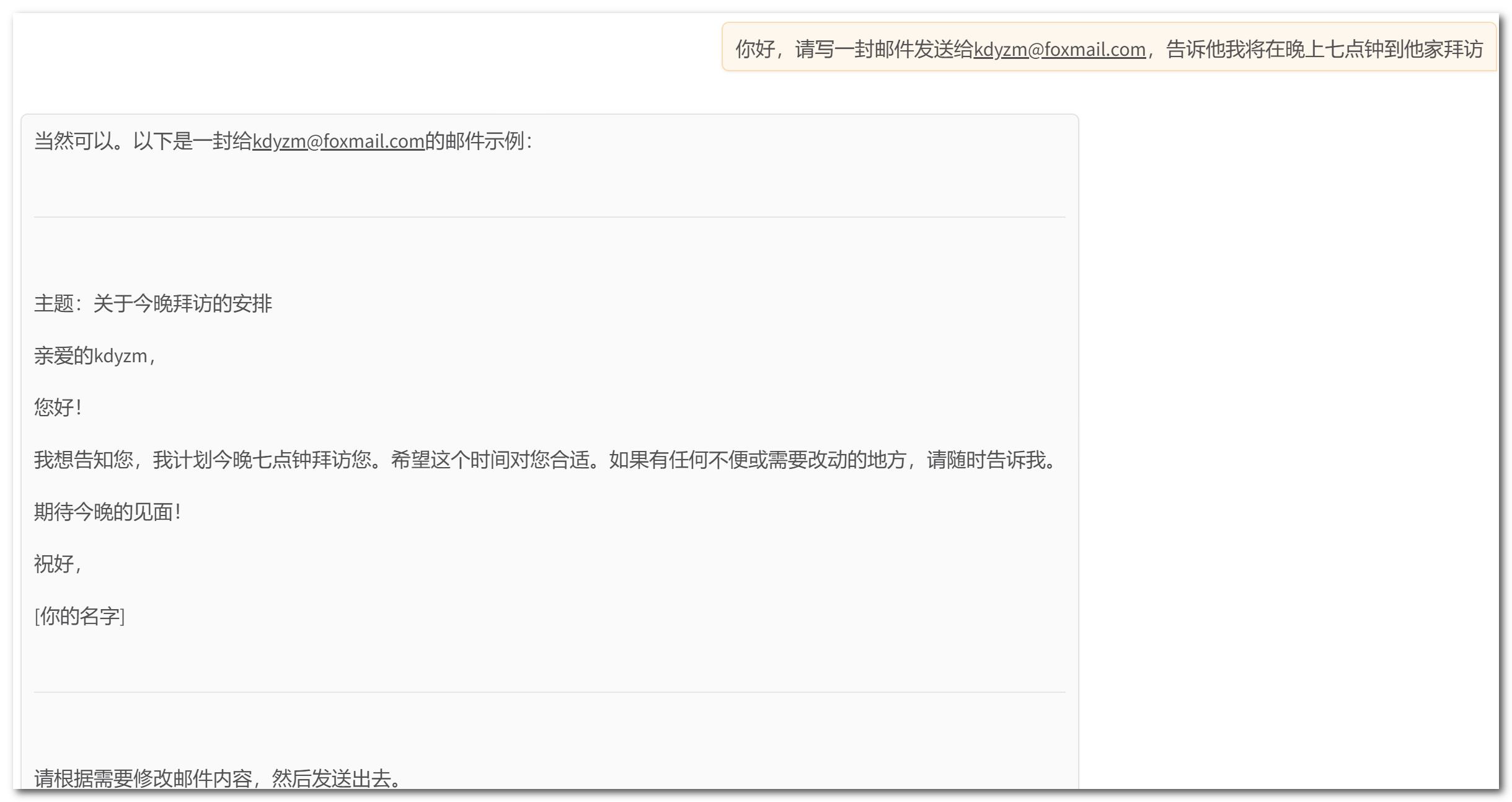
可以看到,大模型无法发送邮件,它只会帮我们生成一个邮件模板,然后让我们自己手动发送出去。如何让大模型拥有发送邮件的能力呢?这里就引入来了一个概念:function calling。
一、概念:Function calling
简单来说,Function calling让大语言模型拥有了调用外部接口的能力,使用这种能力,大模型能做一些比如实时获取天气信息、发送邮件等和现实世界交互的事情。
1、原理
在发送信息给大模型的时候,携带着“工具”列表,这些工具列表代表着大模型能使用的工具。当大模型遇到用户提出的问题时,会先思考是否应该调用工具解决问题,如果需要调用工具,和普通消息不同,这种情况下会返回“function_call”类型的消息,请求方根据返回结果调用对应的工具得到工具输出,然后将之前的信息加上工具输出的信息一起发送给大模型,让大模型整合起来综合判断给出结果。
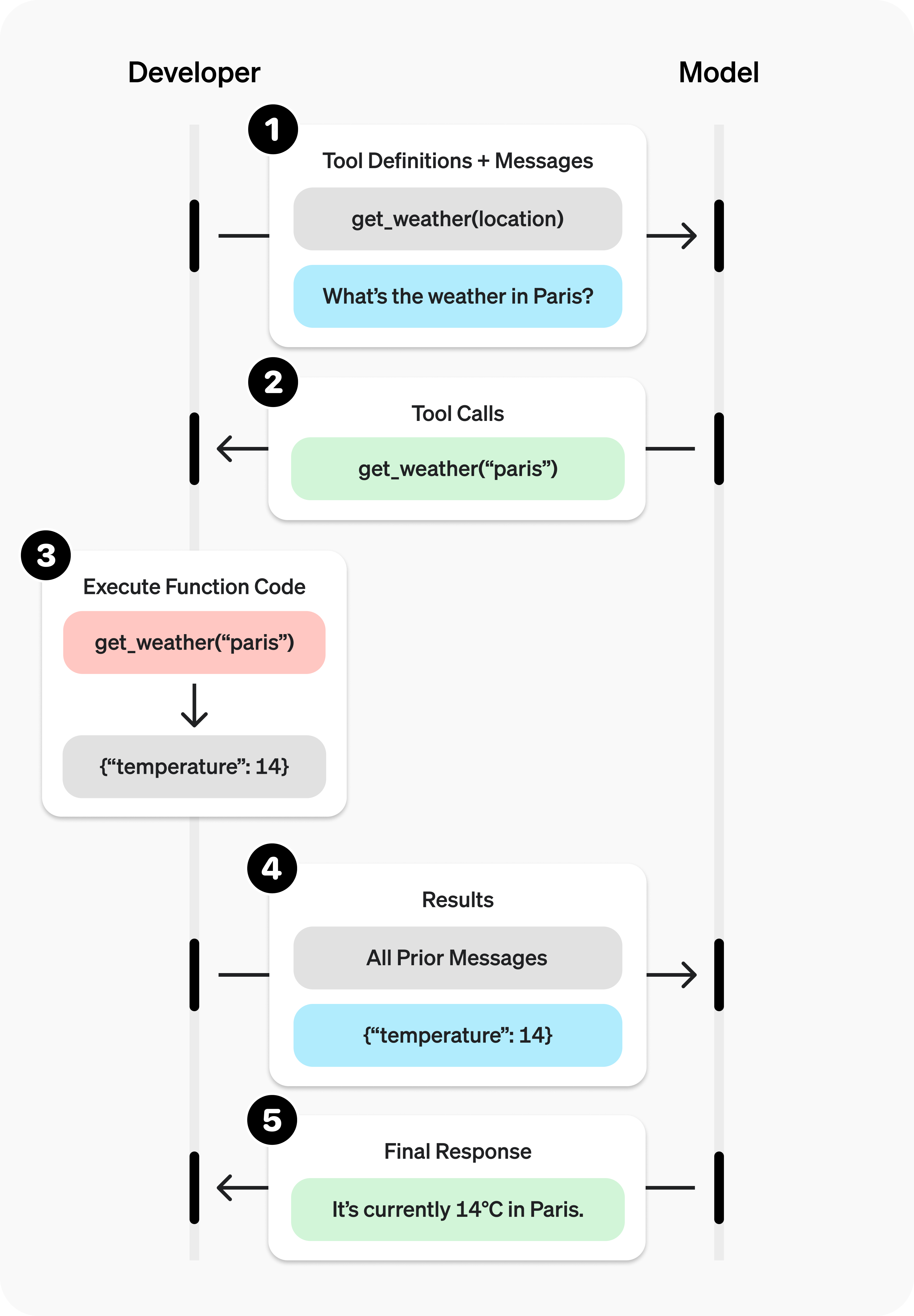
以获取天气信息为例,官网给出了获取天气的流程图
2、案例
OpenAI官网Function calling文档:https://platform.openai.com/docs/guides/function-calling?api-mode=responses&example=get-weather
文档中给了获取天气、发送邮件、搜索本地知识库这三个例子,以获取天气为例:
from openai import OpenAI
client = OpenAI()
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
}
},
"required": [
"location"
],
"additionalProperties": False
}
}]
response = client.responses.create(
model="gpt-4o",
input=[{"role": "user", "content": "What is the weather like in Paris today?"}],
tools=tools
)
print(response.output)
结果输出:
[{
"type": "function_call",
"id": "fc_12345xyz",
"call_id": "call_12345xyz",
"name": "get_weather",
"arguments": "{\"location\":\"Paris, France\"}"
}]
可以看到,使用OpenAI的官方API调用很繁琐,而且定义工具列表需要使用json格式的字符串,非常的不友好,lagnchain则解决了这些麻烦。
二、langchain中的Tool calling
langchain中的Function calling换了个更直接的名字:Tool calling,翻译过来叫做“工具调用”,实际上底层还是使用的Function calling。
Tools概念:https://python.langchain.com/docs/concepts/tools/
