Cloudera Certified Associate Administrator案例之Configure篇
Cloudera Certified Associate Administrator案例之Configure篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.下载CDH集群中最新的配置文件
问题描述:
某个集群的使用者需要通过客户端登陆集群,请使用CM下载HDFS和YARN的配置文件,保存到客户端机器的"/home/yinzhengjie/hadoop/etc/hadoop"目录下,并保持文件名不变。 解决方案:
可以通过登陆CM WebUI界面下载,也可以直接登陆服务器进行下载。
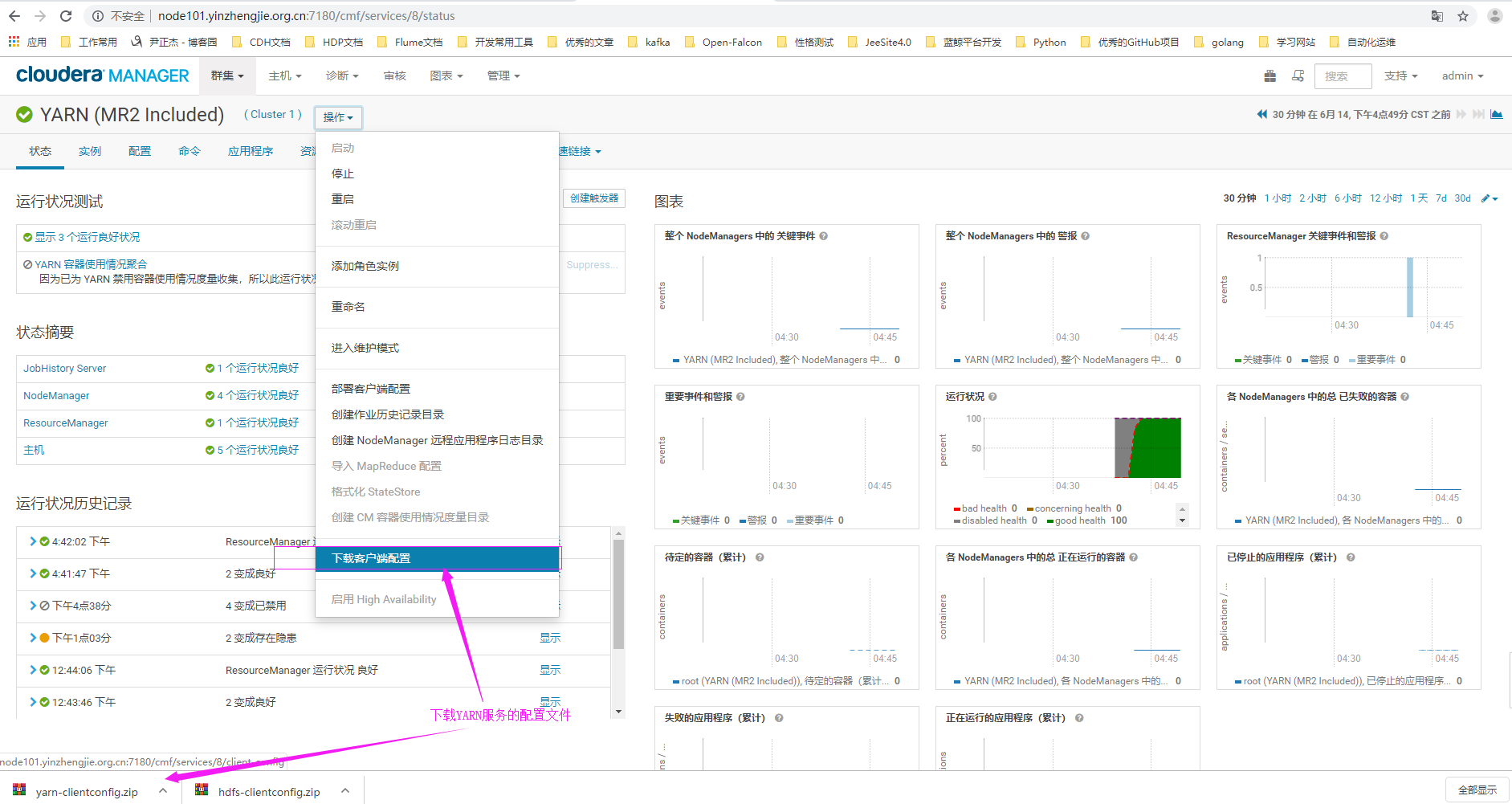
1>.使用正确的用户名密码登录CM界面,点击hdfs服务

2>. 下载HDFS的配置文件

3>.使用正确的用户名密码登录CM界面,点击yarn服务
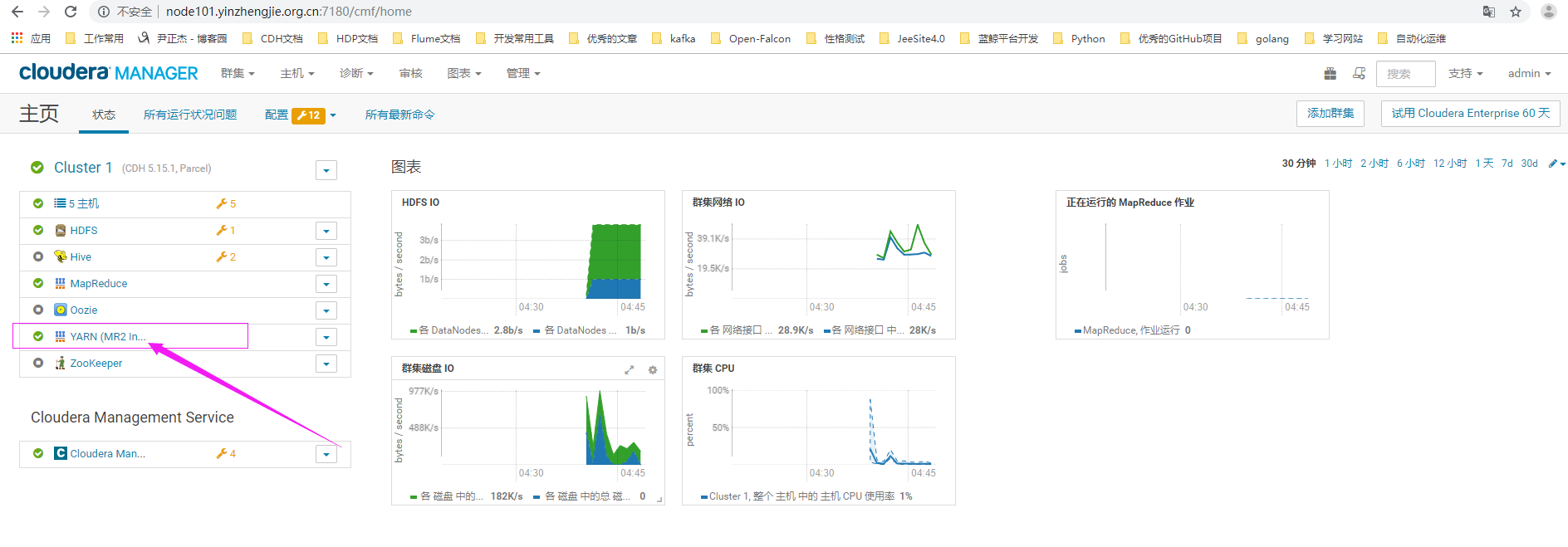
