第9.1讲、Tiny Encoder Transformer:极简文本分类与注意力可视化实战
Tiny Encoder Transformer:极简文本分类与注意力可视化实战
项目简介
本项目实现了一个极简版的 Transformer Encoder 文本分类器,并通过 Streamlit 提供了交互式可视化界面。用户可以输入任意文本,实时查看模型的分类结果及注意力权重热力图,直观理解 Transformer 的内部机制。项目采用 HuggingFace 的多语言 BERT 分词器,支持中英文等多种语言输入,适合教学、演示和轻量级 NLP 应用开发。
主要功能
- 多语言支持:集成 HuggingFace
bert-base-multilingual-cased分词器,支持 100+ 语言。 - 极简 Transformer 结构:自定义实现位置编码、单层/多层 Transformer Encoder、分类头,结构清晰,便于学习和扩展。
- 注意力可视化:可实时展示输入文本的注意力热力图和每个 token 被关注的占比,帮助理解模型关注机制。
- 高效演示:训练时仅用 AG News 数据集的前 200 条数据,并只训练 10 个 batch,保证页面加载和交互速度。
代码结构与核心实现
1. 数据加载与预处理
使用 HuggingFace datasets 库加载 AG News 数据集,并用 BERT 分词器对文本进行编码:
from datasets import load_dataset
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
dataset = load_dataset("ag_news")
dataset["train"] = dataset["train"].select(range(200)) # 只用前200条数据
def encode(example):
tokens = tokenizer(
example["text"],
padding="max_length",
truncation=True,
max_length=64,
return_tensors="pt"
)
return {
"input_ids": tokens["input_ids"].squeeze(0),
"label": example["label"]
}
encoded_train = dataset["train"].map(encode)
2. Tiny Encoder 模型结构
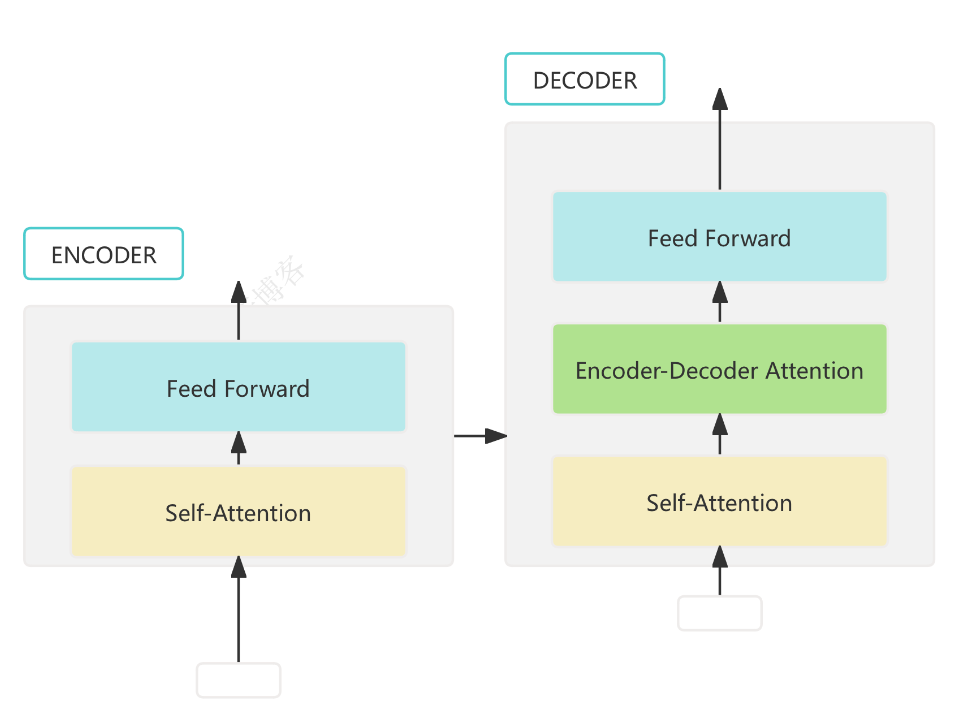
模型包含词嵌入层、位置编码、若干 Transformer Encoder 层和分类头,支持输出每层的注意力权重:
import torch.nn as nn
class PositionalEncoding(nn.Module):
