微信支付万亿日志在Hermes中的实践
导语 | 微信支付日志系统利用 Hermes 来实现日志的全文检索功能,自从接入以来,日志量持续增长。目前单日入库日志量已经突破万亿级,单集群日入库规模也已经突破了万亿,存储规模达 PB 级。本文将介绍微信支付日志系统在 Hermes 上的实践,希望与大家一同交流。文章作者:宋新村,腾讯大数据高级运维工程师。
一、业务规模
目前微信支付日志单日最大入库总量已达到万亿级,单日入库存储量达 PB 级,而在春节等重大节假日预计整个日入库规模会有进一步的增长。
微信支付日志业务采用的 Hermes 集群,单集群日入库规模也已经突破了万亿级每天,节点部署有二百多台,单集群存储总量达到 PB 级。另外,每天的检索查询并发在 6000 左右:
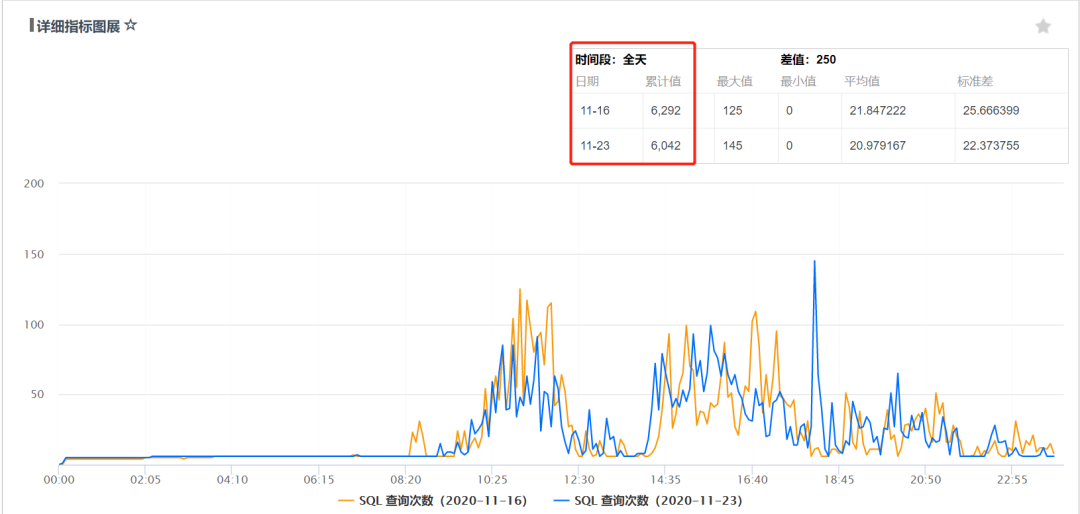
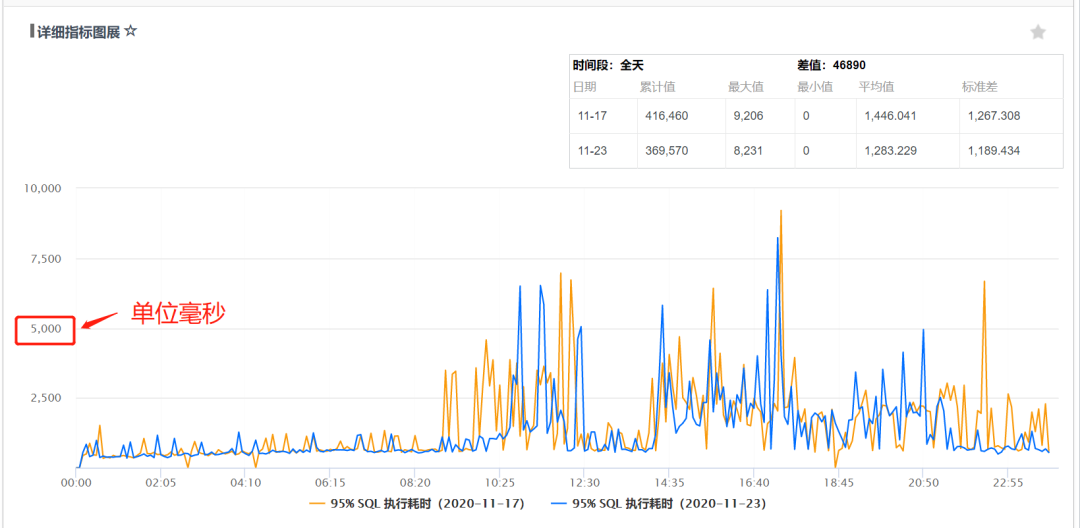
在如此海量日志存储规模下,整个微信支付日志查询 SLA 达到了 4 个 9,95% 的耗时小于 5s。
二、存算分离
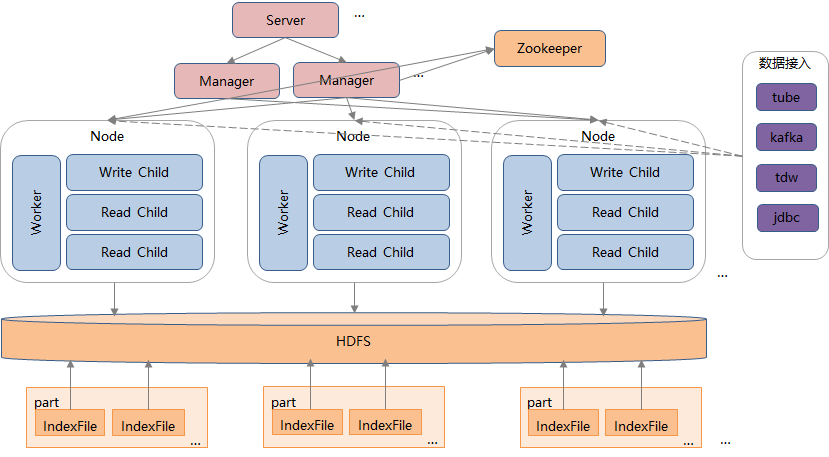
Hermes 底层存储采用 HDFS 来实现,所有的存储相关的策略都由专业的 HDFS 的能力来提供,包括:
1. 数据多副本容灾
日志默认存储 2 副本容灾,针对历史数据可以灵活的降低副本来减少存储成本,而针对非常重要的日志数据也可以灵活的增加副本来提高数据容灾能力。
2. 磁盘故障容错
单磁盘或单机故障 HDFS 可自动迁移副本,整个容错过程对上层计算层透明。
3. 冷热分级