Tool calling概念:https://python.langchain.com/docs/concepts/tool_calling/
1、工具定义
定义工具很简单,使用装饰器@tool,比如定义两数相乘的工具如下:
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
可以看到,定义一个工具方法很简单,普通方法加上装饰器@tool即可(关于复杂方法后续再讲)。
工具定义完成,可以使用
print(
json.dumps(
multiply.args_schema.model_json_schema(),
indent=4,
ensure_ascii=False,
)
)
打印scheme信息:
{
"description": "Multiply two numbers.",
"properties": {
"a": {
"title": "A",
"type": "integer"
},
"b": {
"title": "B",
"type": "integer"
}
},
"required": [
"a",
"b"
],
"title": "multiply",
"type": "object"
}
2、工具调用
上面我们已经定义好了两数相乘的工具:
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
接下来使用携带该工具访问大模型:
# Tool 创建
tools = [multiply]
# Tool 绑定
model_with_tools = model.bind_tools(tools)
# Tool 调用
response = model_with_tools.invoke("2乘以2等于多少?")
输出大模型返回的function_tool信息:
print(json.dumps(response.tool_calls, indent=4))
结果如下所示:
[
{
"name": "multiply",
"args": {
"a": 2,
"b": 3
},
"id": "chatcmpl-tool-83c83e9537ae4820bc3b1123fec3570b",
"type": "tool_call"
}
]
它告诉我们要调用multiply方法,参数是a=2和b=3,如何调用呢?
3、工具执行
大模型已经告诉我们要执行的方法以及调用的参数了,接下来如何执行呢?
第一步:转换tool列表为字典
tool_dic = {tool.name: tool for tool in tools}
第二步:依次执行tool_call列表中的方法
for tool_call in response.tool_calls:
selected_tool = tool_dic[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call)
print(type(tool_msg))
这样就可以执行目标方法了。注意这里返回的tool_msg信息类型是ToolMessage。
接下来需要将上下文信息带着最后输出的工具输出的信息一起打包给大模型,让大模型整合结果输出给出最终答案。
