电影推荐系统---协同过滤算法(SVD,NMF)
SVD
参考 https://www.zybuluo.com/rianusr/note/1195225
1 推荐系统概述
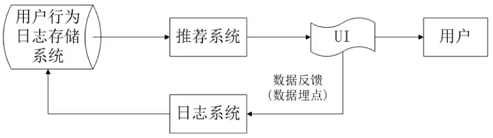
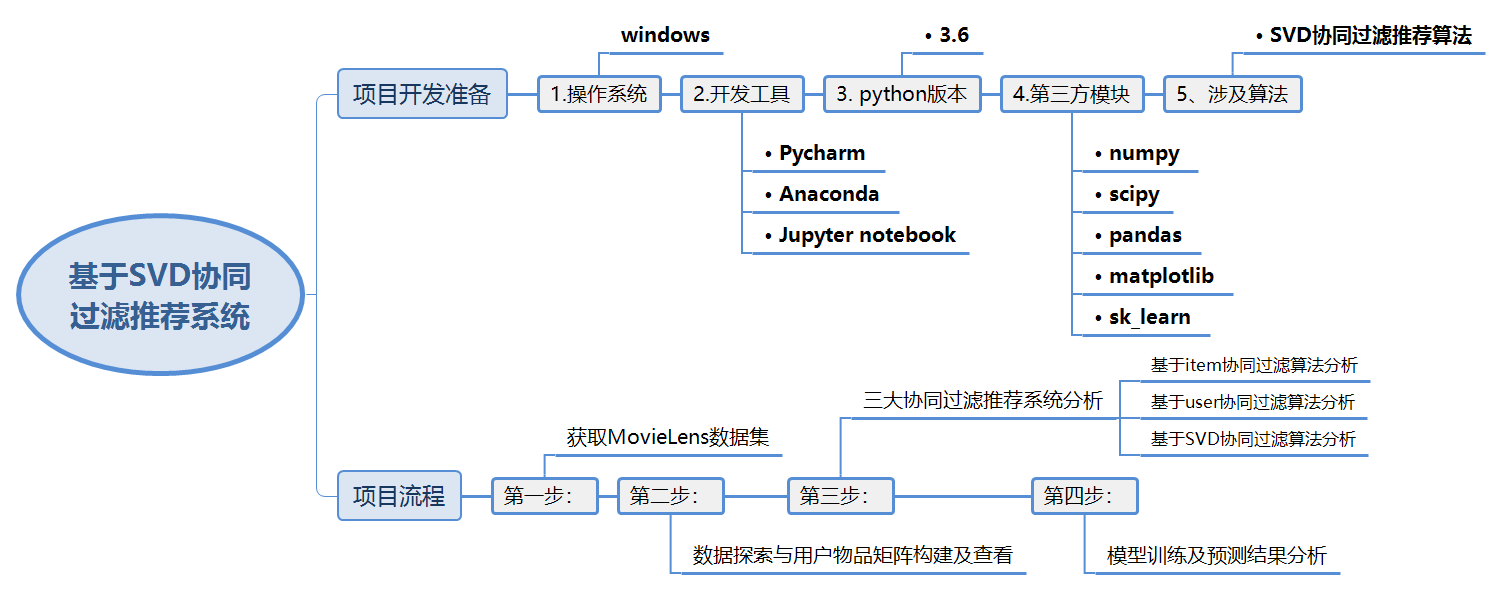
1.1 项目安排


1.2 三大协同过滤



1.3 项目开发工具
2 Movielens数据集简介
- MovieLens是推荐系统常用的数据集;
MovieLens数据集中,用户对自己看过的电影进行评分,分值为1~5;
MovieLens包括两个不同大小的库,适用于不同规模的算法;
·小规模的库事943个独立用户对1682部电影做的10000次评分的数据;
·大规模的库事6040个独立用户对3900部电影做的100万次评分的数据;
数据集下载地址:http://files.grouplens.org/datasets/movielens/ml-100k.zip
3 数据探索
3.1 导入小规模的库数据
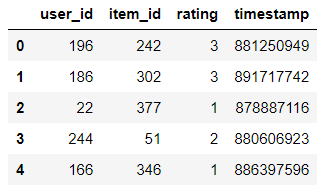
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltdata=pd.read_csv('ml-100k/u.data',sep='\t',names=['user_id','item_id','rating','timestamp'])data.head()
3.2 数据探索及发现
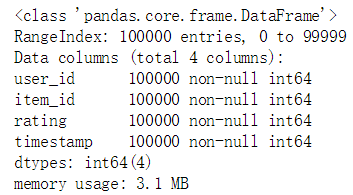
# 数据信息查看data.info()
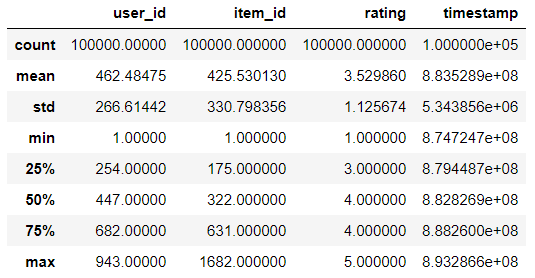
# 数据描述data.describe()
data.user_id.nunique() # nunique() --> 返回不重复user_id的个数,统计用户的个数data.item_id.nunique() # 统计被评价电影的个数
>> 943
>> 1682
data.duplicated(subset=['user_id','item_id']).sum() # 查看user_id与item_id是否有重复的情况
>> 0
从导入的数据可以看出,user_id共有943个,item_id共有1682个,与数据对于的user_id及item_id的编号刚好是1~943和1~1682,可见数据已经清洗好的,不需要重新处理
然后将数据集拆分为训练集和测试集,分别进行处理
且user_id与item_id均不存在重复的情况,数据可以直接使用。
3.3 数据检查
3.3.1 查看每个物品对应用户的数量
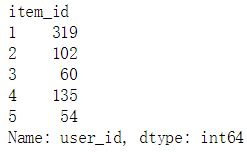
a. 根据item_id分类聚合
# 统计每个物品对应的用户数item_id_usercnt = train_data.groupby('item_id').count().user_iditem_id_usercnt[:5]
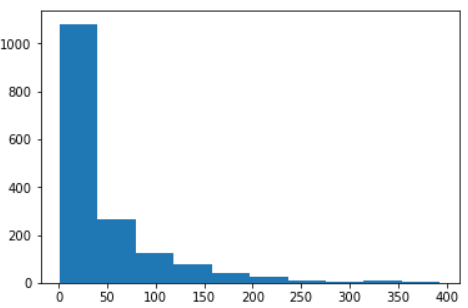
b. 直方图展示
# 展示分类聚合结果plt.hist(item_id_usercnt.values)plt.show()
c. 查看十分位数
# 分别查看每一物品对应的用户的十分位数(十分位数、二十分位数...一百分位数)item_id_usercnt.quantile(q=np.arange(0,1.1,0.1))
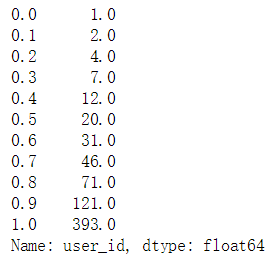
d. 物品对应用户数量数据查看发现
约有30%左右的物品对应的用户数少于10个,对这部分物品计算与其他物品的相似度不会太准确
3.3.2 查看每个用户对应物品的数量
a. 根据user_id分类聚合
# 统计每个用户对应的物品数user_id_itemcnt = train_data.groupby('user_id').count().item_iduser_id_itemcnt[:5]
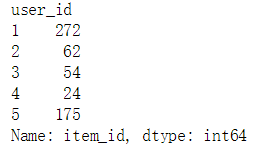
b. 直方图展示
# 展示分类聚合结果plt.hist(user_id_itemcnt.values)plt.show()
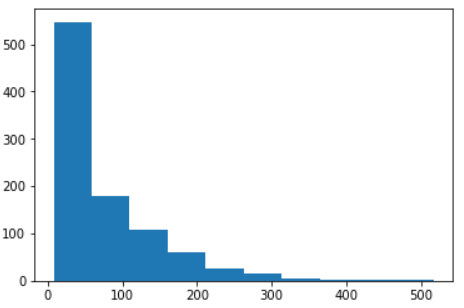
