使用nodejs爬取拉勾苏州和上海的.NET职位信息
最近开始找工作,本人苏州,面了几家都没有结果很是伤心。在拉勾上按照城市苏州关键字.NET来搜索一共才80来个职位,再用薪水一过滤,基本上没几个能投了。再加上最近苏州的房价蹭蹭的长,房贷压力也是非常大,所以有点想往上海去发展。闲来无聊写了个小爬虫,爬了下苏州跟上海的.NET职位的信息,然后简单对比了一下。
是的小弟擅长.NET,为啥用nodejs?因为前几天有家公司给了个机会可以转nodejs,所以我是用来练手的,不过后来也泡汤了,但是还是花两晚写完了。刚学,代码丑轻喷哈!
一:如何爬取拉勾的数据
这个其实非常简单,本来还以为要用正则去分析html,其实拉勾分页提了ajax的接口,可以直接用http去访问。打开神器Chrome的F12一看便知。
这是用nodejs模拟分页请求的代码:
var getData = function (kd,city,pn) {
var mongo = require('./mongo');
var http = require('http');
var queryString = require('querystring');
var postData=queryString.stringify({
'pn':pn,
'kd':kd,
'first':false
});
var options = {
hostname:'www.lagou.com',
method:'POST',
path:'/jobs/positionAjax.json?px=default&city='+city,
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': postData.length
}
};
var postResult = '';
var req = http.request(options,(res)=>{
console.log(`STATUS:${res.statusCode}`);
res.setEncoding('utf8');
res.on('data',(chunk)=>{
postResult+=chunk;
});
res.on('end',()=>{
console.log(`RESULT:${postResult}`);
var jsonObj =JSON.parse(postResult);
//insert into db
jsonObj.content.result.forEach((item)=>{
var salary = item.salary;
//拆分3k-6k,易于统计
var arr = salary.split('-');
var min = arr[0].substring(0,arr[0].indexOf('k'));
var max = arr.length>1? arr[1].substring(0,arr[1].indexOf('k')):min;
item.salaryMin = parseInt(min);
item.salaryMax = parseInt(max);
mongo.save(city,item);
});
if(jsonObj.content.hasNextPage&&jsonObj.content.totalPageCount>pn){
getData(kd,city,pn+1);
}
});
req.on('error',(e)=>{
console.log(`problem with request:${e.message}`);
});
});
req.write(postData);
req.end();
console.log(`start to get data. pn:${pn} city:${city} kd:${kd}`);
};
exports.run = getData;
二:数据存储在哪里
拉勾的分页接口返回的是json对象,那么自然是存mongoDb最简单了。
下面是mongoDb的封装:
var save=function (city,jsonObj) {
var Db = require('mongodb').Db;
var Server = require('mongodb').Server;
var db = new Db('test',new Server('localhost',27017))
db.open((err,db)=>{
var coll = db.collection(city);
coll.save(jsonObj,(err,r)=>{
if(!err){
console.log('save to '+city);
}
db.close();
});
});
};
var removeAll = function (city,callback) {
var Db = require('mongodb').Db;
var Server = require('mongodb').Server;
