32位x86处理器编程架构
1. IA-32架构的基本执行环境
1.1 寄存器的扩展
为了在汇编语言程序中使用经过扩展(Extend) 的寄存器:
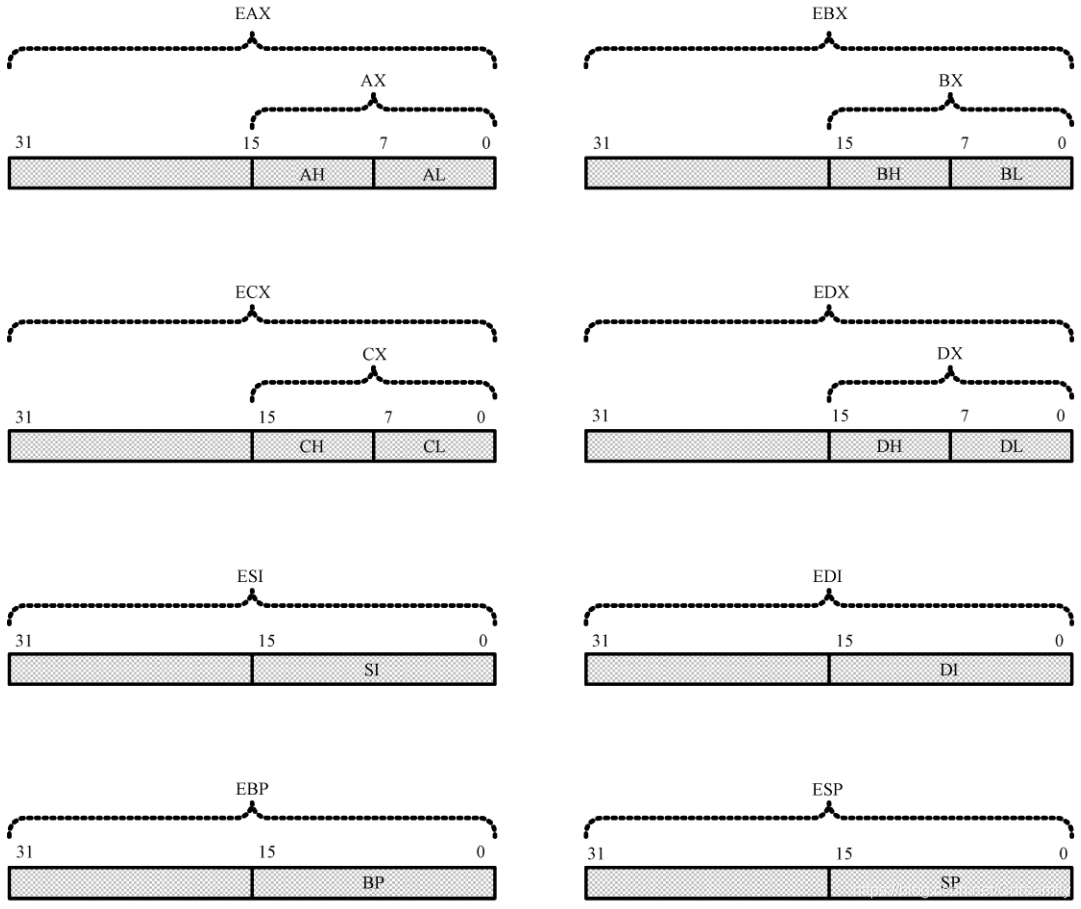
在32位模式下,为了生成32位物理地址,处理器需要使用32位的指令指针寄存器。标志寄存器也扩展到32位,第16位和原先保持一致。
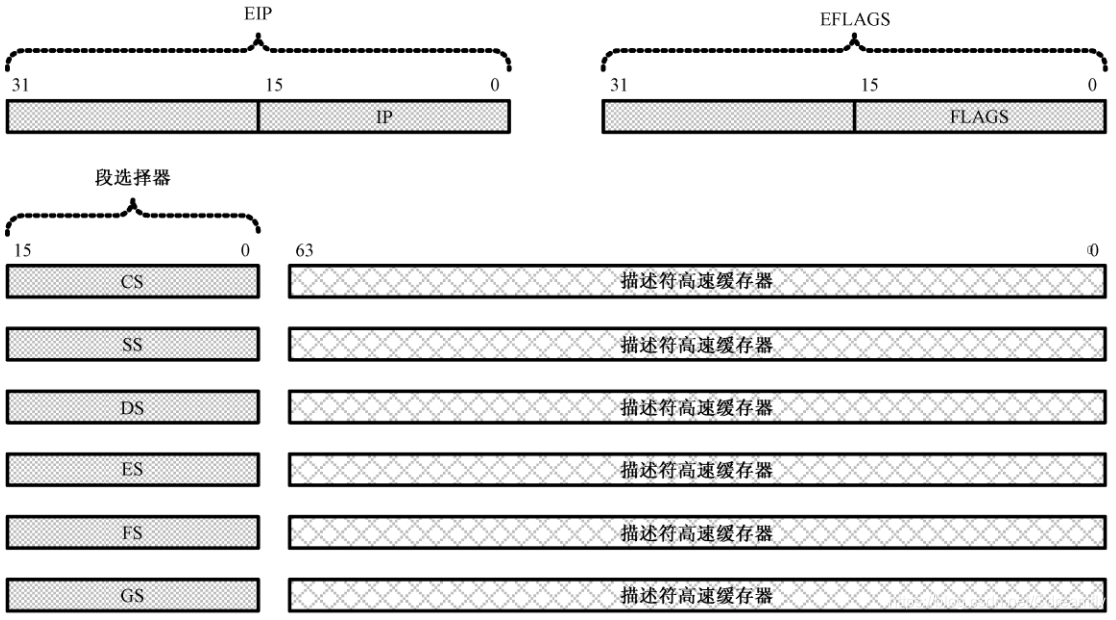
32位处理器依然需要以段位单位访问内存,即,只分一个段,段地基地址是0x00000000,段地长度(大小)是4GB。在这种情况下,可以视为不分段,即平坦模式(Flat Mode)。
在32位模式下传统的段寄存器,保存的不再是16位段地址,而是段选择器,而且增加了两个额外的段寄存器FS和GS,每个段寄存器还包括一个不可见部分,称为描述符高速缓存器。
1.2 线性地址
段的管理是由处理器的段部件负责进行的,段部件将段地址和偏移地址相加,得到访问内存的地址。一般来说,段部件产生的地址就是物理地址。
分页功能将物理内存空间划分成逻辑上的页。页的大小是固定的,一般为4KB,通过使用页,可以简化内存管理,将小块内存空间,分配给某个任务。
当页功能开启时,段部件产生的地址就不再是物理地址了,而是线性地址(Linear Address),线性地址还要经页部件转换后,才是物理地址。
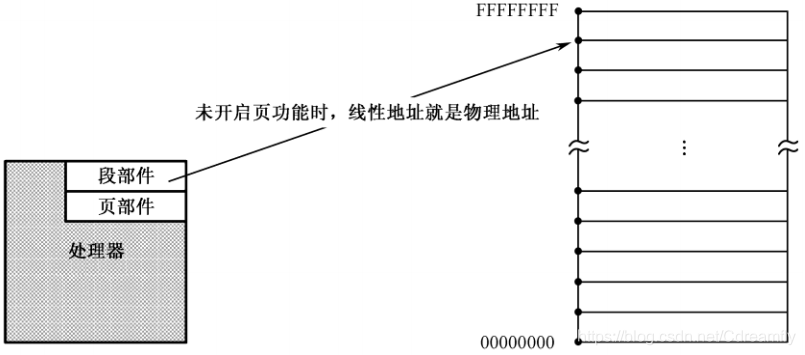
线性地址的概念用来描述任务的地址空间。IA-32 处理器上的每个任务都拥有4GB 的虚拟内存空间,这是一段长 4GB 的平坦空间,就像一段平直的线段,因此叫线性地址空间。相应地,由段部件产生的地址,就对应着线性地址空间上的每一个点,这就是线性地址。
2. 现代处理器的结构和特点
2.1 流水线
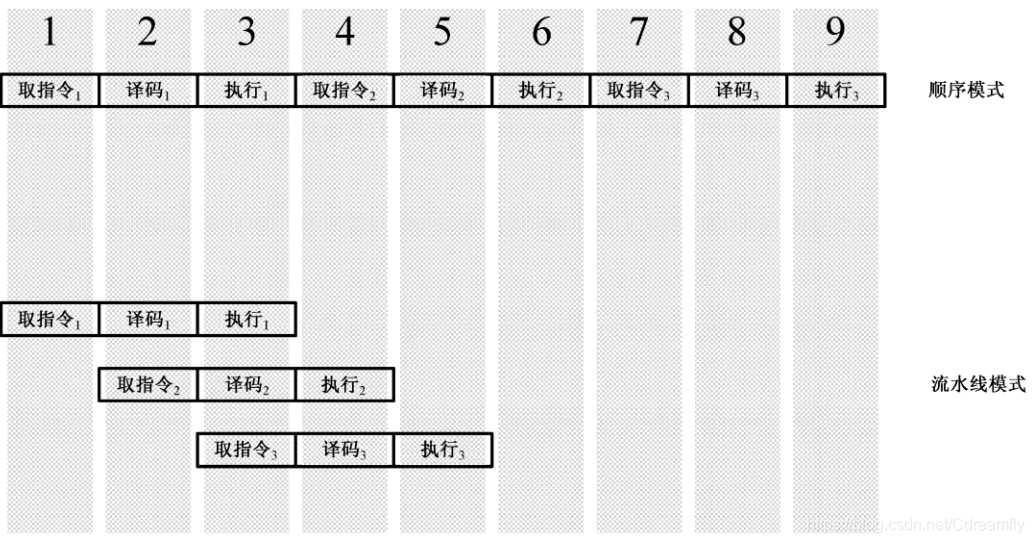
为了提高处理器的执行效率和速度,可以把一条指令的执行过程分解成若干个细小的步骤,并分配给相应的单元来完成。各个单元的执行是独立的,并行的。如此一来,各个步骤的执行在时间上就会重叠起来,这种执行指令的方法就是 流水线(Pipe-Line) 技术。