# ... 位置编码实现,见下文详细代码 ...
class TransformerEncoderLayerWithTrace(nn.Module):
# ... 支持 trace 的单层 Transformer Encoder,见下文详细代码 ...
class TinyEncoderClassifier(nn.Module):
# ... 嵌入、位置编码、编码器堆叠、分类头,见下文详细代码 ...
3. 训练流程
采用交叉熵损失和 Adam 优化器,仅训练 10 个 batch,极大提升演示速度:
import torch.optim as optim
from torch.utils.data import DataLoader
train_loader = DataLoader(encoded_train, batch_size=16, shuffle=True)
model = TinyEncoderClassifier(...)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
model.train()
for i, batch in enumerate(train_loader):
if i >= 10: # 只训练10个batch
break
input_ids = batch["input_ids"]
labels = batch["label"]
logits, _ = model(input_ids)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
4. Streamlit 可视化界面
- 提供文本输入框,用户可输入任意文本。
- 实时推理并展示分类结果。
- 可视化 Transformer 第一层各个注意力头的权重热力图和每个 token 被关注的占比(条形图)。
import streamlit as st
import seaborn as sns
import matplotlib.pyplot as plt
user_input = st.text_input("请输入文本:", "We all have a home called China.")
if user_input:
# ... 推理与注意力可视化代码,见下文详细代码 ...
训练与推理流程详解
数据加载与预处理
- 加载 AG News 数据集,仅取前 200 条样本。
- 用多语言 BERT 分词器编码文本,填充/截断到 64 长度。
模型结构
- 词嵌入层将 token id 映射为向量。
- 位置编码为每个 token 添加可区分的位置信息。
- 堆叠若干 Transformer Encoder 层,支持输出注意力权重。
- 分类头对第一个 token 的输出做分类(类似 BERT 的 [CLS])。
训练流程
- 损失函数为交叉熵,优化器为 Adam。
- 只训练 1 个 epoch,且只训练 10 个 batch,保证演示速度。
推理与可视化
- 用户输入文本,模型输出预测类别编号。
- 可视化注意力热力图和每个 token 被关注的占比,直观展示模型关注点。
适用场景
- Transformer 原理教学与可视化演示
- 注意力机制理解与分析
- 多语言文本分类任务的快速原型开发
- NLP 课程、讲座、实验室演示
完整案例说明:
Tiny Encoder
1. 代码主要功能
该脚本实现了一个基于 Transformer Encoder 的文本分类模型,并通过 Streamlit 提供了可视化界面,
支持输入一句话并展示模型的分类结果及注意力权重热力图。
2. 主要模块说明
- Tokenizer 初始化:
- 使用 HuggingFace 的多语言 BERT Tokenizer 对输入文本进行分词和编码。
- 模型结构:
- 包含词嵌入层、位置编码、若干 Transformer Encoder 层(带注意力权重 trace)、分类器。
- 数据处理与训练:
- 加载 AG News 数据集,编码文本,训练模型并保存。
- 若已存在训练好的模型则直接加载。
- Streamlit 可视化:
- 提供文本输入框,实时推理并展示分类结果。
- 可视化 Transformer 第一层各个注意力头的权重热力图。
3. 数据流向说明
- 输入:
- 用户在 Streamlit 网页输入一句英文(或多语言)文本。
- 分词与编码:
- Tokenizer 将文本转为固定长度的 token id 序列(input_ids)。
- 模型推理:
- input_ids 输入 TinyEncoderClassifier,经过嵌入、位置编码、若干 Transformer 层,输出 logits(分类结果)和注意力权重(trace)。
- 分类输出:
- 取 logits 最大值作为类别预测,显示在网页上。
- 注意力可视化:
- 取第一层注意力权重,分别绘制每个 head 的热力图,帮助理解模型关注的 token 关系。
4. 适用场景
- 适合教学、演示 Transformer 注意力机制和文本分类原理。
- 可扩展用于多语言文本分类任务。
import math
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from transformers import AutoTokenizer
from datasets import load_dataset
import streamlit as st
import seaborn as sns
import matplotlib.pyplot as plt
# ============================
# 位置编码模块
# ============================
class PositionalEncoding(nn.Module):
"""
位置编码模块:为输入的 token 序列添加可区分位置信息。
使用正弦和余弦函数生成不同频率的编码。
"""
def __init__(self, d_model, max_len=512):
super().__init__()
# 创建一个 (max_len, d_model) 的全零张量,用于存储位置编码
pe = torch.zeros(max_len, d_model)