4、整合到大模型
调用完工具之后需要将结果告诉大模型,让大模型综合上下文得到后续答案。如何告诉大模型呢?在上一篇文章《大模型开发之langchain0.3(二):构建带有记忆功能的聊天机器人》中告诉大模型上下文,也即是历史记录的方法就是构造Message列表,上一步工具执行的结果返回类型是ToolMessage,我们将它加入列表即可;最后将message列表一起发送给大模型,让大模型给出答案。
完整代码如下所示:
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b."""
print("multiply 方法被执行")
return a * b
model = init_chat_model("gpt-3.5-turbo")
# Tool 创建
tools = [multiply]
# Tool 绑定
model_with_tools = model.bind_tools(tools)
# Tool 调用
history = [HumanMessage("2乘以3等于多少?")]
ai_message = model_with_tools.invoke(history)
history.append(ai_message)
tool_dic = {tool.name: tool for tool in tools}
for tool_call in ai_message.tool_calls:
selected_tool = tool_dic[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call)
history.append(tool_msg)
ai_message = model_with_tools.invoke(history)
print(ai_message.content)
if __name__ == '__main__':
pass
结果:
multiply 方法被执行
2乘以3等于6。
三、整合gradio
为了更直观的查看工具调用的情况,将本节内容整合到gradio是个不错的选择,同时需要兼容上篇文章《大模型开发之langchain0.3(二):构建带有记忆功能的聊天机器人》中记忆功能、Context Window限制功能,由于使用了工具调用,暂时没想好如何实现工具调用显示和正文部分流式输出的组合。
1、代码整合
核心点在于如何显示方法调,可以参考文档:https://www.gradio.app/docs/gradio/chatbot#demos 案例中的chatbot_with_tools 章节。
from gradio import ChatMessage
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, AIMessage, trim_messages
from langchain_core.tools import tool
import gradio as gr
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b."""
