[Docker镜像] 关于阿里云容器镜像服务的使用(以天池比赛提交镜像为例)
最近在参加天池比赛,由于比赛需要使用阿里云容器镜像服务完成线上预测任务,所以花费了3-4天的时间了解并使用Docker完成相关镜像操作,在此分享下我学习的内容,以下是本文的目录结构:
- 介绍
- 镜像
- 容器
- 仓库
- 阿里镜像服务使用流程
- 开通镜像服务
- 构建镜像
- 检查镜像
- 推送镜像
- 其他
一、介绍
首先我们要知道为什么要使用Docker(可实现容器和镜像)?Docker是一种虚拟化方式,它与虚拟机不同之处在于:Docker不像虚拟机要提前下载好一个操作系统(Operating System, OS)才能实现虚拟化,很方便让用户把一个用户程序从一个平台直接迁移到另一个平台。举个简单的例子:你用一台电脑,从Github上fork的人脸识别项目代码要求使用环境得在cuda10.1和Pytorch1.4,然后你又要搞另外一个有关垃圾分类的算法项目,但这个项目又要求你的环境配置是cuda10。不同项目要求不同环境,这就比较让人为难,因此Docker的出现能让你本机安装环境不变的情况,虚拟化出不同的环境,且不同容器内放着不同代码,这样你能更好的进行项目迁移和扩展。云服务提供商也是用这种办法让用户更高效地调用他们平台资源。
那具体有哪些应用场景呢?例如:
- 公司要你同时进行多个不同环境配置下不同的项目。
- 算法比赛要对你代码预测时间进行考评。
- 云服务提供商要更好地利用服务器资源。
Docker包括三个概念:镜像(Image),容器(Container)和仓库(Repository)。
1. 镜像(Image)
镜像包含一个完整的ubuntu操作系统环境,相当于一个root文件系统,采用分层储存法(前一层是后一层基础,每一层的改变只会发生在自己这一层。基于基础镜像,自己还能定制化加入其它层)。
2. 容器(Container)
如果说镜像是基础层,那么容器就是它最上层的存储层。熟悉类和实例的朋友,可以把镜像看作类,容器看作实例。任何保存与容器存储层的信息都会被容器删除而丢失,因此不建议向其写入任何数据,用数据卷Volume比较好,这样数据不会随容器消失而丢失。容器的好处就是,你有镜像的环境,你再构建个容器关联到该镜像环境下,你就能把容器当作是一个简易版的Linux环境,在其中放入你的代码和数据,进入容器运行它们。
3. 仓库(Repository)
