The Architectural Principles Behind Vrbo’s GraphQL Implementation
At Vrbo, we’ve been using GraphQL for over a year. But there are some differences in how we’ve implemented and used GraphQL compared to some examples we’ve seen in the wild.
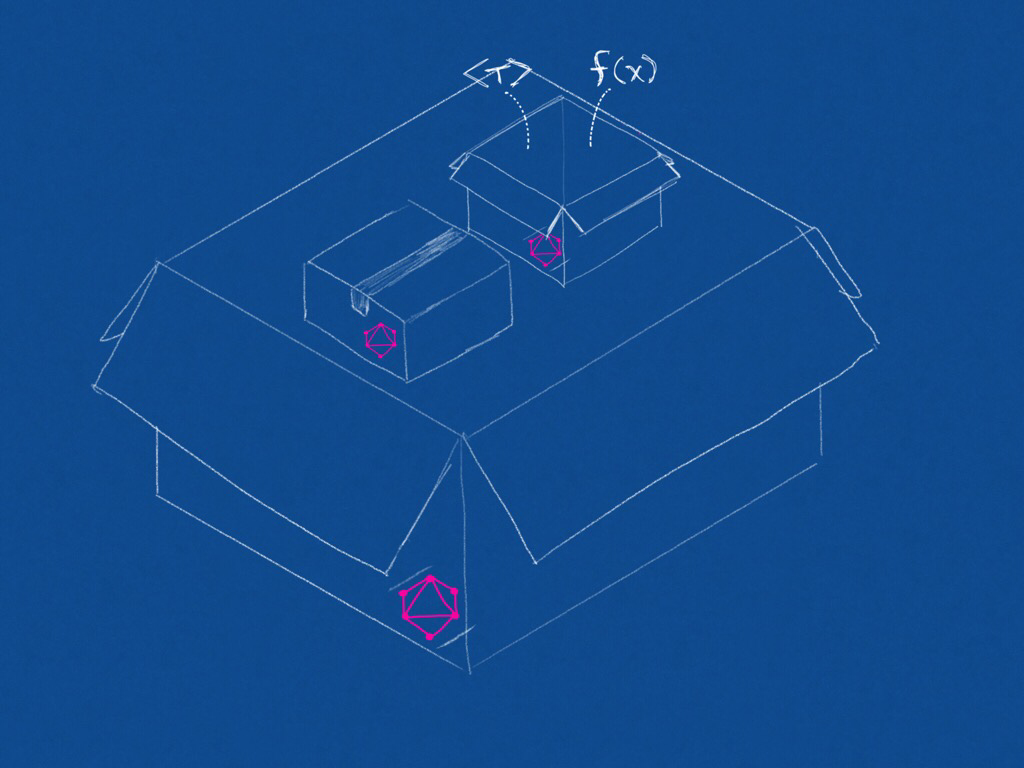
Components of components
This is because in adopting GraphQL at scale, we wanted to ensure not only the success of individual teams, but the scalability and predictability of that success from team to team across Vrbo.
In addition, we’ve learned from past mistakes with other orchestration models and wanted our new model to work differently.
Previously, we relied on dedicated orchestration services. These proved to be not only an unnecessary moving part, but created dependencies between teams that slowed them down and created a wider blast radius when something went wrong.
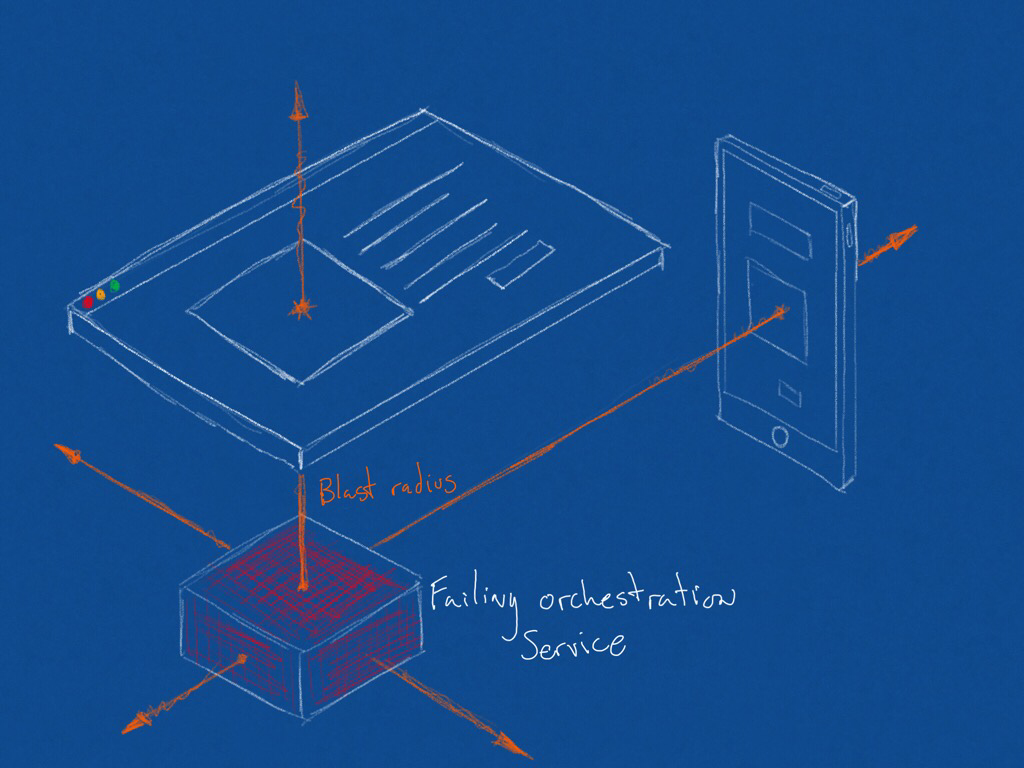
Diagram indicating blast radius of a failure
High level goals
In developing a new front-tier API (orchestration, public APIs) architecture, we had a few goals in mind.