利用 HDFS 提供的异构存储能力,结合 Hermes 本身的按天分区存储,可以非常方便的实现数据的冷热分级。冷热分级后的数据对上层业务透明,业务无需关注数据本身的存储情况
4. EC编码
HDFS 3.0 版本之后支持 EC 编码,进一步降低存储成本,目前暂时未在线上实践。
通过采用这种存算分离的架构,一方面可以简化上层的计算层的设计;另一方面计算层计算索引的时候只需计算单份即可实现多副本容灾,从而极大的减少计算层的 CPU、内存资源消耗,使得写入 QPS 成倍提升。
三、异步索引合并
Hermes 本身采用类 LSM 的数据写入模式,数据先写入内存+WAL,积累到一定数量后再批量刷写到 HDFS 进行持久化存储。节点故障时,系统通过回滚 WAL 进行数据恢复,从而确保整个写入为高效的顺序写入。
这种高效的写入方式带来的一个问题就是:随着数据的不断刷写,会产生大量的小的索引,从而对查询和 HDFS 存储造成较大的压力。
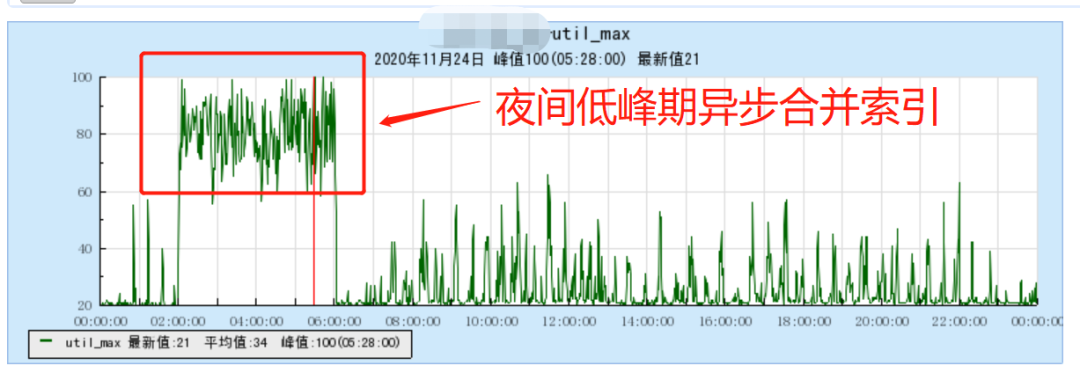
Hermes 本身会不断的对小的索引进行合并,降低索引文件的个数;而在夜间低峰期,我们也会对历史的分区数据进行一次较大的合并粒度,从而尽可能的提高整个系统的查询效率。微信支付业务的合并时间点选取的是凌晨 2~6 点,避开了凌晨 0~1 点的除夕红包高峰。
四、索引与数据分离
日志等业务场景的一个重要的特点就是:先按照分词+字段信息进行检索,然后拉取完整的一整行日志进行分析。
针对这种场景,传统的列存往往存在行存信息获取效率较低,而索引和数据混存又会存在合并索引时读写 IO 放大严重的问题。
为此,Hermes 除了会对日志进行分词构建索引之外,还可以额外配置存储一份完整的日志行存信息:
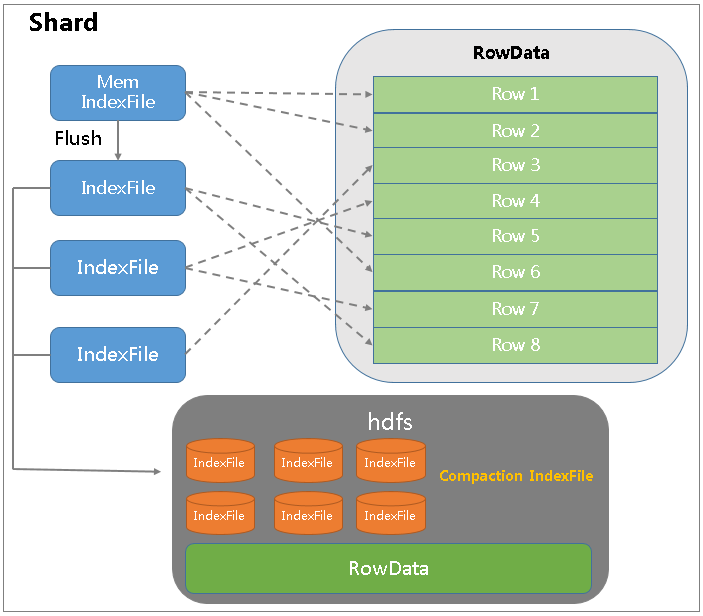
