java笔试中创建String对象的思考
题目是这样的下面那些生成新的String对象()
A 、 String s = new String();
B 、 String s = new String("A");
C、 String s = " ";
D、 String s = "A".intern();
E、 String s = (String)String.class.newInstance();
从这一个题目突然一看之下,感觉A、B、C、D、E全都对,那么到底选什么那?
分析一下:
A:创建了名为s的对象
B:可能创建了两个对象,一个是s对象,另一个是位于常量池中的A对象
C:创建了一个指向空字符串的引用
D:“A”.intern是什么鬼?咱们具体分析一下:
什么都先不说,先看下面这个引入的例子:
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin");
本人JDK版本1.8,输出结果为:
true
true
再将上面的例子加上一行代码:
String str2 = "SEUCalvin";//新加的一行代码,其余不变
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin");
false
false
是不是感觉莫名其妙,新定义的str2好像和str1没有半毛钱的关系,怎么会影响到有关str1的输出结果呢?其实这都是intern()方法搞的鬼!看完这篇文章,你就会明白。o(∩_∩)o
说实话我本来想总结一篇Android内存泄漏的文章的,查阅了很多资料,发现不得不从Java的OOM讲起,讲Java的OOM又不得不讲Java的虚拟机架构。如果不了解JVM的同学可以查看此篇JVM——Java虚拟机架构。(这篇文章已经被我修改过N多次了,个人感觉还是挺全面清晰的,每次看都会有新的理解。)
在JVM架构一文中也有介绍,在JVM运行时数据区中的方法区有一个常量池,但是发现在JDK1.6以后常量池被放置在了堆空间,因此常量池位置的不同影响到了String的intern()方法的表现。深入了解后发现还是值得写下来记录一下的。
1.为什么要介绍intern()方法
intern()方法设计的初衷,就是重用String对象,以节省内存消耗。这么说可能有点抽象,那么就用例子来证明。
static final int MAX = 100000;
static final String[] arr = new String[MAX]; public static void main(String[] args) throws Exception {
//为长度为10的Integer数组随机赋值
Integer[] sample = new Integer[10];
Random random = new Random(1000);
for (int i = 0; i < sample.length; i++) {
sample[i] = random.nextInt();
}
//记录程序开始时间
long t = System.currentTimeMillis();
//使用/不使用intern方法为10万个String赋值,值来自于Integer数组的10个数
for (int i = 0; i < MAX; i++) {
arr[i] = new String(String.valueOf(sample[i % sample.length]));
//arr[i] = new String(String.valueOf(sample[i % sample.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}
这个例子也比较简单,就是为了证明使用intern()比不使用intern()消耗的内存更少。
