【“互联网+”大赛华为云赛道】GaussDB命题攻略:支持三种开发语言,轻松完成数据库缓冲池
摘要:七届中国国际“互联网+”大学生创新创业大赛火热报名中,为了帮助参赛者更好了解赛题设计思路和命题方向,华为云产业命题赛道举行了线上直播解读,华为云数据库资深架构师苏斌在直播间详细解读了GaussDB命题赛道攻略,通过剖析数据库关键技术和赛题考点,助力参赛选手轻松拿高分。
目前,第七届中国国际“互联网+”大学生创新创业大赛火热报名中,为了帮助参赛者更好了解赛题设计思路和命题方向,华为云产业命题赛道举行了线上直播解读,华为云数据库资深架构师苏斌在直播间详细解读了GaussDB命题赛道攻略,通过剖析数据库关键技术和赛题考点,助力参赛选手轻松拿高分。

数据库是什么?
谈及数据库,可能有很多小伙伴不太了解,简单来说,数据库是存取和管理数据的软件(在生活中可以形象的类比为“大仓库”、“电子文件柜”等等)。当今世界是一个信息爆炸的时代,充斥着大量数据,我们的衣食住行,生活的方方面面都与数据有了不可分割的关系。
为了满足各种类型的数据特点与爆炸式的数据增长与存储管理压力,社会催生了多种类型数据库的蓬勃发展,很多关键的数据库新技术,例如分布式、云原生等也应运而生。这类数据库相比传统数据库性能更强,可靠性更强,扩展性更强,容量更大,有了这类数据库,数据读取/存储速度更快了,时延更低了,应对故障场景更从容了,面对大流量洪峰再也不怕了……
说到云原生分布式数据库的典型代表,华为云GaussDB(for MySQL)必须榜上有名。作为华为云GaussDB数据库的当家花旦,GaussDB(for MySQL) 100%兼容MySQL语法,是华为最新一代高性能企业级分布式关系型数据库。它基于华为最新一代DFV分布式存储,采用计算存储分离架构,最高支持128TB的海量存储,可实现超百万级QPS吞吐,支持跨AZ部署,数据0丢失,既拥有商业数据库的性能和可靠性,又具备开源数据库的灵活性。
为了让开发者深入了解数据库技术,并用相关技术解决企业实际业务问题,本届“互联网+”大赛的产业命题赛道·华为云GaussDB命题推出了相关题目:基于GaussDB(for MySQL)实现高性能、高扩展性的bufferpool(缓冲池)。
赛题解读:抢先掌握bufferpool(缓冲池)原理及技术,应战更从容
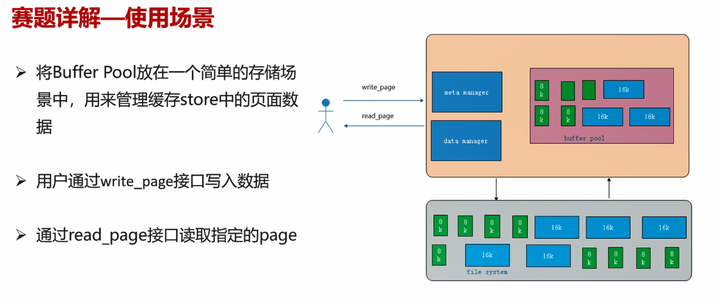
数据库系统一般都会有一个Buffer Pool(缓冲池),用于将一些频繁访问的热点数据从磁盘读到缓存中,避免我们在数据库中读取或者写入数据时对慢速磁盘设备进行频繁访问,从而加快数据的访问速度,提升数据库的性能。
本赛道赛题就是希望选手能借鉴并参考GaussDB(for MySQL)的设计理念和思路,实现一个高性能、高扩展性的Buffer Pool。比赛分为三个阶段,1)实现一个基本功能的Buffer Pool, 能够缓存固定大小(16K)的一些热点数据,需要保证从缓存中读取和写入数据的正确性。2)在保证正确性的前提下,使用LRU、LFU和LRU-K等淘汰算法及其变种,提升Buffer Pool 的命中率,从而提高热点数据访问速度。3)在云化场景下,为了提高资源利用率,会多种数据库共用同一存储资源池,每种数据库有不同的page size(页面大小), Buffer Pool需要有高扩展性,能够支持同时缓存各种page size(page size 固定为8KB、16KB、32KB和2MB)的数据。
这里科普下赛题中的相关概念:
- Page:Page是数据库中磁盘和内存交换的基本单位,也是数据库管理磁盘空间的基本单位。比如MySQL中默认的page大小为16K,PostgreSQL page为8K。
- Data manager:数据管理器,用于管理数据的读取和写入。
- Meta manager:元数据管理器,用于管理page在内存中的信息。
答题指南
8月31日报名结束后(在互联网+大赛官网和华为云平台均需报名),提交作品入口正式对外开放,请参考赛事组提供的DEMO,该DEMO包含评测程序及简单Buffer Pool实现,请在此基础上完成Buffer Pool的代码编写与编译,并在平台上传参赛作品,获取评测分数与结果。赛题组针对C++语言提供了log4cxx日志组件,详情参见赛题组DEMO,Java/Python等语言请使用常用的日志组件。作品运行反馈界面同时也提供日志下载,同时请避免打印过多的日志。
为了充分保证比赛的公平性,参赛选手不得使用第三方存储引擎库(如RocksDB、LevelDB、LMDB等),在其之上封装接口用来参赛;不得依赖第三方动态库,以免导致程序在评测环境不能运行;参赛程序初始化需在3分钟内完成,关闭需在10分钟内完成,测试需在30分钟内完成。
什么样的作品容易拿高分?