如上图所示,通过将索引和数据分离存储,索引目录里只存储倒排索引,行数据里同一个分片里每个索引目录相应的行数据。通过每个索引目录的 Offset 和 RowId,在 RowData 中读取结果数据。
通过索引和数据的分离,索引目录刷盘次数和个数降低 68%,内存使用量降低 70%,磁盘使用量降低 14%,检索性能提升 80%。

五、存储冷热分级
微信支付 90% 的日志模块都是数据量非常小的长尾模块。因此适当的引入一些高性能的 SSD 设备来加速这些存储较小的业务的查询是非常合适的,而为了可以尽可能的减少 SSD 的成本,需要对业务的数据进行冷热分级。
Hermes 本身的数据冷热分级是利用 HDFS 的异构存储能力来实现的,通过配置不同的副本放置策略,可以灵活的指定副本使用的存储类型,而整个过程对上层业务透明。
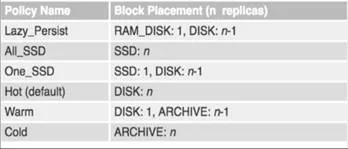
HDFS 异构存储策略如下所示:
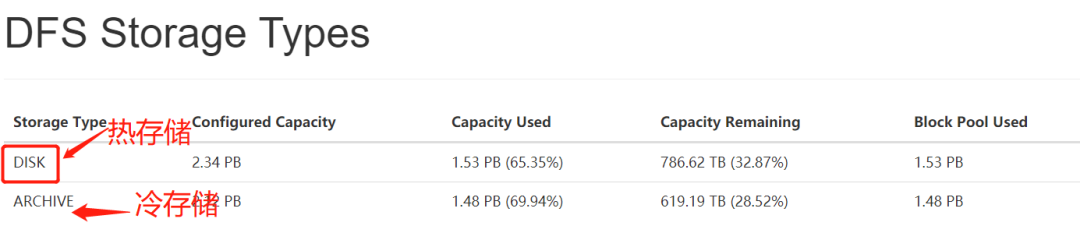
HDFS 异构存储在 Hermes 中的实践:
六、历史分区副本降级
Hermes 底层存储采用 HDFS 多副本来进行数据容灾,一般默认会存储两副本。目前微信支付的日志最长的保存周期为 30 天,存储数据量非常大。
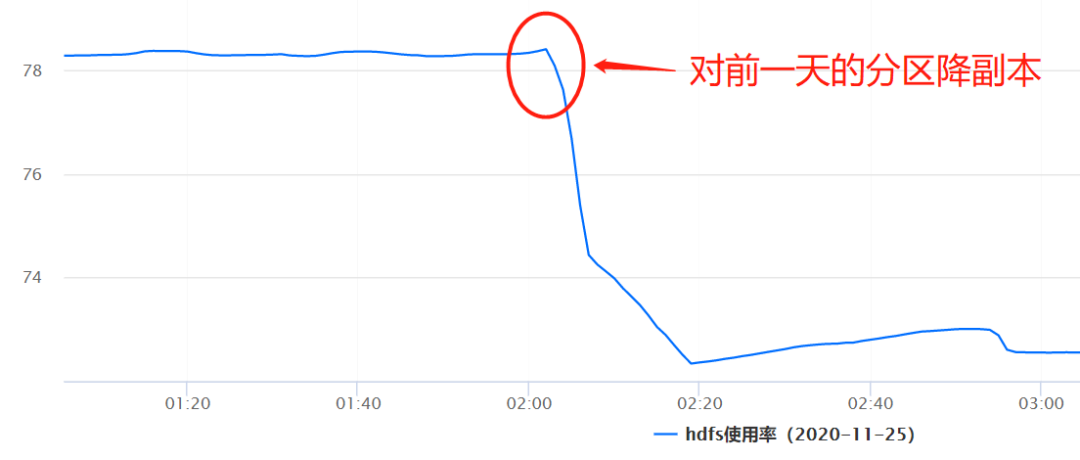
为了尽可能的降低业务的存储成本,在同业务协商沟通之后,了解到一般三天之前的日志的查询需求很低,对于日志的稳定性可以降低一些,因此 Hermes 运维侧直接对三天前的数据进行例行降副本操作,从而使得整个存储的成本直接降低 70% 以上,整个降副本操作对上层计算层和业务层都是透明的,业务对此没有任何感知。
