说说openjdk及G1回收器日志内容详细分析
谈谈openjdk:
在正式往下学习JVM之前,这里谈谈openjdk这个网站,这个在学习java并发时也用过它来分析过锁的底层实现,如:https://www.cnblogs.com/webor2006/p/11442551.html,为啥要说它,目前学习JVM已经记录了80多篇了,从纯小白到目前的学习貌似对JVM有东东了解得还不错了,但是!!其实还只是了解了个冰山一角,主要是JVM是一个太庞大的知识领域了,毕境不是真正在商业公司里做过JVM相关的工作,所以对于它的新知识在未来会一直出现,那在面对网上新出的一些理论上的说明,怎么知道它是真的还是假的,或者说这些理论的来源是在哪里呢?如果有想法验证的话就可以通过这个openjdk的底层JVM的源代码来进行,所以这里打开openjdk再提一下:


然后随便打开一个目录则就可以看到大量的底层C++实现:
谈这么一个小点就是假如未来想再进一步的探讨JVM自己来求验的话可以通过这种方式来进行,仅此而已。
G1回收器日志内容详细分析:
在前面学习了大量的关于G1收集器相关的理论之后,下面则编写一个实际的例子来看一下G1回收器产生日志跟之前咱们学习的其它的回收器产生的日志有啥区别,其实区别是非常之大的,如下:
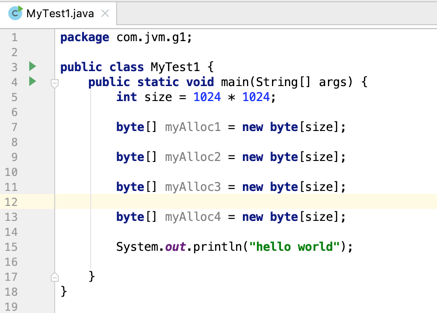
就是在内存中申请了4M的大小,如果不加任何参数运行当然比较简单:

好,接下来就是配置一下运行参数,我们目前用的JDK版本是1.8,默认它的收集器并非是G1收集器,而1.9之后则默认收集器就变为G1了,所以得显示的指定一下,如下:
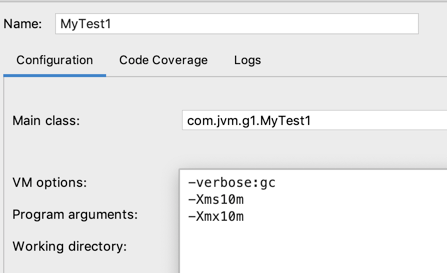
这三个参数之前都配过,这里再解释一下:
-verbose:gc:此代表会输出GC的详细日志。
-Xms10m、-Xmx10m:堆内存指定10m,不可以扩容,为了更容易打出相关日志这里将堆内存指定小一点。
接着第三个参数,这个就比较重要了:
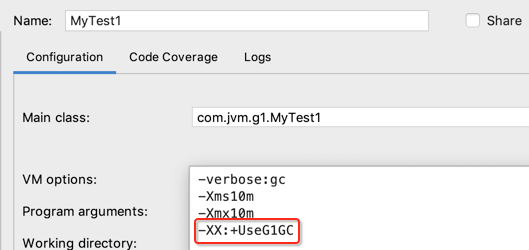
指定用G1垃圾收集器,接着再继续添加其它参数:
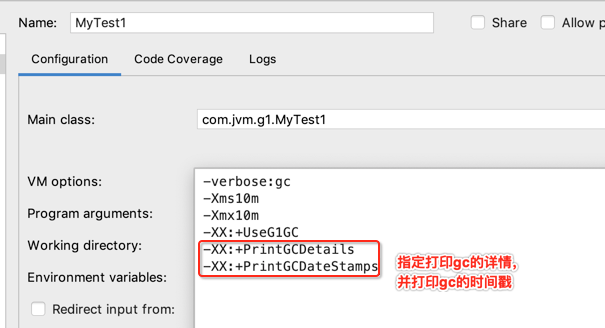
接下来再来指定最大的停顿时间,这个在之前的理论中也已经提及过,回忆下:
配置一下:

好,此时再运行一下:
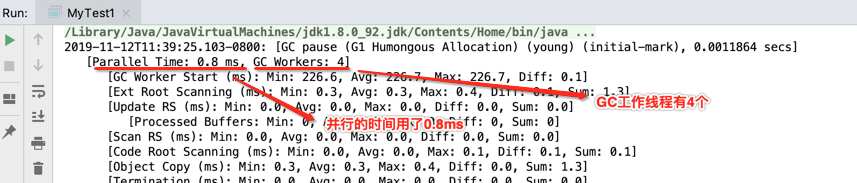
2019-11-12T11:39:25.103-0800: [GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0011864 secs]
[Parallel Time: 0.8 ms, GC Workers: 4]
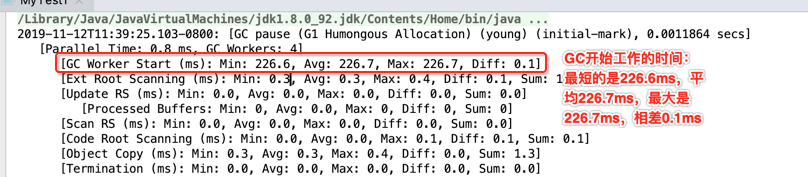
[GC Worker Start (ms): Min: 226.6, Avg: 226.7, Max: 226.7, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.3, Avg: 0.3, Max: 0.4, Diff: 0.1, Sum: 1.3]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1]
[Object Copy (ms): Min: 0.3, Avg: 0.3, Max: 0.4, Diff: 0.0, Sum: 1.3]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 1.5, Max: 3, Diff: 2, Sum: 6]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 0.6, Avg: 0.7, Max: 0.7, Diff: 0.1, Sum: 2.8]
[GC Worker End (ms): Min: 227.4, Avg: 227.4, Max: 227.4, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
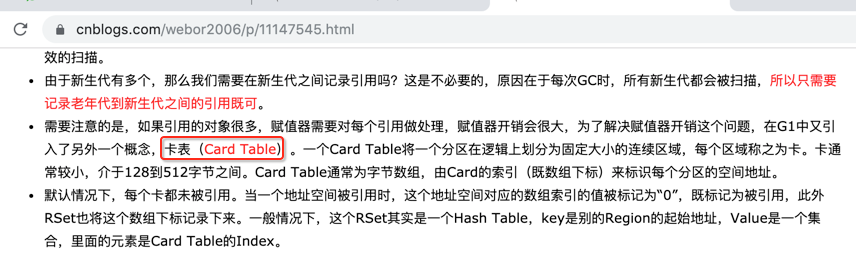
[Clear CT: 0.1 ms]
[Other: 0.3 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.2 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
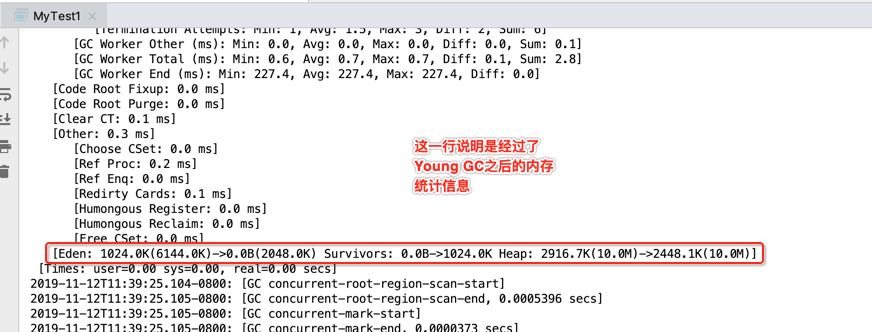
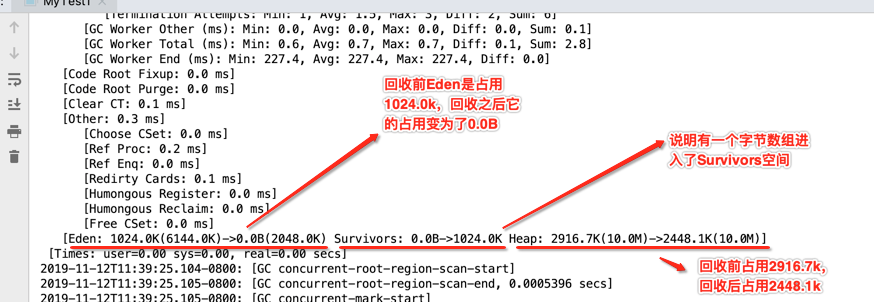
[Eden: 1024.0K(6144.0K)->0.0B(2048.0K) Survivors: 0.0B->1024.0K Heap: 2916.7K(10.0M)->2448.1K(10.0M)]
[Times: user=0.00 sys=0.00, real=0.00 secs]