var db = new Db('test',new Server('localhost',27017))
db.open((err,db)=>{
var coll = db.collection(city);
coll.remove((err,numOfRows)=>{
if(!err){
console.log(`${city} collection be removed. ${numOfRows}`);
}
db.close();
callback(err);
});
});
};
var readAll=function (city,callback) {
var Db = require('mongodb').Db;
var Server = require('mongodb').Server;
var db = new Db('test',new Server('localhost',27017))
db.open((err,db)=>{
var coll = db.collection(city);
var cursor = coll.find();
cursor.toArray((err,results)=>{
if(!err){
callback(results);
//db.close();
}
db.close();
});
});
}
exports.save = save;
exports.removeAll = removeAll;
exports.readAll = readAll;
三:如何展示数据
使用nodejs自带的httpServer,接受到请求的时候直接读取一个html文件,然后把对比的信息填入html文本里,用一个h5的chart来展示
下面是服务器的代码:
var http = require('http');
var fs = require('fs');
var stati = require('./statistics');
var szStati = {text:'SuZhou'};
var shStati = {text:'ShangHai'};
var server=new http.Server();
server.on('request',function(req,res){
res.writeHead(200,{'Content-Type':'text/html'});
fs.readFile('./index.html','utf8',(err,data)=>{
if (err) {
throw err;
}
console.log(data);
// res.write(data);
// res.end();
stati.statiSalary('苏州',(results)=>{
szStati.values = results;
stati.statiSalary('上海',(results)=>{
shStati.values = results;
var series =[szStati,shStati];
var strSeries = JSON.stringify(series);
console.log(strSeries);
data = data.replace('@series',strSeries);
console.log(data);
res.write(data);
res.end();
});
});
});
});
server.listen(3000);
console.log('http server started...port:3000');
四:统计结果
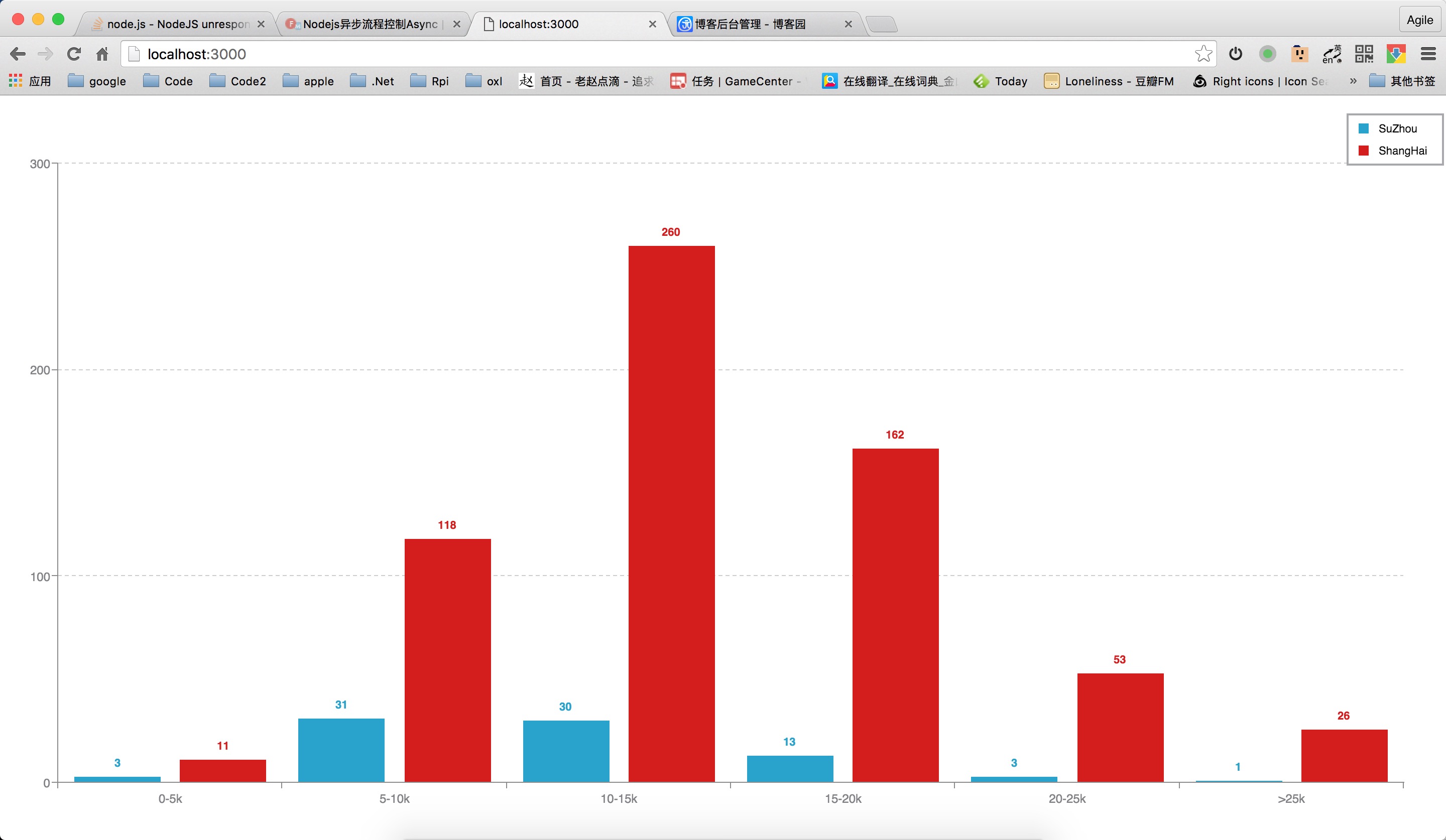
统计按照 0-5k,5-10k,10-15k,15-20k,20-25k,>25k这几个区间按照职位的数量进行统计。
0-5k:上海是苏州的4倍
5-10k:上海是苏州的4倍
10-15k:上海是苏州的9倍
15-20k:上海是苏州的12倍
20-25k:上海是苏州的17倍
>25k:上海是苏州的26倍
可以看到从10-15k开始的职位,上海的数量是苏州的10多倍,越是高薪的职位倍数越高。由此可以看出,苏州跟上海的差距还是非常大的。苏州政府一直沾沾自喜,觉得自己在互联网圈子有多牛逼,搞了一堆孵化器,但其实拿的出手的公司有几家呢,一只手都数过来了,跟北上广深一线还是差的很远呢,还是要努力啊。
恐怕我也要背井离乡去上海的寻找未来了。
还没学会用VS Code上传到github上,先直接上传代码吧:lagouSpider.zip
使用nodejs爬取拉勾苏州和上海的.NET职位信息的更多相关文章
- 爬取拉勾部分求职信息+Bootstrap页面显示
今天在用python实现爬虫的时候,就想看一下用c#实现同样的功能到底会多出来多少code,结果写着写着干脆把页面也简单的写一个出来,方便调试, 大致流程如下: 1.分析拉勾数据 2.查找拉勾做了哪些 ...
