兰姆达 x AnayticDB 降本30%的数据湖最佳实践
1. 客户介绍
上海兰姆达数据科技有限公司(简称“兰姆达数据”)是一家提供卓越的数据科学软件产品和解决方案的初创高科技公司。兰姆达核心团队专注于大数据,机器学习算法和精准营销SaaS平台。公司提供的数据科学平台主要包括:自动化机器学习平台SuperML和自助式BI工具SuperBI。
在行业解决方案上,公司已上线一套针对汽车4S 店的售后精准营销SaaS平台“超级站长Super4S” ,服务了一汽大众,上汽通用等数十家经销商。目前公司主要客户集中在汽车,电商,互联网等行业。
2. 业务背景
本业务主要目的是对用户在社交媒体和新媒体上发布的内容进行文本挖掘。数据主要包括各媒体平台的文章/视频的主贴内容以用户的评论内容,本业务有以下几个特点和挑战:
数据量大,每日新增文本数据数百万条
文本数据内容需要更新,例如文章发布后每天的阅读数,点赞数等指标都会变化,分析时需要用文章最新的指标
不需要进行实时分析,只需要T+1离线分析
文本分析耗时长,需要集群资源能灵活的弹升保证较快完成计算任务
文本分析算法复杂,传统的数据仓库SQL语言不能实现所有需求
业务整体技术架构如下
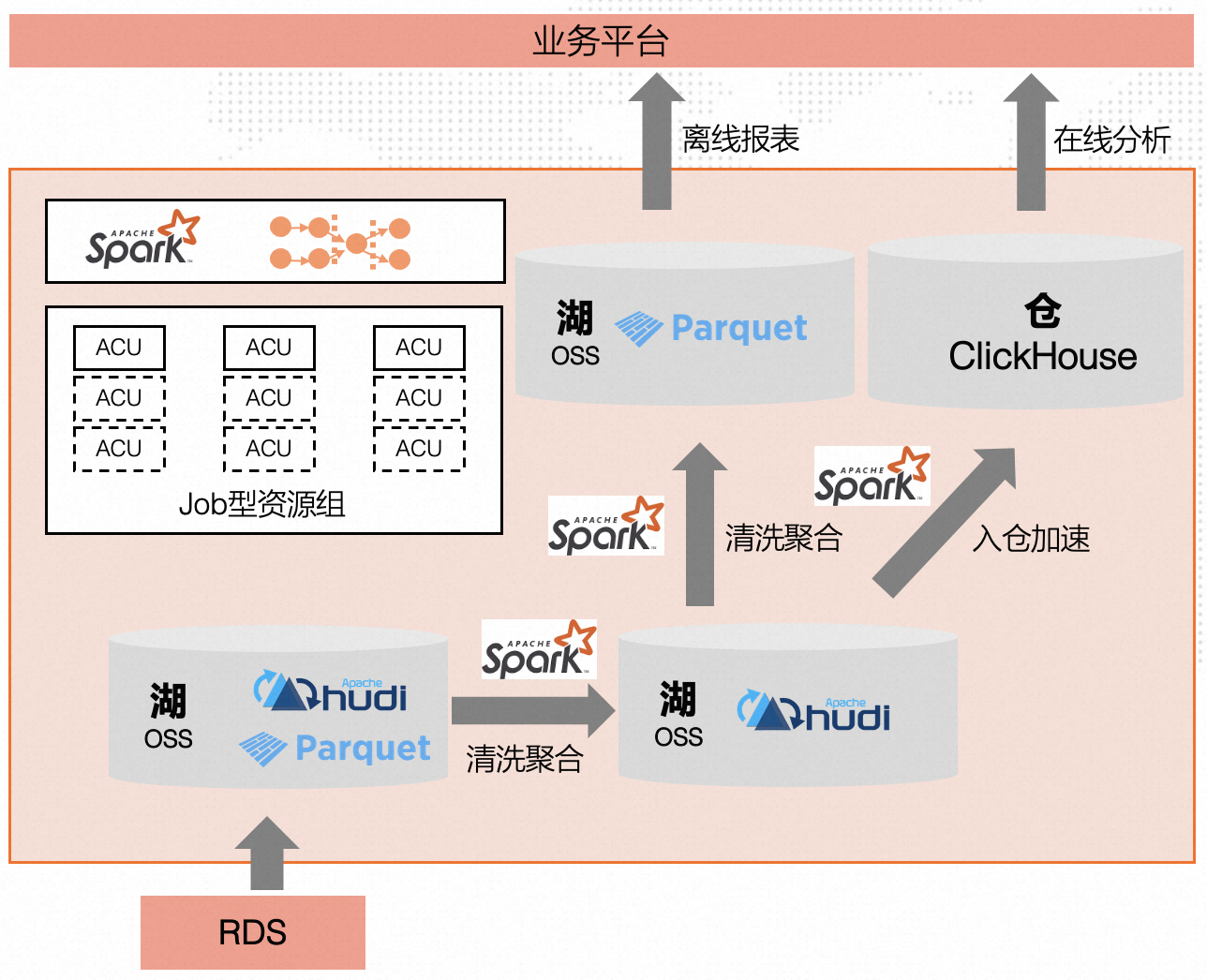
通过平台自研数据采集模块从门户网站采集信息至RDS,日增百万条记录
RDS数据通过数据增量抽取以parquet格式写入OSS
通过 Spark 对 parquet表进行清洗并写入Hudi表,清洗逻辑涉及分词、分句、实体关键词的抽取(车型)、统计等。
通过 Spark 对Hudi表进行清洗聚合后再写入Hudi表