print("multiply 方法被执行")
return a * b
model = init_chat_model("gpt-3.5-turbo")
# Tool 创建
tools = [multiply]
# Tool 绑定
model_with_tools = model.bind_tools(tools)
trimmer = trim_messages(
max_tokens=300,
strategy="last",
token_counter=model,
include_system=True,
allow_partial=False,
start_on="human",
)
def response(input_message, gradio_history):
# Tool 调用
history = [HumanMessage(i["content"]) if i["role"] == 'user' else AIMessage(i["content"]) for i in gradio_history]
history.append(HumanMessage(input_message))
local_gradio_history = list()
ai_message = model_with_tools.invoke(trimmer.invoke(history))
if ai_message.tool_calls:
tool_dic = {tool_item.name: tool_item for tool_item in tools}
for tool_call in ai_message.tool_calls:
tool_name = tool_call["name"].lower()
selected_tool = tool_dic[tool_name]
tool_msg = selected_tool.invoke(tool_call)
history.append(tool_msg)
local_gradio_history.append(
ChatMessage(
role="assistant",
content=f"tool '{tool_name}' invoke result is {tool_msg}",
metadata={"title": f"️ Used tool '{tool_name}'"},
)
)
yield local_gradio_history
ai_message = model_with_tools.invoke(trimmer.invoke(history))