七、日志批量导出
微信支付的同事经常会有批量导出指定时间段的命中某些关键词的日志的需求:
为此 Hermes 提供批量异步导出日志到 HDFS 等存储介质的功能,用户提交导出请求后,系统会把所有命中的日志导出一份到 TDW HDFS 上面,用户再用 TDW HDFS 客户端或者通过 Hermes 的接口机拖走就行。
TDW HDFS 上面用户的日志导出文件:

八、结语
微信支付接入 Hermes 以来,日志量规模从最初的百亿规模增长至现在的万亿级规模,对整个 Hermes 本身的存储能力、扩展能力、容灾能力和资源规划能力都持续提出挑战。
好在 Hermes 本身优秀的存储架构使得可以在海量业务数据规模下灵活的对业务的数据进行翻转腾挪,从而从容的应对业务持续提出的各种挑战。
微信支付万亿日志在Hermes中的实践的更多相关文章
- 万亿级KV存储架构与实践
一.KV 存储发展历程 我们第一代的分布式 KV 存储如下图左侧的架构所示,相信很多公司都经历过这个阶段.在客户端内做一致性哈希,在后端部署很多的 Memcached 实例,这样就实现了最基本的 KV ...
- iOS开发支付集成之微信支付
这一篇是<iOS开发之支付>这一部分的继支付宝支付集成,银联支付集成第三篇,微信支付.在集成的时候建议都要去下载最新版的SDK,因为我知道的前不久支付宝,银联都更新了一次,微信的不太清楚更 ...
- 小程序微信支付(UNIAPP+第三方SDK:binarywang)
小程序支付流程图说明(UNIAPP+第三方SDK:binarywang) 说明:小程序为UNI-APP开发,使用的第三方微信支付SDK为binarywang提供的,此SDK对微信公众号.小程序.微信各 ...
