Storm入门2-单词计数案例学习
【本篇文章主要是通过一个单词计数的案例学习,来加深对storm的基本概念的理解以及基本的开发流程和如何提交并运行一个拓扑】
单词计数拓扑WordCountTopology实现的基本功能就是不停地读入一个个句子,最后输出每个单词和数目并在终端不断的更新结果,拓扑的数据流如下:

- 语句输入Spout: 从数据源不停地读入数据,并生成一个个句子,输出的tuple格式:{"sentence":"hello world"}
- 语句分割Bolt: 将一个句子分割成一个个单词,输出的tuple格式:{"word":"hello"} {"word":"world"}
- 单词计数Bolt: 保存每个单词出现的次数,每接到上游一个tuple后,将对应的单词加1,并将该单词和次数发送到下游去,输出的tuple格式:{"hello":"1"} {"world":"3"}
- 结果上报Bolt: 维护一份所有单词计数表,每接到上游一个tuple后,更新表中的计数数据,并在终端将结果打印出来。
开发步骤:
1.环境
- 操作系统:mac os 10.10.3
- JDK: jdk1.8.0_40
- IDE: intellij idea 15.0.3
- Maven: apache-maven-3.0.3
2.项目搭建
- 在idea新建一个maven项目工程:storm-learning
- 修改pom.xml文件,加入strom核心的依赖,配置slf4j依赖,方便Log输出
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.1</version>
</dependency> <dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.2</version>
</dependency>
</dependencies>
3. Spout和Bolt组件的开发
- SentenceSpout
- SplitSentenceBolt
- WordCountBolt
- ReportBolt
SentenceSpout.java
public class SentenceSpout extends BaseRichSpout{
private SpoutOutputCollector spoutOutputCollector;
//为了简单,定义一个静态数据模拟不断的数据流产生
private static final String[] sentences={
"The logic for a realtime application is packaged into a Storm topology",
"A Storm topology is analogous to a MapReduce job",
"One key difference is that a MapReduce job eventually finishes whereas a topology runs forever",
" A topology is a graph of spouts and bolts that are connected with stream groupings"
};
private int index=0;
//初始化操作
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
//核心逻辑
public void nextTuple() {
spoutOutputCollector.emit(new Values(sentences[index]));
++index;
if(index>=sentences.length){
index=0;
}
}
//向下游输出
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentences"));
}
}
SplitSentenceBolt.java
public class SplitSentenceBolt extends BaseRichBolt{
private OutputCollector outputCollector;
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.outputCollector = outputCollector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentences");
String[] words = sentence.split(" ");
for(String word : words){
outputCollector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word"));
}
}
WordCountBolt.java
public class WordCountBolt extends BaseRichBolt{
//保存单词计数
private Map<String,Long> wordCount = null;
private OutputCollector outputCollector;
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.outputCollector = outputCollector;
wordCount = new HashMap<String, Long>();
}
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = wordCount.get(word);
if(count == null){
count = 0L;
}
++count;
wordCount.put(word,count);
outputCollector.emit(new Values(word,count));
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word","count"));
}
}
ReportBolt.java
public class ReportBolt extends BaseRichBolt {
private static final Logger log = LoggerFactory.getLogger(ReportBolt.class);
private Map<String, Long> counts = null;
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
counts = new HashMap<String, Long>();
}
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = tuple.getLongByField("count");
counts.put(word, count);
//打印更新后的结果
printReport();
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//无下游输出,不需要代码
}
//主要用于将结果打印出来,便于观察
private void printReport(){
log.info("--------------------------begin-------------------");
Set<String> words = counts.keySet();
for(String word : words){
log.info("@report-bolt@: " + word + " ---> " + counts.get(word));
}
log.info("--------------------------end---------------------");
}
}
4.拓扑配置
- WordCountTopology
public class WordCountTopology {
private static final Logger log = LoggerFactory.getLogger(WordCountTopology.class);
//各个组件名字的唯一标识
private final static String SENTENCE_SPOUT_ID = "sentence-spout";
private final static String SPLIT_SENTENCE_BOLT_ID = "split-bolt";
private final static String WORD_COUNT_BOLT_ID = "count-bolt";
private final static String REPORT_BOLT_ID = "report-bolt";
//拓扑名称
private final static String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) {
log.info(".........begining.......");
//各个组件的实例
SentenceSpout sentenceSpout = new SentenceSpout();
SplitSentenceBolt splitSentenceBolt = new SplitSentenceBolt();
WordCountBolt wordCountBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
//构建一个拓扑Builder
TopologyBuilder topologyBuilder = new TopologyBuilder();
//配置第一个组件sentenceSpout
topologyBuilder.setSpout(SENTENCE_SPOUT_ID, sentenceSpout, 2);
//配置第二个组件splitSentenceBolt,上游为sentenceSpout,tuple分组方式为随机分组shuffleGrouping
topologyBuilder.setBolt(SPLIT_SENTENCE_BOLT_ID, splitSentenceBolt).shuffleGrouping(SENTENCE_SPOUT_ID);
//配置第三个组件wordCountBolt,上游为splitSentenceBolt,tuple分组方式为fieldsGrouping,同一个单词将进入同一个task中(bolt实例)
topologyBuilder.setBolt(WORD_COUNT_BOLT_ID, wordCountBolt).fieldsGrouping(SPLIT_SENTENCE_BOLT_ID, new Fields("word"));
//配置最后一个组件reportBolt,上游为wordCountBolt,tuple分组方式为globalGrouping,即所有的tuple都进入这一个task中
topologyBuilder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(WORD_COUNT_BOLT_ID);
Config config = new Config();
//建立本地集群,利用LocalCluster,storm在程序启动时会在本地自动建立一个集群,不需要用户自己再搭建,方便本地开发和debug
LocalCluster cluster = new LocalCluster();
//创建拓扑实例,并提交到本地集群进行运行
cluster.submitTopology(TOPOLOGY_NAME, config, topologyBuilder.createTopology());
}
}
5.拓扑执行
- 方法一:通过IDEA执行
在idea中对代码进行编译compile,然后run;
观察控制台输出会发现,storm首先在本地自动建立了运行环境,即启动了zookepeer,接着启动nimbus,supervisor;然后nimbus将提交的topology进行分发到supervisor,supervisor启动woker进程,woker进程里利用Executor来运行topology的组件(spout和bolt);最后在控制台发现不断的输出单词计数的结果。
zookepeer的连接建立