根据业务诉求生成Parquet离线文件供数据分析师下载使用或将数据导入ClickHouse进行在线分析
3. 解决方案
针对本业务的上述特点,我们在技术选型的时候重点关注以下几个技术点:
方便支持海量非结构化数据存储和备份
减少数据的移动,存储和计算分离
以离线计算为主
计算资源能弹性升级,并且实现按量计费模式,不能有高昂的包年包月基础费
能高效支持数据更新
经过调研发现阿里云 ADB湖仓版是最能满足以上需求的产品。ADB Spark按量付费,完全弹性的特性很好的满足了我们的业务诉求。构建本业务使用到的阿里云组件主要包括:
OSS对象存储:用于存储海量文本数据,具有存储便宜,无限容量,安全可靠等优势,省去了很多担心容量不够和数据丢失的后顾之忧。
ADB湖仓版:使用ADB Spark作为计算引擎对文本数据进行分析,相比传统数据库技术能更快更灵活的处理数据和开发分析算法。
ADB Hudi:基于Hudi技术实现对海量数据的及时更新。
DMS:阿里云的另外一套数据开发调度平台,可以作为dataworks的一个补充,最关键的是它是免费的。
ClickHouse:数据湖分析输出的结果数据可以推送到Clickhouse中进行后续的BI可视化分析和查询,满足对数据实时查询的需求
ADB湖仓版整体架构如下(来自官方资料),我们的业务流程与该图比较契合。
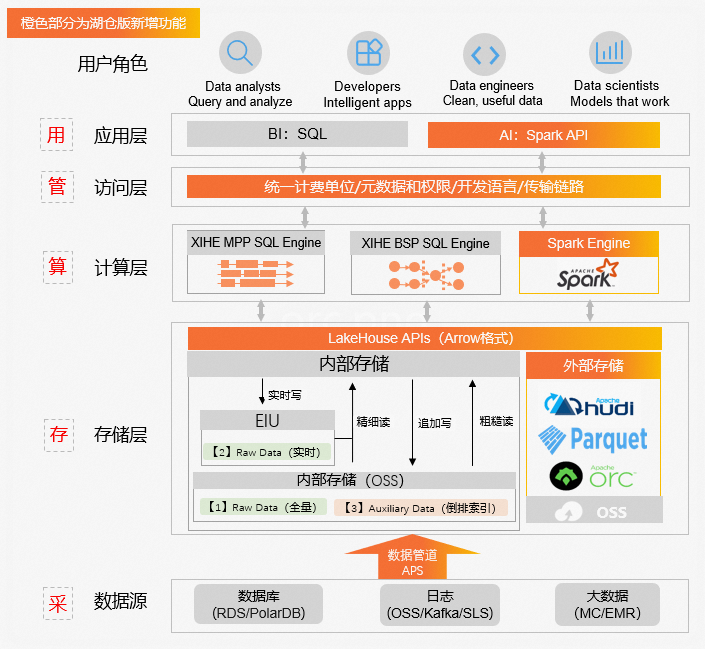
ADB Spark:按需弹性的大规模离线处理引擎
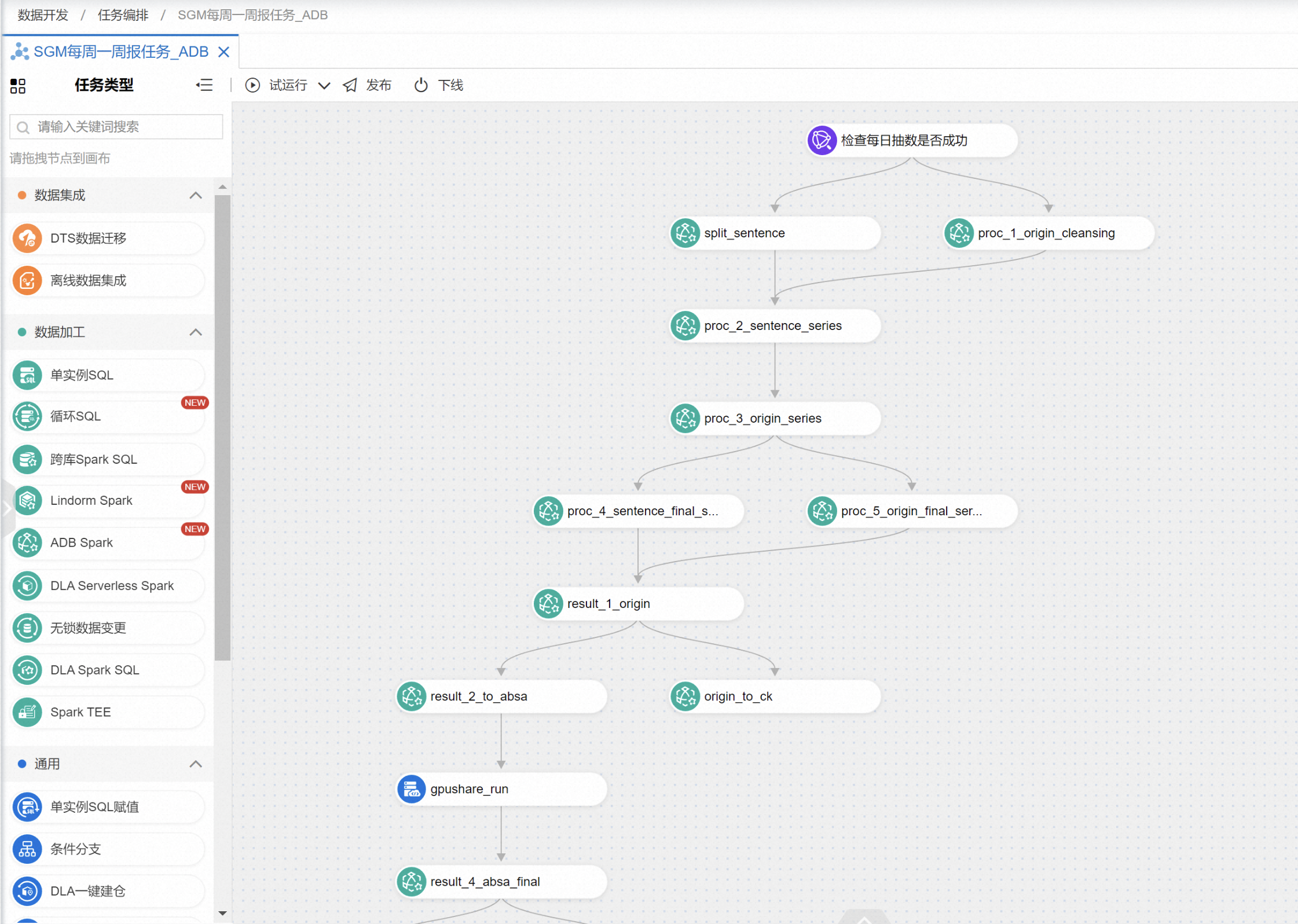
ADB Spark用作大规模离线数据清洗聚合,完全弹性,无需运维,借助DMS + ADB Spark可以很好的编排作业,典型业务工作流编排如下
