曾经风光无限的 Oracle DBA 已经落伍了吗?
先讲一个残酷的事实,Oracle DBA,若仍停留在纯粹的运维方向,未来的路将会越走越窄,尤其是在国内的特殊环境下,可以说是前途渺茫,举步维艰。
既然如此,那Oracle DBA们应该如何破局呢?
- Part1.回顾DBA历史
- Part2.走进AI时代
- Part3.如何破局重生?
Part1:回顾DBA历史
国内最早期从事Oracle DBA岗位的人,如今基本已经退休或接近退休状态,这些前辈们,除去混日子的不算,其中运气好的早已实现财务自由,运气差的也基本能达到中产水平,那一代人是充分享受到了属于那个时代的红利。
不过,真正的一名合格运维DBA所付出的辛苦绝对远高于IT行业各技术岗的平均水平,无论是在他们漫长技术积累的学习之路上,还是从无数个深夜中熬着心血去保障、值守、救火的身影中,都可以了解到他们的高回报并不是纯时代红利,也是实实在在的付出了太多代价换来的。
无奈时代变化太快,后面的故事就是,看到这行表面光鲜的从业者越来越多,各种水平参差不齐的培训机构泛滥成灾,导致供大于求,加之市场上同时出现很多专业做这方面服务的公司,同时Oracle数据库本身也变得越来越稳定,在各种因素综合影响之下,让Oracle DBA不再是传奇,最终红利彻底消失,已和其他普通岗位没啥区别,有时还会被同行戏谑曾经省吃俭用花大几万块考下来的OCM认证早已没了含金量。
所以,这么多年来苦心专研Oracle是都白学了?曾经风光无限的 Oracle DBA 已经落伍了吗?
Part2:走进AI时代
现如今,整个社会都开始走进了AI时代。不过别担心,Oracle DBA 传统运维方向有可能不再景气,但Oracle技术本身可并不落伍,而且一直都是引领技术前沿的。
这不,最近大火的AI,Oracle也是有全套解决方案与之匹配的。掌握了这些技能,不仅能让你瞬间领悟Oracle的Vector Search等新的技能,还能让自身紧跟AI相关技术前沿。
之前和一些从事Oracle DBA的朋友们闲聊,发现最难转变的是一些使用习惯。很多老的观念还是把Oracle作为纯粹的老牌关系型数据库,对其多模融合的相关技术置若罔闻,更别提什么AI相关技术。
所以导致有些小伙伴虽然早已听闻Oracle 23ai和AI的紧密结合,但是具体到落地究竟怎么用,实在是丈二和尚摸不着头脑。
Part3:如何破局重生?
纸上得来终觉浅,绝知此事要躬行。
如果没有特别的境遇,最好的起步指导材料依然来源于Oracle官方文档,关于AI,可以看下《Oracle AI Vector Search User's Guide》这本书。书中有一章节,就非常适合AI新手来快速体验到Oracle的AI到底能做些啥,它就是:
- SQL Quick Start Using a Vector Embedding Model Uploaded into the Database
https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/sql-quick-start-using-vector-embedding-model-uploaded-database.html
该文章提供了一组实际可操作的命令,帮助我们快速了解最核心的Oracle AI VECTOR Search。现在就带大家一起体验下这个过程,一起轻松踏入AI的浪潮之中。
文章说我们需要准备三个类似于以下内容的文件:
- 1.Embedding Model
- 2.json-relational-duality-developers-guide.pdf
- 3.oracle-database-23ai-new-features-guide.pdf
其实就是一个Embedding模型,两个PDF文件用于测试。
而在这个刚开始的阶段,你完全不必折腾什么onnx的模型转换,也无需关注其是否支持中文,更不必花心思去挑选什么测试材料,甚至连具体要执行的命令都不需要修改太多,就先按照文档的示例一步步做,感受过之后在进阶阶段或具体项目中实践时,再去考虑所有细节项。
上面提到的每个文件都贴心的提供了对应下载地址,这都是官方文档中直接给出的安全地址,你可以直接wget下载,笔者已亲测均可正常下载:
- https://adwc4pm.objectstorage.us-ashburn-1.oci.customer-oci.com/p/VBRD9P8ZFWkKvnfhrWxkpPe8K03-JIoM5h_8EJyJcpE80c108fuUjg7R5L5O7mMZ/n/adwc4pm/b/OML-Resources/o/all_MiniLM_L12_v2_augmented.zip
- https://docs.oracle.com/en/database/oracle/oracle-database/23/jsnvu/json-relational-duality-developers-guide.pdf
- https://docs.oracle.com/en/database/oracle/oracle-database/23/nfcoa/oracle-database-23ai-new-features-guide.pdf
其中下载下来的这个zip包,解压unzip all-MiniLM-L12-v2_augmented.zip后,会发现有一个README-ALL_MINILM_L12_V2-augmented.txt ,这个说明文件还非常详细的给出了整个onnx模型加载到Oracle库内的操作步骤,大多命令都可以稍加修改直接使用。
梳理关键命令,比如就按照我的测试环境修改如下:
sqlplus / as sysdba;
alter session set container=ALFRED;
SQL> GRANT DB_DEVELOPER_ROLE, CREATE MINING MODEL TO TPCH;
SQL> CREATE OR REPLACE DIRECTORY DM_DUMP AS '/home/oracle';
SQL> GRANT READ ON DIRECTORY DM_DUMP TO TPCH;
SQL> GRANT WRITE ON DIRECTORY DM_DUMP TO TPCH;
SQL> exit
使用tpch测试用户导入ONNX的Embedding模型:
--使用TPCH用户登录
sqlplus tpch/tpch@alfred
--删除模型(可选)
exec DBMS_VECTOR.DROP_ONNX_MODEL(model_name => 'ALL_MINILM_L12_V2', force => true);
--加载导入模型:
BEGIN
DBMS_VECTOR.LOAD_ONNX_MODEL(
directory => 'DM_DUMP',
file_name => 'all_MiniLM_L12_v2.onnx',
model_name => 'ALL_MINILM_L12_V2',
metadata => JSON('{"function" : "embedding", "embeddingOutput" : "embedding", "input": {"input": ["DATA"]}}'));
END;
/
--查询导入的EMBEDDING模型:
select model_name, algorithm, mining_function from user_mining_models where model_name='ALL_MINILM_L12_V2';
--测试EMBEDDING模型可用,可以正常返回向量化结果
SELECT VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'The quick brown fox jumped' as DATA) AS embedding;
到此,是不是没有任何难度?