c. 查看十分位数
# 分别查看每一用户对应的物品的十分位数(十分位数、二十分位数...一百分位数)user_id_itemcnt.quantile(q=np.arange(0,1.1,0.1))
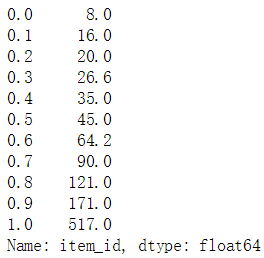
d. 物品对应用户数量数据查看发现
从每个用户对应的物品数量至少为20个的情况来看,基于用户相似度的准确度会比基于物品要好
3.4 构建用户-物品矩阵
3.4.1 获取矩阵行数m、列数n
# 通过nunique()方法分别获得user_id、item_id的去重计数m_users = train_data.user_id.nunique() #n_items = train_data.item_id.nunique()
3.4.2 创建一个全是0的m*n的矩阵并向矩阵中填充对应数据
user_item_matrix = np.zeros((m_users,n_items)) # 创建一个全是0的m*n的矩阵'''itertuples() 将每一行转换为对应的元组,且数据一一对应for line in data.head().itertuples():print(line)>> Pandas(Index=0, user_id=196, item_id=242, rating=3, timestamp=881250949)>> Pandas(Index=1, user_id=186, item_id=302, rating=3, timestamp=891717742)>> Pandas(Index=2, user_id=22, item_id=377, rating=1, timestamp=878887116)>> Pandas(Index=3, user_id=244, item_id=51, rating=2, timestamp=880606923)>> Pandas(Index=4, user_id=166, item_id=346, rating=1, timestamp=886397596)'''for line in data.itertuples():user_item_matrix[line[1]-1,line[2]-1]=line[3]'''因为user_id 和 item_id都是从1开始编号的,而矩阵的索引是从零开始data数据的第二列为user_id,第三列为item_id,第三列则为对应user对item的评分'''user_item_matrix #展示一下用户物品矩阵

3.4.3 查看用户-物品矩阵的稀疏性
# 统计矩阵中非0值的个数与矩阵总元素个数的比值,保留3位小数sparsity = round(len(user_item_matrix.nonzero()[1])/float(m_users*n_items),3)sparsity
>> 0.063
发现:用户-物品 矩阵非常稀疏,只有6%的用户物品有互动记录
4 基于item的协同过滤推荐系统
4.1 物品相似度矩阵
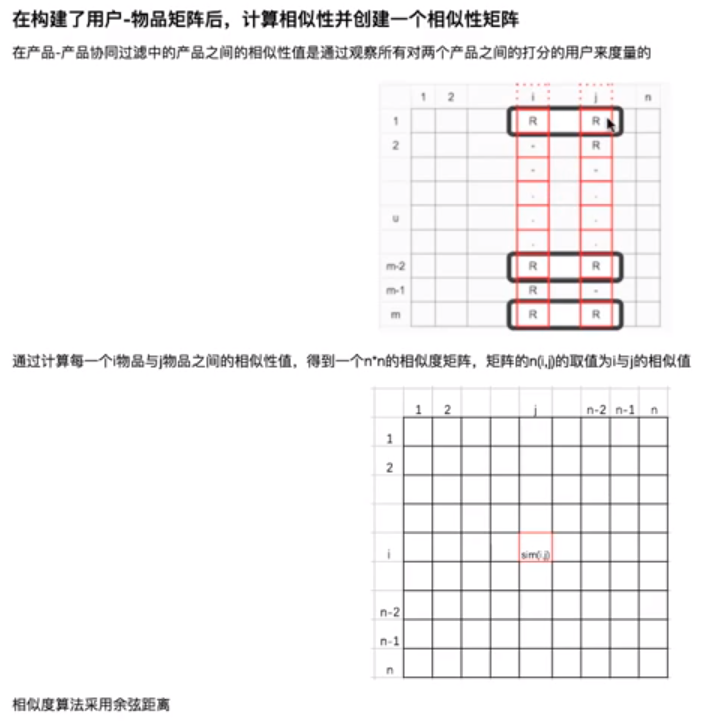
4.2 基于item的协同过滤推荐 - 预测原理
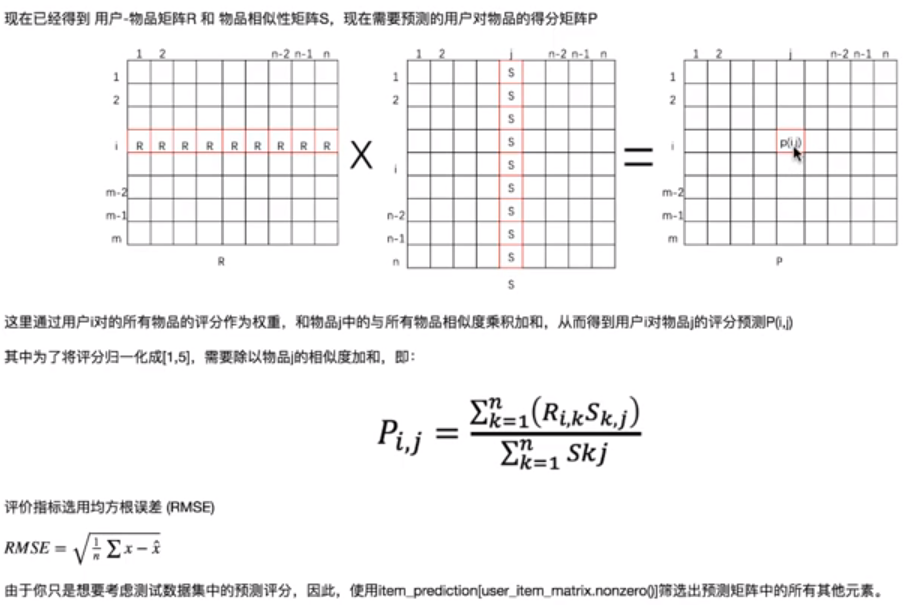
4.3 代码实现
import numpy as npimport pandas as pd# 导入数据data=pd.read_csv('ml-100k/u.data',sep='\t',names=['user_id','item_id','rating','timestamp'])# 用户物品统计n_users = data.user_id.nunique()n_items = data.item_id.nunique()# 拆分数据集from sklearn.model_selection import train_test_splittrain_data,test_data =train_test_split(data,test_size=0.3) #按照训练集70%,测试集30%的比例对数据进行拆分# 训练集 用户-物品 矩阵user_item_matrix = np.zeros((n_users,n_items))for line in