4>.下载YARN服务的配置文件
5>.查看集群后端存储配置文件的路径
[root@node101.yinzhengjie.org.cn ~]# ll /etc/hadoop/conf.cloudera.hdfs/ #HDFS集群存储路径
total
-rw-r--r-- root root Jun : __cloudera_generation__
-rw-r--r-- root root Jun : __cloudera_metadata__
-rw-r--r-- root root Jun : core-site.xml
-rw-r--r-- root root Jun : hadoop-env.sh
-rw-r--r-- root root Jun : hdfs-site.xml
-rw-r--r-- root root Jun : log4j.properties
-rw-r--r-- root root Jun : ssl-client.xml
-rw-r--r-- root root Jun : topology.map
-rwxr-xr-x root root Jun : topology.py
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# ll /etc/hadoop/conf.cloudera.yarn/ #YARN集群存储路径
total
-rw-r--r-- root root Jun : __cloudera_generation__
-rw-r--r-- root root Jun : __cloudera_metadata__
-rw-r--r-- root root Jun : core-site.xml
-rw-r--r-- root root Jun : hadoop-env.sh
-rw-r--r-- root root Jun : hdfs-site.xml
-rw-r--r-- root root Jun : log4j.properties
-rw-r--r-- root root Jun : mapred-site.xml