我们就已经体验了Oracle库内Embedding Model的导入,以后你需要其他Embedding模型,也是同样方法导入,只是有些需要格式转换下才可以,目前模型大小限制是不可超过1G。
接下来创建测试表,插入测试数据:
注意这里测试表只有两个字段,一个是正常的ID列,另一个是BLOB数据类型的data列。
而提到BLOB(Binary Large Object),不得不说,传统运维DBA对这个是敏感的,认为这种二进制大对象非结构化的数据一定不要存在数据库中,但时代在变化,如果你希望数据完全由数据库管理而非文件系统,BLOB反而是不二之选。
--如果存在此测试表就先删除
--drop table documentation_tab purge;
--创建测试表documentation_tab
create table documentation_tab (id number, data blob);
--插入测试数据
insert into documentation_tab values(1, to_blob(bfilename('DM_DUMP', 'json-relational-duality-developers-guide.pdf')));
insert into documentation_tab values(2, to_blob(bfilename('DM_DUMP', 'oracle-database-23ai-new-features-guide.pdf')));
commit;
select dbms_lob.getlength(data) from documentation_tab;
我们看到,这里将之前的两个PDF文件分别插入到表中的两行,通过查询BLOB的数据长度也可以了解占用空间的大小(单位是字节)。

接下来,创建一个关系表来存储非结构化的chunk以及相关向量。
注意,这里这张表的设计,有文档ID,有Chunk ID, 有chunk原文数据,有chunk向量化后的数据。
chunk简单理解就相当于是将这里的每个PDF文件分解成小段。至于chunk的好处大家感兴趣可以自行搜索了解下,总之,这个做法算是最佳实践。
--drop table doc_chunks purge;
create table doc_chunks (doc_id number, chunk_id number, chunk_data varchar2(4000), chunk_embedding vector);
--一条SQL语句就可以完成操作:
--The INSERT statement reads each PDF file from DOCUMENTATION_TAB, transforms each PDF file into text, chunks each resulting text, then finally generates corresponding vector embeddings on each chunk that is created. All that is done in one single INSERT SELECT statement.