train_data.itertuples():user_item_matrix[line[1]-1,line[2]-1] = line[3]# 构建物品相似矩阵 - 使用sklearn.metrics.pairwise中的cosine计算余弦距离'''采用余弦距离计算相似度如果两个物品在同一条水平线上,则其夹角为零,对应的余弦值为1,代表完全相似如果两个物品处于垂直的方向上,其夹角为90度,那么其余弦值为0,代表毫不相干'''from sklearn.metrics.pairwise import pairwise_distances# 相似度计算定义为余弦距离item_similarity_m = pairwise_distances(user_item_matrix.T,metric='cosine')# 物品相似矩阵探索'''item_similarity_m.shape >> (1682, 1682)item_similarity_m[0:5,0:5].round(2) # 取5*5的矩阵查看其保留两位小数的数据# pairwise_distances模块在计算物品相似性时,不会计算自己与自己的相似性,所以所以对角线的值都为0>> array([[0. , 0.67, 0.73, 0.7 , 0.81],[0.67, 0. , 0.84, 0.64, 0.82],[0.73, 0.84, 0. , 0.8 , 0.85],[0.7 , 0.64, 0.8 , 0. , 0.76],[0.81, 0.82, 0.85, 0.76, 0. ]])'''# 现在我们只分析上三角,得到等分位数item_similarity_m_triu = np.triu(item_similarity_m,k=1) # 取得上三角数据item_sim_nonzero = np.round(item_similarity_m_triu[item_similarity_m_triu.nonzero()],3)'''# 上三角矩阵arr=np.linspace(1,9,9).reshape(3,3)arr>> array([[1., 2., 3.],[4., 5., 6.],[7., 8., 9.]])np.triu(arr,k=1) # 默认k=0,k的值正数表示向右上角移对应个单位,把对应位置全部变为0>> array([[0., 2., 3.],[0., 0., 6.],[0., 0., 0.]])'''# 查看十分位数np.percentile(item_sim_nonzero,np.arange(0,101,10))
>> array([0. , 0.829, 0.884, 0.919, 0.948, 0.976, 1., 1.,1. , 1. , 1. ])
可以看出相似性得分普遍偏大,相似度没有比较好的可区分性。
4.4 训练集预测
user_item_precdiction = user_item_matrix.dot(item_similarity_m) / np.array([np.abs(item_similarity_m).sum(axis=1)])# 除以np.array([np.abs(item_similarity_m).sum(axis=1)]是为了可以使评分在1~5之间,使1~5的标准化# 只取数据集中有评分的数据集进行评估from sklearn.metrics import mean_squared_errorfrom math import sqrtprediction_flatten = user_item_precdiction[train_item_matrix.nonzero()]user_item_matrix_flatten = train_item_matrix[train_item_matrix.nonzero()]error_train = sqrt(mean_squared_error(prediction_flatten,user_item_matrix_flatten)) # 均方根误差计算print('训练集预测均方根误差:',error_train)
>> 训练集预测均方根误差:3.4714925320107684
4.5 测试集预测
