深入源码理解Spark RDD的数据分区原理
通过内存创建RDD的分区设置
1、示例代码
在创建RDD的时候,我们可以从内存中进行创建;输出保存为文件。为了演示效果,我们的示例代码如下:
import org.apache.spark.{SparkConf, SparkContext}
object Spark02RddParallelizeSet {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "C:\\Hadoop\\")
val spark = new SparkConf().setMaster("local[*]").setAppName("RddParallelizeSet")
val context = new SparkContext(spark)
val list = List(1, 2, 3, 4)
// TODO: 从内存创建RDD,并且设置并行执行的任务数量
// numSlices: Int = defaultParallelism
val memoryRDD = context.makeRDD(list, 1)
memoryRDD.saveAsTextFile("output")
val memoryRDD1 = context.makeRDD(list, 2)
memoryRDD1.saveAsTextFile("output1")
val memoryRDD2 = context.makeRDD(list, 3)
memoryRDD2.saveAsTextFile("output2")
val memoryRDD3 = context.makeRDD(list, 4)
memoryRDD3.saveAsTextFile("output3")
val memoryRDD4 = context.makeRDD(list, 5)
memoryRDD4.saveAsTextFile("output4")
// TODO: 结束
context.stop()
}
}
上面的代码里,我们从内存中创建了5个RDD,每个RDD设置了不同的分区数。
2、执行结果
(1)1个分区的RDD,效果如下图所示:
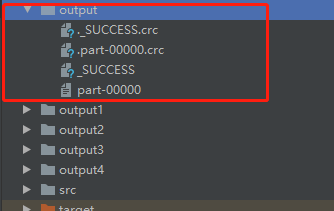
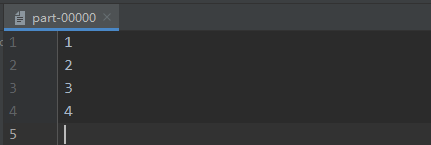
在output文件夹中,只包含了一个分区文件 part-00000 ,其文件内容如下图所示:
(2)2个分区的RDD,效果如下图所示:
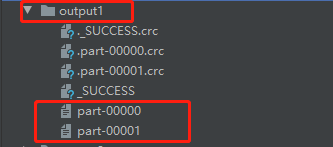
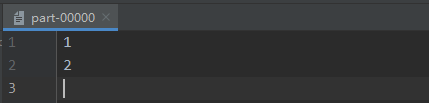
在output1文件夹中,包含了两个分区文件 part-00000 以及 part-00001,二者文件内容如下图所示:

(3)3个分区的RDD,效果如下图所示:
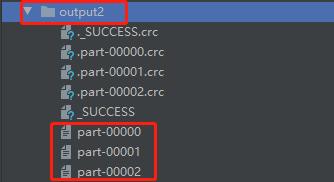
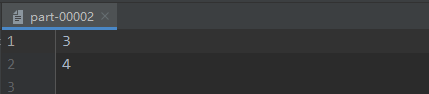
在output2文件夹中,包含了三个分区文件 part-00000 、part-00001、part-00002,三者文件内容如下图所示:


(4)4个分区的RDD,效果如下图所示:
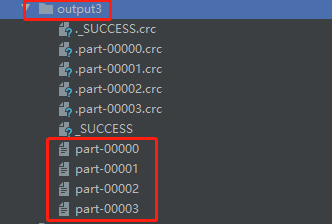
在output3文件夹中,包含了四个分区文件 part-00000、part-00001、part-00002、part-00003,四者文件内容如下图所示:




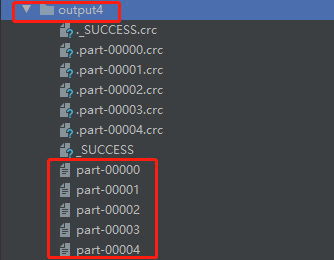
在output4文件夹中,包含了五个分区文件 part-00000、part-00001、part-00002、part-00003、part-00004,五者文件内容如下图所示:





3、分析结果
仔细看看上面图片中的结果,不难发现其中肯定深藏猫腻。不同分区数的设置,都存在不同的输出效果。要想深究其中缘由,有必要去了解Spark的在这一块的源码实现。进入到 makeRDD( ) 这个方法中,可以看到如下源码:
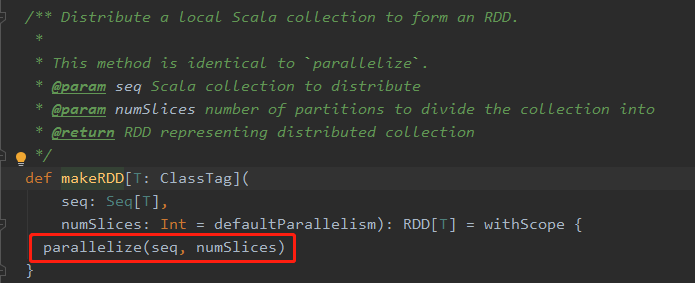
在图片中用红色方框框起来的部分,是一个方法,其中传入了两个参数,第一个 seq 就是在我们自己写的代码中,自己定义的那个 List;第二个 numSlices 就是我们自己写的代码中的那个分区数。
再点进 parallelize( seq, numSlices) 这个方法中去,可以看到如下源码:
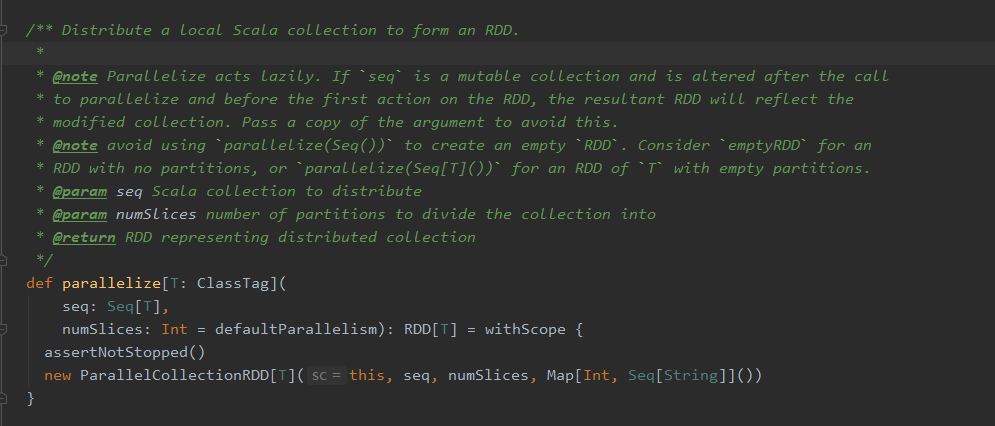
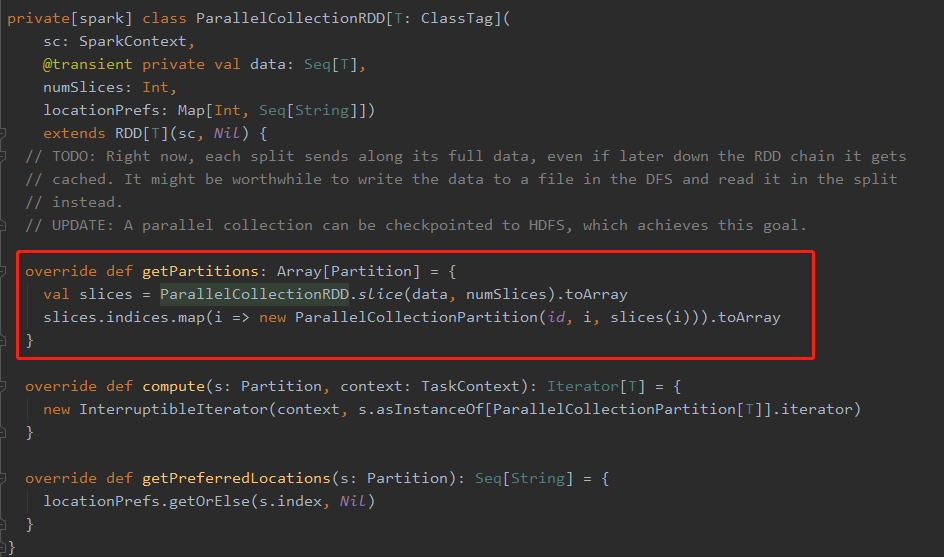
红色线框框出的这个名为 getPartitions 的方法,返回的是一个分区的数组,ParallelCollectionRDD.slice( ) 调用的是 ParallelCollectionRDD 伴生对象里面的一个方法,看样子应该是这个方法里的代码规定了怎么进行分区的划分了,于是,进到这个方法里面,果不其然,可以看到如下代码块:

在 slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] 这个方法中,我们可以看到一个关于 seq 这个传入的参数的模式匹配:
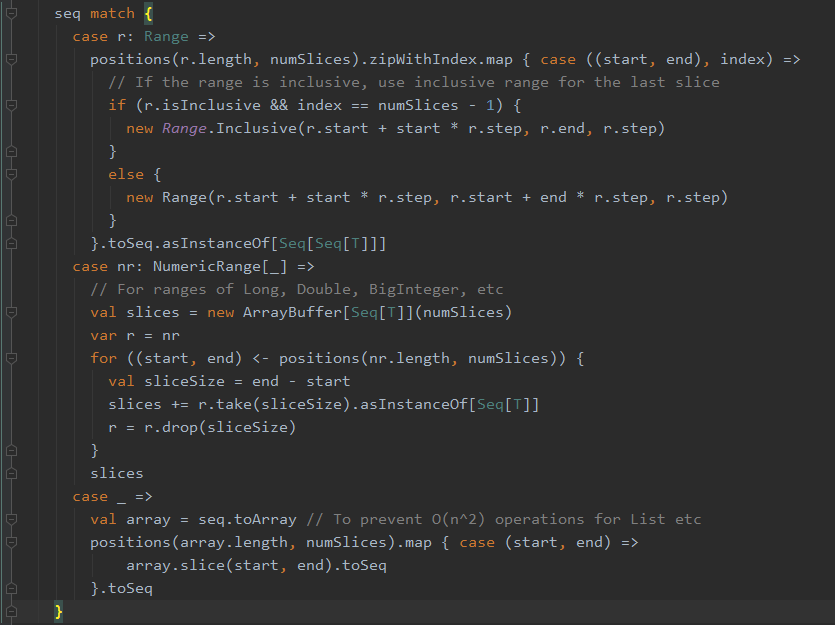
在上图的这一段代码中,模式匹配第一个匹配的是 Range 类型,很明显与我们传入的 List 类型不一致,因此 case r: Range 这一块的匹配代码可以跳过。第二个匹配的也是Range,相比于第一个匹配的Range 整形类型 而言,第二个则可以匹配更多种类型的 Range。当然第二个case也不是我们要看的。那么就剩下第三个 "case _" 这种情况了。
在第三个情况中,首先将 我们传入的 List 转换为了一个 array,为什么要有这一步,源码中也给出了注释:To prevent O(n ^ 2) operations for List etc。之后调用了positions( ) 方法,将转换后的数组的长度以及分区数量传入,该方法源码如下:
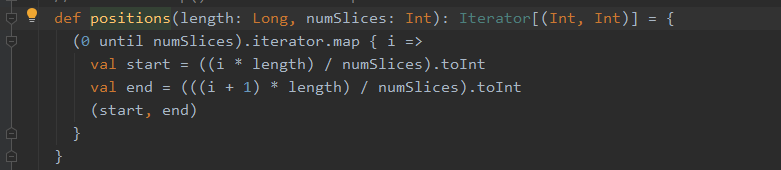
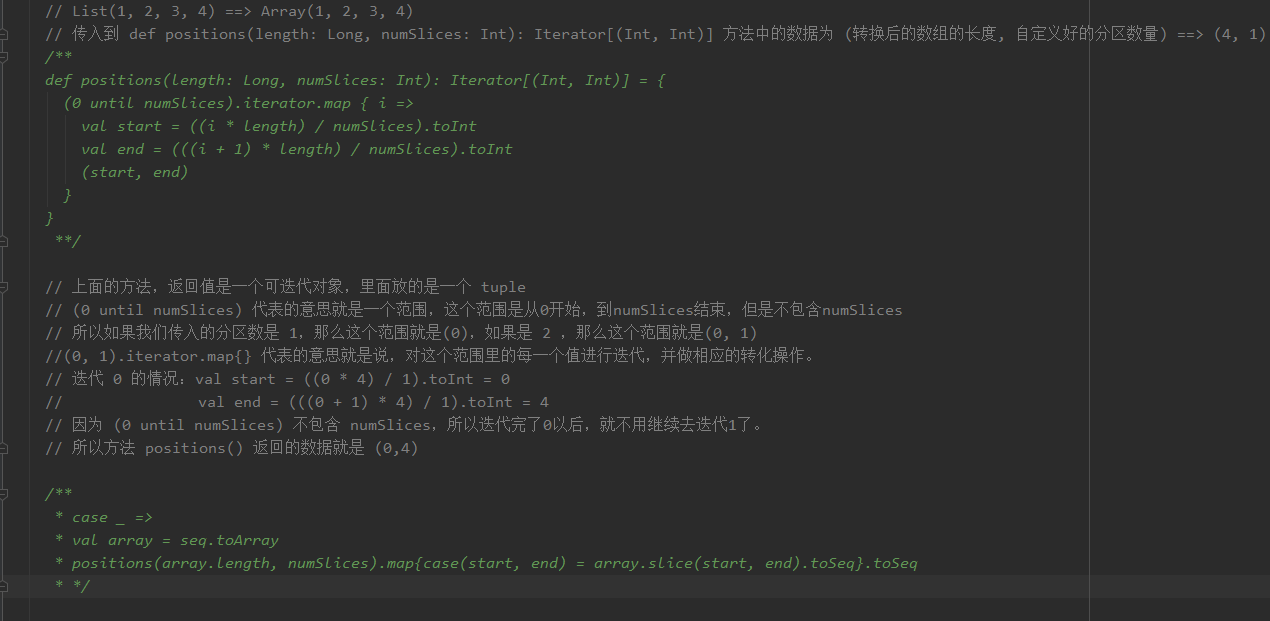
我的分析过程如下,数据是(1,2,3,4),分区数量是1的情况:
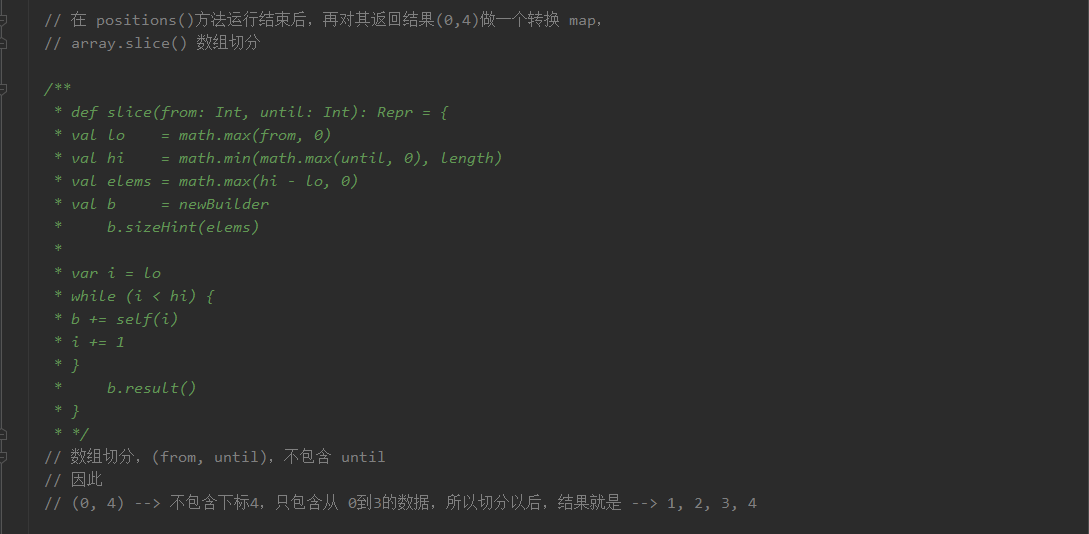
4、小结
深入源码理解Spark RDD的数据分区原理的更多相关文章
- Caffe源码理解2:SyncedMemory CPU和GPU间的数据同步
目录 写在前面 成员变量的含义及作用 构造与析构 内存同步管理 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 在Caffe源码理解1中介绍了Blob类,其中的数据成 ...