先定义一个长度为10的Integer数组,并随机为其赋值,在通过for循环为长度为10万的String对象依次赋值,这些值都来自于Integer数组。两种情况分别运行,可通过Window ---> Preferences --> Java --> Installed JREs设置JVM启动参数为-agentlib:hprof=heap=dump,format=b,将程序运行完后的hprof置于工程目录下。再通过MAT插件查看该hprof文件。
两次实验结果如下:
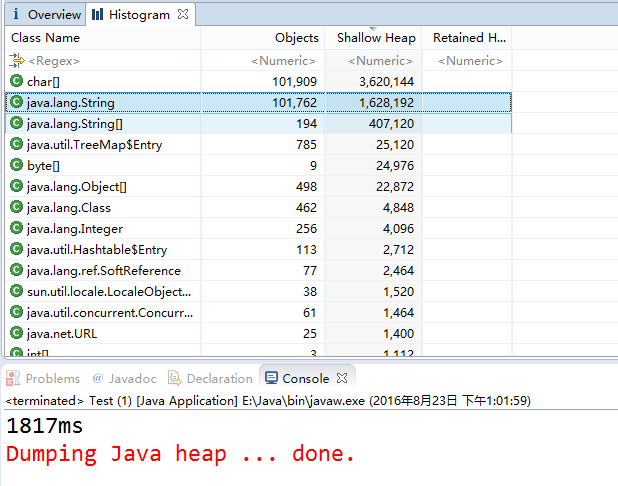
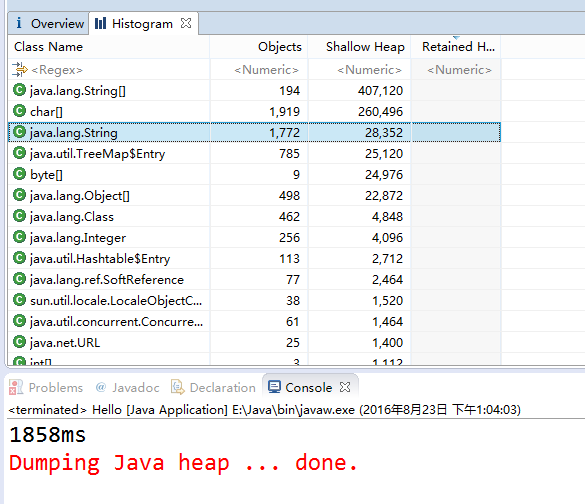
从运行结果来看,不使用intern()的情况下,程序生成了101762个String对象,而使用了intern()方法时,程序仅生成了1772个String对象。自然也证明了intern()节省内存的结论。
细心的同学会发现使用了intern()方法后程序运行时间有所增加。这是因为程序中每次都是用了new String后又进行intern()操作的耗时时间,但是不使用intern()占用内存空间导致GC的时间是要远远大于这点时间的。
2.深入认识intern()方法
JDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能不同,具体怎么个不同法,且看看下面代码:
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
输出结果为:
JDK1.6以及以下:false false
JDK1.7以及以上:false true
再分别调整上面代码2.3行、7.8行的顺序
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
输出结果为:
JDK1.6以及以下:false false
JDK1.7以及以上:false false
下面依据上面代码对intern()方法进行分析:
2.1 JDK1.6
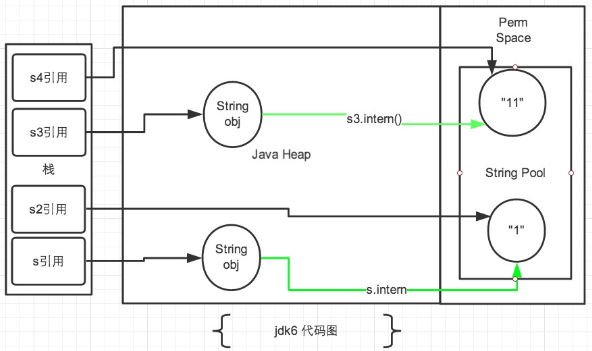
在JDK1.6中所有的输出结果都是 false,因为JDK1.6以及以前版本中,常量池是放在 Perm 区(属于方法区)中的,熟悉JVM的话应该知道这是和堆区完全分开的。
使用引号声明的字符串都是会直接在字符串常量池中生成的,而 new 出来的 String 对象是放在堆空间中的。所以两者的内存地址肯定是不相同的,即使调用了intern()方法也是不影响的。如果不清楚String类的“==”和equals()的区别可以查看我的这篇博文Java面试——从Java堆、栈角度比较equals和==的区别。
intern()方法在JDK1.6中的作用是:比如String s = new String("SEU_Calvin"),再调用s.intern(),此时返回值还是字符串"SEU_Calvin",表面上看起来好像这个方法没什么用处。但实际上,在JDK1.6中它做了个小动作:检查字符串池里是否存在"SEU_Calvin"这么一个字符串,如果存在,就返回池里的字符串;如果不存在,该方法会把"SEU_Calvin"添加到字符串池中,然后再返回它的引用。然而在JDK1.7中却不是这样的,后面会讨论。
2.2 JDK1.7
针对JDK1.7以及以上的版本,我们将上面两段代码分开讨论。先看第一段代码的情况:
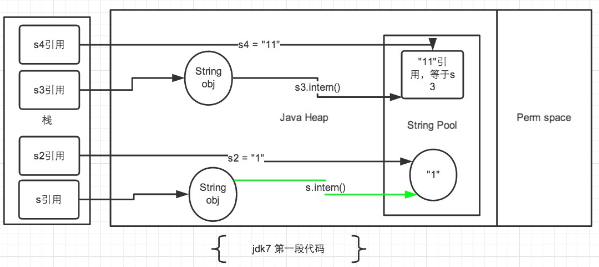
再把第一段代码贴一下便于查看:
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
String s = newString("1"),生成了常量池中的“1” 和堆空间中的字符串对象。
s.intern(),这一行的作用是s对象去常量池中寻找后发现"1"已经存在于常量池中了。
String s2 = "1",这行代码是生成一个s2的引用指向常量池中的“1”对象。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String("1") + newString("1"),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。