--注意修改model名字为ALL_MINILM_L12_V2
insert into doc_chunks
select dt.id doc_id, et.embed_id chunk_id, et.embed_data chunk_data, to_vector(et.embed_vector) chunk_embedding
from
documentation_tab dt,
dbms_vector_chain.utl_to_embeddings(
dbms_vector_chain.utl_to_chunks(dbms_vector_chain.utl_to_text(dt.data), json('{"normalize":"all"}')),
json('{"provider":"database", "model":"ALL_MINILM_L12_V2"}')) t,
JSON_TABLE(t.column_value, '$[*]' COLUMNS (embed_id NUMBER PATH '$.embed_id', embed_data VARCHAR2(4000) PATH '$.embed_data', embed_vector CLOB PATH '$.embed_vector')) et;
commit;
这里使用一条SQL就实现了从 documentation_tab 表中读取文档数据 (dt.data)、将文档转换为文本、将文本分割成多个块 (chunks)、为每个文本块生成嵌入向量 (embeddings)、将结果插入到 doc_chunks 表中的整个流程,最终成功插入了1377条数据:

然后,生成用于similarity查询检索的query_vector:
ACCEPT text_input CHAR PROMPT 'Enter text: '
--different methods of backup and recovery
VARIABLE text_variable VARCHAR2(1000)
VARIABLE query_vector VECTOR
BEGIN
:text_variable := '&text_input';
SELECT vector_embedding(ALL_MINILM_L12_V2 using :text_variable as data) into :query_vector;
END;
/
PRINT query_vector
使用下面SQL进行相似性检索,在你的书中,找到与备份恢复最相关的前4个chunk:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 4 ROWS ONLY;
--如果你想找指定哪本书,还可以通过where条件来指定:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
WHERE doc_id=1