-rw-r--r-- root root Jun : ssl-client.xml
-rw-r--r-- root hadoop Jun : topology.map
-rwxr-xr-x root hadoop Jun : topology.py
-rw-r--r-- root root Jun : yarn-site.xml
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
二.限制HDFS服务的日志大小
问题描述:
根据管理要求,需要限制HDFS服务的日志大小。其限制为:NameNode服务保留4个日志文件,总量不超过8GB;Secondary NameNode 服务也保留4个日志文件,总量不超过8GB;两个服务总占用的磁盘空间 量不超过16GB。 解决方案:
单个服务的单个日志只要不超 过2GB,并将日志数设为4个,即可以满足要求。
1>.使用正确的用户名密码登录CM界面,点击hdfs服务
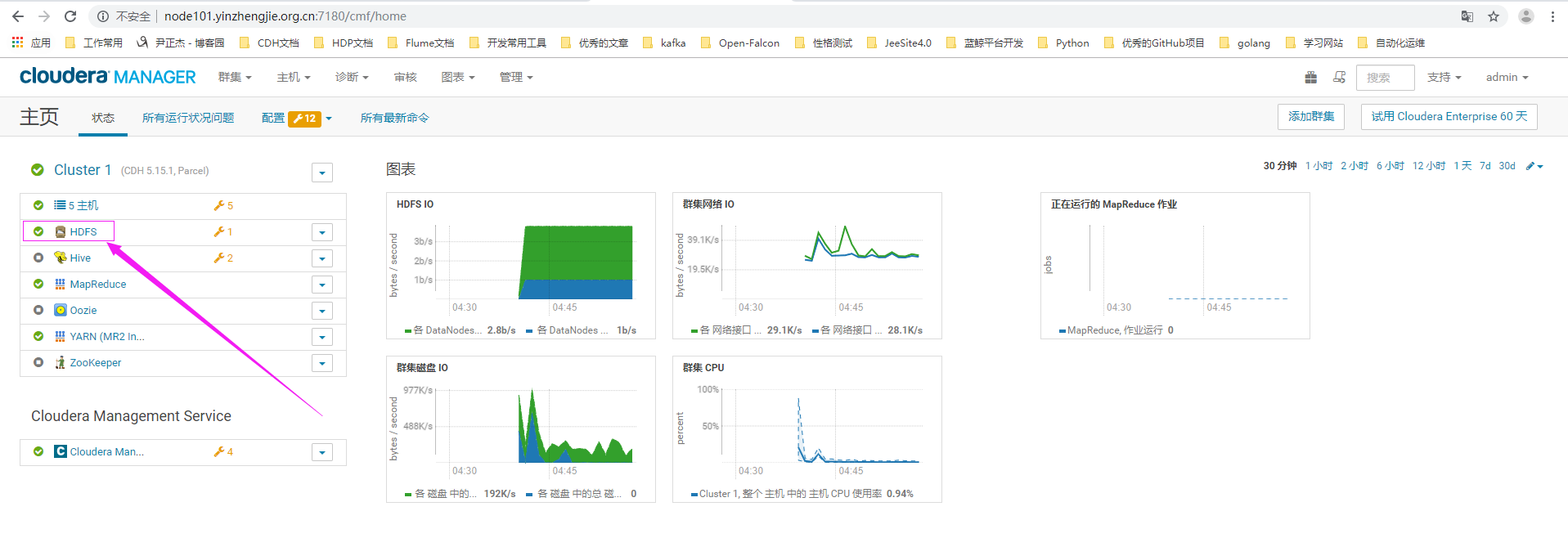