local_gradio_history.append(
ChatMessage(
role="assistant",
content=ai_message.content,
)
)
yield local_gradio_history
demo = gr.ChatInterface(
fn=response,
type="messages",
flagging_mode="manual",
flagging_options=["Like", "Spam", "Inappropriate", "Other"],
save_history=True,
)
if __name__ == '__main__':
demo.launch()
2、运行界面
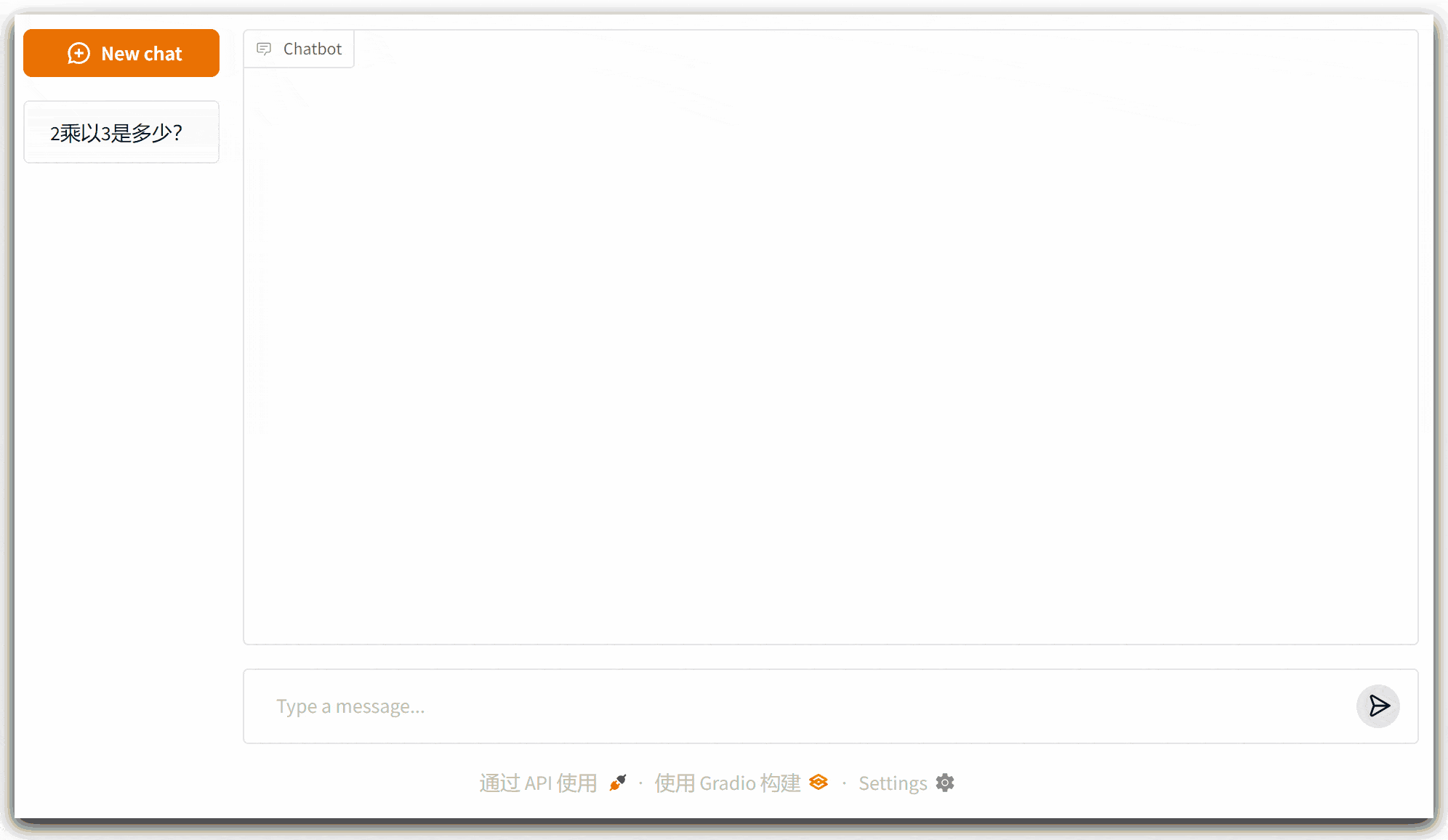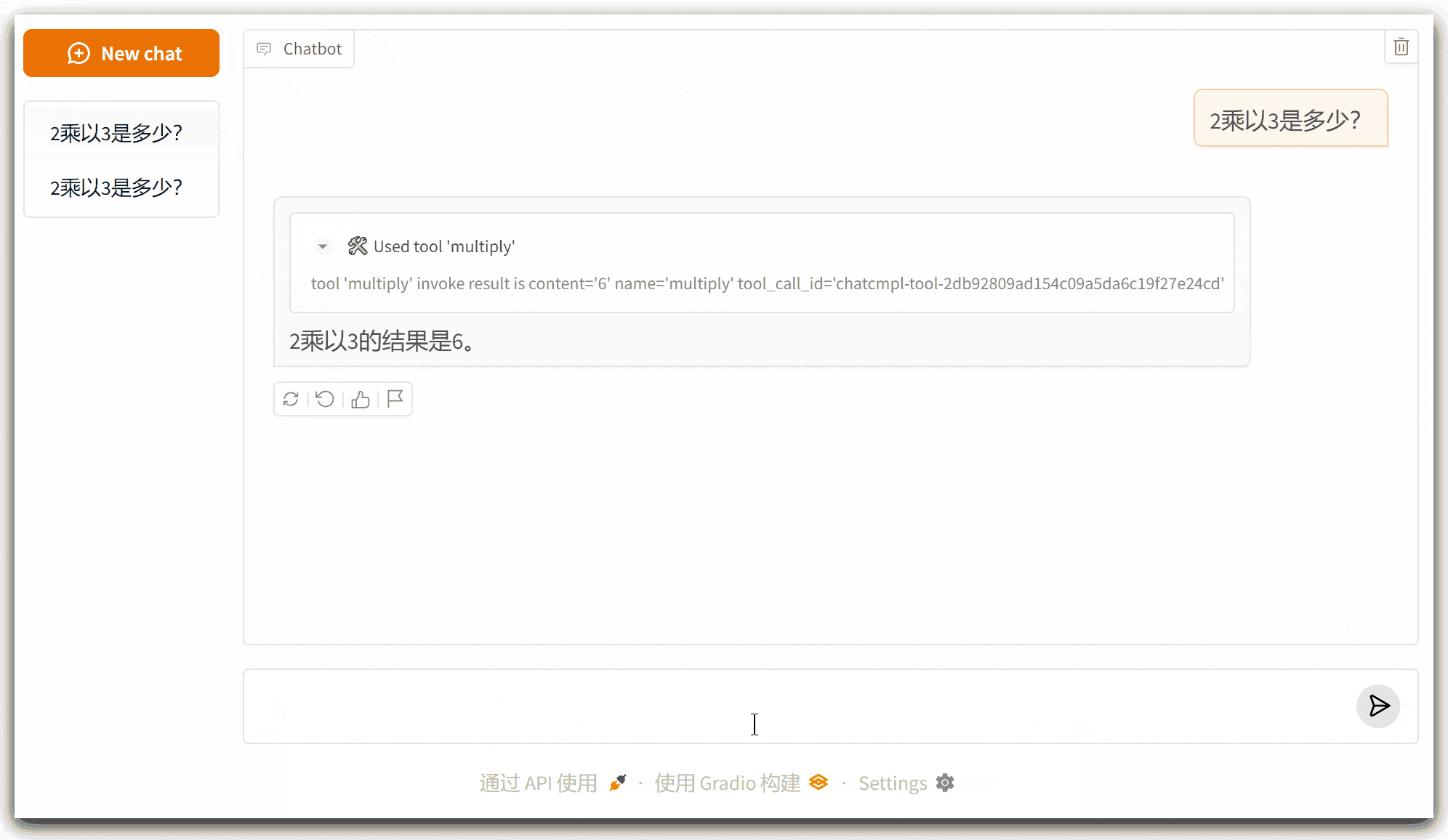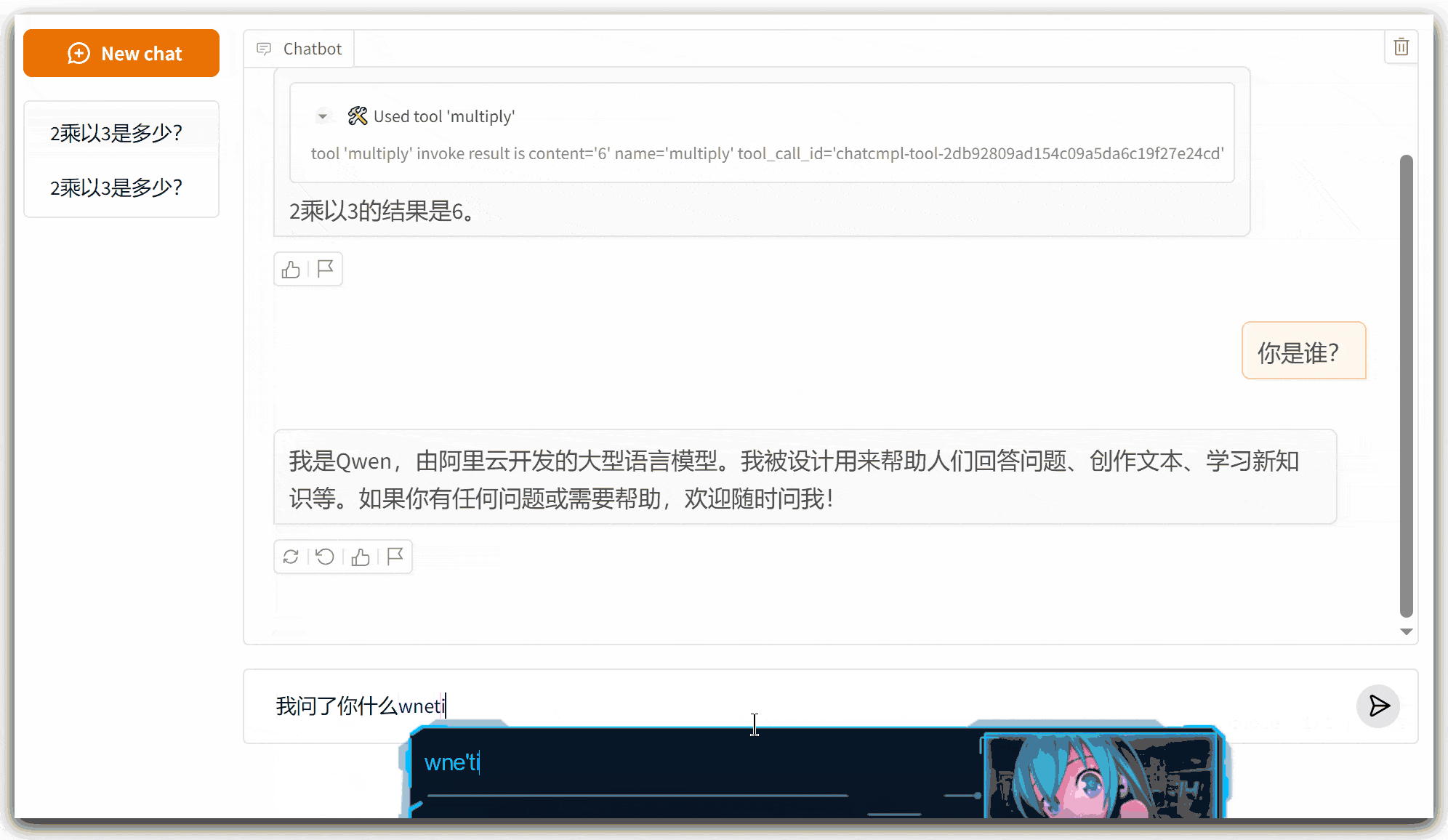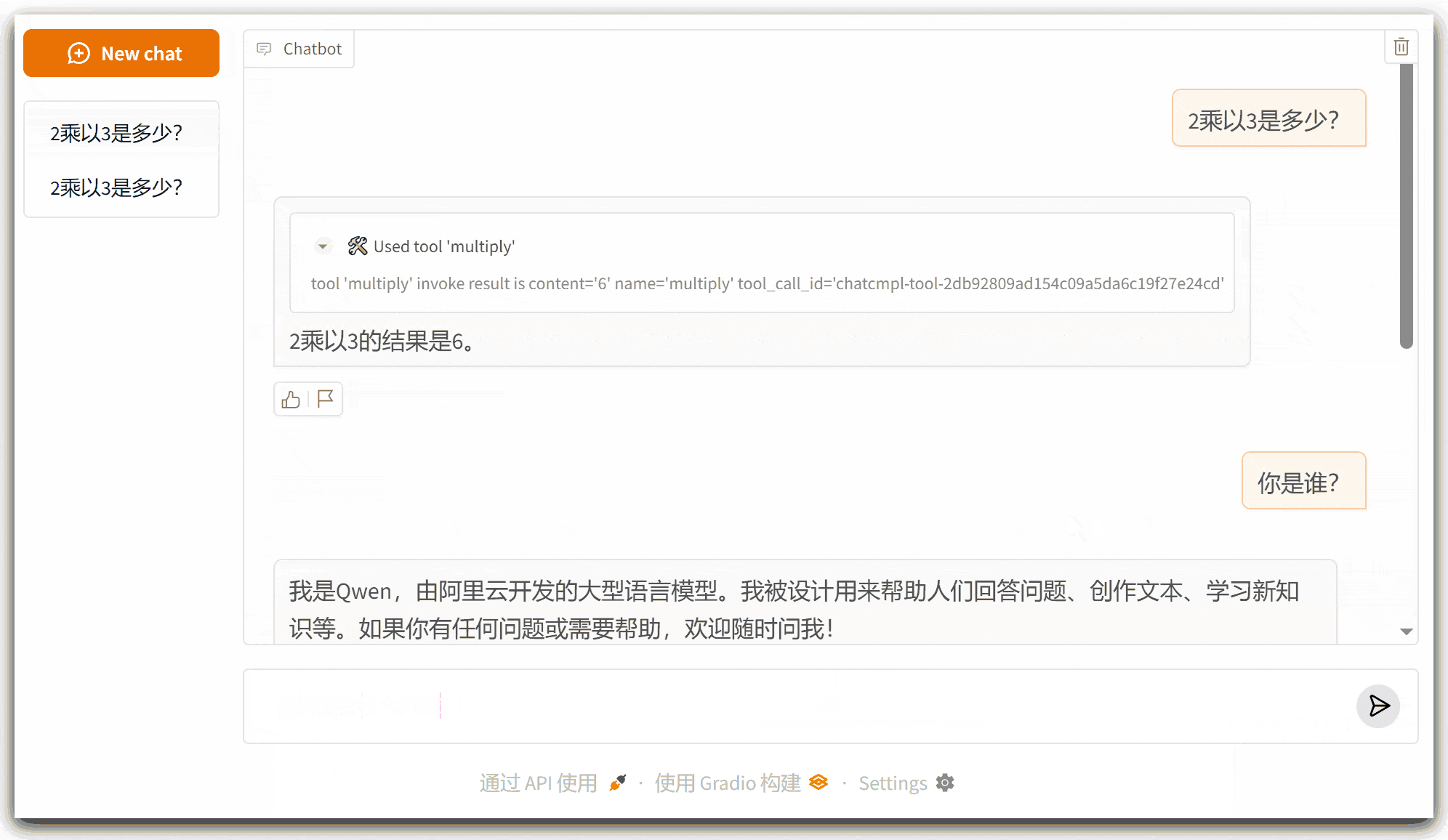
可以看到,大模型会根据用户请求的问题决定是否要调用相关的工具;新增加的方法调用正常发挥作用,同时以前的上下文记忆功能也没有受到影响。
四、注意事项
注意,并非所有的大模型都支持function_call,不支持function_call的大模型输出返回的AIMessage的tool_calls字段一直是空的。
最后,欢迎关注我的博客呀~
langchain0.3教程:聊天机器人进阶之方法调用的更多相关文章
- 笔记5:QQ群聊天机器人
之前经常在别人群里看到有自动回复消息的机器人. 功能有好多,可以玩各种游戏.觉得还蛮有意思的.. 于是就去请教别人怎么弄得,但是他们都说得好复杂,好高大上,无非就是不想让别人弄 本人是个不会轻易放弃的 ...
- Rasa Stack:创建支持上下文的人工智能助理和聊天机器人教程
相关概念 Rasa Stack 是一组开放源码机器学习工具,供开发人员创建支持上下文的人工智能助理和聊天机器人: • Core = 聊天机器人框架包含基于机器学习的对话管理 • NLU = 用于自然语 ...
- Python进阶开发之网络编程,socket实现在线聊天机器人
系列文章 √第一章 元类编程,已完成 ; √第二章 网络编程,已完成 ; 本文目录 什么是socket?创建socket客户端创建socket服务端socket工作流程图解socket公共函数汇总实战 ...