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 4 ROWS ONLY;
使用EXPLAIN PLAN 命令确定优化器是如何执行的,目前没有索引,肯定是全表扫:
EXPLAIN PLAN FOR
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 4 ROWS ONLY;
select plan_table_output from table(dbms_xplan.display('plan_table',null,'all'));
运行多向量相似性检索,找前两本最相关的书中,前4个最相关的块:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH FIRST 2 PARTITIONS BY doc_id, 4 ROWS ONLY;
创建向量索引:
--创建HNSW类型的向量索引(提前需要确认设置:vector_memory_size)
--alter system set vector_memory_size=1G scope=spfile;
create vector index docs_hnsw_idx on doc_chunks(chunk_embedding)
organization inmemory neighbor graph
distance COSINE
with target accuracy 95;
--如果23ai版本过低,可能还没有INDEX_SUBTYPE字段
SELECT INDEX_NAME, INDEX_TYPE, INDEX_SUBTYPE
FROM USER_INDEXES;
--如果OK,正常显示如下:
INDEX_NAME INDEX_TYPE INDEX_SUBTYPE
------------- ---------------- ---------------------------
DOCS_HNSW_IDX VECTOR INMEMORY_NEIGHBOR_GRAPH_HNSW
--使用JSON_SERIALIZE查询:
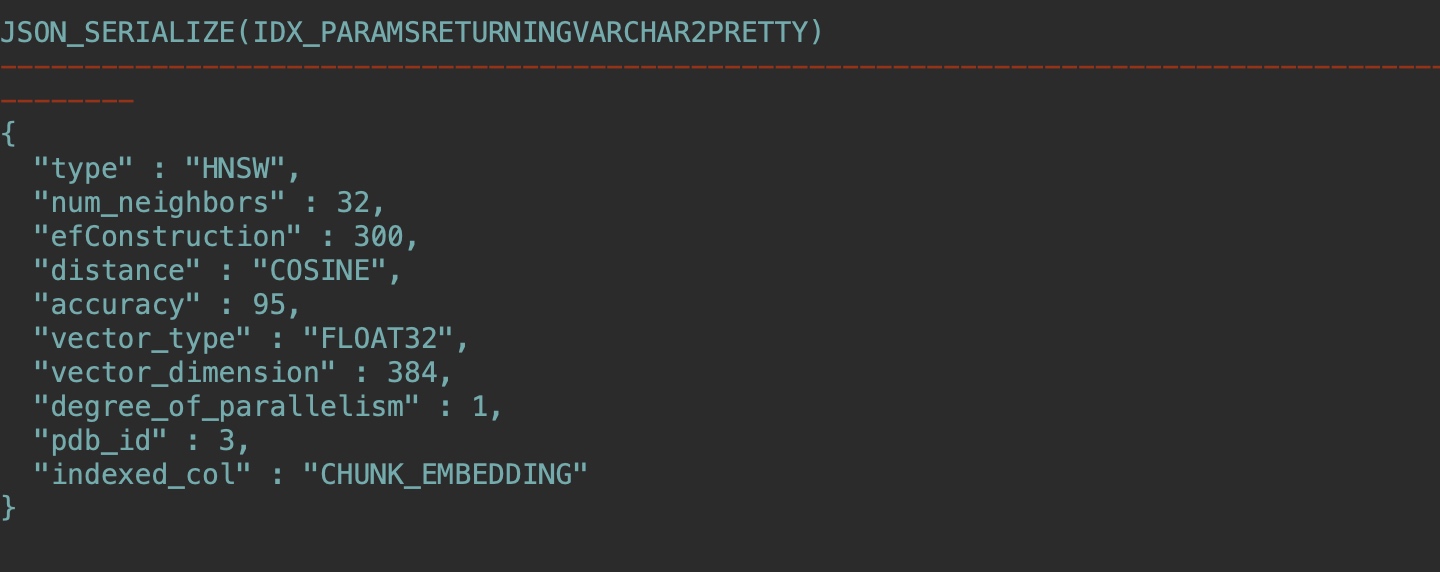
SELECT JSON_SERIALIZE(IDX_PARAMS returning varchar2 PRETTY)
FROM VECSYS.VECTOR$INDEX where IDX_NAME = 'DOCS_HNSW_IDX';
--确定在 vector memory area中的内存分配:
select CON_ID, POOL, ALLOC_BYTES/1024/1024 as ALLOC_BYTES_MB,
USED_BYTES/1024/1024 as USED_BYTES_MB
from V$VECTOR_MEMORY_POOL order by 1,2;