2>.搜索关键字“NameNode Max Log Size”
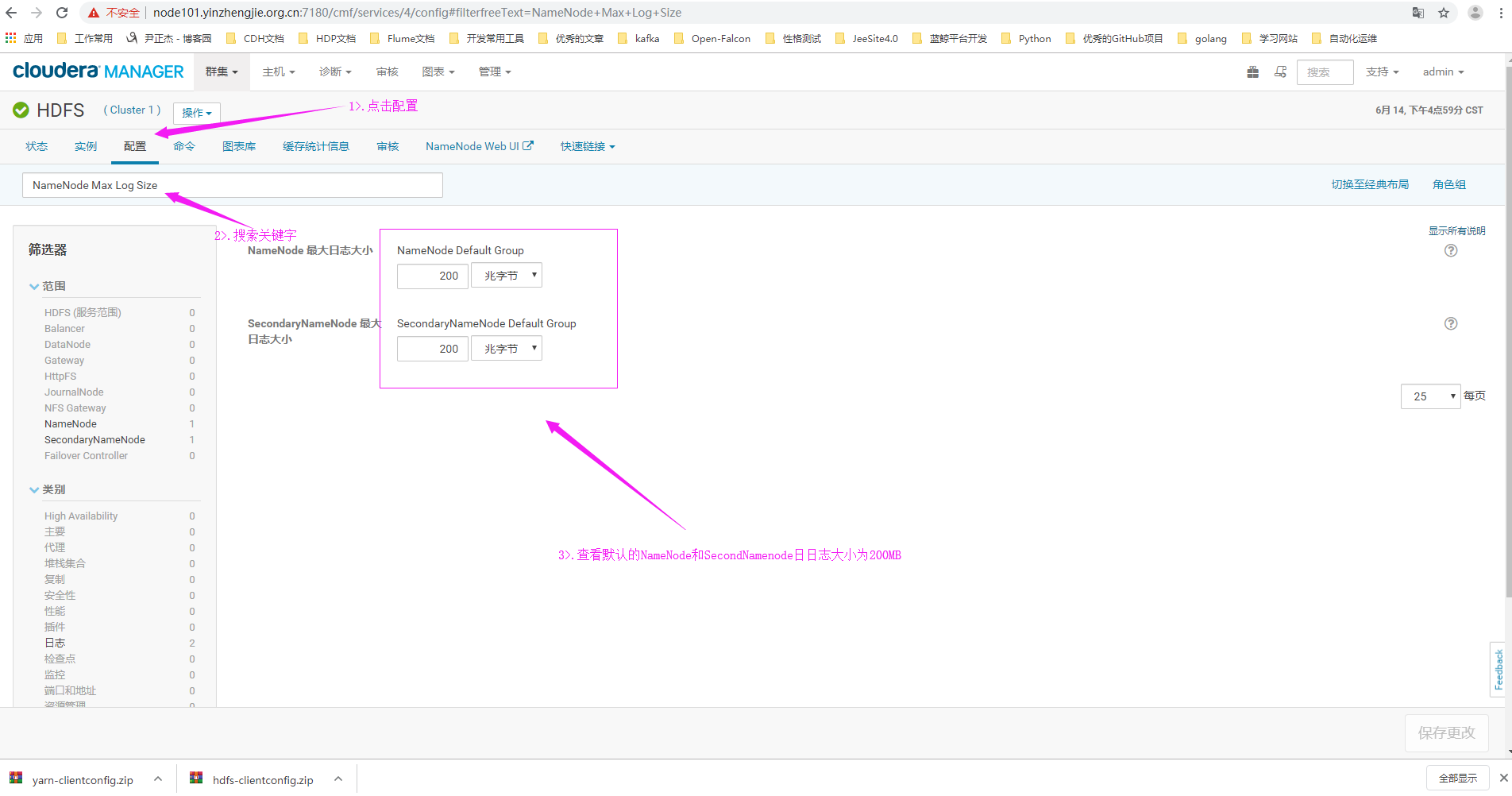
3>.修改默认值200MB为2GB并点击保存按钮

4>.搜索关键字“SecondaryNameNode Max Log Size”(中文对应:"SecondaryNameNode 最大日志文件备份")
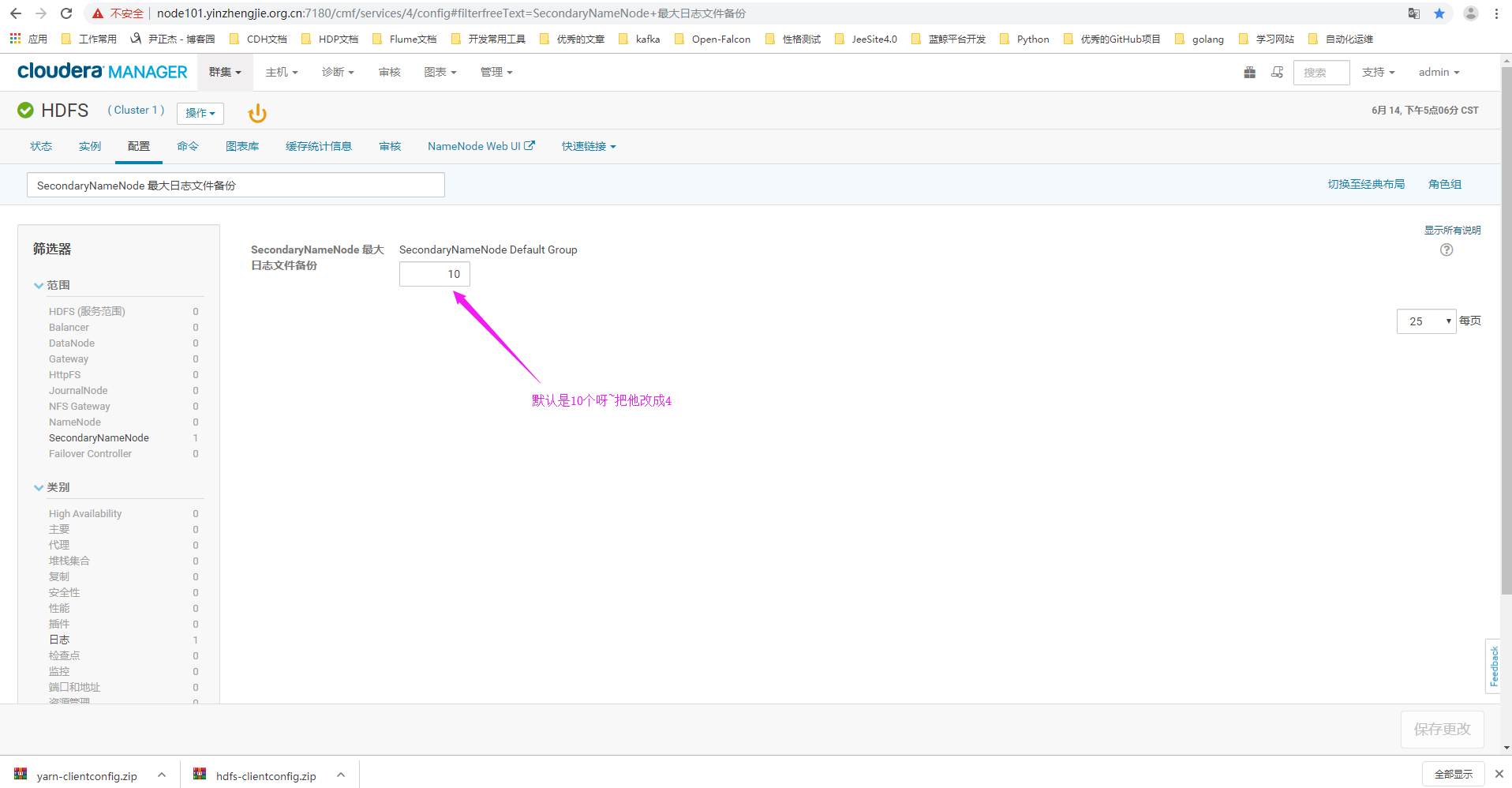
5>.修改日志文件的备份数为4
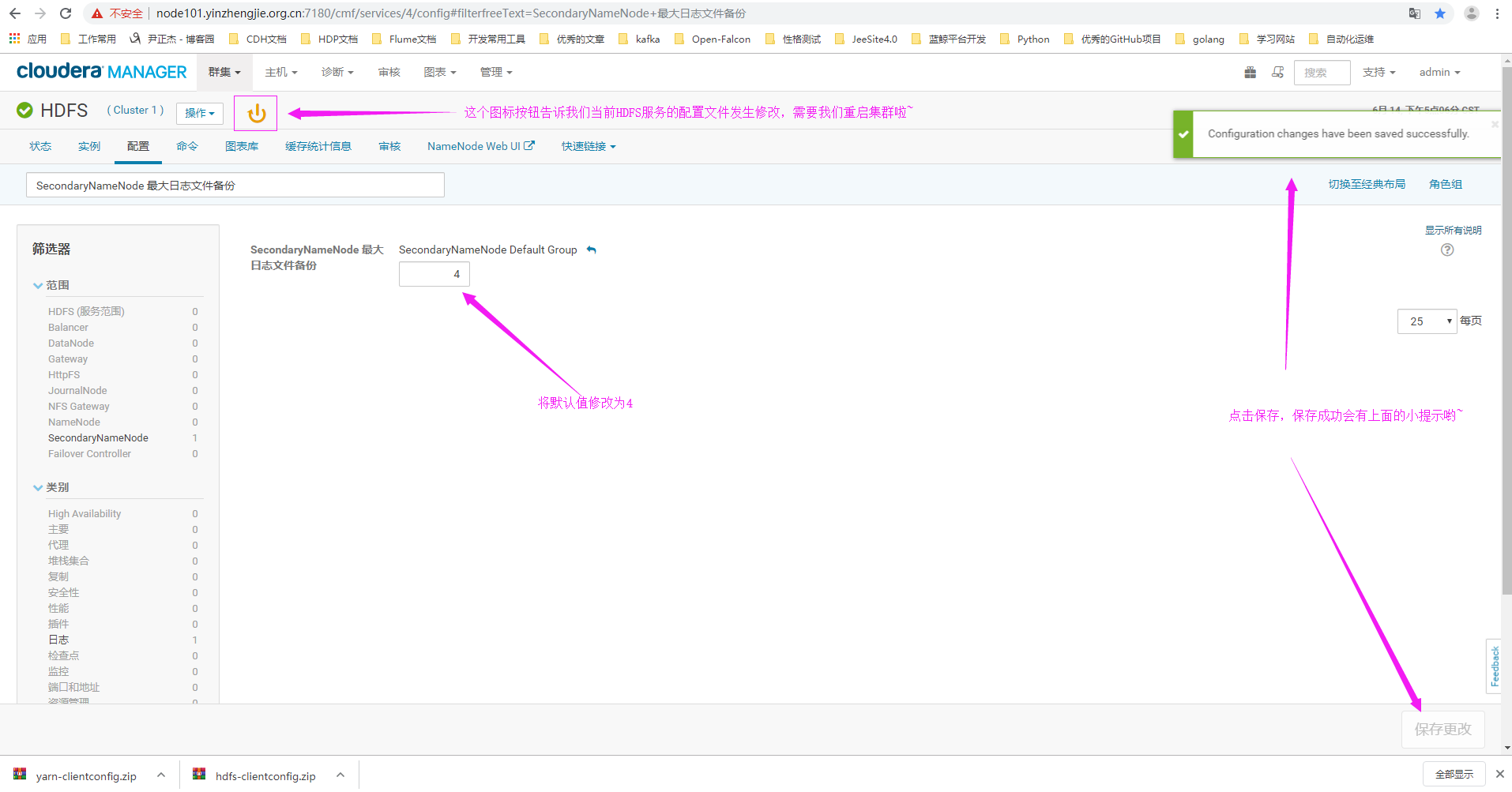
6>.重启HDFS服务

三.修改Namenode的堆内存
问题描述:
集群承接了日志分析需求,将保存百万、千万数量级的文件,因 此需要扩大NameNode使用的堆内存,使其可以管理尽可能多的文件。物理内存的分配要求为:节点总物理内存为31GB,为系统服务保留的内存为6.2GB;NameNode和Secondary NameNode需设置相等大小的堆内存; 所有服务的堆内存均需要乘以1.3后计入总使用量中。需要为NameNode和相关服务配置尽可能大且满足要求的内存量,且不能触发任何警告。 解决方案:
根据计算(31 - 6.2) / 1.3 = 19,因此 NameNode和Secondary NameNode各可设置9.5GB的堆内存。
1>.使用正确的用户名密码登录CM界面,点击hdfs服务
2>.点击配置,搜索关键字“Java Heap Size of NameNode in Bytes”(对应中文为:"NameNode 的 Java 堆栈大小(字节)")
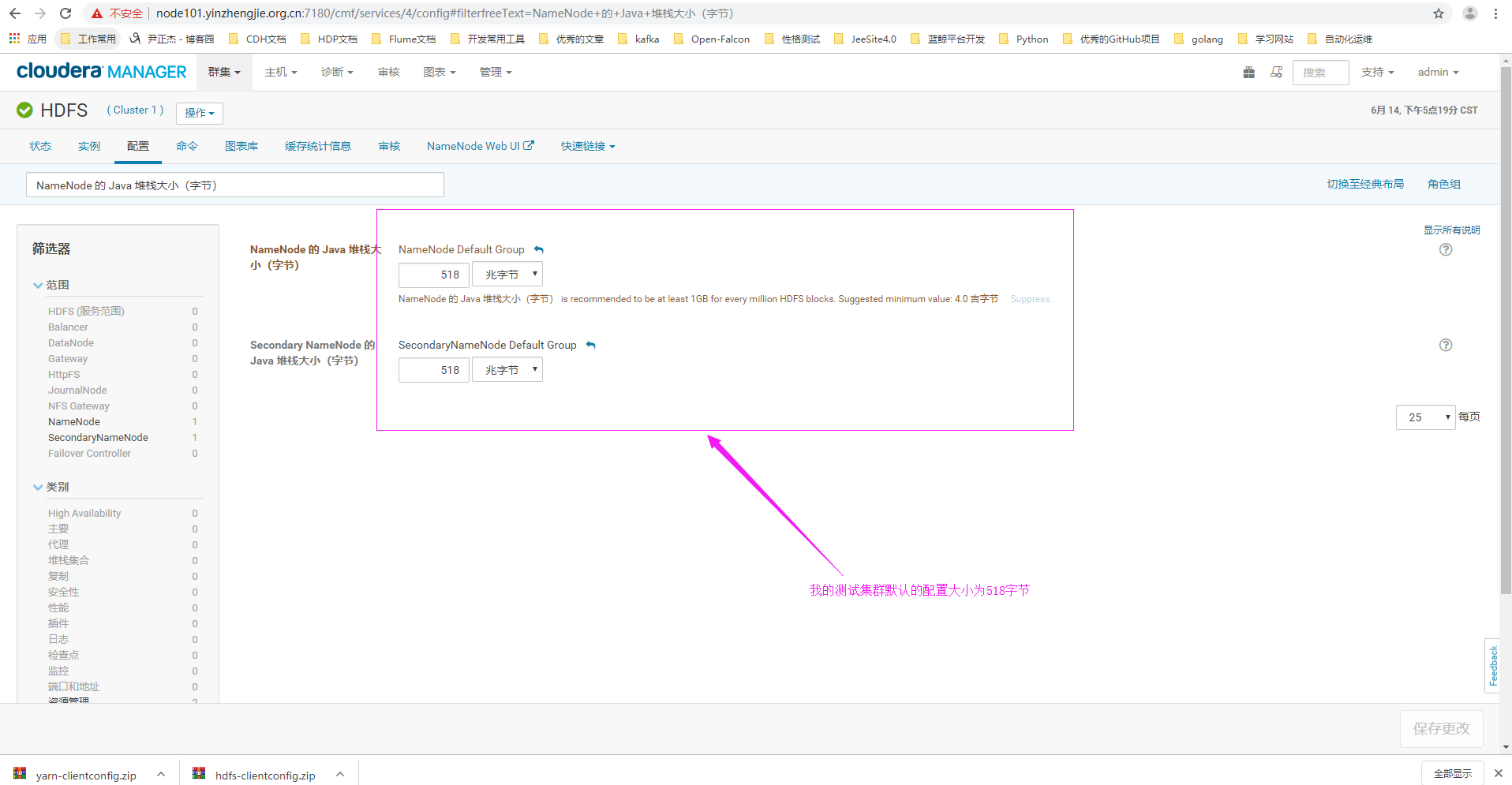
3>.设置NameNode和SencondName的堆内存为9.5GB
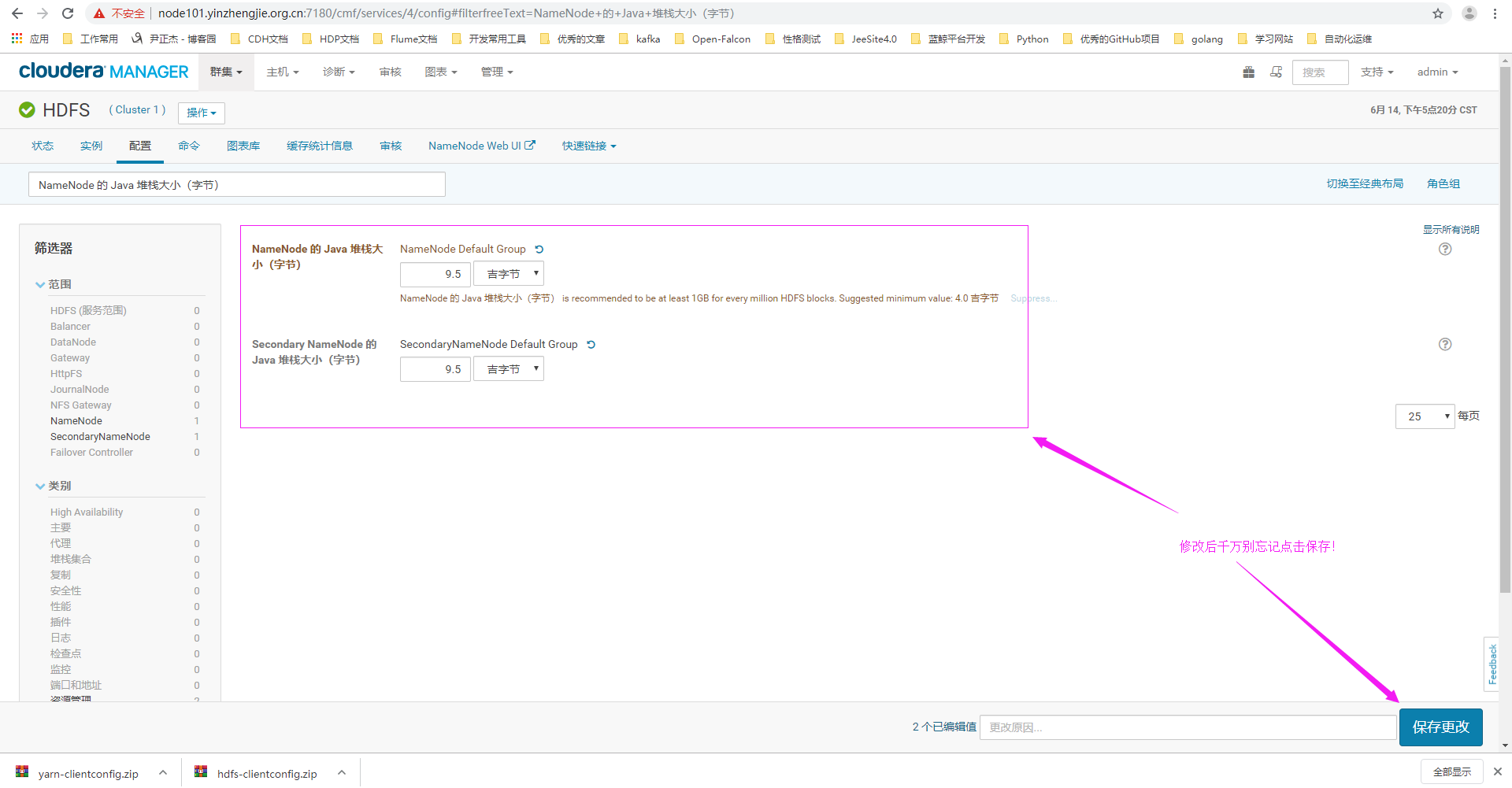
4>.重启HDFS集群(需要注意的是,如果我们设置的NameNode或者SecondNamenode的堆内存大小总和大于当前服务器内存时,我们在重启集群时会启动失败!)