- Increase team velocity by reducing dependencies between teams and services
- Reduce blast radius by:
* Insulating teams from change
* Reducing points of failure - Improve predictability of a team’s:
* Compute needs
* Cost expectations - Simplify collaboration and sharing
- Improve portability across environments
Breaking up GraphQL schema into components
A GraphQL schema is made up of types (type schema), root types (API operations) and resolvers (business logic).
An example type:

GraphQL type example
This defines a new type Author, which is merely a type definition. To perform operations on Author, such as a query, we must define a root type:

GraphQL root type example
This defines a query operation to the API’s surface called author that clients can now interact with.
But we still need to execute some code for the query to do work and this is where resolvers come in. In javascript, a resolver might look something like this:

GraphQL resolver example
As you can imagine, a schema can grow quite large as our API surface area grows. This is in part why we break down and componentize these elements of a schema into independently versionable modules that can be imported and merged into an API based on the requirements of the use case.
An application or API can aggregate as many components as it needs to fulfill its UI or user needs.
Our first iteration of where schema is merged, which has been the basis of our success so far, is called “partials”. This brought the convenience and simplicity of node modules to GraphQL.
Our next major iteration for GraphQL includes a newer component model in which each component is its own fully independently executable schema, making both composition and aggregation easier.
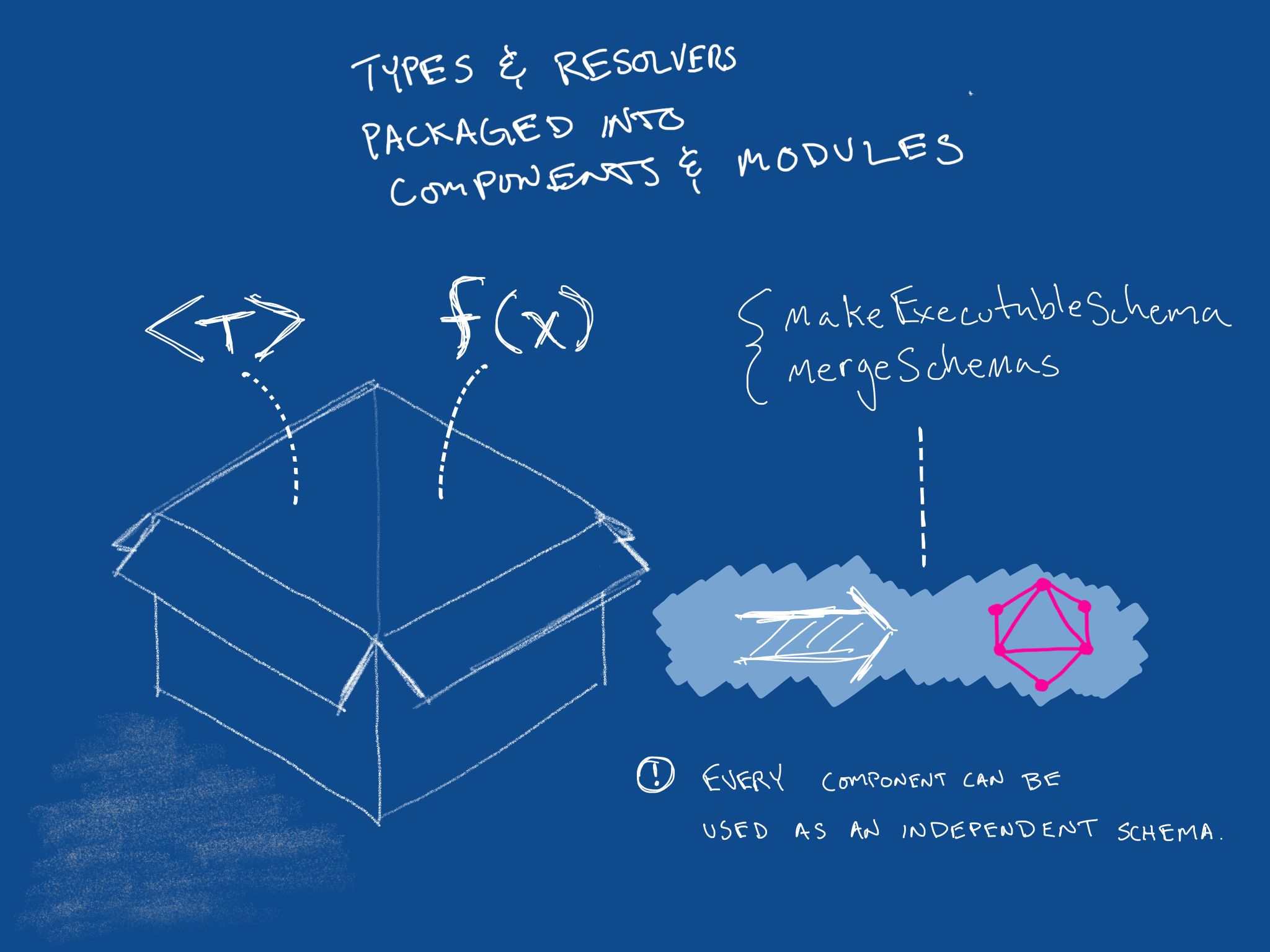
Diagram indicating what a package is comprised of
Implementation design principles
In developing tools to create component-based schemas, we want the following characteristics:
- Composable types
* Types can be made up of many shared types
* Extend and compose types for a use case without impacting others - Composable resolvers
* Invoke without invoking a new service (no network hops)
* Ability to reduce repetitive service calls within the same query tree - Portable
* Injectable upstream requirements (service clients, etc) - Easy to collaborate
* Shared code, not services
* Manage contributions, version as needed, simplify co-development - Schema first
* Easy to read, Easy to update
* Collaborate cross platform on API design in common language
Separate use cases, separate services
With a component model it is not necessary to provision, operationalize and share a service. Each application or API can provide for its own needs by specifying the components it needs.
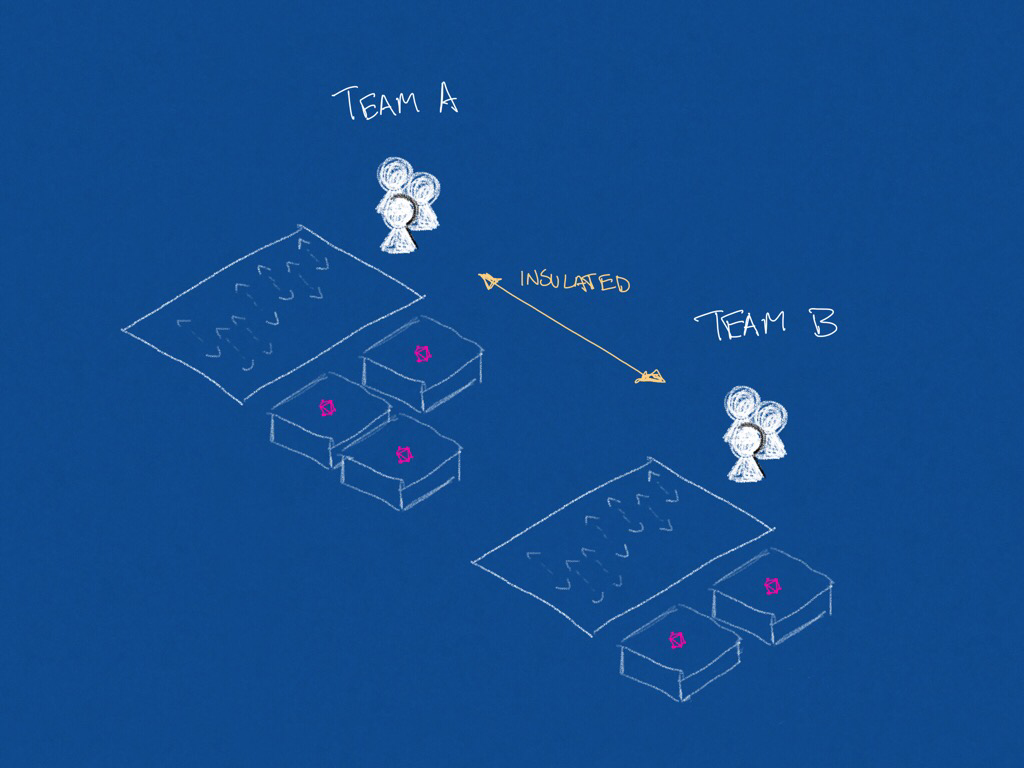
Diagram depicting independent team iteration / responsibility
Because components are composed and merged together without a centralized or shared service, teams can:
- Pick and choose their own orchestration needs
- Version independently of other teams
- Scale independently as their use case demands
- Perform better cost attribution
- Explicitly declare data requirements in UI components
This is a powerful model because it enables our goals for reducing dependencies between teams and the affected area caused by changes in a shared service.