建好索引之后,就可以进行近似的相似性检索(approximate similarity search),在你的书中找到前四条最相关的chunk:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH APPROX FIRST 4 ROWS ONLY WITH TARGET ACCURACY 80;
--同样,可以where指定第一个文档,从第一个文档中找到前四条最相关的chunk:
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
WHERE doc_id=1
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH APPROX FIRST 4 ROWS ONLY WITH TARGET ACCURACY 80;
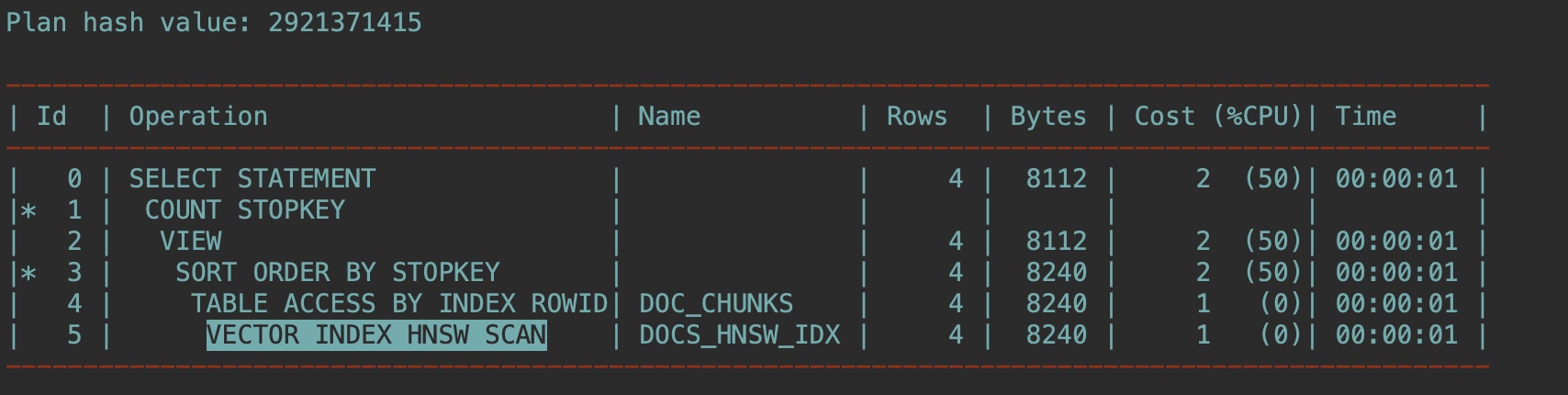
这次还是用EXPLAIN PLAN 确认优化器如何解析此查询:
EXPLAIN PLAN FOR
SELECT doc_id, chunk_id, chunk_data
FROM doc_chunks
ORDER BY vector_distance(chunk_embedding , :query_vector, COSINE)
FETCH APPROX FIRST 4 ROWS ONLY WITH TARGET ACCURACY 80;
select plan_table_output from table(dbms_xplan.display('plan_table',null,'all'));
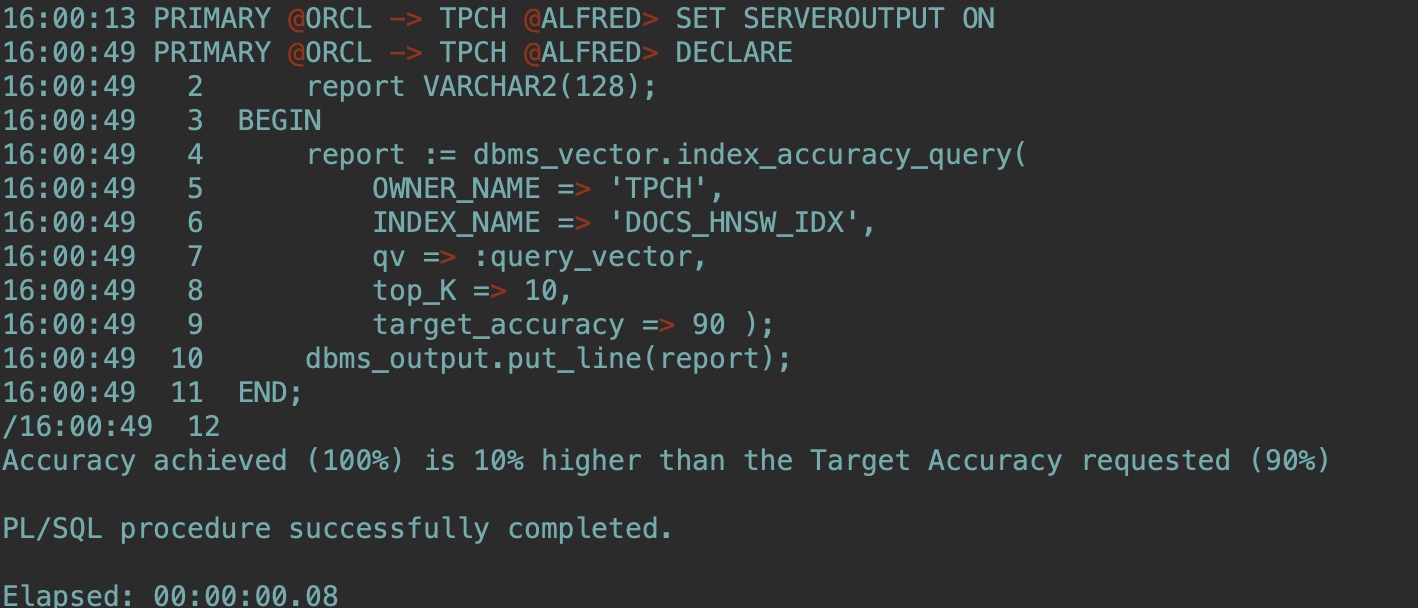
确认近似相似检索的向量索引性能(Determine your vector index performance for your approximate similarity searches.):
--注意修改OWNER_NAME
SET SERVEROUTPUT ON
DECLARE
report VARCHAR2(128);
BEGIN
report := dbms_vector.index_accuracy_query(
OWNER_NAME => 'TPCH',
INDEX_NAME => 'DOCS_HNSW_IDX',
qv => :query_vector,
top_K => 10,
target_accuracy => 90 );
dbms_output.put_line(report);
END;
/
现在我们创建一个新表用于混合检索:
--
--DROP TABLE documentation_tab2 PURGE;
CREATE TABLE documentation_tab2 (id NUMBER, file_name VARCHAR2(200));
INSERT INTO documentation_tab2 VALUES(1, 'json-relational-duality-developers-guide.pdf');