- 基于SpringBoot的Environment源码理解实现分散配置
前提 org.springframework.core.env.Environment是当前应用运行环境的公开接口,主要包括应用程序运行环境的两个关键方面:配置文件(profiles)和属性.Envi ...
- Pytorch学习之源码理解:pytorch/examples/mnists
Pytorch学习之源码理解:pytorch/examples/mnists from __future__ import print_function import argparse import ...
- [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler
[源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler 目录 [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampl ...
- [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader
[源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 目录 [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 0x00 摘要 0x01 ...
- HashMap源码理解一下?
HashMap 是一个散列桶(本质是数组+链表),散列桶就是数据结构里面的散列表,每个数组元素是一个Node节点,该节点又链接着多个节点形成一个链表,故一个数组元素 = 一个链表,利用了数组线性查找和 ...
- Fresco源码解析 - DataSource怎样存储数据
Fresco源码解析 - DataSource怎样存储数据 datasource是一个独立的 package,与FB导入的guava包都在同一个工程内 - fbcore. datasource的类关系 ...
- jedis的源码理解-基础篇
[jedis的源码理解-基础篇][http://my.oschina.net/u/944165/blog/127998] (关注实现关键功能的类) 基于jedis 2.2.0-SNAPSHOT ...
- HDFS源码分析心跳汇报之数据块汇报
在<HDFS源码分析心跳汇报之数据块增量汇报>一文中,我们详细介绍了数据块增量汇报的内容,了解到它是时间间隔更长的正常数据块汇报周期内一个smaller的数据块汇报,它负责将DataNod ...
随机推荐
- 利用74HC595实现的流水灯 Arduino
int big = 2; int push = 3; int datain = 4; void setup() { Serial.begin(9600); pinMode(big, OUTPUT); ...
- Java对象公约
灵魂static关键字 Java规定:方法只能由对象来调用. 换句话来说,在面向对象的思维下,方法与对象存在一种强耦合. static作用:即使没有初始化对象,也可以调用方法.(类比到属性上同样如此) ...
- JS 原生ajax写法
<script> //step1.创建XMLHTTPRequest对象,对于低版本的IE,需要换一个ActiveXObject对象 var xhr; if (window.XMLHttpR ...
- 使用ATOMac进行Mac自动化测试
ATOMac简介 atomac是一个支持在mac上做自动化的python库,GitHub地址如下: https://github.com/pyatom/pyatom 安装 # Python2 sudo ...
- 字符输入输出不一样!:什么情况下需要getchar()吃空格和回车
今天一个很简单的题居然一直不对... 大概是用字符组成的一个方块..然后各种转换, 关键是我算法都写好了,然而输入进去的字符方块直接输出来都不太对... 后来想起吃空格问题,因为scanf了%c的话, ...
- vector STL
高呼“STL大法好!!” vector 是一个不限定容量的数组. 先说一下头文件 #include<vector> 1.声明 vector<int>v1;//vector元素为 ...
- 03_Linux定制篇
第十四章 JAVAEE定制篇 搭建JAVAEE环境 14.1 安装JDK 1)先将软件通过xftp5上传到/opt下 2)解压缩到/opt 3)配置环境变量的配置文件vim/etc/profile J ...
- Python os.pathconf() 方法
概述 os.pathconf() 方法用于返回一个打开的文件的系统配置信息.高佣联盟 www.cgewang.com Unix 平台下可用. 语法 fpathconf()方法语法格式如下: os.fp ...
- 痞子衡嵌入式:MCUXpresso IDE下使用J-Link下载算法在Flash调试注意事项(i.MXRT500为例)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是MCUXpresso IDE下使用J-Link下载算法在Flash调试注意事项. 痞子衡前段时间写过一篇小文<为i.MXRT设计更 ...
- 7.18 NOI模拟赛 因懒无名 线段树分治 线段树维护直径
LINK:因懒无名 20分显然有\(n\cdot q\)的暴力. 还有20分 每次只询问一种颜色的直径不过带修改. 容易想到利用线段树维护直径就可以解决了. 当然也可以进行线段树分治 每种颜色存一下直 ...