如果想完成高质量作品在大赛中“一骑绝尘”,那么你可能还需要了解比赛的评分逻辑,每个作品的测评分为两个阶段,包括正确性评测和性能评测。
正确性评测阶段,评测程序会进行纯读和读写混合测试。测试系统会随机对所有数据页面进行访问,访问包括读和写。
a. 对读取的页面,会对该页面进行正确性验证,页面验证不通过测试将结束,且测试不得分。
b. 对写入的页面,该页面可能在后续被再次访问,并进行正确性验证;同时当评测程序完成运行测试后,将发送信号关闭参赛程序,参赛程序需持久化尚未持久化的页面数据,评测程序将进行页面正确性验证。如果验证不通过,测试将结束,且测试不得分。
只有通过正确性评测阶段,才会进入性能评测阶段。性能评测的评测模型会有多种,评测参数参考如下:

在正确性验证通过的情况下,对每个不同评测模型的测试阶段整体计时,如果该阶段的正确检测全部通过,则成绩有效,根据总用时从低到高进行排名(用时越短排名越靠前)。评测程序将根据评测模型对参赛程序进行测试,计时从发送第一个请求开始,最后一个请求完成结束,最终计时为各项测试模型的测试阶段耗时之和。
最后再次提醒大家,本次“互联网+”大赛GaussDB赛道的时间安排:报名和时间截止到8月31日,初/复赛截止9月30日,预计10月中下旬举行全国总决赛。点击链接进入大赛页面报名:戳它报名。想要了解更多赛题详解,欢迎观看GaussDB命题解读直播回顾:回顾链接。
【“互联网+”大赛华为云赛道】GaussDB命题攻略:支持三种开发语言,轻松完成数据库缓冲池的更多相关文章
- Oracle12c 性能优化攻略:攻略1-1:创建具有最优性能的数据库
一:章节前言 本章着眼于影响表中数据存储性能的数据库特性. 表的性能部分取决于在创建之前所应用的数据库特性.例如:在最初创建数据库时采用的物理存储特性以及相关的表空间都会在后来影响表的性能.类似地,表 ...
- 2019阿里云开年Hi购季基础云产品分会场全攻略!
2019阿里云云上Hi购季活动已经于2月25日正式开启,从已开放的活动页面来看,活动分为三个阶段: 2月25日-3月04日的活动报名阶段.3月04日-3月16日的新购满返+5折抢购阶段.3月16日-3 ...
- 华为云DevCloud为开发者提供高效智能的可信开发环境
在HUAWEI CONNECT 2019期间,在华为云云服务开发者分论坛上,华为云布道师做了<CloudIDE:开发者的高效.智能的可信开发环境>专题演讲,主要介绍了华为云DevCloud ...
- 2019阿里云开年Hi购季云通信分会场全攻略!
2019阿里云云上Hi购季活动已经于2月25日正式开启,从已开放的活动页面来看,活动分为三个阶段: 2月25日-3月04日的活动报名阶段.3月04日-3月16日的新购满返+5折抢购阶段.3月16日-3 ...
- Python 自动化测试全攻略:五种自动化测试模型实战详解
随着移动互联网的发展,软件研发模型逐步完善,软件交付质量越来越受到软件公司的重视,软件测试技术特别是自动化测试技术开始在软件系统研发过程中发挥着越来越重要的作用. 与传统的手工测试技术相比,自动化测试 ...