INSERT INTO documentation_tab2 VALUES(2, 'oracle-database-23ai-new-features-guide.pdf');
COMMIT;
要创建混合向量索引,需要指定文件所在的数据存储。在这里,我们使用存储PDF文件的DM_DUMP目录:
BEGIN
ctx_ddl.create_preference('DS', 'DIRECTORY_DATASTORE');
ctx_ddl.set_attribute('DS', 'DIRECTORY', 'DM_DUMP');
END;
/
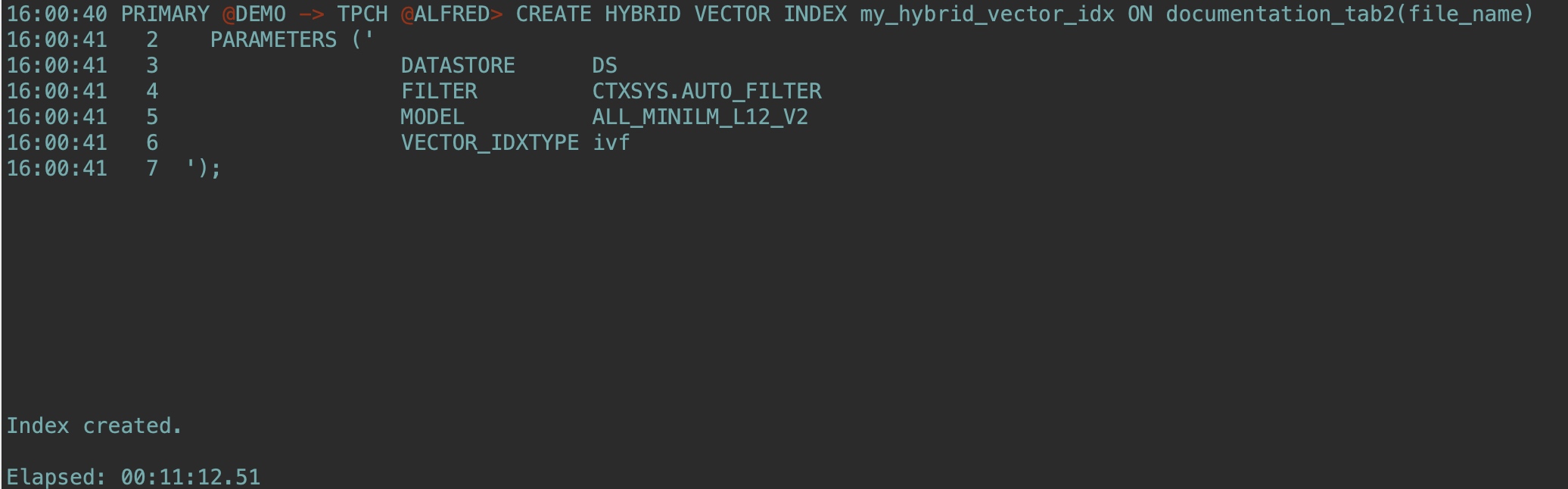
--这里23ai较低版本可能报错,建议使用23.7或以上,创建时间较长耐心等待:
CREATE HYBRID VECTOR INDEX my_hybrid_vector_idx ON documentation_tab2(file_name)
PARAMETERS ('
DATASTORE DS
FILTER CTXSYS.AUTO_FILTER
MODEL ALL_MINILM_L12_V2
VECTOR_IDXTYPE ivf
');
创建混合向量索引后,检查创建的以下内部表:
SELECT COUNT(*) FROM DR$my_hybrid_vector_idx$VR;
SELECT COUNT(*) FROM my_hybrid_vector_idx$VECTORS;
DESC my_hybrid_vector_idx$VECTORS
SELECT COUNT(*) FROM DR$MY_HYBRID_VECTOR_IDX$I;
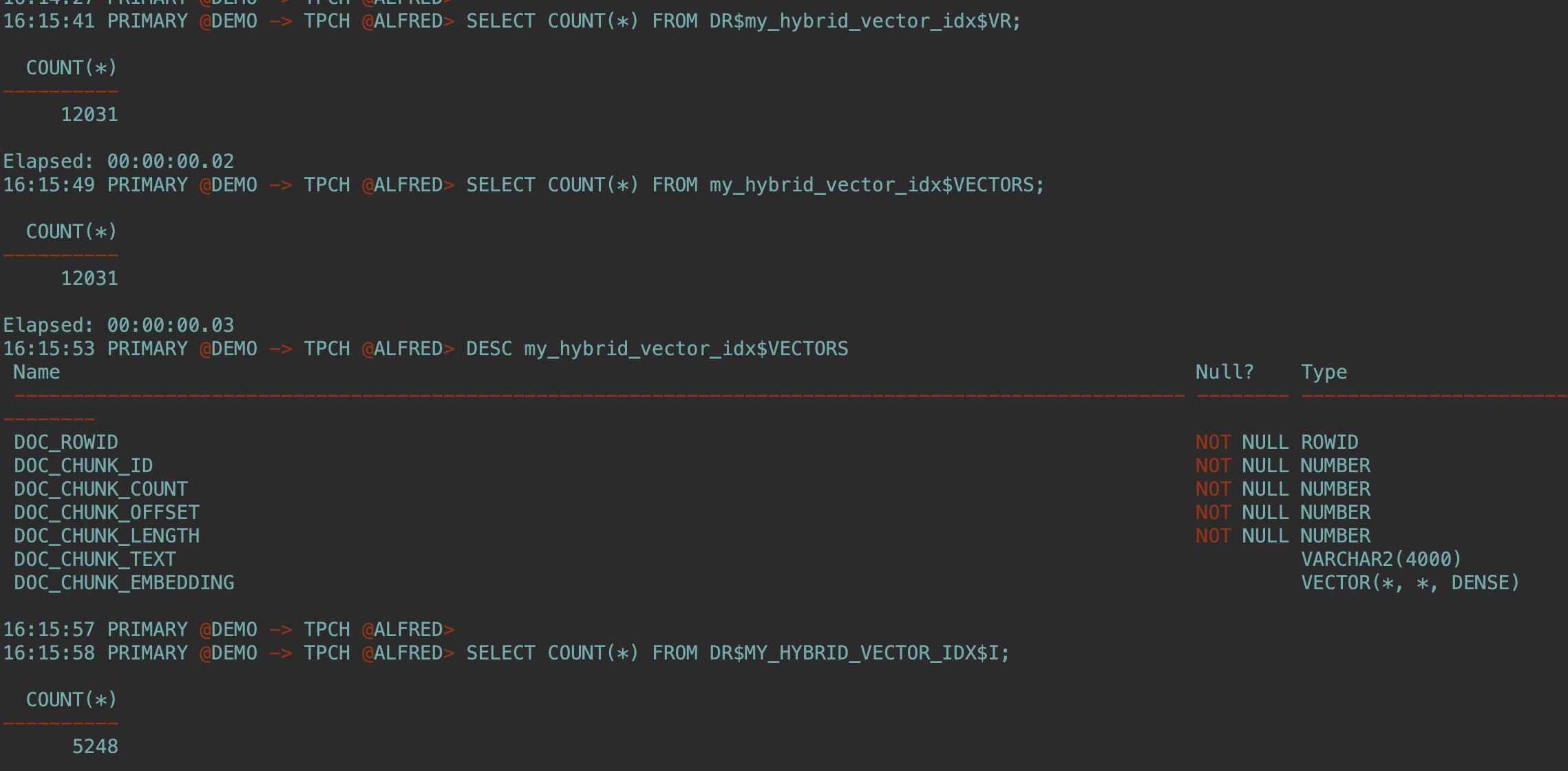
可以通过指定以下参数来运行第一次混合搜索:
The hybrid vector index name
The search scorer you want to use (this scoring function is used after merging results from keyword search and similarity search)
The fusion function to use to merge the results from both searches
The search text you want for your similarity search
The search mode to use to produce the vector search results
The aggregation function to use to calculate the vector score for each document identified by your similarity search
The score weight for your vector score
