Python并发编程05 /死锁现象、递归锁、信号量、GIL锁、计算密集型/IO密集型效率验证、进程池/线程池
Python并发编程05 /死锁现象、递归锁、信号量、GIL锁、计算密集型/IO密集型效率验证、进程池/线程池
1. 死锁现象
死锁:
是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。死锁现象:
①连续锁多次,②锁嵌套引起的死锁现象代码示例:
from threading import Thread
from threading import Lock
import time lock_A = Lock()
lock_B = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2() def f1(self):
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_B.acquire()
print(f'{self.name}拿到了B锁')
lock_B.release()
lock_A.release() def f2(self):
lock_B.acquire()
print(f'{self.name}拿到了B锁')
time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_A.release()
lock_B.release() if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()

2. 递归锁
递归锁
作用:递归锁可以解决死锁现象,业务需要多个锁时,先要考虑递归锁
工作原理:递归锁有一个计数的功能, 原数字为0,上一次锁,计数+1,释放一次锁,计数-1,
只要递归锁上面的数字不为零,其他线程就不能抢锁.代码示例
使用方式一:
from threading import Thread
from threading import RLock
import time lock_A = lock_B = RLock()
class MyThread(Thread): def run(self):
self.f1()
self.f2() def f1(self):
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_B.acquire()
print(f'{self.name}拿到了B锁')
lock_B.release()
lock_A.release() def f2(self):
lock_B.acquire()
print(f'{self.name}拿到了B锁')
time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_A.release()
lock_B.release() if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
使用方式二:利用上下文管理
from threading import RLock def task():
with RLock:
print(111)
print(222) # 执行完with内的语句会释放锁
3. 信号量
可以并发的数量,本质上也是一种锁,可以设置同一时刻抢锁线程的数量
代码示例
from threading import Thread, Semaphore, current_thread
import time
import random
sem = Semaphore(5) def task():
sem.acquire()
print(f'{current_thread().name} 吃饭中...')
time.sleep(random.randint(1,3))
sem.release() if __name__ == '__main__':
for i in range(20):
t = Thread(target=task,)
t.start()
4. GIL全局解释器锁
1. 背景
理论上来说:单个进程的多线程可以利用多核.
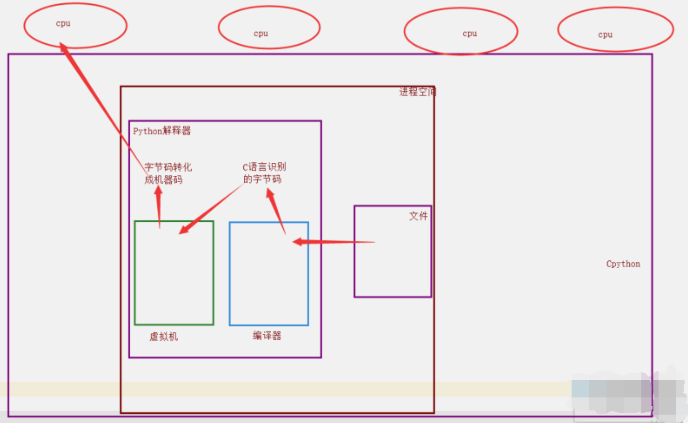
但是,开发Cpython解释器的程序员,给进入解释器的线程加了锁.
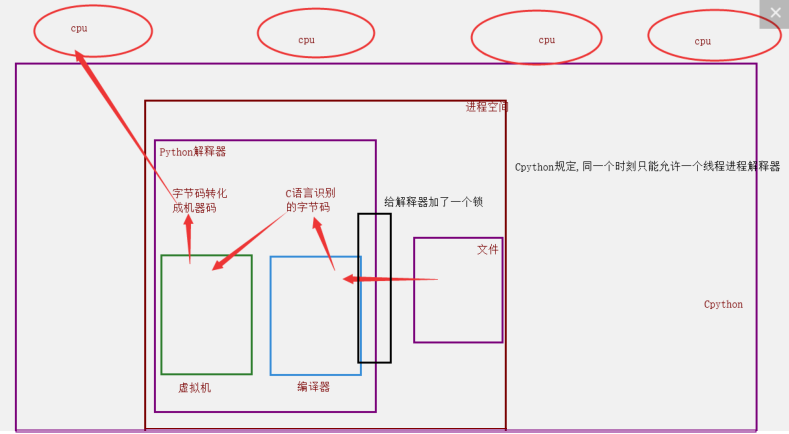
2. 加锁的原因:
当时都是单核时代,而且cpu价格非常贵.
如果不加全局解释器锁, 开发Cpython解释器的程序员就会在源码内部各种主动加锁,解锁,非常麻烦,各种死锁现象等等.为了省事儿,直接进入解释器时给线程加一个锁.
优缺点:
优点: 保证了Cpython解释器的数据资源的安全.
缺点: 单个进程的多线程不能利用多核.Jpython没有GIL锁,pypy也没有GIL锁
现在多核时代, 我将Cpython的GIL锁去掉行么?