Composition
One of the great aspects of GraphQL is its ability to compose types and resolvers. We don’t want to force two teams to constantly iterate on the same definitions just to satisfy all use cases.
Instead, it is easy for teams to compose new types or extend existing types as separate components that can then be versioned and developed independently.
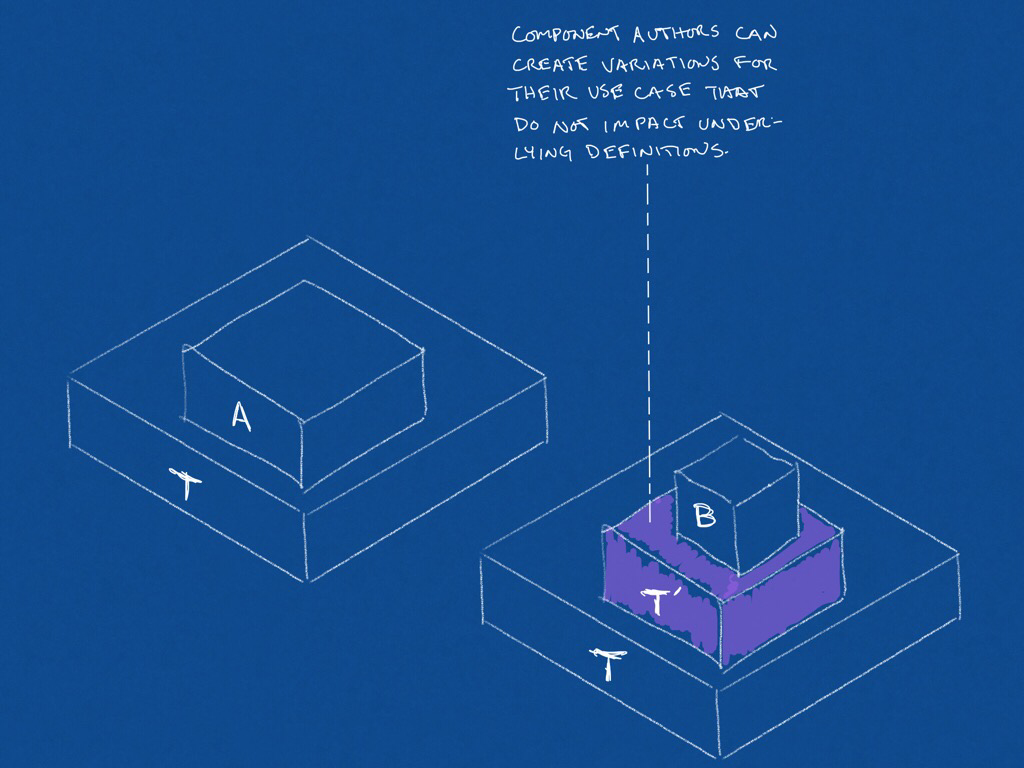
Diagram of component dependencies as packages
A component module A may be composed of an imported module and type T while another component module B, with slightly different needs than A has been composed from a T’ component.
This also allows components to take advantage of existing resolvers by simply invoking across a binding to the composed type. We can also cache results from these calls within a single execution of a query or mutation, reducing the number of times something must be resolved at all.
Components in code
So what might this look like from a code perspective? Let’s take a more real-world example for a property listing appearing on a site like Vrbo.
What is a Listing made up of? Let’s make it overly simple and assume:
- Property
- Reviews
Let’s start with the Property component.