test_data_matrix = np.zeros((n_users,n_items))for line in test_data.itertuples():test_data_matrix[line[1]-1,line[2]-1]=line[3]# 预测矩阵item_prediction = test_data_matrix.dot(item_similarity_m) / np.array(np.abs(item_similarity_m).sum(axis=1))# 只取数据集中有评分的数据集进行评估prediction_flatten = user_item_precdiction[test_data_matrix.nonzero()]test_data_matrix_flatten = test_data_matrix[test_data_matrix.nonzero()]error_test = sqrt(mean_squared_error(prediction_flatten,test_data_matrix_flatten)) # 均方根误差计算print('测试集预测均方根误差:',error_test)
>> 测试集预测均方根误差:3.4645810277607487
4.6 单模型结果提示思路
4.6.1 改变相似度算法 - 采用欧式距离
# 相似度计算定义为欧式距离item_similarity_m = pairwise_distances(user_item_matrix.T,metric='euclidean')
>> 训练集预测均方根误差:3.3818902386408056
>> 测试集预测均方根误差:3.3763275676001396
4.6.2 增加训练集比例
from sklearn.model_selection import train_test_splittrain_data,test_data =train_test_split(data,test_size=0.2)
>> 训练集预测均方根误差:3.4464124130045506
>> 测试集预测均方根误差:3.4247175440782516
4.6.3 增加训练集的同时采用欧式距离
>> 训练集预测均方根误差:3.3395618010919823
>> 测试集预测均方根误差:3.339569787071282
4.7 基于item协同过滤推荐系统结果分析
- 1、通过改变物品矩阵相似度(采用欧式距离)的计算方法可以看出预测效果略有提升;
- 2、通过增加训练集的方法对预测结果略有提升,但并不明显;
- 3、在增加训练集的同时采用欧式距离计算相似度发现预测效果提升最好,但均方根误差依然很大,与之前预测(物品是分位数查看结果,其区分性并不是很好)相符;
- 4、因而在此例中使用基于item的协同过滤推荐系统并不理想。
5 基于user的协同过滤的推荐系统
5.1 用户相似矩阵
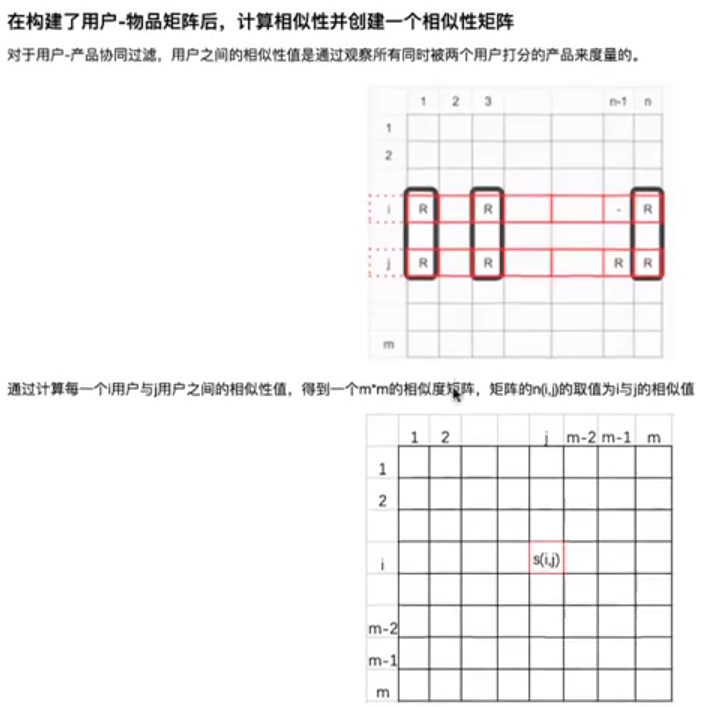
5.2 基于user的协同过滤的推荐系统 - 预测原理
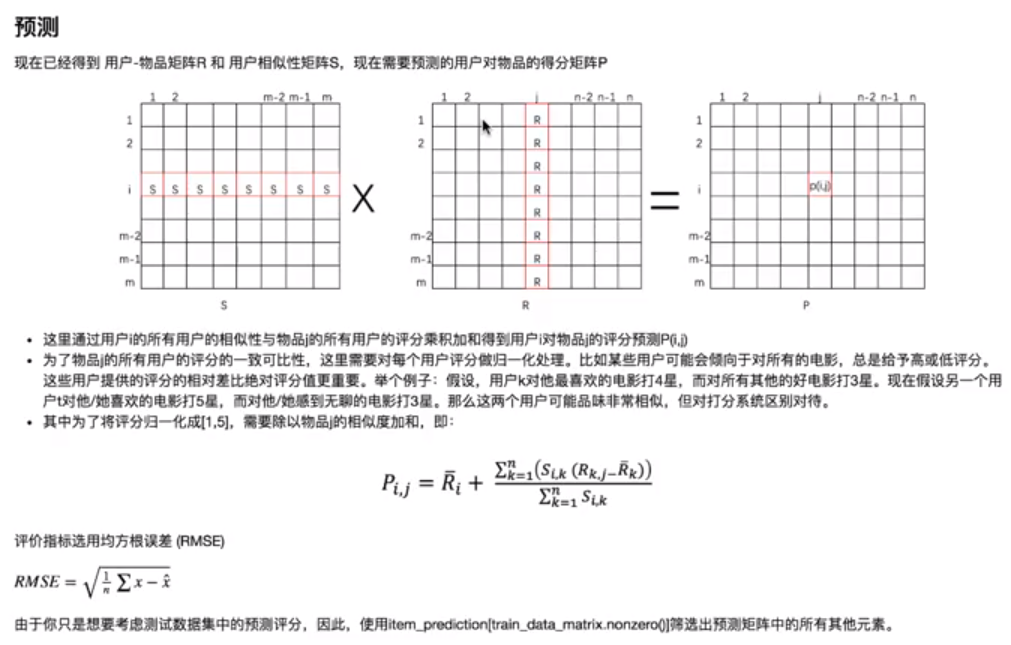
5.3 代码实现
# 导入数据import numpy as npimport pandas as pddata=pd.read_csv('ml-100k/u.data',sep='\t',names=['user_id','item_id','rating','timestamp'])# 用户物品统计n_users = data.user_id.nunique()n_items = data.item_id.nunique()# 拆分数据集from sklearn.model_selection import train_test_split# 按照训练集70%,测试集30%的比例对数据进行拆分train_data,test_data =train_test_split(data,test_size=0.3)# 训练集 用户-物品 矩阵user_item_matrix = np.zeros((n_users,n_items))for line in train_data.itertuples():user_item_matrix[line[1]-1,line[2]-1] = line[3]# 构建用户相似矩阵 - 采用余弦距离from sklearn.metrics.pairwise import pairwise_distances# 相似度计算定义为余弦距离user_similarity_m = pairwise_distances(user_item_matrix,metric='cosine') # 每个用户数据为一行,此处不需要再进行转置user_similarity_m[0:5,0:5].round(2) # 取5*5的矩阵查看其保留两位小数的数据'''>> array([[0. , 0.85, 0.96, 0.96, 0.74],[0.85, 0. , 0.99, 0.84, 0.93],[0.96, 0.99, 0. , 0.77, 0.97],[0.96, 0.84, 0.77, 0. , 0.97],[0.74, 0.93, 0.97, 0.97, 0. ]])'''# 现在我们只分析上三角,得到等分位数user_similarity_m_triu = np.triu(user_similarity_m,k=1) # 取得上三角数据user_sim_nonzero = np.round(user_similarity_m_triu[user_similarity_m_triu.nonzero()],3)np.percentile(user_sim_nonzero,np.arange(0,101,10))
>> array([0.266,0.752,0.804,0.842,0.871,0.896,0.919,0.941,0.962,0.991, 1. ])
可以看出用户矩阵的相似性区分性还是比较好的
5.4 训练集预测
mean_user_rating = user_item_matrix.mean(axis=1)rating_diff = (user_item_matrix - mean_user_rating[:,np.newaxis]) # np.newaxis作用:为mean_user_rating增加一个维度,实现加减操作user_precdiction = mean_user_rating[:,np.newaxis] + user_similarity_m.dot(rating_diff) / np.array([np.abs(user_similarity_m).sum(axis=1)]).T# 处以np.array([np.abs(item_similarity_m).sum(axis=1)]是为了可以使评分在1~5之间,使1~5的标准化# 只取数据集中有评分的数据集进行评估from sklearn.metrics import mean_squared_errorfrom math import sqrtprediction_flatten = user_precdiction[user_item_matrix.nonzero()]user_item_matrix_flatten = user_item_matrix[user_item_matrix.nonzero()]error_train = sqrt(mean_squared_error(prediction_flatten,user_item_matrix_flatten)) # 均方根误差计算print('训练集预测均方根误差:',error_train)
>> 训练集预测均方根误差:3.165938175006113
5.5 测试集预测
test_data_matrix = np.zeros((n_users,n_items))for line in test_data.itertuples():test_data_matrix[line[1]-1,line[2]-1]=line[3]# 预测矩阵rating_diff = (test_data_matrix - mean_user_rating[:,np.newaxis]) # np.newaxis作用:为mean_user_rating增加一个维度,实现加减操作user_precdiction = mean_user_rating[:,np.newaxis] + user_similarity_m.dot(rating_diff) / np.array([np.abs(user_similarity_m).sum(axis=1)]).T# 只取数据集中有评分的数据集进行评估prediction_flatten = user_precdiction[user_item_matrix.nonzero()]user_item_matrix_flatten = user_item_matrix[user_item_matrix.nonzero()]error_test = sqrt(mean_squared_error(prediction_flatten,user_item_matrix_flatten)) # 均方根误差计算print('测试集预测均方根误差:',error_test)