典型的Spark SQL写入Hudi表作业配置如下
set spark.driver.resourceSpec=medium;
set spark.executor.instances=30;
set spark.executor.resourceSpec=medium;
set spark.app.name=dwm_origin_cleansing_daily;
set spark.sql.storeAssignmentPolicy=LEGACY;
set spark.driver.maxResultSize=10G;
set spark.driver.memoryOverheadFactor=0.4;
set hoodie.metadata.enable = true;
set hoodie.cleaner.commits.retained=3;
-- 每日新增数据去重清洗插入dwm_origin_hudi 表
insert into table dia_dwm.dwm_origin_hudi partition (pt,sid)
select
site_id,
channel_id,
category_1st,
category_2nd,
url,
date(issue_time) as pt,
site_id as sid
from
(
select *,row_number() OVER (PARTITION BY pid ORDER BY crawl_time DESC) AS rn
from dia_ods.ods_channel_collect_origin
where dt='${bizdate}'
) t
where t.rn = 1
ADB Hudi:支持增删改的高吞吐数据层
考虑典型业务场景:计算某个微博7天内的点赞量以及微博对于汽车的评价。
采集模块每天采集微博数据并写入RDS,每天采集的微博都是一个事件写入RDS,因此RDS中对于同一条微博会有多条数据,需要计算微博7天点赞量并对微博进行情感分析。
引入Hudi之前处理流程
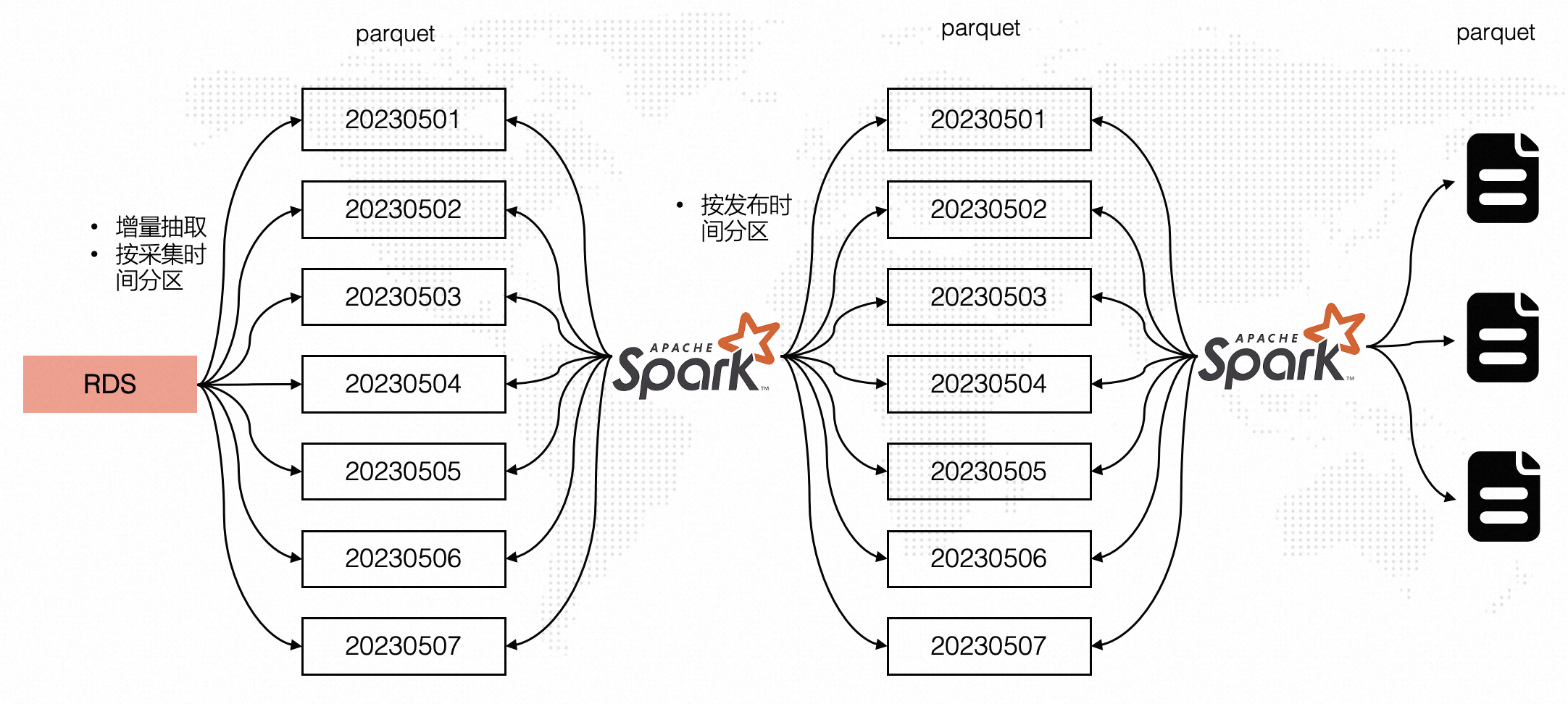
在引入Hudi之前整体处理流程如下图所示,RDS数据按照采集时间每天增量抽取至OSS中,如考虑20230501-20230507七天分区数据,20230507分区中可能会包含20230506以及20230501分区的数据。
通过Spark读取七天的数据并开窗取同一条微博最新数据以及过滤掉七天外的数据(20230501分区可能包含20230401的数据,对于这部分超过7天的数据直接过滤掉),处理完后按照发布时间(事件时间)分区写入parquet表,此时的写入是分区覆盖写(保证写入最新数据),也就意味着Spark每天读取7天的数据,然后全量覆盖多个分区,有较多的重复计算和写入,处理效率相对低效。
引入Hudi之后处理流程
在引入Hudi后,前面增量抽取与前面方案相同,但是在第二步Spark计算时只处理一天的数据,而非处理七天的数据,然后按照发布时间(事件时间)更新Hudi表的对应分区,不需要进行分区级全量覆盖,同时Spark对于延迟数据(20230401)可以直接借助Hudi Upsert能力支持对超过7天的数据进行更新,而非在Spark开窗函数中过滤掉。
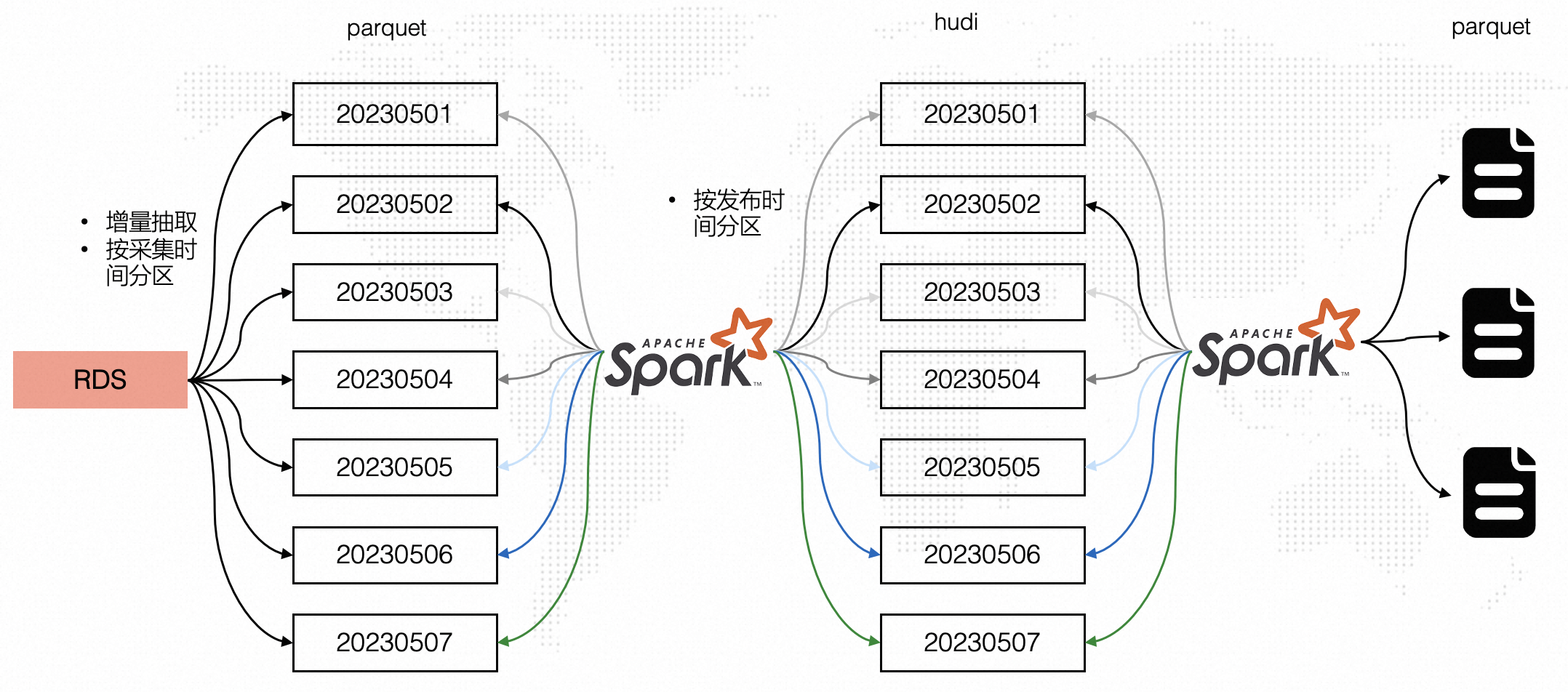
对比两种架构,引入Hudi后的架构有如下优势。
