redis源码分析(五)--cluster(集群)结构
Redis集群
Redis支持集群模式,集群中可以存在多个master,每个master又可以拥有多个slave。数据根据关键字映射到不同的slot,每一个master负责一部分的slots,数据被存储在负责它的slot的master节点上。slave会同步它的master节点上的数据到本节点,当master节点挂掉时,slave可以上升为master节点继续服务,保障集群的完整性与可靠性。
Redis集群中的每一个节点都拥有其它所有节点的信息,任意节点都知道客户端请求的数据被存储在哪一个master节点上,因此客户端可以连接到任意节点执行操作。这不同于hdfs文件系统的namenode与datanode的概念,namenode一旦挂掉,整个系统就不可用了,namenode成为了系统的瓶颈。Redis中master不仅拥有多个slave,并且空闲的slave还可以在不同的master之间流动,加强集群的可靠性。
这篇文章主要介绍redis的集群结构及内部集群信息的管理,slave与master之间数据的同步将在其它文章中介绍。
1. Redis集群结构
Redis中存在多个master,每个master又可以有多个slave,现假设有集群中有9个节点,3个master,每个master节点又有2个slave,那么它的结构可以表示如图1-1:
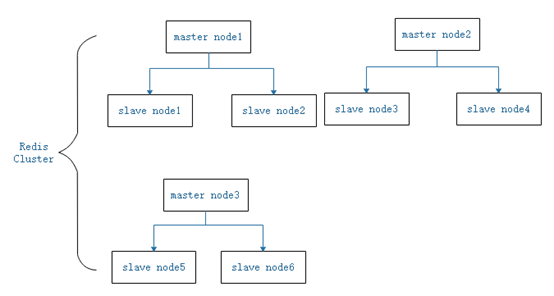
图1-1 集群结构图
不同的master可以拥有不同数量的slave,且集群中任意一个节点都与其它所有节点建立了连接,每一个节点都在称为cluster port的端口监听其它节点的集群通信连接。
2. Redis集群数据结构
与集群相关的数据结构主要有clusterState与clusterNode两个(在cluster.h源文件中声明):每一个redis实例拥有唯一一个clusterState实例,即server.cluster;而clusterNode的实例与集群中的节点数目n对应,每一个节点上都拥有n个clusterNode实例表示它知道的n个节点的信息,存储在clusterState结构的nodes成员中。
clusterState中有2个与集群结构相关的成员,声明如下(省略了大部分成员,仅留下了与集群整体结构相关的成员):
typedef struct clusterState {
clusterNode *myself; /* This node */
...
dict *nodes; /* Hash table of name -> clusterNode structures */
...
clusterNode *slots[CLUSTER_SLOTS];
...
} clusterState;
nodes成员是一个字典,以节点nameid为关键字,指向clusterNode的指针为值,假设集群有4个节点,那么nodes存储内容大致可以表示如下:
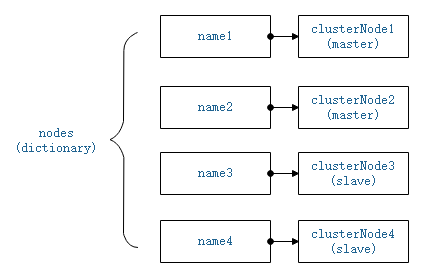
图2-1 nodes结构
集群中的节点都有一个nameid,以nameid为索引即可在nodes字典中找到描述该节点信息的clusterNode实例。而slots是一个clusterNode结构的指针数组,CLUSTER_SLOTS是redis中定义的支持的slot最大值,所有的key计算得到的slot都小于该值。slots[slot]存储着负责该slot的master节点的clusterNode结构的指针。每一个节点上都拥有该slots数组,因此在任意节点上都可以查找到负责某个slot的主节点的信息。假设集群拥有3个master节点,那么slots结构可表示如下:
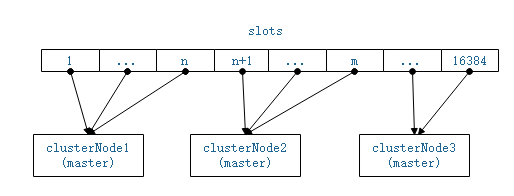
图2-2 clusterState中的指针数组slots
clusterNode结构描述了一个节点的基本信息,如ip,port, cluster port等,其声明如下:
typedef struct clusterNode {
mstime_t ctime; /* Node object creation time. */
char name[CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
int flags; /* CLUSTER_NODE_... */
...
unsigned char slots[CLUSTER_SLOTS/]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
int numslaves; /* Number of slave nodes, if this is a master */
struct clusterNode **slaves; /* pointers to slave nodes */
struct clusterNode *slaveof; /* pointer to the master node. Note that it
may be NULL even if the node is a slave
if we don't have the master node in our
tables. */
...
char ip[NET_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known clients port of this node */
int cport; /* Latest known cluster port of this node. */
clusterLink *link; /* TCP/IP link with this node */
...