s3.intern(),这一行代码,是将 s3中的“11”字符串放入 String 常量池中,此时常量池中不存在“11”字符串,JDK1.6的做法是直接在常量池中生成一个 "11" 的对象。
但是在JDK1.7中,常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用直接指向 s3 引用的对象,也就是说s3.intern() ==s3会返回true。
String s4 = "11", 这一行代码会直接去常量池中创建,但是发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。因此s3 == s4返回了true。
下面继续分析第二段代码:
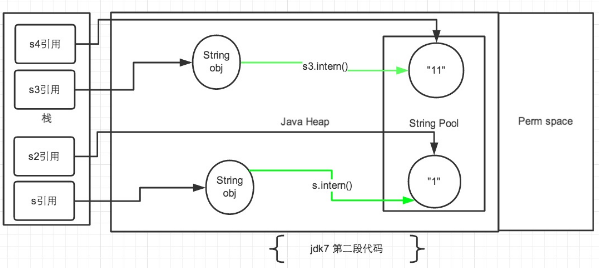
再把第二段代码贴一下便于查看:
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
String s = newString("1"),生成了常量池中的“1” 和堆空间中的字符串对象。
String s2 = "1",这行代码是生成一个s2的引用指向常量池中的“1”对象,但是发现已经存在了,那么就直接指向了它。
s.intern(),这一行在这里就没什么实际作用了。因为"1"已经存在了。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String("1") + newString("1"),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。
String s4 = "11", 这一行代码会直接去生成常量池中的"11"。
s3.intern(),这一行在这里就没什么实际作用了。因为"11"已经存在了。
结果就是 s3 和 s4 的引用地址明显不同。因此返回了false。
3 总结
终于要做Ending了。现在再来看一下开篇给的引入例子,是不是就很清晰了呢。
String str1 = new String("SEU") + new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin");
str1.intern() == str1就是上面例子中的情况,str1.intern()发现常量池中不存在“SEUCalvin”,因此指向了str1。 "SEUCalvin"在常量池中创建时,也就直接指向了str1了。两个都返回true就理所当然啦。
那么第二段代码呢:
String str2 = "SEUCalvin";//新加的一行代码,其余不变
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin");
也很简单啦,str2先在常量池中创建了“SEUCalvin”,那么str1.intern()当然就直接指向了str2,你可以去验证它们两个是返回的true。后面的"SEUCalvin"也一样指向str2。所以谁都不搭理在堆空间中的str1了,所以都返回了false。
转载请注明出处http://blog.csdn.net/seu_calvin/article/details/52291082
从上面的分析中,我们就可以知道“A”.intern();不一定创建了String对象,可能只是取了一个A对象的引用。
E、选项则是产生一个实例,并没有创建String对象。
转载请注明出处:https://i.cnblogs.com/EditPosts.aspx?postid=9119698&update=1
java笔试中创建String对象的思考的更多相关文章
- java 创建string对象机制 字符串缓冲池 字符串拼接机制
对于创建String对象的机制,在这一过程中涉及的东西还是值得探究一番的. 首先看通过new String对象和直接赋值的方式有什么区别,看如下代码: public static void main( ...