# 生成位置索引 (max_len, 1)
position = torch.arange(0, max_len).unsqueeze(1)
# 计算每个维度对应的分母项(不同频率)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
# 偶数位置用 sin,奇数位置用 cos
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 增加 batch 维度,形状变为 (1, max_len, d_model)
pe = pe.unsqueeze(0)
# 注册为 buffer,模型保存时一同保存,但不是参数
self.register_buffer('pe', pe)
def forward(self, x):
"""
输入:x,形状为 (batch, seq_len, d_model)
输出:加上位置编码后的张量,形状同输入
"""
return x + self.pe[:, :x.size(1)]
# ============================
# 单层 Transformer Encoder,支持输出注意力权重
# ============================
class TransformerEncoderLayerWithTrace(nn.Module):
"""
单层 Transformer Encoder,支持输出注意力权重。
包含多头自注意力、前馈网络、残差连接和层归一化。
"""
def __init__(self, d_model, nhead, dim_feedforward):
super().__init__()
# 多头自注意力层
self.self_attn = nn.MultiheadAttention(d_model, nhead, batch_first=True)
# 前馈网络第一层
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(0.1)
# 前馈网络第二层
self.linear2 = nn.Linear(dim_feedforward, d_model)
# 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout 层
self.dropout1 = nn.Dropout(0.1)
self.dropout2 = nn.Dropout(0.1)
def forward(self, src, trace=False):
"""
前向传播。
参数:
src: 输入序列,形状为 (batch, seq_len, d_model)
trace: 是否返回注意力权重
返回:
src: 输出序列
attn_weights: 注意力权重(如果 trace=True)
"""
# 多头自注意力,attn_weights 形状为 (batch, nhead, seq_len, seq_len)
attn_output, attn_weights = self.self_attn(src, src, src, need_weights=trace)
# 残差连接 + 层归一化
src2 = self.dropout1(attn_output)
src = self.norm1(src + src2)
# 前馈网络
src2 = self.linear2(self.dropout(torch.relu(self.linear1(src))))
# 残差连接 + 层归一化
src = self.norm2(src + self.dropout2(src2))
# 返回输出和注意力权重(可选)
return src, attn_weights if trace else None
# ============================
# Tiny Transformer 分类模型
# ============================
class TinyEncoderClassifier(nn.Module):
"""
Tiny Transformer 分类模型:
包含嵌入层、位置编码、若干 Transformer 编码器层和分类头。
支持输出每层的注意力权重。
"""
def __init__(self, vocab_size, d_model, n_heads, d_ff, num_layers, max_len, num_classes):
super().__init__()
# 词嵌入层,将 token id 映射为向量
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码模块
self.pos_encoder = PositionalEncoding(d_model, max_len)
# 堆叠多个 Transformer 编码器层
self.layers = nn.ModuleList([
TransformerEncoderLayerWithTrace(d_model, n_heads, d_ff) for _ in range(num_layers)
])
# 分类头,对第一个 token 的输出做分类
self.classifier = nn.Linear(d_model, num_classes)
def forward(self, input_ids, trace=False):
"""
前向传播。
参数:
input_ids: 输入 token id,形状为 (batch, seq_len)
trace: 是否输出注意力权重
返回:
logits: 分类输出 (batch, num_classes)
traces: 每层的注意力权重(可选)
"""
# 词嵌入
x = self.embedding(input_ids)
# 加位置编码
x = self.pos_encoder(x)
traces = []
# 依次通过每一层 Transformer 编码器
for layer in self.layers:
x, attn = layer(x, trace=trace)
if trace:
traces.append({"attn_map": attn})
