【LeetCode二叉树#01】二叉树的遍历(递归/迭代)
二叉树递归遍历
写递归算法时候需要遵循的三个点:
- 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
- 确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
- 确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
前序遍历
以前序遍历为例
LeetCode上的代码模板如下:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
}
};
因为要使用递归,所以肯定得有一个递归函数,那么现在按照上面的三个规则来写
1、确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处 理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode* cur, vector<int>& vec){
}
2.确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
void traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL) return;
}
3.确定单层递归的逻辑:前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
void traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL) return;
vec.push_back(cur->val);//取出当前节点的值(中)
traversal(cur->left, vec);//到左子树的节点中取值(左)
traversal(cur->right, vec);//到右子树的节点中取值(右)
}
因此,前序遍历的完整代码如下:
class Solution {
public:
//编写递归函数
void traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL)return;
vec.push_back(cur->val);//取出当前节点的值
traversal(cur->left, vec);//到左子树的节点中取值
traversal(cur->right, vec);//到右子树的节点中取值
}
vector<int> preorderTraversal(TreeNode* root) {
//定义结果数组
vector<int> res;
traversal(root, res);
return res;
}
};
中序遍历
同理,中序和后序遍历中只需修改递归函数traversal中的单层递归逻辑即可
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL)return;
traversal(cur->left, vec);//到左子树的节点中取值(左)
vec.push_back(cur->val);//取出当前节点的值(中)
traversal(cur->right,vec);//到右子树的节点中取值(右)
}
vector<int> inorderTraversal(TreeNode* root) {
//定义结果数组
vector<int> res;
traversal(root, res);
return res;
}
};
后序遍历
class Solution {
public:
//编写递归函数
void traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL) return;
traversal(cur->left, vec);
traversal(cur->right, vec);
vec.push_back(cur->val);
}
vector<int> postorderTraversal(TreeNode* root) {
vector<int> res;
traversal(root, res);
return res;
}
};
注意
前/中/后序遍历的顺序里,所谓的“中”(例如中左右)其实可以理解为在使用递归三部曲时的“确认单层逻辑”的过程
二叉树非递归遍历
面试时有可能会考察一些简单的递归逻辑的迭代法实现
例如,用迭代法来实现前中后序遍历
前序遍历(迭代法)
图示模拟
通过迭代法进行前序遍历主要是利用栈的方式实现的
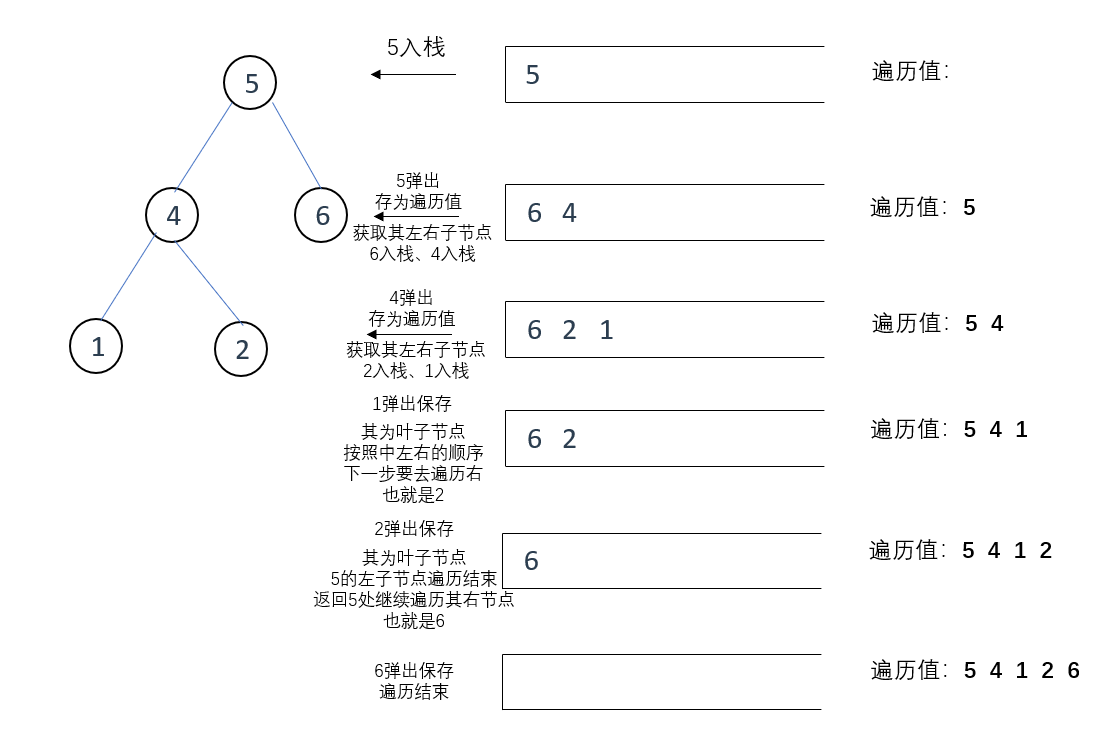
如图所示,将当前遍历到的节点存入栈中,保存其值到结果数组后将其弹出,然后根据该节点的左右指针,把该节点的左右子节点再放入栈中
注意:放入栈的顺序要与遍历顺序相反
例如:前序遍历的顺序是 中左右 ,当 5 入栈时实际上是在进行对于 中 的遍历,而 5 的左右子节点入栈时要以 “右左” 的顺序进入,这样在出栈时才能保证顺序为 “左右” ,才能达成 "中左右" 的遍历顺序
代码
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
//定义一个栈,注意保存的是节点数据类型
stack<TreeNode*> st;
//定义一个结果数组
vector<int> res;
//检测传入节点是否为空
if(root == NULL) return res;
//将根节点压栈
st.push(root); //中
//当栈中不为空时持续遍历
while(!(st.empty())){
//保存当前栈顶节点
TreeNode* node = st.top();
//弹出当前节点
st.pop();
//保存结果
res.push_back(node->val);
//判断当前节点有无左右子节点,有就按顺序压栈(明确你的出栈顺序,入栈时要相反)
if(node->right)st.push(node->right); //右
if(node->left)st.push(node->left); //左
}
return res;//最终遍历结果的顺序:中左右(前序)
}
};
后序遍历(迭代法)
因为中序遍历的迭代法不是简单的在前序的基础上修改顺序就可以实现的,所以先说后续遍历
在前序的基础上实现后序的方式很巧妙
后序遍历顺序:左右中
前序遍历顺序:中左右
因为要使用栈来实现迭代遍历,所以在实际代码中前序遍历的入栈顺序是:中右左
此时我们对其进行一个翻转处理,是不是就变成了左右中,即后序遍历的顺序
代码
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
//定义一个栈,注意保存的是节点数据类型
stack<TreeNode*> st;
//定义一个结果数组
vector<int> res;
//检测传入节点是否为空
if(root == NULL) return res;
//将根节点压栈
st.push(root); //中
//当栈中不为空时持续遍历
while(!(st.empty())){
//保存当前栈顶节点
TreeNode* node = st.top();
//弹出当前节点
st.pop();
//保存结果
res.push_back(node->val);