nimbus启动

supervisor启动

worker启动

Executor启动执行
结果输出
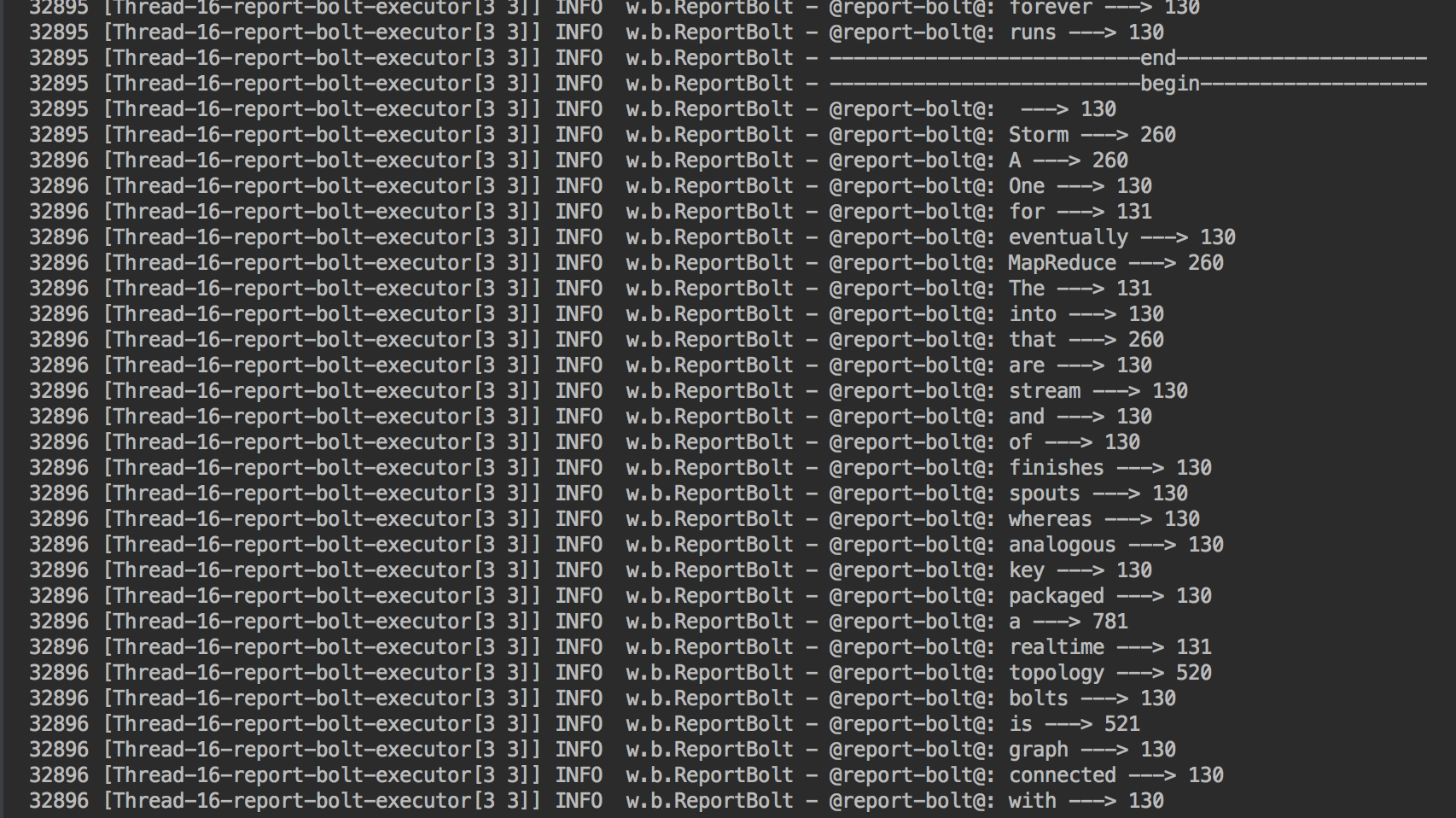
- 方法二:通过maven来执行
- 进入到该项目的主目录下:storm-learning
- mvn compile 进行代码编译,保证代码编译通过
- 通过mvn执行程序:
mvn exec:java -Dexec.mainClass="wordCount.WordCountTopology"
- 控制台输出的结果跟方法一一致
Storm入门2-单词计数案例学习的更多相关文章
- 大数据学习——Storm学习单词计数案例
需求:计算单词在文档中出现的次数,每出现一次就累加一次 遇到的问题 这个问题是<scope>provided</scope>作用域问题 https://www.cnblogs. ...
- 2.Storm集群部署及单词统计案例
1.集群部署的基本流程 2.集群部署的基础环境准备 3.Storm集群部署 4.Storm集群的进程及日志熟悉 5.Storm集群的常用操作命令 6.Storm源码下载及目录熟悉 7.Storm 单词 ...
- Storm实现单词计数
package com.mengyao.storm; import java.io.File; import java.io.IOException; import java.util.Collect ...
- hadoop笔记之MapReduce的应用案例(WordCount单词计数)
MapReduce的应用案例(WordCount单词计数) MapReduce的应用案例(WordCount单词计数) 1. WordCount单词计数 作用: 计算文件中出现每个单词的频数 输入结果 ...
- storm(5)-分布式单词计数例子
例子需求: spout:向后端发送{"sentence":"my dog has fleas"}.一般要连数据源,此处简化写死了. 语句分割bolt(Split ...
- 【Storm】storm安装、配置、使用以及Storm单词计数程序的实例分析
前言:阅读笔记 storm和hadoop集群非常像.hadoop执行mr.storm执行topologies. mr和topologies最关键的不同点是:mr执行终于会结束,而topologies永 ...
- storm入门基础实例(无可靠性保证实例)
本实例为入门篇无可靠性保证实例,关于storm的介绍,以及一些术语名词等,可以参考Storm介绍(一).Storm介绍(二). 本案例是基于storm0.9.3版本 1.案例结构 案例:Word Co ...
- Storm入门之第一章
Storm入门之第一章 1.名词 spout龙卷,读取原始数据为bolt提供数据 bolt雷电,从spout或者其他的bolt接收数据,并处理数据,处理结果可作为其他bolt的数据源或最终结果 nim ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
随机推荐