仓库就是集中存放镜像文件的场所,一个仓库可以包含同一软件不同版本的镜像,而标签tag就对应不同版本,例如:[仓库名] : [版本标签], ubuntu:16.04和ubuntu:18.04就是个很好的例子。总的来说:仓库注册服务器上往往存放多个仓库,每个仓库又包含多个镜像,每个镜像有不同的标签。 需要注意的是,如果我们使用官方Docker Hub的需要翻墙,但像阿里云就提供了一些基础镜像(存放在阿里的服务器上),因此阿里云提供镜像的仓库也可以叫做是加速器,方便我们从国内下载合适的镜像。
*以上部分内容摘自:《Docker - 从入门到实践》
二、 阿里镜像服务使用流程
阿里虽然官方提供了一个简单的入门介绍 [1],但是有些简略,这里我完整地分享下我参加天池比赛提交镜像的使用流程。
1. 开通镜像服务
首先我们要建立个私有仓库去存放我们的构建的镜像文件。打开阿里云容器镜像服务,在网页右上角进入控制台,登录后可免费开通镜像托管,根据需求选择仓库地址,设置私有仓库,之后将代码源设为本地仓库,灵活度大。
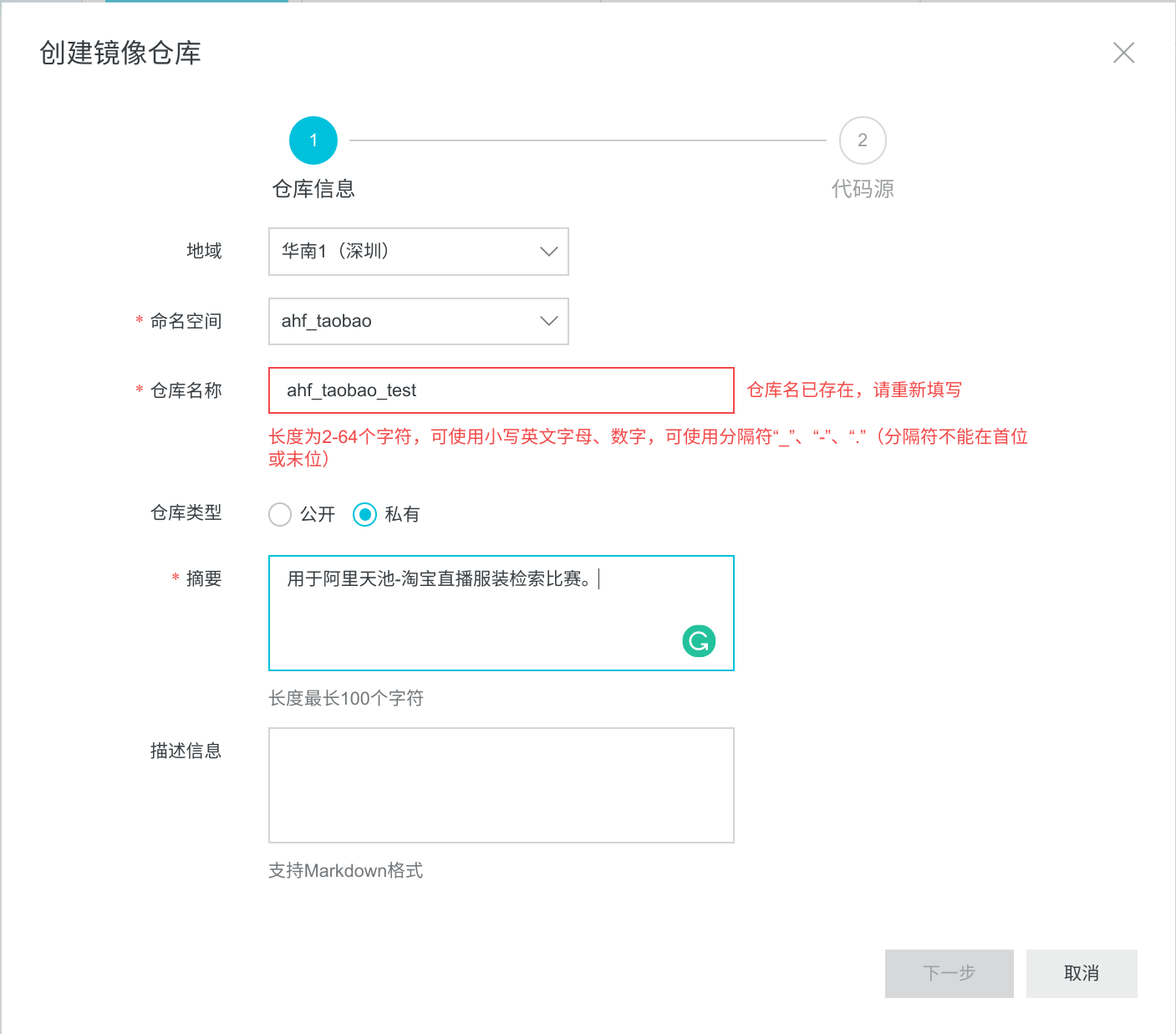
创建好仓库后,一定要设置固定密码(在左侧菜单栏:默认实例 - 访问凭证 - 设置固定密码),用于拉取或上传镜像的凭证信息(避免其他人窃取你仓库的镜像)。

2. 构建镜像
现在仓库有了,我们需要构建符合我们项目代码运行环境的镜像了。
有两种构建镜像的方式,如下:
- 使用 docker pull 从仓库拉取我们需要的基础镜像到本地,再在本地上使用该镜像启动容器( docker run ),进入到容器后便可安装其他额外的依赖项或放入相关文件,最后使用 docker commit 提交更新后的镜像即可。
- 利用Dockerfile来创建镜像,其包含如何创建和修改基础镜像的指令。
个人比较偏好第二种,虽然第一种构建方式,对个人来说挺方便的,但构建完就容易忘记之前修改镜像的整个过程。而第二种方法适合在团队中有,有利于团队中互相了解镜像搭建过程,而且回头修改之前构建镜像过程也比较方便。我下面也讲下如何使用第Dockerfile来创建镜像。
首先,创建并进入到一个目录,假设这里是/taobao/,那么该目录下要有以下三类文件:
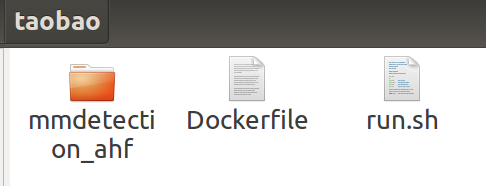
- Dockerfile:Docker镜像配置文件,内含构建镜像的各自指令。
- 项目代码文件:存放了项目代码,我这里就是上图的mmdetection_ahf,其用于目标检测任务。
- run.sh:运行代码的脚本文件。简单来说就是Linux Terminal下的要执行的命令集。
上面的解释可能会有点难理解,通过了解下面举的例子就能很好地明白上面三类文件的角色是什么了。首先我们看下Dockerfile的具体内容:
# 拉取阿里云公开的镜像,内含mmdetection文件
FROM registry.cn-shanghai.aliyuncs.com/tcc-public/mmdetection:pytorch1.3-cuda10.1-py3 # 加入本地文件
ADD . / # 到mmdetection下
WORKDIR /mmdetection_ahf # 编译mmdetection
ENV FORCE_CUDA="1"
RUN pip install --no-cache-dir -e . # 回到根目录
WORKDIR / # 运行sh
CMD ["sh", "run.sh"]
上面这个例子是我要拉取阿里提供mmdetection的基础镜像(具体请见:阿里基础镜像地址集)。然后加入本地文件是指我把taobao/下的三类文件加入到镜像里了,之后进入到mmdetection_ahf目录下进行编译,之后回到根目录运行run.sh脚本文件。(注意:我的阿里提供的mmdetection镜像内的根目录下已经含有mmdetection的代码,我这里的mmdetection_ahf是从它这个镜像里复制到本地,然后修改的。关于怎么将镜像中的文件复制到本地的方法,我将放到 "3. 其他" 这块进行讲解)。
run.sh如果不明白,看下我下面的例子就意会了,就是你要线上怎么去运行代码得到最终的结果:
# UTF-8, 确保python的默认编码为utf-8
export PYTHONIOENCODING=utf-8 # 回到根目录
cd / # 1. 为目标检测模型准备测试数据
python mmdetection_ahf/data/test_data_prepare.py # 2. 目标检测模型模型预测结果
cd mmdetection_ahf
./tools/dist_test.sh configs/baseline_config.py mmdet/models/pretrained_models/epoch_100.pth 1 --json_out ./work_dirs/result.json
最后正式开始构建此镜像:
# 一个仓库包含一个工程不同版本的镜像,例如ubuntu:16.04和ubuntu:18.04
sudo nvidia-docker build -t registry.cn-shenzhen.aliyuncs.com/[命名空间]/[仓库名称]:[版本号]
3. 检查镜像(可选)
检查镜像该环节是可选的,它主要目的是在线下确认你的之前构建的镜像是否成功?是否能正常走完整个代码项目的流程?