//判断当前节点有无左右子节点,有就按顺序压栈(明确你的出栈顺序,入栈时要相反)
if(node->left)st.push(node->left); //左
if(node->right)st.push(node->right); //右
//出栈顺序:中右左(与入栈相反)
}
//翻转数组
reverse(res.begin(), res.end());
return res;//最终遍历结果的顺序:左右中(后序)
}
};
中序遍历(迭代法)
通过前序和后序遍历的实现可以发现,这个过程其实可以分为遍历节点和处理节点两部分
并且在前序和后序遍历中,要遍历的节点与要处理的节点为同一顺序,因此可以按照上面的模式写出代码
但是,中序遍历的过程中,遍历和处理节点并不能够同时进行(顺序不一致),因此需要新的实现逻辑
中序遍历的动画如下:
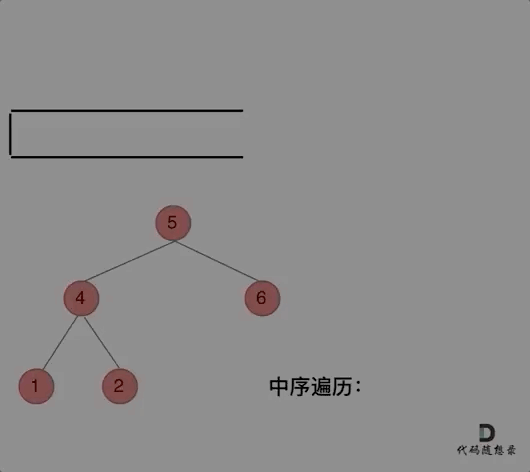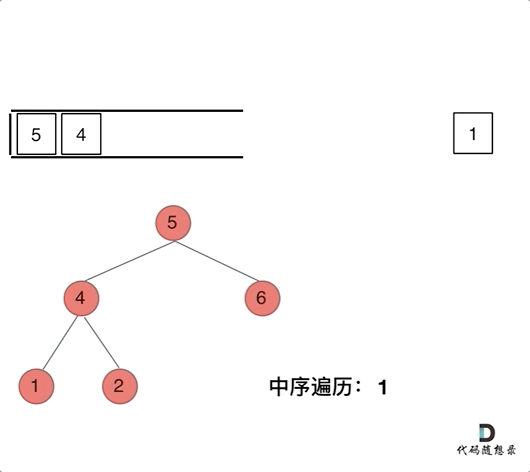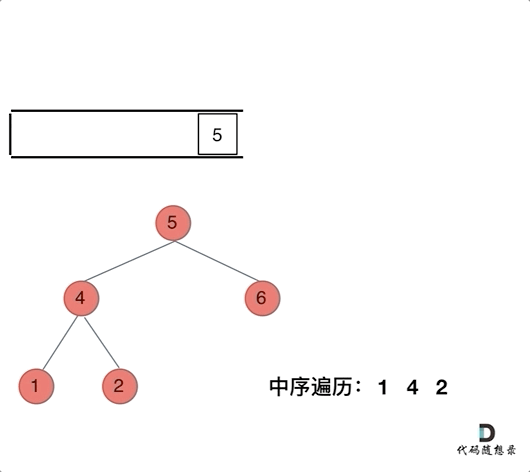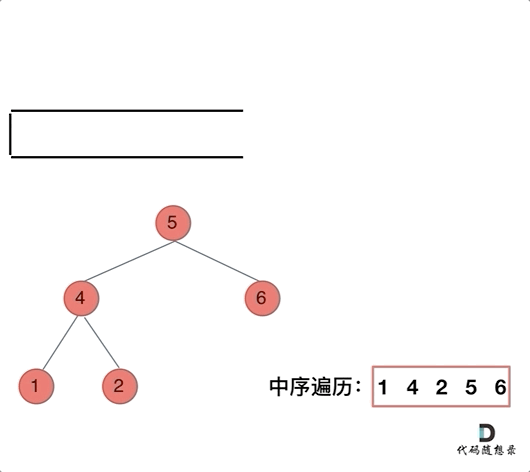
首先,中序遍历的顺序是 左中右
因此从头结点 5 开始,我们定义一个指针一直遍历该二叉树的左指针指向的节点(左子节点)并压栈,直到指针指向空
然后开始从栈顶取节点
此时取的肯定是叶子节点,但是我们仍要判断其是否有左右节点(显然是没有的,要不然上面的指针也不会指向空)
将该节点的值保存到结果数组中,重复上述操作
代码
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
//定义栈
stack<TreeNode*> st;
vector<int> res;
//将指针指向根节点
TreeNode* cur = root;
//遍历
while(!(st.empty()) || cur ! = NULL){
//判断是否遍历到最底层
if(cur ! = NULL){
st.push(cur);//压栈
cur = cur->left;//继续向左遍历
}else{//当遍历到了左边的最底层,开始出栈(处理数据,即放进res)
cur = st.top();//让指针指向当前弹出的节点
st.pop();
res.push_back(cur->val);
//判断每个出栈的节点是否有左右子节点
cur = cur->right;//如果有,则又会触发if的第一个条件,继续将右子节点压栈
//不存在的话cur指向空就右来到else这
}
}
return res;
}
};
【LeetCode二叉树#01】二叉树的遍历(递归/迭代)的更多相关文章
- 二叉树的创建、遍历(递归和非递归实现)、交换左右子数、求高度(c++实现)
要求:以左右孩子表示法实现链式方式存储的二叉树(lson—rson),以菜单方式设计并完成功能任务:建立并存储树.输出前序遍历结果.输出中序遍历结果.输出后序遍历结果.交换左右子树.统计高度,其中对于 ...
- 【Warrior刷题笔记】剑指offer 32. 三道题,让你学会二叉树的深度广度优先遍历与递归迭代技术
题目一 剑指 Offer 32 - I. 从上到下打印二叉树 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/cong-shang-dao-xi ...
- 【LeetCode题解】94_二叉树的中序遍历
目录 [LeetCode题解]94_二叉树的中序遍历 描述 方法一:递归 Java 代码 Python代码 方法二:非递归 Java 代码 Python 代码 [LeetCode题解]94_二叉树的中 ...