>> 测试集预测均方根误差:3.393103348518984
5.6 单模型结果提示思路
5.6.1 改变相似度算法 - 采用欧式距离
# 相似度计算定义为欧式距离item_similarity_m = pairwise_distances(user_item_matrix.T,metric='euclidean')
>> 训练集预测均方根误差:3.1190848133071603
>> 测试集预测均方根误差:3.3913121798056123
5.6.2 减少训练集比例 / 增加测试集比例
from sklearn.model_selection import train_test_splittrain_data,test_data =train_test_split(data,test_size=0.4)
>> 训练集预测均方根误差:3.237884760612846
>> 测试集预测均方根误差:3.34890617988761
5.6.2 增加训练集比例
from sklearn.model_selection import train_test_splittrain_data,test_data =train_test_split(data,test_size=0.2)
>> 训练集预测均方根误差:3.094954182470391
>> 测试集预测均方根误差:3.435958471375406
5.6.3 增加测试集的同时采用欧式距离
>> 训练集预测均方根误差:3.1925775976328934
>> 测试集预测均方根误差:3.330738557937318
5.7 基于user协同过滤推荐系统结果分析
- 1、采用欧式距离的情况下,训练集数据预测效果提升较测试集明显;
- 2、运行结果显示基于user的预测结果在测试集上普遍不如在训练集上的预测结果。分析其原因:a.user相似矩阵本身太小(943*943),远小于item相似矩阵的(1682*1682);b.在原因a的基础上,测试集的矩阵就更小;
- 2、因而基于user协同过滤系统中,分别采用了减小/增大训练集两种优化方法对模型进行了测试,发现只要数据集增大,其预测效果就有提升;
- 3、在减小训练集并采用欧式距离的情况下,模型在测试集的预测效果有所提升,但依然不理想;
- 4、与基于item的协同过滤系统相比,基于user协同过滤系统模型预测效果明显略微优秀。
6 基于SVD协同过滤推荐系统
6.1 SVD协同推荐系统原理
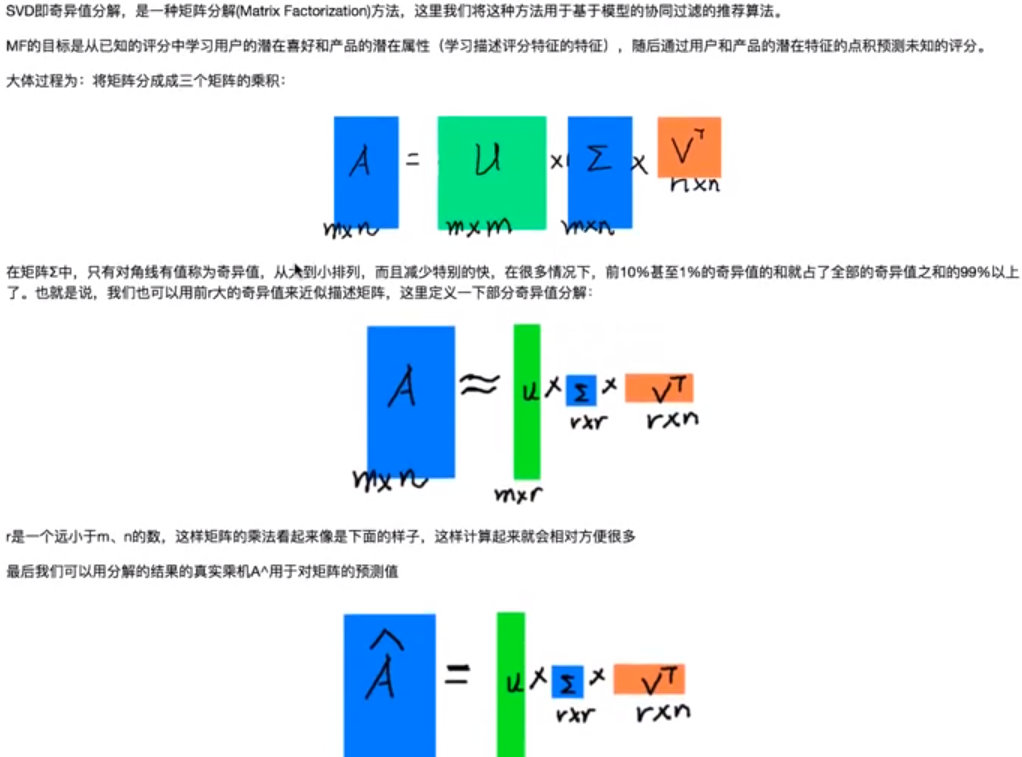
6.2 代码实现
# 导入数据import numpy as npimport pandas as pddata=pd.read_csv('ml-100k/u.data',sep='\t',names=['user_id','item_id','rating','timestamp'])# 拆分数据集并分别构建用户-物品矩阵# 用户物品统计n_users = data.user_id.nunique()n_items = data.item_id.nunique()from sklearn.model_selection import train_test_split# 按照训练集70%,测试集30%的比例对数据进行拆分train_data,test_data =train_test_split(data,test_size=0.3)# 训练集 用户-物品 矩阵train_data_matrix = np.zeros((n_users,n_items))for line in train_data.itertuples():train_data_matrix[line[1]-1,line[2]-1] = line[3]# 测试集 用户-物品 矩阵test_data_matrix = np.zeros((n_users,n_items))for line in train_data.itertuples():test_data_matrix[line[1]-1,line[2]-1] = line[3]# SVD矩阵import