首先,先查看镜像:
sudo docker images # 查看CPU镜像
sudo nvidia-docker images # 查看GPU镜像
如果镜像存在,则说明镜像构建成功了一半,那么接下来看看镜像能不能成功运行run.sh的所有命令:
# 构建完成后可先验证是否正常运行,正常运行后再进行推送。
# 需要注意的事,如果你本地工程代码里需要用到云服务器的数据例如tcdata/时,你直接验证该代码可能会报错,
# 因为你没有云服务器上的数据,所以你可以先在本地搞一个类似目录结构的demo_data数据文件,使用``-v /demo_data:/tcdata``去将本地目录挂载到容器上,
# 简单来说就是将本地数据demo_data文件,改成别名tcdata,挂载你之前构建的镜像上的容器上面。
# 这样就能实现线下测试,如果测试没有报错,就能放心推送镜像到云上。
# --shm-size 50G 是为了防止运行过程中尝试的中间文件过大,导致现有容器装不下
sudo nvidia-docker run --shm-size 50G -v /demo_data:/tcdata registry.cn-shenzhen.aliyuncs.com/[命名空间]/[仓库名称]:[版本号] sh run.sh
(注意:docker和nvidia-docker区别在于后者可以使用GPU。它们的安装请参考:docker和nvidia-docker安装教程。)
4. 推送镜像
如果上面线下的镜像检查环节没问题,就可以把镜像推送到我们之前建的阿里云私有仓库里去了。
sudo nvidia-docker push registry.cn-shenzhen.aliyuncs.com/[命名空间]/[仓库名称]:[版本号]
完成!可以到比赛页面提交结果了!
三、其他
我们前两个部分只是讲了一些docker大概是怎么使用的,那么在这部分里,我整理了我在docker使用过程中,对我有帮助的一些操作命令。
1. 怎么创建空白的Dockerfile?
touch Dockerfile # 建立一个Dockerfile空配置文件
2. 怎么查看镜像和容器?
sudo docker images # 查看镜像
sudo docker ps -a # 查看容器
3. 怎么删除指定/所有的镜像和容器?
sudo docker rmi [image id] # 删除指定镜像
sudo docker rmi $(sudo docker images -q -f "dangling=true") # 删除无用镜像,即image id为<none>的镜像
sudo docker rmi $(sudo docker images) # 删除所有镜像 sudo docker stop [container id] # 暂停指定容器才能实现删除操作
sudo docker rm [container id] # 删除指定容器
sudo docker rm $(sudo docker ps -a -q) # 删除所有容器
4. 怎么创建,进入和退出容器?
# 在指定镜像上创建容器,并进入容器交互界面,--shm-size指定容器大小
sudo nvidia-docker run --shm-size 80G -t -i [image id] /bin/bash # 在容器交互界面内退出容器
exit # 进入指定容器(在sudo docker ps -a下确保该指定容器已开启)
sudo nvidia-docker exec -it [container id] /bin/bash # 开启容器
sudo docker start [container id] # 退出容器
sudo docker stop [container id] # 注意如果要删除某个挂有容器的镜像,一定要先确认该容器已退出并被删除才能删除镜像。
5. 怎么在镜像和本地之间进行上传或复制操作?
# 本地上传文件到容器上
sudo docker cp [本地路径] [container id]:[容器中路径] # 从容器复制文件到本地
sudo docker cp [container id]:[容器中路径] [本地路径]
[Docker镜像] 关于阿里云容器镜像服务的使用(以天池比赛提交镜像为例)的更多相关文章
- 容器监控—阿里云&容器内部服务监控
目前Docker的使用越来越离不开对容器的监控,阿里云最近上线了容器服务,不但提供了核心的容器和宿主机监控能力,而且支持集成 Cloud Insight 监控,下面会介绍如何集成. 首先介绍一下阿里云 ...
- Docker系列(26)- 发布镜像到阿里云容器服务
1.登录阿里云 2.找到容器镜像服务 3.创建命名空间 4.创建镜像仓库 5.上传镜像
- 在阿里云容器服务上开发基于Docker的Spring Cloud微服务应用
本文为阿里云容器服务Spring Cloud应用开发系列文章的第一篇. 一.在阿里云容器服务上开发Spring Cloud微服务应用(本文) 二.部署Spring Cloud应用示例 三.服务发现 四 ...
- .Net Core in Docker - 使用阿里云Codepipeline及阿里云容器镜像服务实现持续集成(CI)
前面已经介绍过了 .Net Core 程序发布到 Docker 容器的内容.但是每次通过 SSH 链接到服务器敲命令,运行脚本也是挺麻烦的一件事.程序员是最懒的,能让电脑解决的问题绝不手动解决,如果当 ...