Spark处理数据由七天变成一天,数据量每天减少约7倍
Spark处理逻辑更简单,无需丢弃七天外的延迟数据,Hudi支持任意延迟时间数据更新写入
写入处理后的数据时无需全量覆盖,直接按照分区更新即可,效率更高
4. 方案收益
从计算耗时和计算费用两个方面来看项目的收益:
- 计算耗时:下降3倍
使用传统自建Hadoop集群的方式,对于小公司,由于成本原因,集群的固定资源一般是不够大的,这会导致计算任务耗时很长,尤其是任务多了之后只能串行处理不能并行化,导致时间会更长。使用可灵活弹性升级的ADB数据湖分析平台后,我们可以并行化启动多个任务流,每个任务流根据我们预计的完成时间分配合理的计算资源ACU数量,可以做到不增加总成本的基础上,让计算时间显著缩短。目前我们每天的计算任务可以控制在30分钟内完成,一周的计算任务可以控制在3小时内完成。最快的一次,我们需要重算历史一年的数据,通过指定使用更多的ACU数量,在1天之内就全部计算完成。同时引入Hudi后作业耗时从10min下降到3min。
- 计算费用:下降30%~50%
ADB数据湖分析的整体费用由两部分构成:OSS存储和接口费+ADB Spark按量计算费用。OSS存储和接口费,按照数据量10TB左右估算,每个月费用应该在2000元以内;ADB Spark按量计算费用是按ACU数量*计算时长收费,100核400G的集群算1个小时大概35元,性价比非常高。ADB Spark + OSS组合方案中 Spark 计算 + OSS存储成本每个月5000左右,一年约6万,搭建传统集群50个CU 估计1年成本9万多,整体成本下降30%,如果业务数据量大,计算复杂,计算频率不是很高,整体成本下降更高,使用ADB Spark数据湖分析绝对是最佳性价比的产品。