- Spark java.lang.outofmemoryerror gc overhead limit exceeded 与 spark OOM:java heap space 解决方法
引用自:http://cache.baiducontent.com/c?m=9f65cb4a8c8507ed4fece7631046893b4c4380146d96864968d4e414c42246 ...
- Orcal函数
where b.rn between 4 and 6--日期函数select sysdate from dual--返回两个日期select months_between(to_date('2017- ...
- javaScript的简单学习
JavaScript介绍 JavaScript跟java没半毛钱关系 JavaScript有三部分组成:ECMAScript,document object model,broswer object ...
- linux后台查看共享内存和消息队列的命令
ipcs ipcs -q : 显示所有的消息队列 ipcs -qt : 显示消息队列的创建时间,发送和接收最后一条消息的时间 ipcs -qp: 显示往消息队列中放消息和从消息队列中取消息的进程ID ...
- Hyper-V 与Broadcom网卡兼容问题
最近在测虚拟机时,碰到一个网卡和Hyper-V不兼容问题,现在共享给大家参考,希望对大家有帮忙. 故障描述: Dell R720 Windows 2012操作系统下的Hyper-V环境后,虚拟机网络速 ...
- Python开发【十二章】:ORM sqlalchemy
一.对象映射关系(ORM) orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却 ...
- requests库基本使用
在python中,字典的输出内容跟json格式内容一样,但是字典的格式是字典,json的格式是字符串,所以在传输的时候(特别是网页)要转换使用. r.text返回的是Unicode型的数据. r.co ...
- centos 安装redis并加入系统服务
1.安装redis wget http://download.redis.io/releases/redis-3.2.5.tar.gz 解压:tar -zxvf redis-3.2.5.tar.gz ...
- delphi 判断一个数组的长度用 Length 还是 SizeOf ?
判断一个数组的长度用 Length 还是 SizeOf ?最近发现一些代码, 甚至有一些专家代码, 在遍历数组时所用的数组长度竟然是 SizeOf(arr); 这不合适! 如果是一维数组.且元素大小是 ...
- PAT树_层序遍历叶节点、中序建树后序输出、AVL树的根、二叉树路径存在性判定、奇妙的完全二叉搜索树、最小堆路径、文件路由
03-树1. List Leaves (25) Given a tree, you are supposed to list all the leaves in the order of top do ...