The CONTAINS string for your keyword search
The score weight for your keyword search
The returned max values you want to see
The maximum number of documents and chunks you want to see in the result
使用文档给出的例子,官方文档中缺少了一个冒号,下面已修正,可以直接复制使用:
SET LONG 10000
SELECT json_serialize(
DBMS_HYBRID_VECTOR.SEARCH(
JSON(
'{
"hybrid_index_name" : "my_hybrid_vector_idx",
"search_scorer" : "rsf",
"search_fusion" : "UNION",
"vector":
{
"search_text" : "How to insert data in json format to a table?",
"search_mode" : "DOCUMENT",
"aggregator" : "MAX",
"score_weight" : 1,
},
"text":
{
"contains" : "data AND json",
"score_weight" : 1,
},
"return":
{
"values" : [ "rowid", "score", "vector_score", "text_score" ],
"topN" : 10
}
}'
)
) RETURNING CLOB pretty);
结果:
SELECT file_name FROM documentation_tab2 WHERE rowid='AAAayGAAAAAO1ajAAB';

混合向量索引维护在后台自动完成,最后测试下在基表中插入新行,并运行与上一步相同的混合搜索查询:
INSERT INTO documentation_tab2 VALUES(3, 'json-relational-duality-developers-guide.pdf');
COMMIT;
这个文件我还没有下载,运行同样查询结果已经多了一组数据:
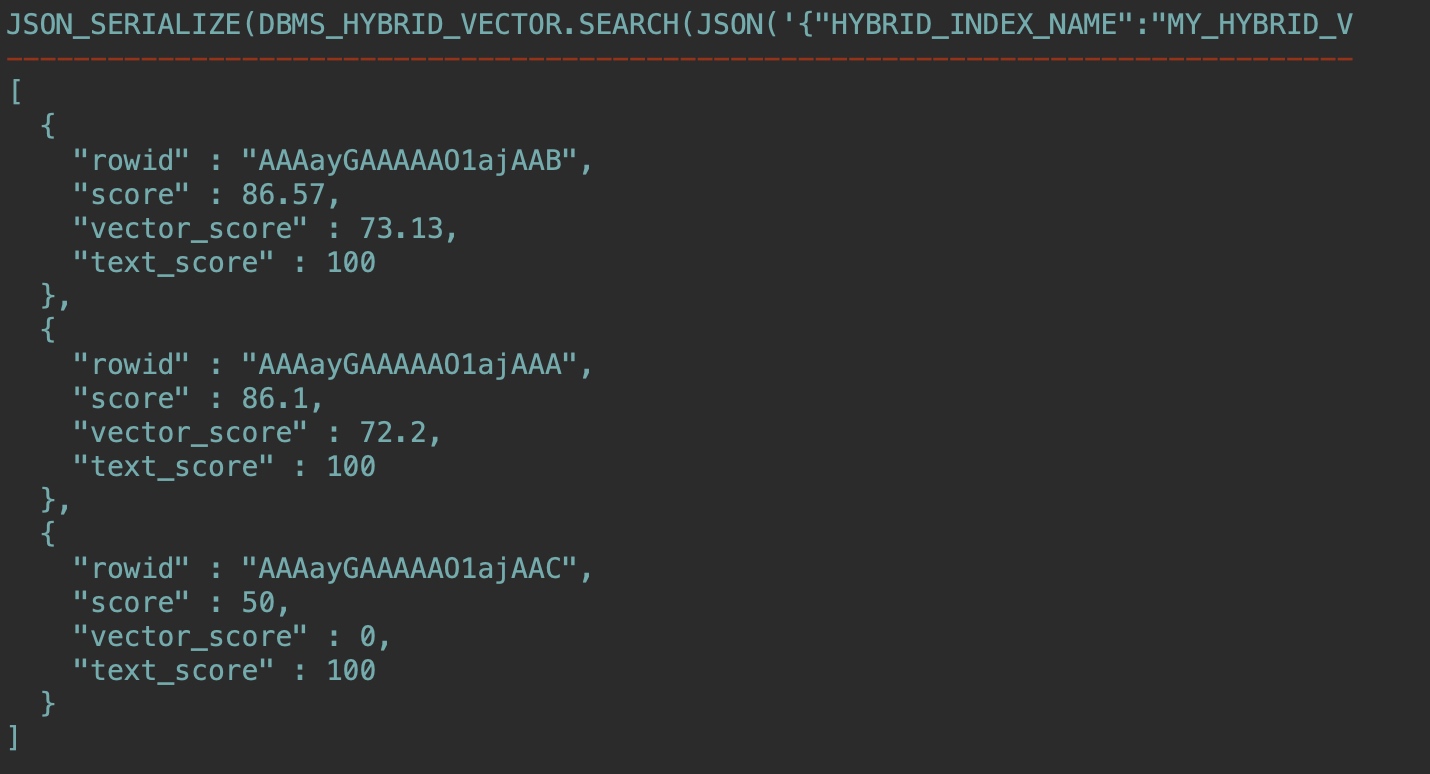
到这里就告一段落了,我们一起快速体验了AI Vector Search,当然很多细节还值得推敲,可以留给后面精进实践的阶段,笔者有时间也会持续跟读者分享更多AI相关技术实践。
最后祝Oracle DBA们在这个变幻莫测的大环境下,都能成功转型,拥抱AI新时代,涅槃重生。
曾经风光无限的 Oracle DBA 已经落伍了吗?的更多相关文章
- Oracle DBA常用查询
Oracle DBA常用查询 –1. 查询系统所有对象select owner, object_name, object_type, created, last_ddl_time, timestamp ...