} clusterNode;
name即是nodes字典中用作关键字的节点nameid
slots与clusterState中的slots有所不同,这里以bit的索引作为slot值,以该bit的状态标识该clusterNode对应的节点是否负责该slot。
slaves与slaveof代表了节点之间的master-slave关系。如果这是一个master节点,那么它的slave节点的clusterNode指针存储在slaves数组中;如果这是一个slave节点,那么slaveof指向了它的master节点的clusterNode。
link,指向当前节点与该clusterNode代表的节点之间的连接的相关信息,节点之间通过该link定期发送ping/pong消息。
在每一个节点中都维护了它知道的所有节点的clusterNode结构,从集群角度上来讲所有节点地位都是平等的,避免了瓶颈节点的出现。而这些结构中的信息主要用于节点之间的通信(即ping/pong),类似于心跳信息,维护整个集群的状态。
3. Redis集群通信结构
Redis集群中的节点没有namenode与datanode的区别,每一个节点都维护了所有节点的信息。如前一小节介绍,clusterNode结构中的link指向了当前节点与clusterNode所代表的节点之间的连接,Redis中每一个节点都与它所知道的所有节点之间维护了一个连接,通过这些连接发ping/pong消息,同步集群信息。集群中任意两个节点之间都建立了两个tcp连接,例如有nodeA与nodeB,那么nodeA中代表nodeB的clusterNode中有一个link维护了A主动与B建立的连接,而nodeB中代表nodeA的clusterNode中也有一个link维护了B主动与A建立的连接,即构建了一个全双工的通信链路。假设集群中存在3个节点,那么它们之间的通信结构如下所示:
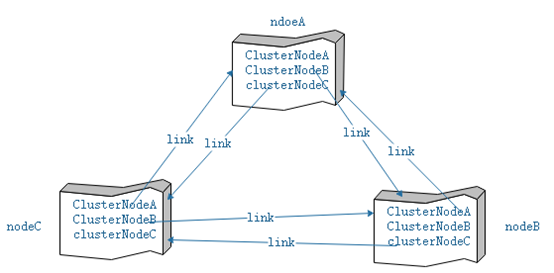
图3-1 3个节点的集群通信结构
注意每个节点也维护了自身的clusterNode结构,并且在clusterState中使用myself指向它。方便修改自身节点的状态。
4. link的建立与节点发现
每一个节点都会在cluster port端口监听tcp连接请求,参见clusterInit函数,并且每个节点都有一个定时任务clusterCron,其中会遍历nodes字典,检测其中的clusterNode的link是否建立,如果没有建立连接,那么会主动连接该clusterNode所代表的节点建立连接。如果nodes字典中没有某个节点clusterNode结构,那么便不会与它建立连接。
建立clusterNode的时机大致有如下几处:
- 从文件中加载节点信息建立 clusterNode结构,在函数clusterLoadConfig中。
- 客户端执行meet命令告知节点信息,建立相应的clusterNode结构,由函数clusterCommand调用clusterStartHandshake完成。
- 接收到meet类消息,建立与发送方对应的clusterNode结构,在函数clusterProcessPacket中。
- 接收到的ping/pong/meet消息中带有其它不知道的节点信息,建立相应的clusterNode结构,同样在clusterProcessPacket函数中,调用clusterStartHandshake完成。
新建立的clusterNode的nameid是随机的,并且此时的clusterNode中flag设置为CLUSTER_NODE_HANDSHAKE状态,表示尚未首次通信。当clusterCron中建立相应的link,并发送ping/meet消息,收到响应消息(Pong)时去除CLUSTER_NODE_HANDSHAKE状态,并将clusterNode的nameid修改为响应消息中附带的nameid,至此成功建立一个方向的连接,反方向的连接由对方主动发起建立。
5. Redis处理通信的函数结构
- clusterInit中监听端口cport,注册读事件,响应函数为clusterAcceptHandler。
- clusterCron中主动建立连接,并将连接结构保存到clusterNode中的link指针中。注册读事件,响应函数为clusterReadHandler,并主动发送ping/meet消息,若先前未注册写事件,则为该link注册写事件,响应函数为clusterWriteHandler。
- clusterAcceptHandler中接受连接后建立link结构(未保存),并注册读事件,响应函数为clusterReadHandler。
- clusterReadHandler中接收数据,当接收到一个完整的消息后,调用clusterProcessPacket函数处理。
Redis中定义了集群通信消息的结构,每一个消息至少包含一个消息头,而消息头中包含整个消息的长度,因此clusterReadHandler中可以判断是否接收到一个完整的数据包。
link指向的结构中包含了sndbuf与rcvbuf两个缓存,其定义如下:
/* clusterLink encapsulates everything needed to talk with a remote node. */
typedef struct clusterLink {
mstime_t ctime; /* Link creation time */
int fd; /* TCP socket file descriptor */
sds sndbuf; /* Packet send buffer */
sds rcvbuf; /* Packet reception buffer */
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;
clusterWriteHandler负责将sndbuf中的数据发送出去,clusterReadHandler负责将数据接收到rcvbuf中,需要发送的集群数据都先填充到sndbuf中,需要接收到数据都先缓存到rcvbuf中,rcvbuf中积累了一个完整数据包再由clusterProcessPacket函数处理。通过缓存将io与数据包处理逻辑分离,简化代码结构。
redis源码分析(五)--cluster(集群)结构的更多相关文章
- redis源码分析(六)--cluster集群同步
Redis集群消息 作为支持集群模式的缓存系统,Redis集群中的各个节点需要定期地进行通信,以维持各个节点关于其它节点信息的实时性与一致性.如前一篇文章介绍的,Redis在专用的端口监听集群其它节点 ...