# 只取第一个 token 的输出做分类(类似 BERT 的 [CLS])
logits = self.classifier(x[:, 0])
return logits, traces if trace else None
# ============================
# 模型构建与训练函数,显式使用CPU
# ============================
@st.cache_resource(show_spinner=False)
def build_and_train_model(d_model, n_heads, d_ff, num_layers):
device = torch.device('cpu') # 显式指定使用CPU
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
dataset = load_dataset("ag_news")
dataset["train"] = dataset["train"].select(range(200)) # 只用前200条数据
MAX_LEN = 64
def encode(example):
tokens = tokenizer(example["text"], padding="max_length", truncation=True, max_length=MAX_LEN, return_tensors="pt")
return {"input_ids": tokens["input_ids"].squeeze(0), "label": example["label"]}
encoded_train = dataset["train"].map(encode)
encoded_train.set_format(type="torch")
train_loader = DataLoader(encoded_train, batch_size=16, shuffle=True)
model = TinyEncoderClassifier(
vocab_size=tokenizer.vocab_size,
d_model=d_model,
n_heads=n_heads,
d_ff=d_ff,
num_layers=num_layers,
max_len=MAX_LEN,
num_classes=4
).to(device) # 模型放到CPU
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
model.train()
for epoch in range(1): # 训练1个epoch
for i, batch in enumerate(train_loader):
if i >= 10: # 只训练10个batch
break
input_ids = batch["input_ids"].to(device) # 输入转到CPU
labels = batch["label"].to(device)
logits, _ = model(input_ids)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return model, tokenizer
# ============================
# Streamlit 页面设置
# ============================
st.set_page_config(page_title="TinyEncoder")
st.title(" Tiny Encoder Transformer")
# 固定模型参数
# d_model: 隐藏层维度,
# n_heads: 注意力头数,
# d_ff: 前馈层维度,
# num_layers: Transformer 层数
d_model = 64
n_heads = 2
d_ff = 128
num_layers = 1
# 构建并训练模型
with st.spinner("模型构建中..."):
model, tokenizer = build_and_train_model(d_model, n_heads, d_ff, num_layers)
# ============================
# 推理与注意力权重可视化
# ============================
model.eval()
device = torch.device('cpu')
model.to(device)
user_input = st.text_input("请输入文本:", "We all have a home called China.")
if user_input:
tokens = tokenizer(user_input, return_tensors="pt", max_length=64, padding="max_length", truncation=True)
input_ids = tokens["input_ids"].to(device) # 放CPU
with torch.no_grad():
logits, traces = model(input_ids, trace=True)
pred_class = torch.argmax(logits, dim=-1).item()
st.markdown(f"### 预测类别编号: `{pred_class}`")
if traces:
attn_map = traces[0]["attn_map"]
if attn_map is not None:
seq_len = input_ids.shape[1]
token_list = tokenizer.convert_ids_to_tokens(input_ids[0])
if '[PAD]' in token_list:
valid_len = token_list.index('[PAD]')
else:
valid_len = seq_len
token_list = token_list[:valid_len]
if attn_map.dim() == 4:
# [batch, heads, seq_len, seq_len]
heads = attn_map.size(1)