2.2 高速缓存
寄存器的速度最快,因为使用了触发器,这是一种反馈原理制作的存储电路,工作速度是 纳秒(ns) 级别的。内存(DRAM 动态存储器) 芯片的材料一般是电容和单个的晶体管,由于电容需要定时刷新,使得他的访问速度变得很慢,通常是几十个纳秒。最后是硬盘,由机电设备,通常在毫秒级(ms)。
这种情况下,为了解决需要等待内存和硬盘这样的低速设备,一个在处理器和 内存(DRAM) 之间速度可以匹配的静态存储器 高速缓存(Cache) 应运而生。
利用程序运行时的局部性原理,可以把处理器正在访问和即将访问的指令和数据块从内存调入高速缓存中。于是,每当处理器要访问内存时,首先检索高速缓存。如果要访问的内容已经在高速缓存中,那么,可以用极快的速度直接从高速缓存中取得,这称为命中(Hit);否则,称为不中(Miss)。在不中的情况下,处理器在取得需要的内容之前必须重新装载高速缓存,而不只是直接到内存中去取那个内容。高速缓存的装载是以块为单位的,包括那个所需数据的邻近内容。为此,需要额外的时间来等待块从内存载入高速缓存,在该过程中所损失的时间称为不中惩罚(MissPenalty)。
2.3 乱序执行
为了实现流水线技术,需要将指令拆分成更小的可独立执行部分,即拆分成微操作(Micro-Operations),简写为μ ops。
有些简单指令只用一个微操作:
add eax,ebx
有些指令可以拆分成两个微操作,一个从内存中读取数据并保存到临时寄存器,另一个用于将EAX寄存器和临时寄存器的数值相加。
add eax,[mem]
这个可以拆分成三个微操作一个从内存中读数据,一个执行相加的动作,第三个用于将相加的结果写回到内存中。一旦将指令拆分成为操作,处理器就可以在必要的时候 乱序执行(Out-Of-Order Execution) 程序:
mov eax,[mem1]
shl eax,5
add eax,[mem2]
mov [mem3],eax