scipy.sparse as spfrom scipy.sparse.linalg import svds# 奇异值分解,超参数k的值就是设定要留下的特征值的数量u, s, vt = svds(train_data_matrix,k=20)s_diag_matrix = np.diag(s)svd_prediction = np.dot(np.dot(u,s_diag_matrix),vt)'''print(u.shape) >> (943, 20)print(s.shape) >> (20,)print(vt.shape) >> (20, 1682)print(s_diag_matrix.shape) >> (20, 20)print(svd_prediction.shape) >> (943, 1682)'''# 预测值限定最小值和最大值# 预测值小于0的均设置为0,大于5的均设置为5svd_prediction[svd_prediction < 0] =0svd_prediction[svd_prediction > 5] =5
6.3 训练集预测
# 只取预测数据中有评分的数据,进行评估from sklearn.metrics import mean_squared_errorfrom math import sqrtprediction_flatten = svd_prediction[train_data_matrix.nonzero()]train_data_matrix_flatten = train_data_matrix[train_data_matrix.nonzero()]error_train = sqrt(mean_squared_error(prediction_flatten,train_data_matrix_flatten))print('训练集预测均方根误差:',error_train)
>> 训练集预测均方根误差:2.440629842312816
6.4 测试集预测
prediction_flatten = svd_prediction[test_data_matrix.nonzero()]test_data_matrix_flatten = test_data_matrix[test_data_matrix.nonzero()]error_test = sqrt(mean_squared_error(prediction_flatten,test_data_matrix_flatten))print('测试集预测均方根误差:',error_test)
>> 测试集预测均方根误差:2.440629842312816
7 三大协同过滤推荐系统总结分析
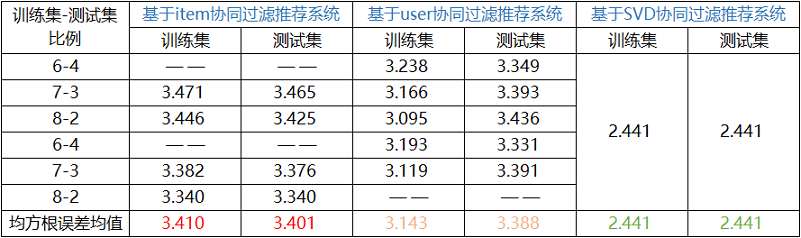
- 1、总体而言,基于小规模MovieLens数据集的本案例中的三大协同过滤推荐系统,其预测的效果总体上可以表示为:推荐系统预测效果:SVD > user > item。
- 2、根据基于user系统过滤推荐系统的情况可以看出,协同过滤推荐系统的数据越多,且数据之间互动越多,则推荐效果越好,然而一般情况下正是因为互动不够充分才会需要推荐系统,所以,收集尽可能多的数据,基于大数据的分析就显的相对比较重要;
- 3 在三大推荐系统中,SCD奇异值推荐系统表现尤为突出,预测的结果相对于其他两个推荐系统而言有非常大的提升,唯一的缺点就是其难以加以解释,但不失为是一种非常好的推荐系统。
NMF
参考
https://blog.csdn.net/qq_26225295/article/details/51165858
电影推荐系统---协同过滤算法(SVD,NMF)的更多相关文章
- SVD++:推荐系统的基于矩阵分解的协同过滤算法的提高
1.背景知识 在讲SVD++之前,我还是想先回到基于物品相似的协同过滤算法.这个算法基本思想是找出一个用户有过正反馈的物品的相似的物品来给其作为推荐.其公式为:
- 机器学习 | 简介推荐场景中的协同过滤算法,以及SVD的使用
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第29篇文章,我们来聊聊SVD在上古时期的推荐场景当中的应用. 推荐的背后逻辑 有没有思考过一个问题,当我们在淘宝或者是 ...