fig, axes = plt.subplots(1, heads, figsize=(5 * heads, 3))
if heads == 1:
axes = [axes]
for i in range(heads):
matrix = attn_map[0, i][:valid_len, :valid_len].cpu().detach().numpy()
sns.heatmap(matrix, ax=axes[i], cbar=False, xticklabels=token_list, yticklabels=token_list)
axes[i].set_title(f"Head {i}")
axes[i].tick_params(labelsize=6)
# 显示每个 token 被关注的占比
attn_sum = matrix.sum(axis=0)
attn_ratio = attn_sum / attn_sum.sum()
fig2, ax2 = plt.subplots(figsize=(5, 2))
ax2.bar(range(valid_len), attn_ratio)
ax2.set_xticks(range(valid_len))
ax2.set_xticklabels(token_list, rotation=90, fontsize=6)
ax2.set_title(f"Head {i} Token Attention Ratio")
st.pyplot(fig2)
st.pyplot(fig)
elif attn_map.dim() == 3:
# [heads, seq_len, seq_len]
heads = attn_map.size(0)
fig, axes = plt.subplots(1, heads, figsize=(5 * heads, 3))
if heads == 1:
axes = [axes]
for i in range(heads):
matrix = attn_map[i][:valid_len, :valid_len].cpu().detach().numpy()
sns.heatmap(matrix, ax=axes[i], cbar=False, xticklabels=token_list, yticklabels=token_list)
axes[i].set_title(f"Head {i}")
axes[i].tick_params(labelsize=6)
# 显示每个 token 被关注的占比
attn_sum = matrix.sum(axis=0)
attn_ratio = attn_sum / attn_sum.sum()
fig2, ax2 = plt.subplots(figsize=(5, 2))
ax2.bar(range(valid_len), attn_ratio)
ax2.set_xticks(range(valid_len))
ax2.set_xticklabels(token_list, rotation=90, fontsize=6)
ax2.set_title(f"Head {i} Token Attention Ratio")
st.pyplot(fig2)
st.pyplot(fig)
elif attn_map.dim() == 2:
# [seq_len, seq_len]
fig, ax = plt.subplots(figsize=(5, 3))
sns.heatmap(attn_map[:valid_len, :valid_len].cpu().detach().numpy(), ax=ax, cbar=False, xticklabels=token_list, yticklabels=token_list)
ax.set_title("Attention Map")
ax.tick_params(labelsize=6)
st.pyplot(fig)
# 显示每个 token 被关注的占比
matrix = attn_map[:valid_len, :valid_len].cpu().detach().numpy()
attn_sum = matrix.sum(axis=0)
attn_ratio = attn_sum / attn_sum.sum()
fig2, ax2 = plt.subplots(figsize=(5, 2))
ax2.bar(range(valid_len), attn_ratio)
ax2.set_xticks(range(valid_len))
ax2.set_xticklabels(token_list, rotation=90, fontsize=6)
ax2.set_title("Token Attention Ratio")
st.pyplot(fig2)
else:
st.warning("注意力权重维度异常,无法可视化。")

第9.1讲、Tiny Encoder Transformer:极简文本分类与注意力可视化实战的更多相关文章
- Vim,极简使用教程,让你瞬间脱离键鼠切换的痛苦
注:看大家对Vim仇恨极大,其实它只是一种文本操作方式,可以减少键鼠的切换,从而让编辑文本的操作更迅捷.并不等同于IDE,在我看来,它们是两个是包含关系,IDE可以有Vim编辑模式.Vim或许可以通过 ...
- 在Web应用中接入微信支付的流程之极简清晰版
在Web应用中接入微信支付的流程之极简清晰版 背景: 在Web应用中接入微信支付,我以为只是调用几个API稍作调试即可. 没想到微信的API和官方文档里隐坑无数,致我抱着怀疑人生的心情悲愤踩遍了丫们布 ...
- 在Web应用中接入微信支付的流程之极简清晰版 (转)
在Web应用中接入微信支付的流程之极简清晰版 背景: 在Web应用中接入微信支付,我以为只是调用几个API稍作调试即可. 没想到微信的API和官方文档里隐坑无数,致我抱着怀疑人生的心情悲愤踩遍了丫们布 ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Mongodb极简实践
MongoDB 极简实践入门 1. 为什么用MongoDB? 传统的计算机应用大多使用关系型数据库来存储数据,比如大家可能熟悉的MySql, Sqlite等等,它的特点是数据以表格(table)的形式 ...