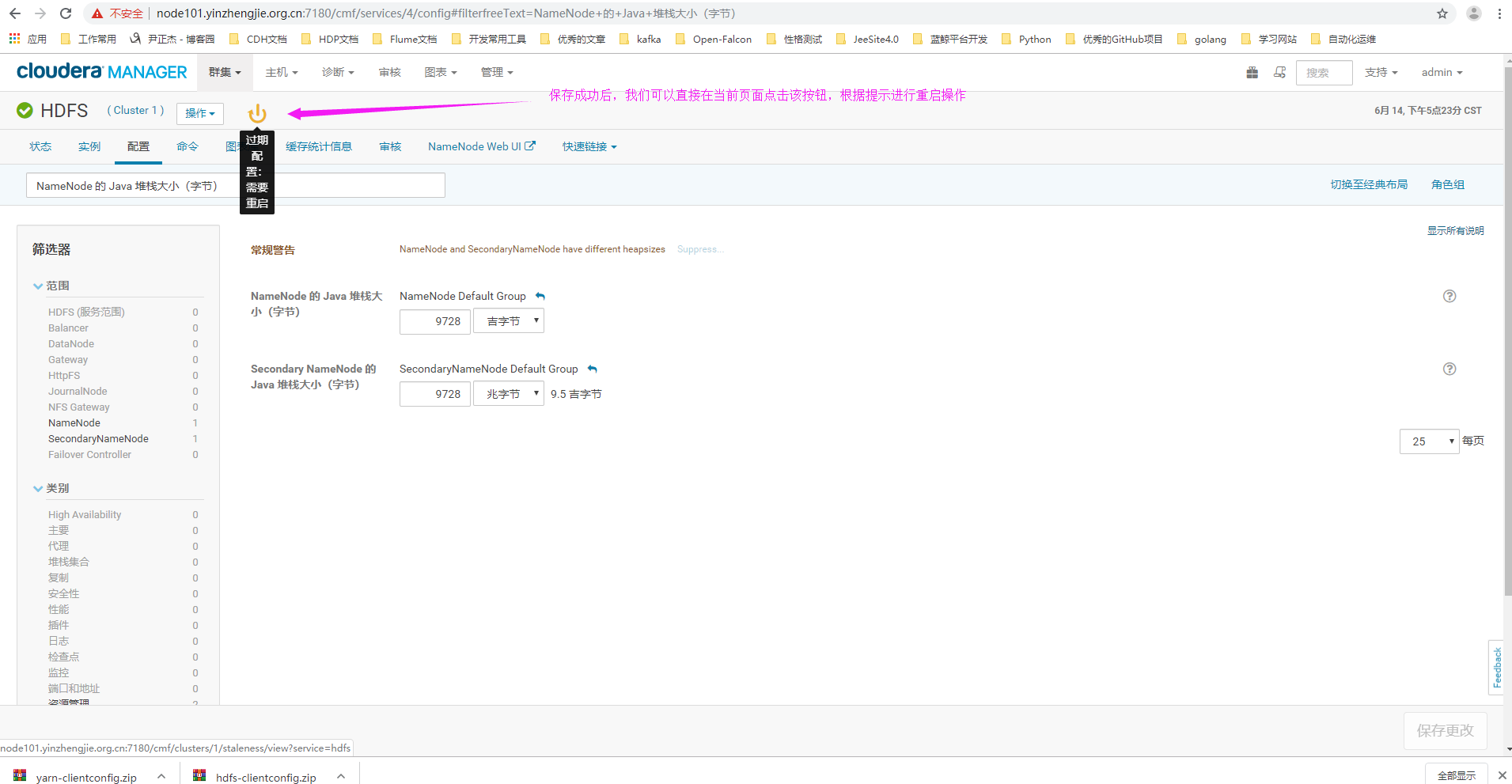
四.开启回收站功能
问题描述:
在描述公司的运维策略时,有人提出如果误删了HDFS的文件系统,可能几天都不会出现,尤其时当周末前发生这样的情况时。为了提供足够的保护级别,你决定将HDFS数据删除后永久清除的时间改为7天。 解决方案:
我们直接在Cloudera Manager WebUI界面进行配置即可。除了配置回收站,还可以配置权限,副本书,块大小,balancer等。
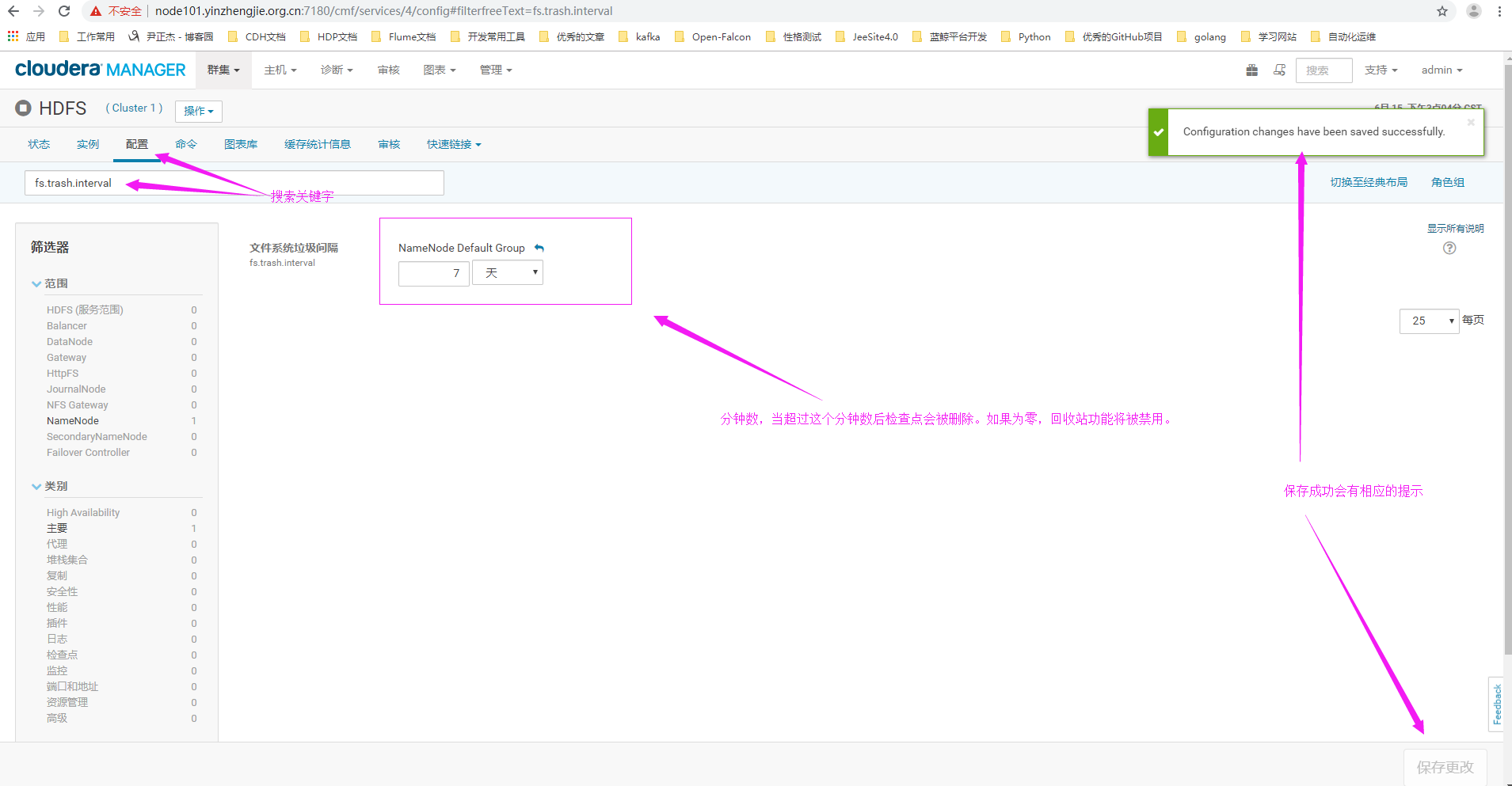
1>.点击HDFS服务

2>.点击配置,并搜索关键字"fs.trash.interval",修改其只为7天,即删除的文件在回收站中被保留的时间周期
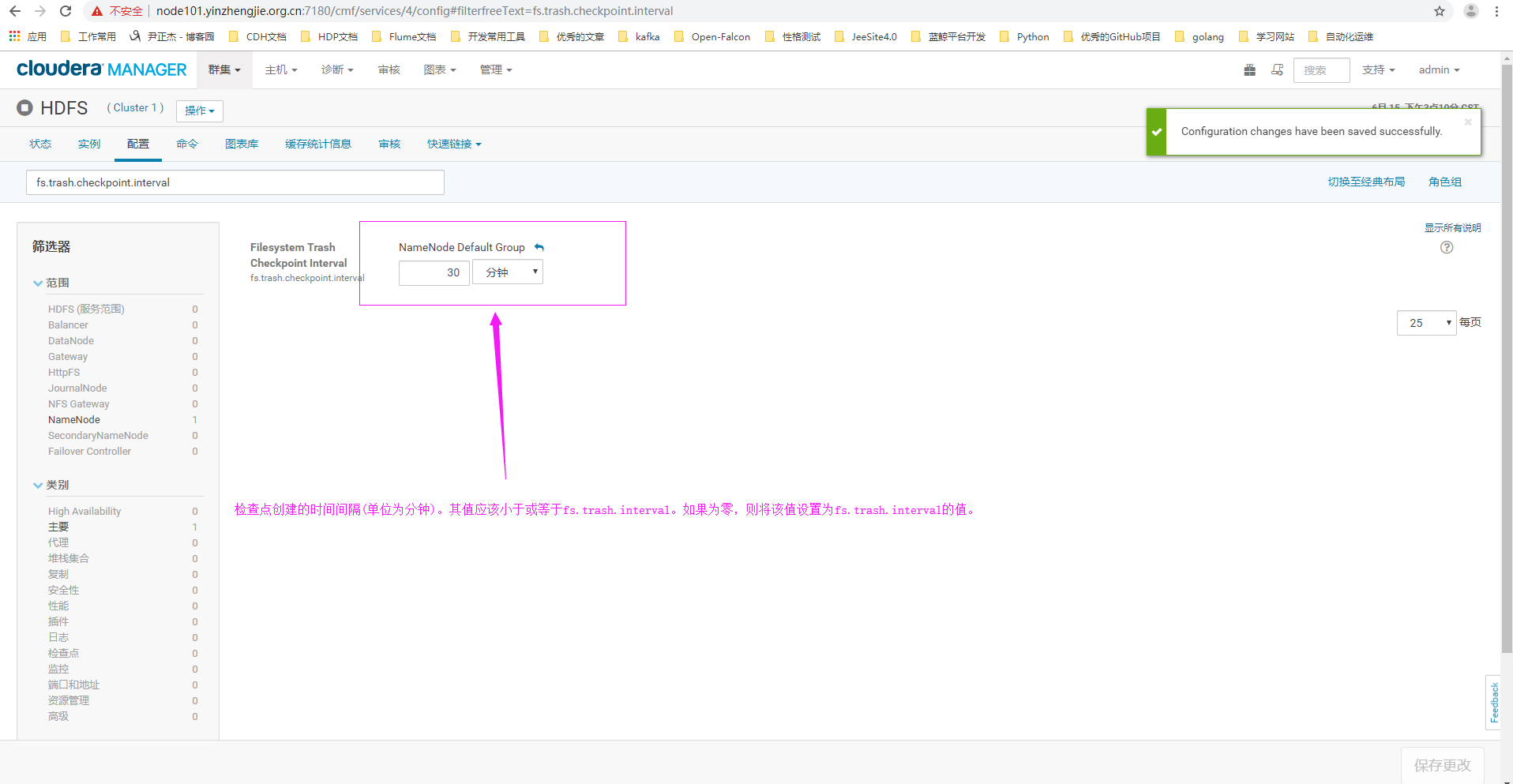
3>.搜索关键词"fs.trash.checkpoint.interval",即定义周期性检查回收站的文件是否过期的时间间隔,改值应该小于上面我们定义"fs.trash.interval"的值
五.