- 日调度万亿次,微服务框架TSF大规模应用——云+未来峰会开发者专场回顾
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 演讲者:张浩 腾讯云中间件产品负责人 背景:众多开发者中,一定经历类似的甜蜜烦恼,就是当线上业务规模越来越大,系统分支发展越来越多的时候,初 ...
- 微信支付之h5方式(非微信内置浏览器中支付)
这两天完成了公司网站手机和PC端的支付对接,就是支付宝和微信. 对接完后有所感触,我们来聊一聊,微信支付的坑,为什么这么说呢,因为我在对接完支付宝后是很愉快的,基本上在demo上稍加修改就ok了, 对 ...
- 日吞吐万亿,腾讯云时序数据库CTSDB解密
一.背景 随着移动互联网.物联网.大数据等行业的高速发展,数据在持续的以指数级的速度增长,比如我们使用手机访问互网络时的行为数据,各种可穿戴设备上报的状态数据,工厂中设备传感器采集的指标数据,传统互联 ...
- 微信公众号中的支付宝支付与微信支付 && 支付宝支付问题(微信bug)
一般,在微信公众号中的商城都是需要支持微信支付和支付宝支付的,当然,较大的公司对于鹅厂和阿里的站队就不说了,所以这里简单记录一下支付宝支付和微信支付的主要流程.说是简单介绍,这是因为确实不难,因为前端 ...
- 微信支付中分账功能 填坑指南V1
公司是做电商的,近期开发了一款小程序,准备线上线下同步销售玩具.这里就涉及到微信支付的功能,网上有很多教程,官方也有文档和Demo,因此微信支付还是比较容易实现的. 由于我们公司是和其他公司合作运营的 ...
- C#在Linux+Mono环境中使用微信支付证书
最近特殊的需求,要把微信平台一个功能页面部署到Linux(CentOS6.5)下,其中涉及到微信支付退款. 鉴于之前实践过mono+jexus+asp.net mvc的部署,于是问题重点在于解决对商户 ...
随机推荐
- 错误解析:org.apache.catalina.LifecycleException: Protocol handler start failed
以下是报错代码: org.apache.catalina.LifecycleException: Protocol handler start failed at org.apache.catalin ...
- 基于虚拟机安装Linux并利用LVM创建磁盘分区
主要步骤:将磁盘设置为LVM类型,并在这四个分区上创建物理卷.卷组和逻辑卷,最后将逻辑卷挂载.电脑使用Windows10 企业版 LTSC 操作系统.虚拟机使用VMware15.5 pro . 1.安 ...
- C# 集合类(一)动态数组ArrayList
C# 集合类自己经常用到: 数组(Array).动态数组(ArrayList).列表(List).哈希表(Hashtable).字典(Dictionary),对于经常使用的这些数据结构,做一个总结,便 ...
- ansible快速部署cassandra3集群
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Python_科学计算平台__pypi体系的numpy、scipy、pandas、matplotlib库简介
1.numpy--基础,以矩阵为基础的数学计算模块,纯数学 存储和处理大型矩阵. 这个是很基础的扩展,其余的扩展都是以此为基础. 快速学习入口 https://docs.scipy.org/doc/n ...
- Nacos配置中心源码分析
1.使用 compile 'com.alibaba.cloud:spring-cloud-starter-alibaba-nacos-config:2.2.3.RELEASE' spring: app ...
- Netty源码解析 -- 内存对齐类SizeClasses
在学习Netty内存池之前,我们先了解一下Netty的内存对齐类SizeClasses,它为Netty内存池中的内存块提供大小对齐,索引计算等服务方法. 源码分析基于Netty 4.1.52 Nett ...
- 通过一道CTF学习HTTP协议请求走私
HTTP请求走私 HTTP请求走私 HTTP请求走私是针对于服务端处理一个或者多个接收http请求序列的方式,进行绕过安全机制,实施未授权访问一种攻击手段,获取敏感信息,并直接危害其他用户. 请求走私 ...
- php(tp5) 生成二维码
phpqrcode类库官网下载地址:https://sourceforge.net/projects/phpqrcode/ 1.我们先看看php是怎么生成二维码的 1.首先我们先下载一下 phpqr ...
- 面试官:小伙子,你给我讲一下java类加载机制和内存模型吧
类加载机制 虚拟机把描述类的数据从 Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的java类型,这就是虚拟机的类加载机制. 类的生命周期 加载(Loadi ...