- 使用Python3.7配合协同过滤算法(base on user,基于人)构建一套简单的精准推荐系统(个性化推荐)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_136 时至2020年,个性化推荐可谓风生水起,Youtube,Netflix,甚至于Pornhub,这些在互联网上叱咤风云的流媒体 ...
- Andrew Ng机器学习课程笔记--week9(下)(推荐系统&协同过滤)
本周内容较多,故分为上下两篇文章. 本文为下篇. 一.内容概要 1. Anomaly Detection Density Estimation Problem Motivation Gaussian ...
- Collaborative Filtering(协同过滤)算法详解
基本思想 基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分.根据不同用户对相同商品或内容的态度和偏好程度计算用户 ...
- Spark MLlib协同过滤算法
算法说明 协同过滤(Collaborative Filtering,简称CF,WIKI上的定义是:简单来说是利用某个兴趣相投.拥有共同经验之群体的喜好来推荐感兴趣的资讯给使用者,个人透过合作的机制给予 ...
- 基于Python协同过滤算法的认识
Contents 1. 协同过滤的简介 2. 协同过滤的核心 3. 协同过滤的实现 4. 协同过滤的应用 1. 协同过滤的简介 关于协同过滤的一个最经典的例子就是看电影,有时候 ...
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
随机推荐
- Java异常处理场景中不同位置的返回值详细解析
Java 异常处理中的返回值在不同位置不同场景下是有一些差别的,这里需要格外注意 具体分以下两种场景: 1 finally语句块没有return语句,即当代码执行到try或者catch语句块中的ret ...
- Angular入门到精通系列教程(11)- 模块(NgModule),延迟加载模块
1. 摘要 2. NgModule举例.说明 3. Angular CLI生成模块 4. 延迟加载模块 5. 总结 环境: Angular CLI: 11.0.6 Angular: 11.0.7 No ...
- chain issues incorrect order,EXtra certs,Contains anchor
背景: 下载颁发下来的ssl证书安装好之后网站正常显示安全,但是通过ssl证书网站去检测报错误:chain issues incorrect order,EXtra certs,Contains an ...
- windows 系统 MySQL_5.6.21安装教程
1.双击安装文件 mysql_installer_community_V5.6.21.1_setup.1418020972.msi,等待安装界面出现,见下图: 2.勾选:I accept thel ...
- 异步日志 Loguru
https://mp.weixin.qq.com/s/hy68s610B9GbL_wgwTn7nA 更优美的python日志管理库Loguru Asynchronous, Thread-safe, M ...
- 签名 sign key 纸质邮件 历史 RSA诞生历史
API接口签名校验,如何安全保存appsecret? - 知乎 https://www.zhihu.com/question/40855191 要保证一般的客户端-服务器通信安全,可以使用3个密钥. ...
- js控制页面元素值
// TODO id 定位 var ele1 = document.getElementById("test1"); // alert(ele1.value) // TODO 根据 ...
- loj黑暗城堡
黑暗城堡 题目描述 你知道黑暗城堡有\(N\)个房间,M 条可以制造的双向通道,以及每条通道的长度. 城堡是树形的并且满足下面的条件: 设\(D_i\)为如果所有的通道都被修建,第i号房间与第1号房间 ...
- bzoj 2038(莫队算法)
2038: [2009国家集训队]小Z的袜子(hose) 时间限制: 20 Sec 内存限制: 259 MB 题目描述 作为一个生活散漫的人,小Z每天早上都要耗费很久从一堆五颜六色的袜子中找出一双来 ...
- SpringBoot启动方式,Spring Boot 定义系统启动任务
SpringBoot启动方式,Spring Boot 定义系统启动任务 SpringBoot启动方式 1.1 方法一 1.2 方法二 1.2.1 start.sh 1.2.2 stop.sh 1.2. ...