- [LeetCode] 144. Binary Tree Preorder Traversal 二叉树的先序遍历
Given a binary tree, return the preorder traversal of its nodes' values. For example:Given binary tr ...
- [LeetCode] Binary Tree Inorder Traversal 二叉树的中序遍历
Given a binary tree, return the inorder traversal of its nodes' values. For example:Given binary tre ...
- LeetCode(94):二叉树的中序遍历
Medium! 题目描述: 给定一个二叉树,返回它的中序 遍历. 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,3,2] 进阶: 递归算法很简单,你可以通过迭代算法完成吗 ...
- LeetCode:二叉树的后序遍历【145】
LeetCode:二叉树的后序遍历[145] 题目描述 给定一个二叉树,返回它的 后序 遍历. 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [3,2,1] 进阶: 递归算法很 ...
- 数据结构(3) 第三天 栈的应用:就近匹配/中缀表达式转后缀表达式 、树/二叉树的概念、二叉树的递归与非递归遍历(DLR LDR LRD)、递归求叶子节点数目/二叉树高度/二叉树拷贝和释放
01 上节课回顾 受限的线性表 栈和队列的链式存储其实就是链表 但是不能任意操作 所以叫受限的线性表 02 栈的应用_就近匹配 案例1就近匹配: #include <stdio.h> in ...
- LeetCode 94:二叉树的中序遍历 Binary Tree Inorder Traversal
题目: 给定一个二叉树,返回它的中序 遍历. Given a binary tree, return the inorder traversal of its nodes' values. 示例: 输 ...
- LeetCode 94. 二叉树的中序遍历(Binary Tree Inorder Traversal)
94. 二叉树的中序遍历 94. Binary Tree Inorder Traversal 题目描述 给定一个二叉树,返回它的 中序 遍历. LeetCode94. Binary Tree Inor ...
随机推荐
- [转帖]配置logback上报日志到Skywalking
https://zhuanlan.zhihu.com/p/506119895 配置logback上报日志到Skywalking 配置logback上报日志到skywalking需要引入toolkit依 ...
- SPECCPU2006的学习与使用
SPECCPU2006的学习与使用 摘要 这个周末问题不是很多, 陪孩子写作业时顺便研究了下SPEC2006 虽然比较落后了. 但是总比没有要强一些. 其实集团有资源, 但是联系不到人, 只能自己学习 ...
- [转帖]15 个必须知道的 chrome 开发工具技巧
在Web开发者中,Google Chrome是使用最广泛的浏览器.六周一次的发布周期和一套强大的不断扩大开发功能,使其成为了web开发者必备的工具.你可能已经熟悉了它的部分功能,如使用console和 ...
- SP5464 CT - Counting triangles 题解
题目翻译 题意 有一个网格,左上角是 \((0,0)\),右上角是 \((x,y)\).求这个网格中一共有多少个等腰直角三角形. 输入 第一行给定一个 \(c\),表示有 \(c\) 组数据. 后面 ...
- 4.2 Inline Hook 挂钩技术
InlineHook 是一种计算机安全编程技术,其原理是在计算机程序执行期间进行拦截.修改.增强现有函数功能.它使用钩子函数(也可以称为回调函数)来截获程序执行的各种事件,并在事件发生前或后进行自定义 ...
- Hadoop3 No FileSystem for scheme "hdfs"
Hadoop3 No FileSystem for scheme "hdfs" 异常信息: org.apache.hadoop.fs.UnsupportedFileSystemEx ...
- elasticsearch源码debug
一.下载源代码 直接用idea下载代码https://github.com/elastic/elasticsearch.git 切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Deb ...
- Data Encryption Standard算法:历经考验的经典加密方案
在当今数字化时代,数据安全是一个至关重要的问题.为了保护敏感数据的机密性和完整性,加密算法成为了数据保护的关键技术.其中,DES(Data Encryption Standard)算法作为一种经典的对 ...
- <semaphore.h> 和 <sys/sem.h> 的区别
<sys/sem.h>为 XSI(最初是 Unix System V)信号量提供接口. 这些不是基本 POSIX 标准的一部分(它们在 XSI 选项中,主要是为了传统的 Unix 兼容性) ...
- .NET 云原生架构师训练营(模块二 基础巩固 日志)--学习笔记
2.2.2 核心模块--日志 ILogger 的使用 日志的 ID 日志的分类 日志的级别 LoggerProvider 日志的最佳实践 .NET Core 和 ASP.NET Core 中的日志记录 ...