- Redis源码解析:26集群(二)键的分配与迁移
Redis集群通过分片的方式来保存数据库中的键值对:一个集群中,每个键都通过哈希函数映射到一个槽位,整个集群共分16384个槽位,集群中每个主节点负责其中的一部分槽位. 当数据库中的16384个槽位都 ...
- Redis源码解析:25集群(一)握手、心跳消息以及下线检测
Redis集群是Redis提供的分布式数据库方案,通过分片来进行数据共享,并提供复制和故障转移功能. 一:初始化 1:数据结构 在源码中,通过server.cluster记录整个集群当前的状态,比如集 ...
- Redis源码解析:28集群(四)手动故障转移、从节点迁移
一:手动故障转移 Redis集群支持手动故障转移.也就是向从节点发送"CLUSTER FAILOVER"命令,使其在主节点未下线的情况下,发起故障转移流程,升级为新的主节点,而原 ...
- Redis源码解析:27集群(三)主从复制、故障转移
一:主从复制 在集群中,为了保证集群的健壮性,通常设置一部分集群节点为主节点,另一部分集群节点为这些主节点的从节点.一般情况下,需要保证每个主节点至少有一个从节点. 集群初始化时,每个集群节点都是以独 ...
- redis源码分析之事务Transaction(下)
接着上一篇,这篇文章分析一下redis事务操作中multi,exec,discard三个核心命令. 原文地址:http://www.jianshu.com/p/e22615586595 看本篇文章前需 ...
- Redis源码分析:serverCron - redis源码笔记
[redis源码分析]http://blog.csdn.net/column/details/redis-source.html Redis源代码重要目录 dict.c:也是很重要的两个文件,主要 ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- Spring5源码分析(1)设计思想与结构
1 源码地址(带有中文注解)git@github.com:yakax/spring-framework-5.0.2.RELEASE--.git Spring 的设计初衷其实就是为了简化我们的开发 基于 ...
随机推荐
- 进阶blog整理
https://blog.csdn.net/zhangerqing https://bbs.csdn.net/topics/310072893 SCJP
- nginx 日志之 access_log格式
Nginx访问日志可以设置自定义的格式,来满足特定的需求. 示例: 示例1 log_format combined_realip '$remote_addr $http_x_forwarded_for ...
- Cisco路由器用SSH替代Telnet连接
本文告诉你若何用SSH替代Telnet. 使用Telnet这个用来访谒远程计较机的TCP/IP和你的用户名和口令.很快地,会有人进行监听,而且他们会操作你平安是因为你意识的缺乏. SSH是替代Teln ...
- [技术博客]react native事件监听、与原生通信——实现对通知消息的响应
在react native中会涉及到很多页面之间的参数传递问题.静态的参数传递通常利用组件的Props属性,在初始化组件时即可从父组件中将参数传递到子组件中.对于非父子关系的组件来说,无法直接传递参数 ...
- java中过滤器(Filter)与拦截器(Interceptor )区别
过滤器(Filter) Servlet中的过滤器Filter是实现了javax.servlet.Filter接口的服务器端程序,主要的用途是设置字符集.控制权限.控制转向.做一些业务逻辑判断等.其工作 ...
- adb命令和fastboot有什么区别
ADB中文解释就是调试桥的作用.既然是调试作用,需要开机并连接电脑,所以adb的命令是需要手机开启usb调试,比较典型的命令比如从电脑端敲入adb命令来安应用:adb install .还有一个命令我 ...
- SpringBoot——配置文件加载位置及外部配置加载顺序
声明 本文部分转自:SpringBoot配置文件加载位置与优先级 正文 1. 项目内部配置文件 spring boot 启动会扫描以下位置的application.properties或者applic ...
- iOS逆向(五)-ipa包重签名
为什么要重签名? 1.在没有源代码的情况下,你已经对某个应用进行了资源修改(比如修改了启动图或图标等).修改完成以后,如果想要让APP可以正常使用,该APP一定要重新签名然后压缩成IPA文件. 2.如 ...
- html5统计数据上报API:SendBeacon
公司为了精准的了解自己产品的用户使用情况,通常会对用户数据进行统计分析,获取pv.uv.页面留存率.访问设备等信息.与之相关的就是客户端的数据采集,然后上报的服务端.为了保证数据的准确性,就需要保证数 ...
- 【专】linux nameserver导致的故障
前言: 大家都知道linux下添加dns服务器,修改/etc/resolv.conf,添加nameserver 119.29.29.29这样一行即可.但是胡乱添加nameserver也会导致故障 ,此 ...