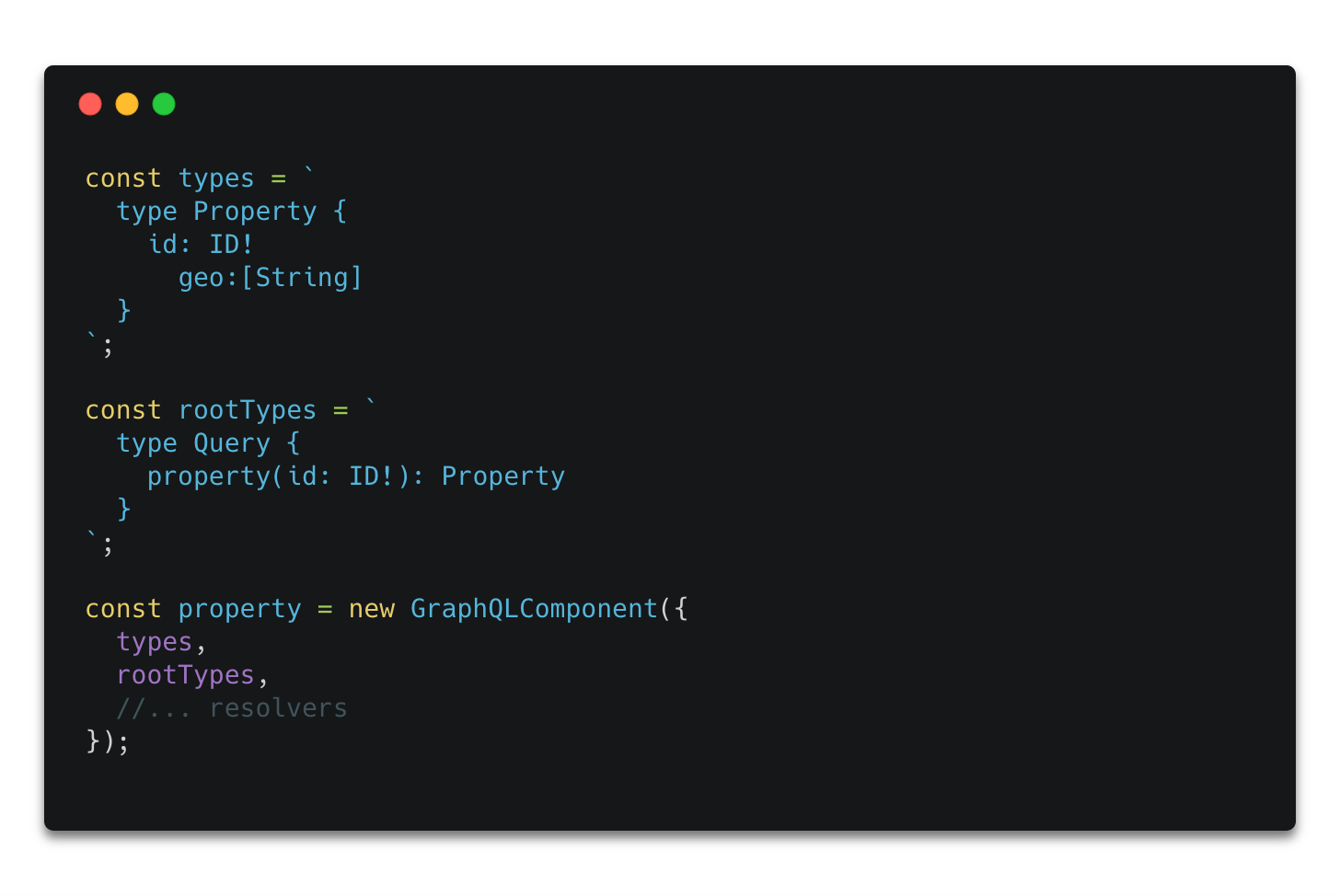
Example property component
Next, Reviews component:
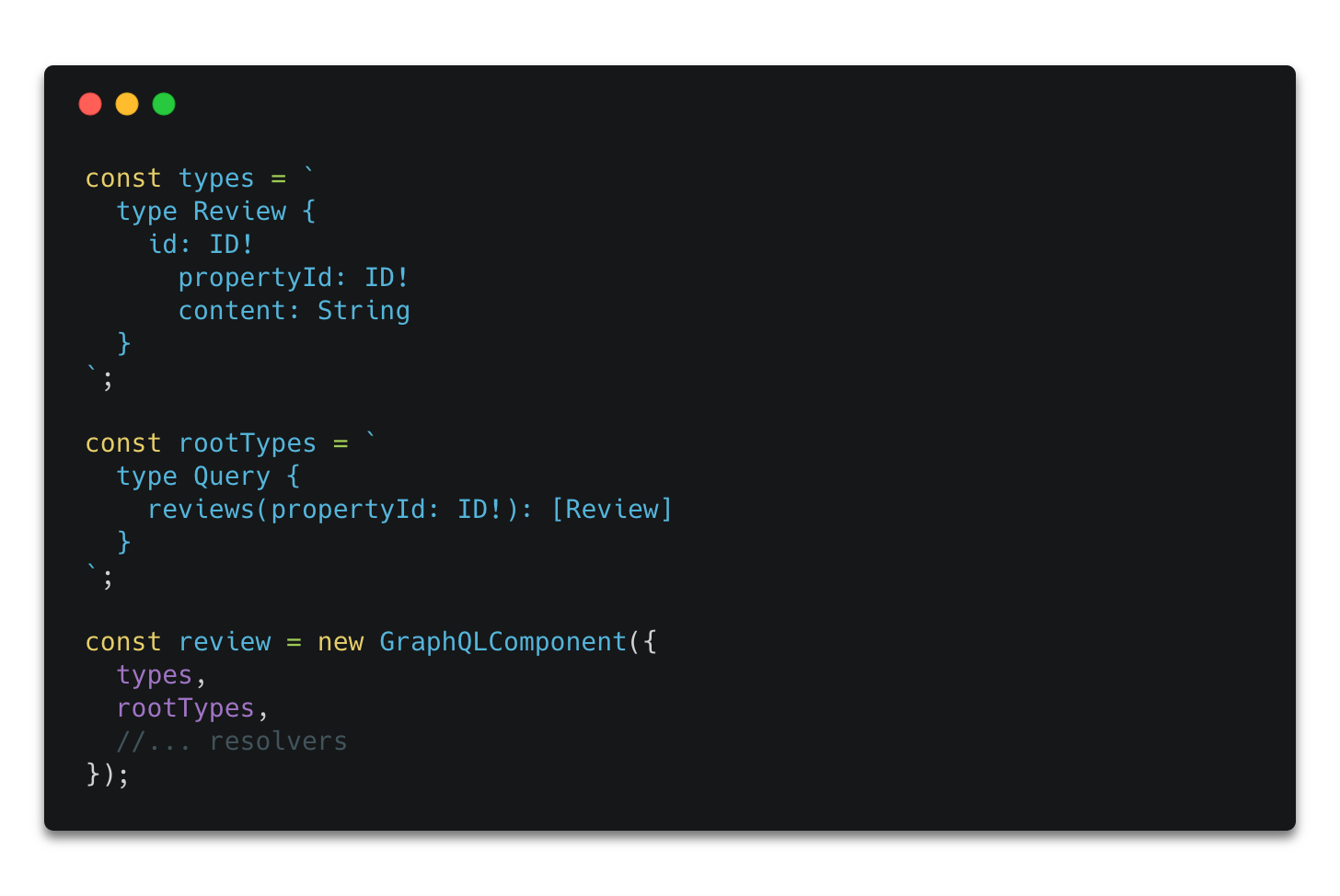
Example reviews component
Finally let’s compose these together into a Listing:
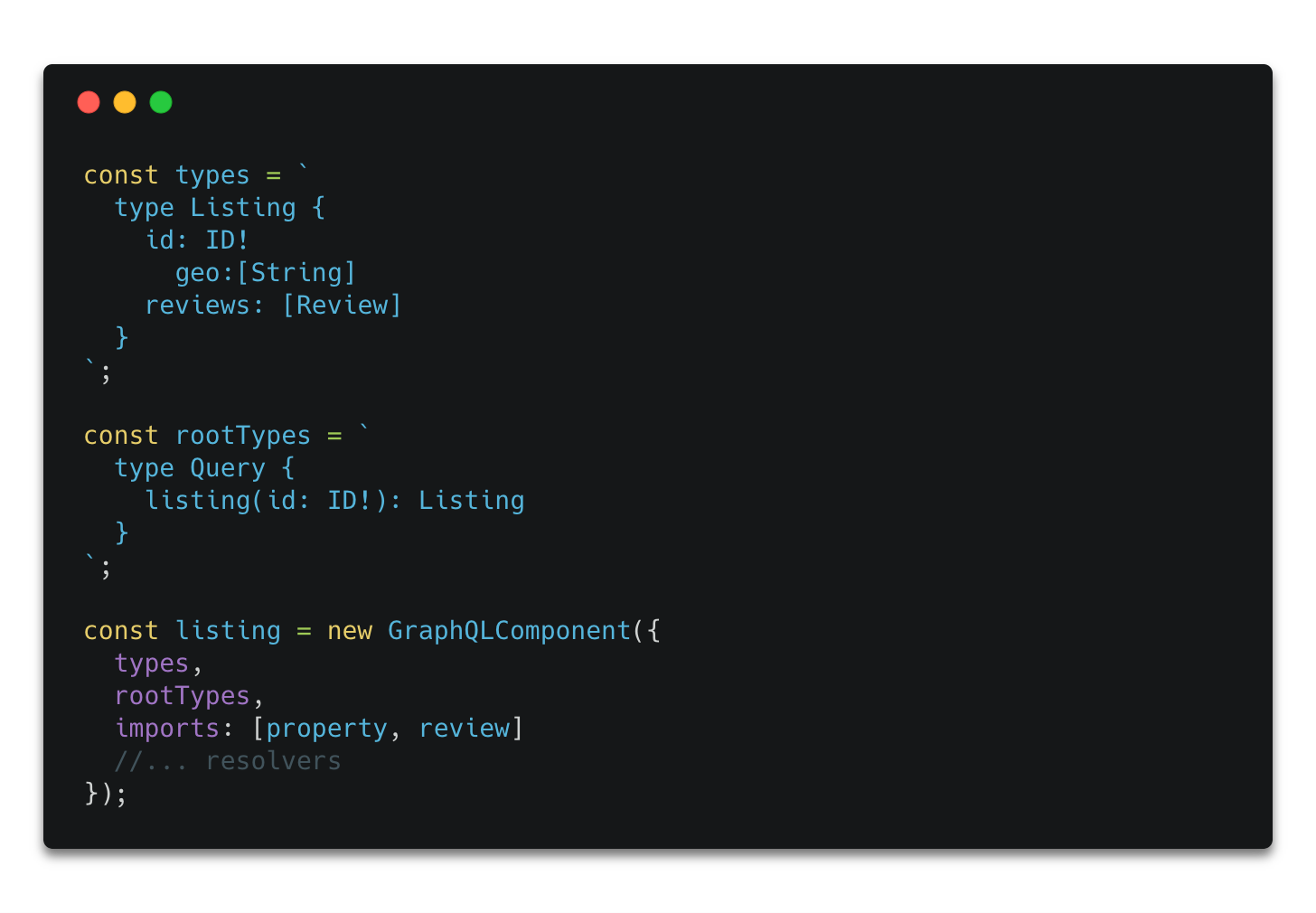
Example listing component
This is different because it also has a new declaration to import property and review. This enables listing to take advantage of both the types in these two components, as well as the resolvers.