因为Cpython解释器所有的业务逻辑都是围绕着单个线程实现的,去掉这个GIL锁,几乎不可能.
单个进程的多线程可以并发,但是不能利用多核,不能并行,多个进程可以并发,并行.
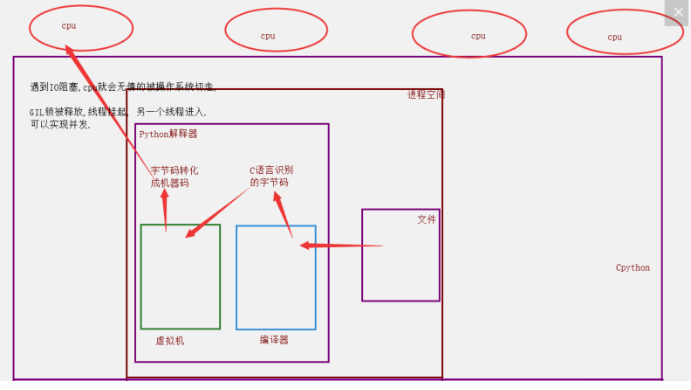
3. GIL与Lock锁的区别
- 相同点: 都是同种锁,互斥锁.
- 不同点:
GIL锁全局解释器锁,保护解释器内部的资源数据的安全.
GIL锁 上锁,释放无需手动操作.
自己代码中定义的互斥锁保护进程线程中的资源数据的安全.
自己定义的互斥锁必须自己手动上锁,释放锁.
4. 为什么GIL保证不了自己数据的安全?
一个线程去修改一个数据的时候,由于网络延迟或者其它原因,被另一个线程抢到GIL锁,拿到这个数据,此时就造成了该数据的不安全。

5. 验证计算密集型、IO密集型的效率
IO密集型:单个进程的多线程并发 vs 多个进程的并发并行
def task():
count = 0
time.sleep(random.randint(1,3))
count += 1 if __name__ == '__main__':
# 多进程的并发,并行
start_time = time.time()
l1 = []
for i in range(50):
p = Process(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time()- start_time}') # 8.000000000 # 多线程的并发
start_time = time.time()
l1 = []
for i in range(50):
p = Thread(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time()- start_time}') # 3.0294392108917236 # 结论:对于IO密集型: 单个进程的多线程的并发效率高.
计算密集型:单个进程的多线程并发 vs 多个进程的并发并行
from threading import Thread
from multiprocessing import Process
import time
import random def task():
count = 0
for i in range(10000000):
count += 1 if __name__ == '__main__':
# 多进程的并发,并行
start_time = time.time()
l1 = []
for i in range(4):
p = Process(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time()- start_time}') # 3.1402080059051514 # 多线程的并发
start_time = time.time()
l1 = []
for i in range(4):
p = Thread(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time()- start_time}') # 4.5913777351379395 # 结论:对于计算密集型: 多进程的并发并行效率高.
6. 多线程实现socket通信
无论是多线程还是多进程,都是一样的写法,来一个客户端请求,我就开一个线程,来一个请求开一个线程,在计算机允许范围内,开启的线程进程数量越多越好.
服务端
import socket
from threading import Thread def communicate(conn,addr):
while 1:
try:
from_client_data = conn.recv(1024)
print(f'来自客户端{addr[1]}的消息: {from_client_data.decode("utf-8")}')
to_client_data = input('>>>').strip()
conn.send(to_client_data.encode('utf-8'))
except Exception:
break
conn.close() def _accept():
server = socket.socket()
server.bind(('127.0.0.1', 8848))
server.listen(5)
while 1:
conn, addr = server.accept()
t = Thread(target=communicate,args=(conn,addr))
t.start() if __name__ == '__main__':
_accept()
客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8848)) while 1:
try:
to_server_data = input('>>>').strip()
client.send(to_server_data.encode('utf-8'))
from_server_data = client.recv(1024)
print(f'来自服务端的消息: {from_server_data.decode("utf-8")}')
except Exception:
break
client.close()
7. 进程池,线程池
定义:进程池线程池就是:控制开启线程或者进程的数量
线程池: 一个容器,这个容器限制住开启线程的数量,比如4个,第一次肯定只能并发的处理4个任务,只要有任务完成,线程马上就会接下一个任务.
代码示例
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random def task(n):
print(f'{os.getpid()} 接客')
time.sleep(random.randint(1,3)) if __name__ == '__main__':
# 开启进程池
p = ProcessPoolExecutor() # 默认不写,进程池里面的进程数与cpu个数相等
for i in range(20):
p.submit(task,i) # 开启线程池
t = ThreadPoolExecutor(100) # 100个线程,不写默认是cpu个数*5 线程数
for i in range(20):
t.submit(task,i)
总结:
信号量与进程池、线程池的区别
1.使用Seamphore,你创建了多少线程,实际就会有多少线程进行执行,只是可同时执行的线程数量会受到限制。但使用线程池,你创建的线程只是作为任务提交给线程池执行,实际工作的线程由线程池创建,并且实际工作的线程数量由线程池自己管理。
2.简单来说,线程池实际工作的线程是work线程,不是你自己创建的,是由线程池创建的,并由线程池自动控制实际并发的work线程数量。而Seamphore相当于一个信号灯,作用是对线程做限流,Seamphore可以对你自己创建的的线程做限流(也可以对线程池的work线程做限流),Seamphore的限流必须通过手动acquire和release来实现。
Python并发编程05 /死锁现象、递归锁、信号量、GIL锁、计算密集型/IO密集型效率验证、进程池/线程池的更多相关文章
- python 并发编程 多线程 死锁现象与递归锁
一 死锁现象 所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等 ...