- VSCode插件开发全攻略(六)开发调试技巧
更多文章请戳VSCode插件开发全攻略系列目录导航. 前言 在介绍完一些比较简单的内容点之后,我觉得有必要先和大家介绍一些开发中遇到的一些细节问题以及技巧,特别是后面一章节将要介绍WebView的知识 ...
- VSCode插件开发全攻略(三)package.json详解
更多文章请戳VSCode插件开发全攻略系列目录导航. package.json 在详细介绍vscode插件开发细节之前,这里我们先详细介绍一下vscode插件的package.json写法,但是建议先 ...
- JQuery攻略(三)数组与字符串
在上两章,JQuery攻略(一) 基础知识——选择器 与 DOM 和 JQuery攻略(二) Jquery手册 我们为后面的章节打好了基础,在这一章节中,我们继续. 在这一章节中,我们记录的是JQue ...
- javase基础复习攻略《三》
编程语言的发展: 机器语言——直接由计算机的指令组成,指令.地址.数据都是以"0"和"1"的符号串组成,可以被计算机直接执行. 汇编语言——用容易理解和记忆的符 ...
- LinuxShell脚本攻略--第三章 以文件之名
生成任意大小的文件文件权限.所有权和粘滞位创建不可修改文件生成空白文件查找符号链接及其指向目标head 与 tail只列出目录的其他方法在命令行中用 pushd 和 popd 快速定位(cd -)统计 ...
随机推荐
- Python 继承和子类示例:从 Person 到 Student 的演示
继承允许我们定义一个类,该类继承另一个类的所有方法和属性.父类是被继承的类,也叫做基类.子类是从另一个类继承的类,也叫做派生类. 创建一个父类 任何类都可以成为父类,因此语法与创建任何其他类相同: 示 ...
- Java技术_基础技术(0003)_类执行顺序详解+实例(阿里面试题)+详细讲解+流程图
类加载机制 加载.验证.准备.初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的 ...
- 好用的解决PowerDesign中字体图片太小分辨率问题【已解决】
熟悉数据库设计的小伙伴可能都会用到一款名叫PowerDesign的工具 但是我在使用这款工具时候发现界面中的图标和文字都非常小,看的人眼睛疼,如下图 我刚开始修改了软件的字体大小,发现只是字稍微大了点 ...
- C语言计算并输出华氏温度为80F所对应的摄氏温度C。转换公式为:C=5*(F-32)/9
#include <stdio.h> int main() { double F = 80.0, C;//定义摄氏温度变量,赋值华氏温度 C = 5 * (F - 32) / 9.0;// ...
- 【开源项目推荐】通用SQL数据血缘分析工具——Sqllineage
大家好,我是独孤风,从本周开始,争取每周为大家带来一个优秀的开源项目推荐. 开源项目不仅促进了技术的发展和普及,还为全球范围内的开发者和用户社区建立了一个共享知识.协作和创新的平台.站在巨人的肩膀上才 ...
- 从0到1,手把手带你开发截图工具ScreenCap------003实现最小化程序到托盘运行
ScreenCap---Version:003 说明 上一篇:实现默认位置设置 为了方便截图干净,实现最小化程序到托盘运行,简洁,勿扰 实现最小化程序到托盘运行 实现托盘菜单功能 实现回显主窗体 实现 ...
- DFT与ATE IP TEST
IP的DFT设计测试与ATE IP TEST是一个设计,测试活动吗? 不是. 这两个设计对于前端工农村很容易搞混,认为是同一个人负责,同一个活动.实际情不是. DFT主要空DSC控制器对IP进行扫描, ...
- [ICPC2014 WF] Pachinko
[ICPC2014 WF] Pachinko 题面翻译 题目描述 有一个宽度为 \(w\) 高度为 \(h\) 的方格纸, $ w \times h$ 的格子中,有一些是空的,有一些是洞,有一些是障碍 ...
- JQuery_1
1.概念:一个JavaScript框架.简化js开发 JavaScript框架:本质上就是一些js文件,封装了js的原生代码. 2.快速入门: 1.步骤 1.下载JQuery jquery.xxx.j ...
- [VBA] 实现SQLserver数据库的增删改查
[VBA] 实现 SQLserver数据库的增删改查 问题背景 用于库存管理的简单Excel系统实现,能够让库管员录入每日出入库信息并进能够按日期查询导出数据,生成简要报表,以及数据修改与删除.非科班 ...