使用阿里云数据湖分析架构后,数据处理时长显著下降,同时计算成本非常优化,ADB数据湖分析可谓是一款性价比极高的大数据产品。
兰姆达 x AnayticDB 降本30%的数据湖最佳实践的更多相关文章
- LambdaToSql 发布 兰姆达转换sql
文档目录索引 查询.函数.分组.排序.分页 添加 Insert into 编辑 Update set 删除 Delete 生成实体 内置常用工具类库 文档完善中... 事务处理 Join 连接查询 ...
- C/C++ C++ 11 兰姆达
{ auto layer = Layer::create(); auto event = cocos2d::EventListenerTouchOneByOne::create(); ev ...
- c++ 兰姆达表达式
#include<iostream> using namespace std; int main() { int a = 1; int b = 2; aut ...
- 翻译 | 30个 Python3 的最佳实践,技巧和窍门
1.使用 Python3 如果你关注 Python 的话,应该会知道 Python 2 已经于今年(2020 年)1 月 1 日正式弃用了.这份教程的很多例子都是只支持 Python 3 的,如果你还 ...
- MySQL 性能优化 30个数据库设计的最佳实践
数据库设计是整个程序的重点之一,为了支持相关程序运行,最佳的数据库设计往往不可能一蹴而就,只能反复探寻并逐步求精,这是一个复杂的过程,也是规划和结构化数据库中的数据对象以及这些数据对象之间关系的过程. ...