- Java中创建实例化对象的几种方式
Java中创建实例化对象有哪些方式? ①最常见的创建对象方法,使用new语句创建一个对象.②通过工厂方法返回对象,例:String s =String.valueOf().(工厂方法涉及到框架)③动用 ...
- Java 关于创建String对象过程的内存分配
一.String s = "abc" 和 String s = new String("abc") 的区别 1.String s = "abc&qu ...
- java中的string对象深入了解
这里来对Java中的String对象做一个稍微深入的了解. Java对象实现的演进 String对象是Java中使用最频繁的对象之一,所以Java开发者们也在不断地对String对象的实现进行优化,以 ...
- Java中创建的对象多了,必然影响内存和性能
1, Java中创建的对象多了,必然影响内存和性能,所以对象的创建越少越好,最后还要记得销毁.
- 创建String对象过程的内存分配
转载自 https://blog.csdn.net/xiabing082/article/details/49759071 常量池(Constant Pool):指的是在编译期被确定 ...
- Java基础之创建实例化对象的方式
Java中创建(实例化)对象的五种方式 1.用new语句直接创建对象,这是最常见的创建对象的方法. 2.通过工厂方法返回对象,如:String str = String.valueOf(23); 3 ...
- JavaScript -- 时光流逝(三):js中的 String 对象的方法
JavaScript -- 知识点回顾篇(三):js中的 String 对象的方法 (1) anchor(): 创建 HTML 锚. <script type="text/javasc ...
- 通常Struts框架会自动地从action mapping中创建action对象
开发者不必在Spring中去注册action,尽管可以这么去做,通常Struts框架会自动地从action mapping中创建action对象 struts2-spring-plugin-x-x-x ...
随机推荐
- [GKCTF2020]老八小超市儿
题目来自buu 一.题目初探 首先是一个shopxo搭建的演示站,通过扫描后台得到如下的网页 二.题目解答 首先是找到后台登陆的admin.php,然后通过百度找到shopxo的默认管理员登陆账号和密 ...
- 网件wndr4300 ttl连接
路由成砖而还能进入cfe或uboot等情况下,可以通过ttl快速救砖. r4300主板有TTL的接线脚,脚的顺序可以找在OpenWrt的wiki上找到. 如下图4个TTL针在左下角,从下往上分别是GN ...
- openpose c++ 配置教程 + python api
之前有介绍过基于tensorflow的openpose版本安装,但是我觉得没有caffe框架那么好用,很多功能也实现不了,比如调节net_resolution的调节,通过调节分辨率来提高检测的精确性和 ...
- Git 创建新分支检查分支
创建分支和切换分支,也可以称为检出分支 创建新分支 git branch branchName 切换到新分支 git checkout branchName 上面两个命令也可以合成为一个命令: git ...
- Py基础—变量名,条件循环,空执行,编码,运算符,字符比较,简化写法
变量名 只能是字母,数字,下划线.数字不能开头,不要和python内置的东西重复.赋予变量名内容:name1 = "shit" 输出变量名内容 print(name1) 条件语句 ...
- Win2008 server R2重置登录密码Administrator
1.PE方式修改密码 背景:https://www.cnblogs.com/Crazy-Liu/p/11245730.html 上述连接中的有AD域的机器系统使用哑巴式老毛桃等启动PE出现以下: 原因 ...
- LVS负载均衡NAT模式原理介绍以及配置实战
LVS基本原理 流程解释: 当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间 PREROUTING 链首先会接收到用户请求,判断目标 IP 确定是本机 IP ...
- 扩展PE头属性说明
CRC检测的算法就是checksum 以下是DllCharacteristics的参数说明
- GDB查看内存命令(x命令) 用gdb查看指定地址的内存内容
GDB查看内存命令(x命令) - super119 - 博客园 https://www.cnblogs.com/super119/archive/2011/11/18/2254382.html 可以使 ...
- ftp协议服务器与tinyhttp服务demo
https://www.jianshu.com/p/fb9fcb69efc9 ....... https://www.jianshu.com/p/e9a2e0755496 ============== ...