- 品尝阿里云容器服务:用nginx镜像创建容器,体验基于域名的路由机制
在前一篇博文中我们了解了阿里云容器服务的路由机制: 请求 -> 负载均衡80端口 -> 容器主机9080端口 -> acsrouting路由容器80端口 --基于域名--> W ...
- 基于阿里云容器服务用docker容器运行ASP.NET 5示例程序
小试阿里云容器服务 之后,接下来有一个挡不住的小试冲动--用docker容器运行程序.首先想到的程序是 ASP.NET 5示例程序,于是参考msdn博客中的这篇博文 Running ASP.NET 5 ...
- 品尝阿里云容器服务:初步尝试ASP.NET Core Web API站点的Docker自动化部署
部署场景是这样的,我们基于 ASP.NET Core 2.0 Preview 1 开发了一个用于管理缓存的 Web API ,想通过阿里云容器服务基于 Docker 部署为内网服务. 在这篇博文中分享 ...
- 阿里云容器服务与ASP.NET Core部署:用 docker secrets 保存 appsettings.Production.json
这是我们使用阿里云容器服务基于 docker 容器部署 asp.net core 应用遇到的另一个问题 —— 如果将包含敏感信息的应用配置文件 appsettings.Production.json ...
- 上传Docker镜像到阿里云
1.配置阿里云的镜像加速器:https://cr.console.aliyun.com/#/accelerator 2.命令行登录到阿里云的doker仓库,--username为阿里云的用户名 d ...
随机推荐
- java -inally转
1.不管有木有出现异常,finally块中代码都会执行: 2.当try和catch中有return时,finally仍然会执行:3.finally是在return后面的表达式运算后执行的(此时并没有返 ...
- 游戏2048的核心算法c#版本的实现
接触游戏有一段时间了,也写了一些东西,效果还不错,今天没事,我就把2048 c# 版本的实现贴出来,代码已经测试过,可以正常.完美运行.当然了,在网上有很多有关2048的实现方法,但是没有提出到类里面 ...
- MeteoInfoLab脚本示例:合并数组
对于全球数据来说,经度要么是-180 - 180,要么是0 - 360,都会存在边界数据不连续的问题.比如0 - 360的数据,怎么得到 -20 - 30度的连续格点数据就是个问题(跨越了数据的经度边 ...
- react中 受控组件和 非受控组件 浅析
一 受控组件 顾名思义,受控 也就是能够被控制,简而言之也就是 该组件ui的显示或者内部state逻辑的变化依赖外部的 props的传入. 二 非受控组件 顾名思义,非受控,也就是内部的视图变化,st ...
- 数据库SQL Server 2016“功能选择”详细说明及精简安装选择
前言 在平时大家安装数据库的时候,一般默认功能选择都会选择全选.但是前两天公司同事问我:"那么多功能为什么都能用到嘛?"顿时,我思考了一下确实没有详细了解每个功能的详细作用,于是花 ...
- Linux ALSA音频库(二) 环境测试+音频合成+语音切换 项目代码分享
1. 环境测试 alsa_test.c #include <alsa/asoundlib.h> #include <stdio.h> // 官方测试代码, 运行后只要有一堆信息 ...
- doment ready事件和load事件的区别及实现
从2017年9月至今工作中大部分使用react,前端渲染的一些基础性知识记忆不是很深刻了.面试**公司的时候,碰到"document ready和load的区别,以及document rea ...
- C# 微支付 JSAPI支付方式 V3.3.6版本
<script type="text/javascript">//结算 (订单号) function PayClearing(num) { $.ajax({ type: ...
- 一文秒懂!Python字符串格式化之format方法详解
format是字符串内嵌的一个方法,用于格式化字符串.以大括号{}来标明被替换的字符串,一定程度上与%目的一致.但在某些方面更加的方便 1.基本用法 1.按照{}的顺序依次匹配括号中的值 s = &q ...
- ssm整合之springmvc.xml文件
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...