- 【python】使用python十分钟创建个人聊天机器人教程
以青云客和图灵机器人接口示范python创建个人聊天机器人教程 一.以青云客聊天机器人为例示范get请求 官方网址:http://api.qingyunke.com/ 1.接入指引 请求地址 http ...
- 使用Botkit和Rasa NLU构建智能聊天机器人
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 我们每天都会听到关于有能力涉及旅游.社交.法律.支持.销售等领域的新型机器人推出的新闻.根据我最后一次查阅的数据,单单Facebook Me ...
- 聊天机器人(chatbot)终极指南:自然语言处理(NLP)和深度机器学习(Deep Machine Learning)
在过去的几个月中,我一直在收集自然语言处理(NLP)以及如何将NLP和深度学习(Deep Learning)应用到聊天机器人(Chatbots)方面的最好的资料. 时不时地我会发现一个出色的资源,因此 ...
- 用python玩微信(聊天机器人,好友信息统计)
1.用 Python 实现微信好友性别及位置信息统计 这里使用的python3+wxpy库+Anaconda(Spyder)开发.如果你想对wxpy有更深的了解请查看:wxpy: 用 Python 玩 ...
- ChatterBot聊天机器人呢结构(五):ChatterBot对话流程
原文地址:http://www.bugingcode.com/blog/ChatterBot_Dialogue_process.html 创建机器人 部署机器人的各种属性,根据前面的章节里聊天机器人的 ...
- 【翻译】用AIML实现的Python人工智能聊天机器人
前言 用python的AIML包很容易就能写一个人工智能聊天机器人. AIML是Artificial Intelligence Markup Language的简写, 但它只是一个简单的XML. 下面 ...
- 3.C#面向对象基础聊天机器人
基于控制台的简单版的聊天机器人,词库可以自己添加. 聊天机器人1.0版本 源码如下: using System; using System.Collections.Generic; using Sys ...
随机推荐
- JAVA8 函数式编程(1)- Lambda表达式
1 简介 简洁的代码就能处理大型数据集合,让复杂的集合处理算法高效的运行在多核CPU上. 面向对象编程是对数据进行抽象,而函数式编程是对行为进行抽象,能编写出更易读的代码--这种代码更多地表达了业务逻 ...
- SpringCloud(八) - 自定义token令牌,鉴权(注解+拦截器),参数解析(注解+解析器)
1.项目结构介绍 项目有使用到,redis和swagger,不在具体介绍: 2.手动鉴权和用户信息参数获取(繁杂,冗余) 2.1用户实体类 /** * Created On : 4/11/2022. ...
- mac sublime text3-快捷键
cmd+n 新建页面 cmd+数字键 切换到对应页面 cmd+p 搜索跳转到对应页 cmd+w 关闭页面 cmd+j 合并一行 cmd+d 选中当前单词,继续敲可以选中多个 cmd+l 选中当前行 c ...
- Linux操作系统基础知识
一.输入法的切换Application ----> System Tools ----> Settings ----> Rejino&language ----> In ...
- VulNyx - Internal
扫描发现有三个端口 basic验证需要用户名密码登录 访问80端口 \URLFinder 发现有个internal的php文件 看看有无任意文件读取漏洞 发现没有回显 但是总感觉怪怪的 应该是有啥东西 ...
- dart中Map类型详解
Map是什么 map类型的数据都是由key和value两个值组成, key是唯一的,value不必唯一,读写数据都是通过key进行. key和value可以是任意类型数据. Map的基本使用 01== ...
- 你的边比较松弛:最短路的 Bellman-Ford 和 SPFA 方法
Dijkstra 的局限性 在带权图的最短路径问题中,我们的目标是从一个起点出发,找到到达其他所有节点的最短路径.无论是交通导航中的最短耗时路线,还是金融网络中的最小成本路径,这一问题的核心始终是如何 ...
- 割以咏志:Stoer–Wagner 算法求解全局最小割
全局最小割问题(Global Min-Cut Problem)是图论中的一个经典问题,旨在通过切割图中的边来划分图的顶点集合.具体来说,给定一个加权无向图 $ G = (V, E) $,图中每条边 $ ...
- Deepseek学习随笔(6)--- API 开发与自动化
获取 API Key 要开始使用 DeepSeek 的 API,你首先需要获取 API Key: 登录 DeepSeek 控制台 . 进入 API 管理 页面,生成 API Key. API 调用示例 ...
- 怎么证明二元函数的极限是多少?& 怎么证明二元函数的极限不存在?
怎么证明二元函数的极限是多少:https://zhaokaifeng.com/16589/ 怎么证明二元函数的极限不存在:https://zhaokaifeng.com/16600/