- Oracle DBA的神器: PRM恢复工具,可脱离Oracle软件运行,直接读取Oracle数据文件中的数据
Oracle DBA的神器: PRM恢复工具,可脱离Oracle软件运行,直接读取Oracle数据文件中的数据 PRM 全称为ParnassusData Recovery Manager ,由 诗檀软 ...
- oracle DBA坚持写博客的7大理由
对于Oracle DBA来说,甚至IT技术人员来说.坚持写博客是个好习惯.以下是我建议大家写博客的七个理由. 帮助整理思路 最近我做出了一个决定,那就是: 我要坚持天天写博客,记录每天所学的重要东西. ...
- oracle dba 职责, 及个人需要掌握内容
ORACLE DBA 职责, 基本相当于日常工作. 0. 数据库设计 1. 模式对象的创建与管理(table, index 等等) 2. 事物管理, 例如并发等 3. SQL 调优 只是针对SQL的 ...
- Oracle DBA 的常用Unix参考手册(二)
9.AIX下显示CPU数量 # lsdev -C|grep Process|wc -l10.Solaris下显示CPU数量# psrinfo -v|grep "Status of pr ...
- Oracle DBA 的常用Unix参考手册(一)
作为一名Oracle DBA,在所难免要接触Unix,但是Unix本身又是极其复杂的,想要深刻掌握同样很不容易.那么到底我们该怎么入手呢?Donald K Burleson 的<Unix for ...
- (摘)ORACLE DBA的职责
ORACLE数据库管理员应按如下方式对ORACLE数据库系统做定期监控: (1). 每天对ORACLE数据库的运行状态,日志文件,备份情况,数据 库的空间使用情况,系统资源的使用情况进行检查,发现并解 ...
- Oracle DBA管理包脚本系列(二)
该系列脚本结合日常工作,方便DBA做数据管理.迁移.同步等功能,以下为该系列的脚本,按照功能划分不同的包.功能有如下: 1)数据库对象管理(添加.修改.删除.禁用/启用.编译.去重复.闪回.文件读写. ...
- Oracle DBA 必须掌握的 查询脚本:
Oracle DBA 必须掌握的 查询脚本: 0:启动与关闭 orcle 数据库的启动与关闭 1:连接数据库 2:数据库开启状态的实现步骤: 2-1:启动数据库 2- ...
- Oracle 史上最全近百条Oracle DBA日常维护SQL脚本指令
史上最全近百条Oracle DBA日常维护SQL脚本指令 https://mp.weixin.qq.com/s?__biz=MjM5MDAxOTk2MQ==&mid=2650281305&am ...
随机推荐
- k8s node节点报错 dial tcp 127.0.0.1:8080: connect: connection refused
前言 在搭建好 kubernetes 环境后,master 节点拥有 control-plane 权限,可以正常使用 kubectl. 但其他 node 节点无法使用 kubectl 命令,即使同步过 ...
- NumPy学习11
今天学习了NumPy线性代数 21, NumPy线性代数 numpy_test11.py : import numpy as np ''' 21, NumPy线性代数 NumPy 提供了 numpy. ...
- NumPy学习9
今天学习了NumPy排序和搜索功能 17, NumPy排序和搜索功能 numpy_test9.py : import numpy as np ''' 17, NumPy排序和搜索功能 NumPy 提供 ...
- OpenHarmony 开源鸿蒙北向开发——hdc工具安装
hdc(OpenHarmony Device Connector)是为开发人员提供的用于设备连接调试的命令行工具,该工具需支持部署在 Windows/Linux/Mac 等系统上与 OpenHar ...
- Ribbon-Loadbalancer自定义负载均衡策略:本地优先+偏向服务器优先
Ribbon 核心顶层抽象 package com.netflix.loadbalancer; public interface IRule { Server choose(Object var1); ...
- C# 多文件打包
public HttpResponseMessage GetZip() { var response = Request.CreateResponse(HttpStatusCode.OK); try ...
- ASP.NET Web.config Transformations
... 参考文档 Web Deployment Content Map for Visual Studio and ASP.NET 微软ASP.NET站点部署指南(3):使用Web.Config文件的 ...
- dxSpreadSheet的报表demo-关于设计报表模板的Datagroup问题
看随机的报表DEMO,主从表也好,数据分组也好.呈现的非常到位. 问题:可是自己在实现数据分组时,一旦设定分组字段就出现了混乱的数据记录. 问题的原因: 看一下一个报表页面设计时需要理清的概念. 页头 ...
- nodejs队列
nodejs队列 创建具有指定并发性的队列对象.添加到队列的任务以并行方式处理(直到并发性限制).如果所有的worker都在进行中,任务就会排队,直到有一个worker可用.worker完成任务后,将 ...
- 🎀windows-剪切板
简介 Windows 剪贴板是一个临时存储区域,它允许用户在不同应用程序之间复制和粘贴文本.图像和其他类型的数据.从 Windows 10 开始,微软引入了一个改进的剪贴板功能,称为剪贴板历史记录,它 ...