- 使用request爬取拉钩网信息
通过cookies信息爬取 分析header和cookies 通过subtext粘贴处理header和cookies信息 处理后,方便粘贴到代码中 爬取拉钩信息代码 import requests c ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...
- 爬取拉钩网上所有的python职位
# 2.爬取拉钩网上的所有python职位. from urllib import request,parse import json,random def user_agent(page): #浏览 ...
- 【爬虫问题】爬取tv.sohu.com的页面, 提取视频相关信息
尝试解决下面的问题 问题: 爬取tv.sohu.com的页面, 提取视频相关信息,不可用爬虫框架完成 何为视频i关信息?属性有哪些? 需求: 做到最大可能的页面覆盖率 *使用httpClient 模拟 ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- 使用nodejs爬取和讯网高管增减持数据
为了抓取和讯网高管增减持的数据,首先得分析一下数据的来源: 网址: http://stockdata.stock.hexun.com/ggzjc/history.shtml 使用chrome开发者工具 ...
- 【原创】py3+requests+json+xlwt,爬取拉勾招聘信息
在拉勾搜索职位时,通过谷歌F12抓取请求信息 发现请求是一个post请求,参数为: 返回的是json数据 有了上面的基础,我们就可以构造请求了 然后对获取到的响应反序列化,这样就获取到了json格式的 ...
随机推荐
- C#程序代码分析(第三周)
刚开始看到这段程序,都不知道是什么东西,问过室友才知道是C#程序:但对C#一点都不了解,最基本的项目建设都不会,在室友的帮助下,以及在网上搜了一些资料,勉强算是完成了此次作业吧. using Syst ...
- canvas绘制坐标轴
效果图如下, var canvas = document.getElementById("canvas"), context = canvas.getContext("2 ...
- RSA密钥生成与使用
RSA密钥生成与使用 openssl生成工具链接:http://pan.baidu.com/s/1c0v3UxE 密码:uv48 1. 打开openssl密钥生成软件打开 openssl 文件夹下的 ...
- Github上传代码菜鸟超详细教程
最近需要将课设代码上传到Github上,之前只是用来fork别人的代码. 这篇文章写得是windows下的使用方法. 第一步:创建Github新账户 第二步:新建仓库 第三部:填写名称,简介(可选 ...
- 《Linux内核设计与实现》读书笔记 第三章 进程管理
第三章进程管理 进程是Unix操作系统抽象概念中最基本的一种.我们拥有操作系统就是为了运行用户程序,因此,进程管理就是所有操作系统的心脏所在. 3.1进程 概念: 进程:处于执行期的程序.但不仅局限于 ...
- AngularJs项目文件以及文件夹结构
app/ ----- Libs/ // references for all libs ---------- angular.js ---------- angular-route.js ----- ...
- MySQL 存储过程
MySQL 存储过程 存储过程是通过给定的语法格式编写自定义的数据库API,类似于给数据库编写可执行函数. 简介 存储过程是一组为了完成特定功能的SQL语句集合,是经过编译后存储在数据库中. 存储过程 ...
- Android 两个activity生命周期的关系
Acitivity的生命周期想必大家都清楚,但是两个activity之间其实不是独立各自进行的. 从第一个activity1启动另外一个activity2时,会先调用本activity1的onPaus ...
- Ubuntu 16 安装ElasticSearch
首先安装Java,参见博客:http://www.cnblogs.com/1zhk/p/6056406.html 下载ElasticSearch安装包 curl -L -O https://artif ...
- 在SqlServer2008R2中,在一张表上加上insert、update、delete触发器(带游标)
在日常工作中,在SqlServer2008R2中,需要向一张表上加上触发器,监控插入.更新.删除. --一个触发器内三种INSERT,UPDATE,DELETE状态 IF exists(select ...