- 20145307陈俊达《网络对抗》Exp3 免杀原理与实践
20145307陈俊达<网络对抗>Exp3 免杀原理与实践 基础问题回答 杀软是如何检测出恶意代码的? 恶意代码中一般会有一段有较明显特征的代码也就是特征码,如果杀毒软件检测到有程序包含的 ...
- 数据库周刊30丨数据安全法草案将亮相;2020数据库产业报告;云南电网上线达梦;达梦7误删Redo Log;Oracle存储过程性能瓶颈;易鲸捷实践案例……
摘要:墨天轮数据库周刊第30期发布啦,每周1次推送本周数据库相关热门资讯.精选文章.干货文档. 热门资讯 1.数据安全法草案即将亮相:将确立数据分级分类管理.应急处置制度[摘要]数据安全法草案即将在本 ...
- 降本增效利器!趣头条Spark Remote Shuffle Service最佳实践
王振华,趣头条大数据总监,趣头条大数据负责人 曹佳清,趣头条大数据离线团队高级研发工程师,曾就职于饿了么大数据INF团队负责存储层和计算层组件研发,目前负责趣头条大数据计算层组件Spark的建设 范振 ...
- Postgresql查询最近12个月、最近30天数据
-- 最近 12 个月 SELECT * FROM 表名 WHERE 日期字段 BETWEEN (now() - INTERVAL '12 months') AND now() -- 最近 30 天 ...
- oracle 查询前30条数据
select * from (select a.*,rownum as rn from tetm_ad_type a) b where b.rn<30 --表名不能用as 字段取别名,直 ...
随机推荐
- NextCloud 在lnmp下 nginx 的配置
server { listen 80; listen [::]:80; server_name lnmp.org www.lnmp.org; root /home/wwwroot/nextcloud; ...
- ES6中新增的promise异步编程解决方案
promise异步编程解决方案 第1章 准备 1.1 区别实例对象与函数对象 (1).实例对象:通过 new 函数 产生的对象,称为实例对象,简称对象 (2).函数对象:将函数作为对象使用 ...
- 可视化大屏的终极解决方案居然这么简单,vue-autofit一行全搞定!
可视化大屏适配/自适应现状 可视化大屏的适配是一个老生常谈的话题了,现在其实不乏一些大佬开源的自适应插件.工具但是我为什么还要重复造轮子呢?因为目前市面上适配工具每一个都无法做到完美的效果,做出来的东 ...
- SpringCloud Gateway 3.x 响应头添加 Skywalking TraceId
在微服务架构中,一次请求可能会被多个服务处理,而每个服务又会产生相应的日志,且每个服务也会有多个实例.在这种情况下,如果系统发生异常,没有 Trace ID,那么在进行日志分析和追踪时就会非常困难,因 ...
- Selenium 打包为.exe执行
前言:不依赖环境执行,拓展UI自动化使用的场景 一.项目结构介绍 case:测试用例次存放目录 config:主要存放yaml文件配置 ele:元素的定位以及执行动作 tools:HTMLTestRu ...
- 2020-09-15:java里的wait()和sleep()的区别有哪些?
福哥答案2020-09-15:#福大大架构师每日一题# 1.线程状态.wait()的线程状态是TimedWaiting和Waiting.sleep()的线程状态是Waiting.2.指定时间.wait ...
- WARNING: The repository located at mirrors.aliyun.com is not a trusted or secure host and is being
更换下载源: https://pypi.tuna.tsinghua.edu.cn/simple/
- python爬虫防止IP被封的一些措施(转)
python爬虫防止IP被封的一些措施(转) 在编写爬虫爬取数据的时候,因为很多网站都有反爬虫措施,所以很容易被封IP,就不能继续爬了.在爬取大数据量的数据时更是瑟瑟发抖,时刻担心着下一秒IP可能就被 ...
- IntelliJ IDEA上手这一篇就够了,从入门到上瘾
前言 每次换电脑,最最最头疼的事情莫过于安装各种软件和搭建开发环境.这算是不想换电脑的一个原因吧(最主要还是穷).除非是电脑坏了开不了机或者点一下卡一下,真不想换电脑.每次换电脑都得折腾好久. 趁着这 ...
- 手动封装XMLHttpRequest
自己动手封装一个XMLHttpRequest, 兼容低版本浏览器,自动检测post与get 类型请求,自动参数拼接,参数类型辨别 <!DOCTYPE html> <html> ...