- MongoDB 极简实践入门
原作者StevenSLXie; 原链接(https://github.com/StevenSLXie/Tutorials-for-Web-Developers/blob/master/MongoDB% ...
- 极简Node教程-七天从小白变大神(一:你需要Express)
如果说用一句话来概括Node那就是:它开启了JavaScript服务器端语言. Node系列的文章并不会从一开始长篇概论的讲Node的历史,安装,以及其他很琐碎的事情.只会专门介绍关于Node或者准确 ...
- Spring Boot (七): Mybatis极简配置
Spring Boot (七): Mybatis极简配置 1. 前言 ORM 框架的目的是简化编程中的数据库操作,经过这么多年的发展,基本上活到现在的就剩下两家了,一个是宣称可以不用写 SQL 的 H ...
- 一个基于protobuf的极简RPC
前言 RPC采用客户机/服务器模式实现两个进程之间的相互通信,socket是RPC经常采用的通信手段之一.当然,除了socket,RPC还有其他的通信方法:http.管道...网络开源的RPC框架也比 ...
- 极简估值教程——第一篇 速判估值与PEG的推导
来自盛京剑客的雪球原创专栏 一.极简速判估值怎么判? 很简单.简单到粗暴. 用PEG PEG=PE/(g*100)=1.0 什么意思? PE市盈率,g未来收益增长率,PEG为1.0合理估值,大于1.0 ...
随机推荐
- sql 周岁计算
select FLOOR(DATEDIFF(DY, substring(身份证字段,7,4), GETDATE()) / 365.25) age from [表名]
- pikachu搭建
pikachu靶场搭建教程 下载小皮面板phpstudy: 小皮官网:https://www.xp.cn/ 下载pikachu : https://github.com/zhuifengshaonia ...
- [第三章]ABAQUS CM插件中文手册
ABAQUS Composite Modeler User Manual(zh-CN) Dassault Systèmes, 2018 注: 源文档的交叉引用链接,本文无效 有些语句英文表达更易理解, ...
- k8s Pod状态详解
k8s Pod状态详解 在 Kubernetes 中,Pod 是最小的可部署的计算单元,它是一组容器的集合,共享同一个网络命名空间.存储卷等资源. Kubernetes 中的 Pod 有以下几种状态: ...
- 云服务器下如何部署Flask项目详细操作步骤
参考网上各种方案,再结合之前学过的Django部署方案,最后确定Flask总体部署是基于:centos7+nginx+uwsgi+python3+Flask之上做的. 本地windows开发测试好了我 ...
- 【Azure Fabric Service】演示使用PowerShell命令部署SF应用程序(.NET)
问题描述 在中国区微软云Azure上使用Service Fabrics服务,本地通过Visual Studio 2022的发布.NET应用,发现无法发布! 在搜寻官方文档之后,可以通过PowerShe ...
- 同一局域网下,远程连接另一台电脑的Mysql数据库
博客地址:https://www.cnblogs.com/zylyehuo/ 参考链接 同一局域网,远程连接别人的Mysql数据库 用电脑A去远程电脑B的数据库,那我们要先在电脑B上设置一下: ste ...
- 入门Dify平台:工作流节点分析
要让智能体在实际应用中表现出色,掌握工作流的使用至关重要.今天,我们将深入探讨Dify平台中的各个节点的功能,了解它们的使用方法以及常见的应用场景.通过对这些节点的全面了解,将能够高效地设计和优化智能 ...
- Linux如何从命令行卡死的进程中退出?
Linux如何从命令行卡死的进程中退出? 不知道大家在使用Linux的时候,会不会遇到一些命令,有可能卡顿,有可能执行时间过长(比如使用 find 查找某个文件),这个时候我不想继续执行这个命令了,说 ...
- BUUCTF---天干地址+甲子
题目 直接参考天干地支表作结,转ASCII flag{Goodjob}