2019-11-12T11:39:25.104-0800: [GC concurrent-root-region-scan-start]
2019-11-12T11:39:25.105-0800: [GC concurrent-root-region-scan-end, 0.0005396 secs]
2019-11-12T11:39:25.105-0800: [GC concurrent-mark-start]
2019-11-12T11:39:25.105-0800: [GC concurrent-mark-end, 0.0000373 secs]
2019-11-12T11:39:25.106-0800: [GC remark 2019-11-12T11:39:25.106-0800: [Finalize Marking, 0.0068794 secs] 2019-11-12T11:39:25.113-0800: [GC ref-proc, 0.0000470 secs] 2019-11-12T11:39:25.113-0800: [Unloading, 0.0008433 secs], 0.0080039 secs]
[Times: user=0.00 sys=0.00, real=0.01 secs]
2019-11-12T11:39:25.114-0800: [GC cleanup 3472K->3472K(10M), 0.0002695 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
hello world
Heap
garbage-first heap total 10240K, used 4496K [0x00000007bf600000, 0x00000007bf700050, 0x00000007c0000000)
region size 1024K, 2 young (2048K), 1 survivors (1024K)
Metaspace used 2656K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 287K, capacity 386K, committed 512K, reserved 1048576K Process finished with exit code 0
呃,看着头晕。。输出了这么多信息。。要想理解G1,分析日志是必须经历过的,所以接下来硬着头皮大致来分析一下:
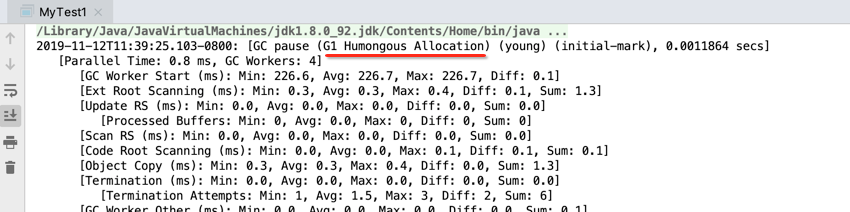
啥意思?这个得回忆一下之前学的理论了,当时提到过这个“Humongous”,https://www.cnblogs.com/webor2006/p/11142839.html,如下:

因为咱们每个数组都申请的1M,肯定是超出标准区域的50%,所以当成了巨大的区域了,所以日志中会有“Humongous”,继续分析:


这里回顾一下理论:


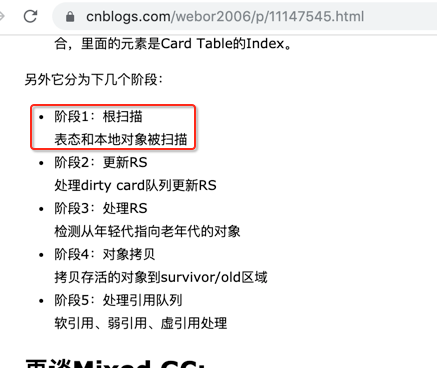
其实它刚好对应之前咱们学习的G1 Young GC的步骤之一,如下:

其中Rset是干啥用的,这里回忆一下,都是在之前的理论中有提及到的:

它其实就对应G1 Young GC的这个流程:
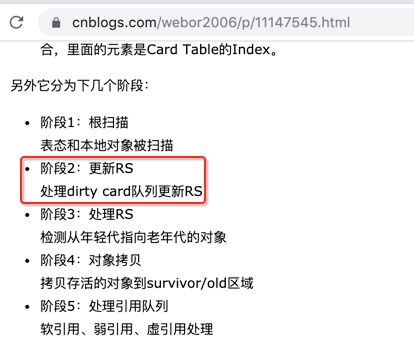
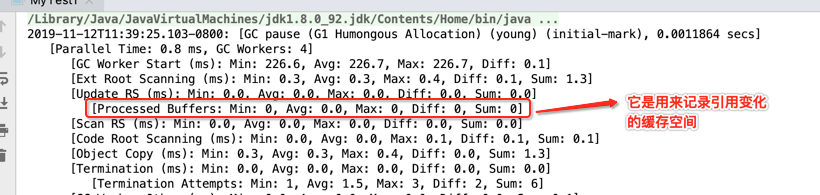
对应G1 Young GC这个流程:
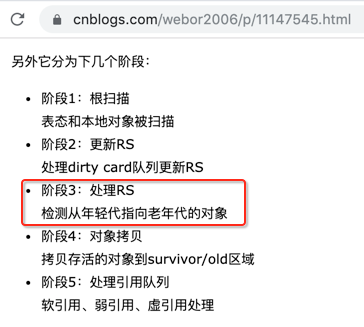
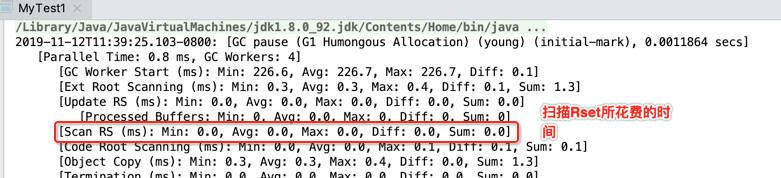

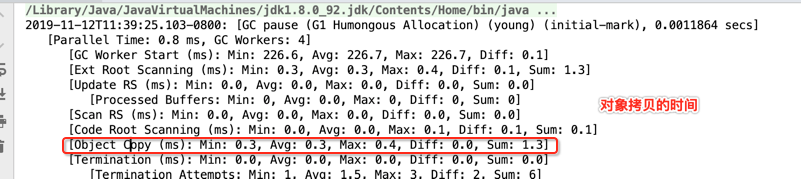
这块在之前G1 Young GC中也有提及,如下:

这里再来回顾个之前的东东,就是gc常见的算法有:

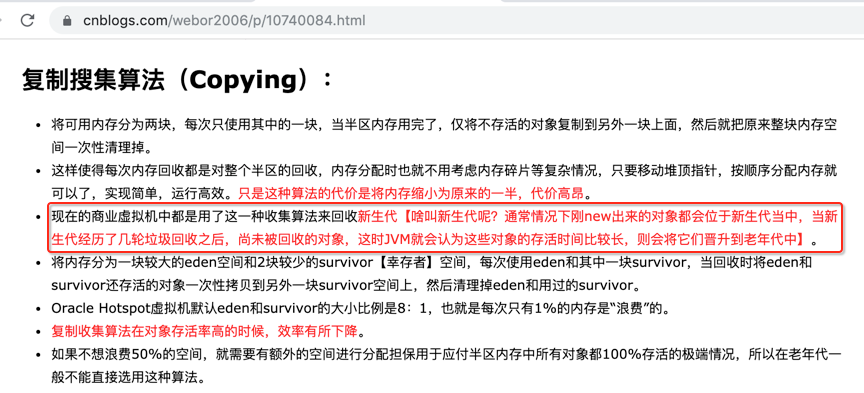
而且在老年代中不可能使用这个复制算法,所以再回顾一下这个图:

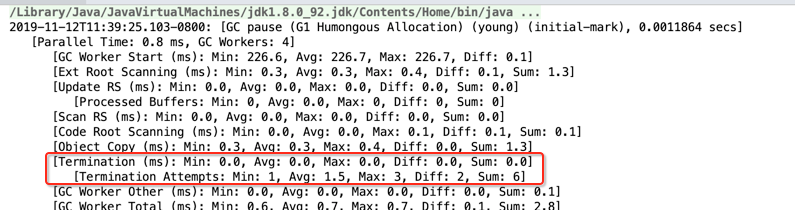
也就是对就G1 Young GC的最后一个步骤:

继续分析:
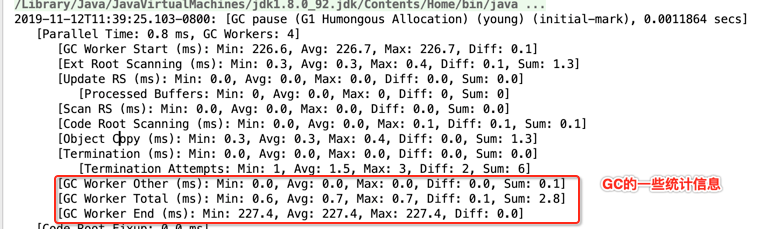
也是来自于G1 Young GC中的理论,回忆一下:
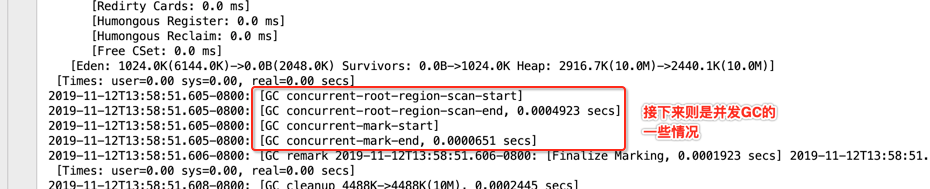

这些其实都是global concurrent marking的过程,回忆一下:

最后看一下整个堆的信息:

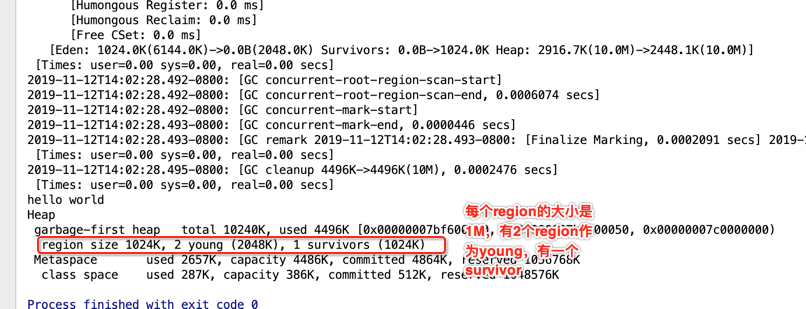
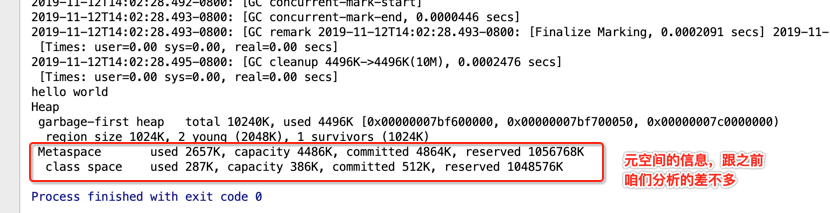
以上就是对于第一个G1日志的大体的认识,有很多细节还待未来进行进一步挖掘。
说说openjdk及G1回收器日志内容详细分析的更多相关文章
- 转:NLog 自定义日志内容,写日志到数据库;修改Nlog.config不起作用的原因
转:http://www.cnblogs.com/tider1999/p/4308440.html NLog的安装请百度,我安装的是3.2.NLog可以向文件,数据库,邮件等写日志,想了解请百度,这里 ...
- 详细分析MySQL事务日志(redo log和undo log)
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 详细分析MySQL事务日志(redo log和undo log) 表明了为何mysql不会丢数据
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 非IMU模式下DML语句产生的REDO日志内容格式解读
实验内容:非IMU模式下DML语句产生的REDO日志内容格式解读 最详细的解读是UPDATE的. 实验环境准备 11G中默认是开启IMU特性的,做此实验需要关闭此特性. alter system se ...
- java架构之路-(JVM优化与原理)JVM之G1回收器和常见参数配置
过去的几天里,我把JVM内部的垃圾回收算法和垃圾回收器.还剩下最后一个G1回收器没有说,我们今天数一下G1回收器和常见的参数配置. G1回收器 G1 (Garbage-First)是一款面向服务器的垃 ...
- 浅谈 G1 GC 日志格式
在 Java9 中,G1 GC 将成为默认的垃圾收集器,G1 垃圾收集器的关键特性之一是能够在不牺牲吞吐量的同时,限制 GC 暂停时间(即可以设置所需的最大停顿时间). 由于 G1 GC 正在逐渐成为 ...
- 日志模块详细介绍 hashlib模块 动态加盐
目录 一:hashlib模块 二:logging 一:hashlib模块 加密: 将明文数据通过一系列算法变成密文数据(目的就是为了数据的安全) 能够做文件一系列校验 python的hashlib提供 ...
- logging日志模块详细,日志模块的配置字典,第三方模块的下载与使用
logging日志模块详细 简介 用Python写代码的时候,在想看的地方写个print xx 就能在控制台上显示打印信息,这样子就能知道它是什么 了,但是当我需要看大量的地方或者在一个文件中查看的时 ...
- springmvc+log4j操作日志记录,详细配置
没有接触过的,先了解一下:log4j教程 部分内容来:log4j教程 感谢! 需要导入包: log包:log4j-12.17.jar 第一步:web.xml配置 <!-- log4j配置,文件路 ...
随机推荐
- 您访问的URL地址不被允许。
访问一个网站在一定时间内的频率过高会被当做攻击网站的行为,然后会被该网站限制访问,再次访问该网站便会出现以下界面,解决办法有: ①更改自己电脑的IP地址 ②换一个设备访问,比如把用电脑访问换成用手机访 ...
- C# Process.Start()函数打开url被360拦截问题
使用Process.Start(new ProcessStartInfo(url))来打开某一网址的时候,往往会被360提示 类似这样的 信息: “威胁:修改此注册表项将更改IE连接设置.少数软件会修 ...
- maven 依赖优化
1.mvn dependency:list 列出项目用到的依赖 2.查看依赖树 mvn dependency:tree 3.mvn dependency:analyze Used undeclare ...
- win10 .net framework 3.5 离线安装 不需要外网
win 10如果安装系统时没有安装.net 3.5 那么在以后安装时就必须联网. win10 .net framework 3.5 离线安装工具: 链接: https://pan.baidu.com/ ...
- golang 数据导出excel (github.com/360EntSecGroup-Skylar/excelize)
package handler import ( "fmt" "git.shannonai.com/public_info_prophet/prophet_risk_ag ...
- Sitecore 8.2 扩展体验分析报告
本文简要介绍了如何为Experience Analytics创建自定义报告.在Sitecore术语中,我会说:创建新的报表维度和适当的报表以显示它们. 我们做的任务是:实现新的报告,显示不同网络浏览器 ...
- Java学习:数据类型转换注意事项
数据类型的转换 当数据类型不一样时,将会发生数据类型转换. 自动类型转换(隐式) 1.特点 :代码不需要进行特殊处理,自动完成. 2.规则 :数据范围从小到大. //左边是long类型,右边是默认的i ...
- CentOS 7.0 更改SSH 远程连接 端口号
许多学习过redhat 7的同学们,在使用centos的时候总会遇到一些问题,因为centos在安装时会默认开启一些服务,今天我们就来更改下centos 7.0的SSH端口. 操作步骤: 远程登录到c ...
- System.ArgumentException:路由集合中已存在名为“XXX”的路由。路由名称必须唯一。
软件环境:Visual Studio 2017 + MVC4 + EF6 问题描述:System.ArgumentException:路由集合中已存在名为“XXX”的路由.路由名称必须唯一. 解决办法 ...
- python基础01day
1 python多版本共存 因为python2和python3的解释器程序都是python.exe,在同时加入环境变量的情况下名称重复,如果重命名的话又会造成需要链接解释器的程序无法调用解释器,所以采 ...