- 并发编程中死锁、递归锁、进程/线程池、协程TCP服务器并发等知识点
1.死锁 定义; 类似两个人分别被囚禁在两间房子里,A手上拿着的是B囚禁房间的钥匙,而B拿着A的钥匙,两个人都没法出去,没法给对方开锁,进而造成死锁现象.具体例子代码如下: # -*-coding:u ...
- python 并发编程 多线程 目录
线程理论 python 并发编程 多线程 开启线程的两种方式 python 并发编程 多线程与多进程的区别 python 并发编程 多线程 Thread对象的其他属性或方法 python 并发编程 多 ...
- Python并发编程03 /僵孤进程,孤儿进程、进程互斥锁,进程队列、进程之间的通信
Python并发编程03 /僵孤进程,孤儿进程.进程互斥锁,进程队列.进程之间的通信 目录 Python并发编程03 /僵孤进程,孤儿进程.进程互斥锁,进程队列.进程之间的通信 1. 僵尸进程/孤儿进 ...
- Python并发编程-GIL全局解释器锁
Python并发编程-GIL全局解释器锁 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.GIL全局解释器锁概述 CPython 在解释器进程级别有一把锁,叫做GIL,即全局解释 ...
- python 并发编程 多进程 互斥锁 目录
python 并发编程 多进程 互斥锁 模拟抢票 互斥锁与join区别
- Python并发编程04 /多线程、生产消费者模型、线程进程对比、线程的方法、线程join、守护线程、线程互斥锁
Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线程join.守护线程.线程互斥锁 目录 Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线 ...
- python并发编程之多线程
一 同步锁 注意: 1线程抢的是GIL锁,GIL锁就是执行权限,拿到权限后才能拿到互斥锁Lock,但是如果发现Lock没有被释放而阻塞,则立即交出拿到的执行权. 2join是等待所有,即整体串行,而 ...
- Python并发编程二(多线程、协程、IO模型)
1.python并发编程之多线程(理论) 1.1线程概念 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于 ...
随机推荐
- 检查*.ldf为何这么大
testdb,只是个测试用文件,备份时突然发现*.ldf怎么这么大,当硬盘不要花银子买啊......--可随意删除...,有空再检查,累了休息... 如批量生成数据.或导入那个来自MySQL的Empl ...
- selenium获取图片验证码
# encoding:utf-8 from PIL import Image from selenium import webdriver url = '网站地址' driver = webdrive ...
- Jmeter(十) - 从入门到精通 - JMeter逻辑控制器 - 中篇(详解教程)
1.简介 Jmeter官网对逻辑控制器的解释是:“Logic Controllers determine the order in which Samplers are processed.”. 意思 ...
- SpringBoot整合Hibernate Validator实现参数验证功能
在前后端分离的开发模式中,后端对前端传入的参数的校验成了必不可少的一个环节.但是在多参数的情况下,在controller层加上参数验证,会显得特别臃肿,并且会有许多的重复代码.这里可以引用Hibern ...
- 带你学够浪:Go语言基础系列 - 8分钟学复合类型
★ 文章每周持续更新,原创不易,「三连」让更多人看到是对我最大的肯定.可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇) " 对于一般的语言使用者来说 ,20% ...
- opencv视频教程分享
opencv视频教程分享-在线与网盘 https://pan.baidu.com/s/1oAcctlS 密码:i5rd 链接:https://pan.baidu.com/s/1kVJ3iSJ 密码: ...
- Java操作RockeMQ
RocketMQ是阿里巴巴在2012年开源的分布式消息中间件,目前已经捐赠给Apache基金会,已经于2016年11月成为 Apache 孵化项目,相信RocketMQ的未来会发挥着越来越大的作用,将 ...
- Spring中的AOP(一)
1. Spring AOP实现机制 Spring采用动态代理机制和字节码生成技术实现AOP.与最初的AspectJ采用编译器将横切逻辑织入目标对象不同,动态代理机制和字节码生成都是在运行期间为目标对象 ...
- Java wait 和 sleep 的区别
一.区别 sleep 来自 Thread 类,和 wait 来自 Object 类 sleep 方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或方法 wait,notify和 ...
- 【Model Log】模型评估指标可视化,自动画Loss、Accuracy曲线图工具,无需人工参与!
1. Model Log 介绍 Model Log 是一款基于 Python3 的轻量级机器学习(Machine Learning).深度学习(Deep Learning)模型训练评估指标可视化工具, ...