In this last example, let’s take a look at the listing resolvers as well:

Example listing resolver
This makes the listing resolver delegate its primary query to property and review in parallel to form its base. The cool thing about this is that it does not simply invoke the resolver function, but rather executes through GraphQL. This lets both type validation and type resolvers to continue to run normally.
The rest of the shaping for Listing type is done with type resolvers (not shown here).
Collaboration
GraphQL is both a query language and type-based schema-first API specification.
One of the problems (and sometimes benefits) of REST is that it is not naturally schema-first. Tools like the OpenAPI specification often rely on after-the-fact generation of specification for documentation purposes only; there is no strict binding of API schema to implementation.
With GraphQL, the schema is the API, and that is a powerful thing.
Because we have relied on inner-source collaboration to develop many of our GraphQL components, the importance of being able to do so in a more accessible way has been critical.
Plain test and even separate .graphql files for type and root type definitions are much easier to read and collaborate on than code, not to mention agnostic to any particular language or platform.
Keeping in sync
When you start versioning modules independently, keeping teams moving off of unsupported versions requires additional tooling to keep track of dependencies and notify developers.
We keep track by building dependency graphs from applications which we can query and run reports to see who is using what.
Finally
In this journey, our evolution has been from monoliths, to miniliths and BFFs (back-ends-for-front-ends), to node apps and modules. But the journey isn’t complete. The industry is evolving to serverless and static pages (JAMStack, etc) and we have begun to as well. As a result, part of our design has also been about runtime portability as well as environment portability.
When it comes down to what it takes to develop a modern web application at Vrbo, it looks something like this:
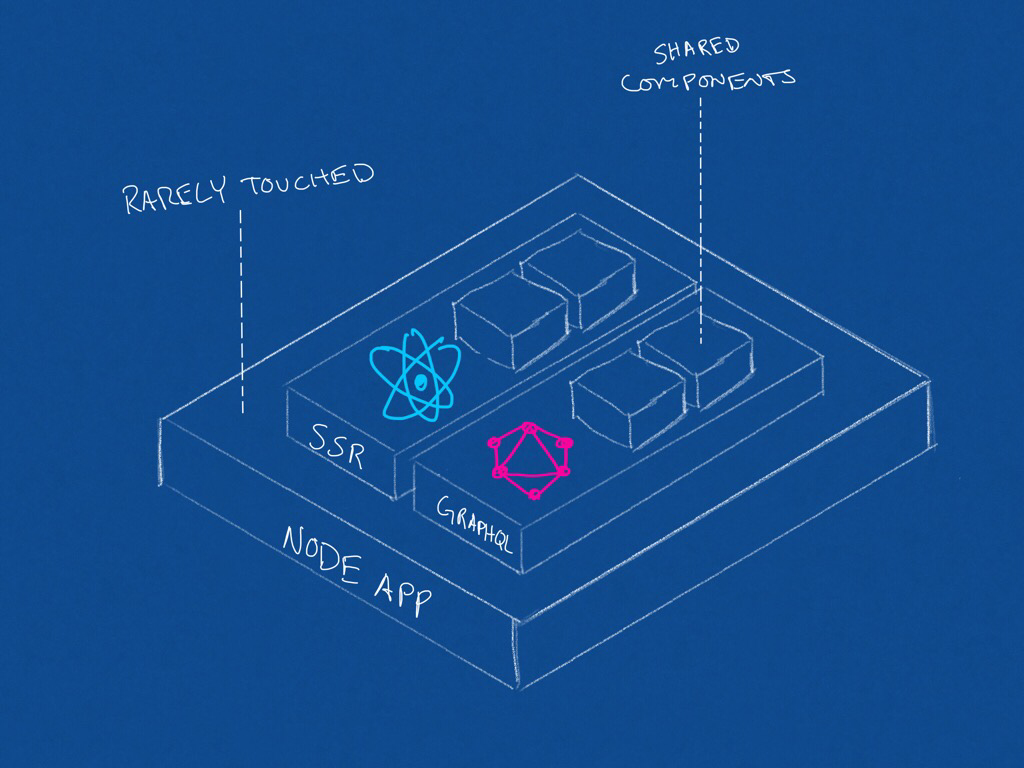
Diagram depicting an application comprised of SSR and GraphQL
Developers spend their time in two areas: React development and GraphQL development (which is usually just reused). This begs the question: why are we deploying applications at all?