Cloudera Certified Associate Administrator案例之Configure篇的更多相关文章
- Cloudera Certified Associate Administrator案例之Troubleshoot篇
Cloudera Certified Associate Administrator案例之Troubleshoot篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.调整日志的进 ...
- Cloudera Certified Associate Administrator案例之Test篇
Cloudera Certified Associate Administrator案例之Test篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.准备工作(将CM升级到&qu ...
- Cloudera Certified Associate Administrator案例之Manage篇
Cloudera Certified Associate Administrator案例之Manage篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载Namenode镜像 ...
- Cloudera Certified Associate Administrator案例之Install篇
Cloudera Certified Associate Administrator案例之Install篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.创建主机模板(为了给主 ...
- Flume实战案例运维篇
Flume实战案例运维篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Flume概述 1>.什么是Flume Flume是一个分布式.可靠.高可用的海量日志聚合系统,支 ...
- CNCF基金会的Certified Kubernetes Administrator认证考试计划
关于CKA考试 CKA(Certified Kubernetes Administrator)是CNCF基金会(Cloud Native Computing Foundation)官方推出的Kuber ...
- 分享数百个 HT 工业互联网 2D 3D 可视化应用案例之 2019 篇
继<分享数百个 HT 工业互联网 2D 3D 可视化应用案例>2018 篇,图扑软件定义 2018 为国内工业互联网可视化的元年后,2019 年里我们与各行业客户进行了更深度合作,拓展了H ...
- 数百个 HT 工业互联网 2D 3D 可视化应用案例分享 - 2019 篇
继<分享数百个 HT 工业互联网 2D 3D 可视化应用案例>2018 篇,图扑软件定义 2018 为国内工业互联网可视化的元年后,2019 年里我们与各行业客户进行了更深度合作,拓展了H ...
- robotframework+selenium搭配chrome浏览器,web测试案例(搭建篇)
这两天发布版本 做的事情有点多,都没有时间努力学习了,先给自己个差评,今天折腾了一天, 把robotframework 和 selenium 还有appnium 都研究了一下 ,大概有个谱,先说说we ...
随机推荐
- SQL Server常用方法
目录 CharIndex:确定某个字符的位置 Substring:截取 stuff: 根据位置替换字符串 replace:替换字符串 CharIndex:确定某个字符的位置 两个参数,前面是关键字,后 ...
- 阿里云k8s事件监控
事件监控是Kubernetes中的另一种监控方式,可以弥补资源监控在实时性.准确性和场景上的缺欠.Kubernetes的架构设计是基于状态机的,不同的状态之间进行转换则会生成相应的事件,正常的状态之间 ...
- 20.Python略有小成(面向对象Ⅱ)
Python(面向对象Ⅱ) 一.类的空间问题 何处可以添加对象属性 class A: def __init__(self,name): self.name = name def func(self,s ...
- day54——jquery补充、bootstrap
day54 jquery 页面载入 window.onload: 原生js的window.onload事件:// onload 等待页面所有内容加载完成之后自动触发的事件 window.onload ...
- leetcode的Hot100系列--347. 前 K 个高频元素--hash表+直接选择排序
这个看着应该是使用堆排序,但我图了一个简单,所以就简单hash表加选择排序来做了. 使用结构体: typedef struct node { struct node *pNext; int value ...
- libevent源码分析一--io事件响应
这篇文章将分析libevent如何组织io事件,如何捕捉事件的发生并进行相应的响应.这里不会详细分析event与event_base的细节,仅描述io事件如何存储与如何响应. 1. select l ...
- [cf 1194 D] 1-2-K Game
(当时让这道sb题卡住了,我比sb还sb) 题意: n个东西,两个人轮流取,每次可以取走1个,2个或k个,不能取的人输,求谁必胜. $0\leq n \leq 10^{9},3\leq k \leq ...
- windows操作系统更改 <远程桌面> 端口号
windows远程桌面连接默认使用的是3389端口,为了避免被他人扫描从而暴力破解远程服务器或者病毒入侵.可以将默认端口修改为其它端口,如8888,11111等.最好修改为10000以后的端口,这样可 ...
- C#泛型集合之——链表
链表基础 1.概述:C#中泛型集合中的链表—LinkedList 是一个双向链表,其结点为LinkedListNode 结构 其中,结点结构包含:Next,Previous,Value三部分.且结点中 ...
- 异常来自 HRESULT:0x8007000B
这个是64位应用32位产生的问题.相信大家搜索的时候很多都是建议改把项目的AnyCPU改成X86,可是很不幸我的改不了. 终于搜索了半天后发现,IIS里解决才是根本办法: .在IIS配置里面启用32位 ...