With the advent of new capabilities in CDNs like compute with CloudFlare Workers, Fly.io, and others, a serverless (and even containerless) orchestration layer makes a lot of sense.

Diagram depicting GraphQL orchestration moving from web tier to CDN
We plan to experiment with pushing our model to the bleeding edge (pun intended), and it is made easier through a component model designed for flexibility and developer scale.
Further reading
While we were working on the next iteration of our partial schema / component model, a new open source project was released called GraphQL Modules. GraphQL follows an almost identical paradigm and looks great.
I’ve been working on a similar project in the open that is an iteration on our existing internal solution and that is what is used here for the examples. Currently, some simple examples can be seen here.
You can also read more about some of the history in these links:
The Architectural Principles Behind Vrbo’s GraphQL Implementation的更多相关文章
- Architectural principles
原文 "If builders built buildings the way programmers wrote programs, then the first woodpecker t ...
- Why GraphQL is Taking Over APIs
A few years ago, I managed a team at DocuSign that was tasked with re-writing the main DocuSign web ...
- Training - An Introduction to Enterprise Integration
What is EI? Enterprise Integration (EI) is a business computing term for the plans, methods, and too ...
- Three Sources of a Solid Object-Oriented Design
pingback :http://java.sys-con.com/node/84633?page=0,1 Object-oriented design is like an alloy consis ...
- Windows Kernel Security Training Courses
http://www.codemachine.com/courses.html#kerdbg Windows Kernel Internals for Security Researchers Thi ...
- Angular vs React---React-ing to change
这篇文章的全局观和思路一级棒! The Fairy Tale Cast your mind back to 2010 when users started to demand interactive ...
- 斯坦福CS课程列表
http://exploredegrees.stanford.edu/coursedescriptions/cs/ CS 101. Introduction to Computing Principl ...
- (转)Web2.0 大型互联网站点的架构
这种资料.向来可遇不可求啊 WikiPedia 技术架构学习分享 http://www.dbanotes.net/opensource/wikipedia_arch.html YouTube 的架构扩 ...
- Awesome Go
A curated list of awesome Go frameworks, libraries and software. Inspired by awesome-python. Contrib ...
随机推荐
- sqlserver分布式事务
启动服务中的Distributed Transaction Coodinator后 创建链接服务器ender-pc\subx 设定连接服务器RPC OUT 以及RPC属性为True 实验一下代码 创建 ...
- MySQL“慢SQL”定位
MySQL"慢SQL"定位 数据库调优我个人觉得必须要明白两件事 1.定位问题(你得知道问题出在哪里,要不然从哪里调优呢) 2.解决问题(这个没有基本的方法来处理,因为不同的问题处 ...
- efCore+Mysql+Net Core
1.首先新建一个空的Asp.net core项目 2.新建一个类 gj.cs public class gj { // <summary> /// 主键 /// </summa ...
- VsCode中编写python环境配置
1. VsCode中编写python环境配置 1.1. 前言 有过开发经验都知道idea一系列的软件虽然功能比较多,但比较容易卡,电脑不好还真容易上火,这里我想要入门python,还是选了款vscod ...
- 86.使用webpack爬过的坑
Webpack 4 和单页应用入门 https://github.com/wallstreetcn/webpack-and-spa-guide
- Java 之 lambda 表达式
一.函数式编程思想概述 在数学中,函数就是有输入量.输出量的一套计算方案,就是“拿什么东西做什么事情”.相对而言,面向对象过分强调“必须通过对象的形式来做事情”,而函数式思想则尽量忽略面向对象的复杂语 ...
- XML简述
XML简述 本文主要内容都是在中国大学MOOC上学习的,这里做个记录. 课程:Java核心技术(进阶),华东师范大学 陈良育老师 感谢陈良育老师,在他的慕课上受益匪浅. XML基本概念 XML(eXt ...
- vue脚手架引入MD5加密函数
可以在全局定义一个MD5的方法,然后引入到vue的脚手架中. 首先 npm install crypto --save 然后引用定义一个对象, import crypto from 'crypto'; ...
- Spark 安装教程
Spark 安装教程 本文原始地址:https://sitoi.cn/posts/45358.html 安装环境 Fedora 29 openjdk version "1.8.0_191&q ...
- Unity 渲染教程(五):多个光源
https://www.jianshu.com/p/c1a9a5d27765 对每个物体渲染多个光源的光照效果. 支持不同的光源类型. 使用光源cookie. 计算顶点光照. 在光照计算中添加球面谐波 ...