这里,指令mov [mem2],eax可以拆分成两个微操作,如此,在执行逻辑左移指令的同时,处理器可以提前从内存中读取mem2的内容,典型的,如果数据不在高速缓存中,那么处理器在获取mem1的内容之后,会立即开始获取mem2的内容,于是同时,shl指令已经开始执行了。同理,乱序执行可以大大加快如push,call等指令的执行速度。
2.4 寄存器重命名
mov eax,[mem1]
shl eax,3
mov [mem2],eax
mov eax,[mem3]
add eax,2
mov [mem4],eax
代码上做了两件事情,一个是将mem1的内容进行左移3个单位,另一个是将mem3的内容+2,如果将后面三个操作所用的寄存器名名称不同的名字,那么这个操作也不会被影响,所以处理器为最后三条指令使用了另一个不同的临时寄存器,因此左移和加法可以并行地进行。
mov eax,[mem1]
mov ebx,[mem2]
add ebx,eax
shl eax,3
mov [mem3],eax
mov [mem4],ebx
假定现在mem1的内容在高速缓存中,可以立即取得,但mem2的内容不在高速缓存中,也就是说,算术左移可以在add之前就进行了,所以我们为左移设定一个新的临时寄存器,那么这样eax的内容认识以前的,他将一直保存着这个值,直到ebx的内容就绪,然后和它一同做加法运算。如果没有寄存器重命名机制,左移操作将不得不等待从内从中读取mem2的内容到EBX寄存器中以及加法操作。
在所有操作都完成后,那个代表EAX寄存器的最终结果的临时寄存器的内容被写入真实的EAX寄存中,该处理过程被称为引退(Retirement)。所有通用寄存器,栈指针,标志,浮点寄存器,甚至段寄存器都有可能被重命名。
2.5 分支目标预测
流水线并不是百分百完美解决方案。如果遇到转移指令,则后面已经进入流水线的指令就无效了。所以引入了分支预测技术(Branch Prediction)。它会预测预测会不会发生转移,当处理器执行了一条分支语句后,它会在处理器内部一个小容量的高速缓存器,叫 分支目标缓存器(Branch Target Buffer,BTB) 中记录当前指令的地址,分支目标的地址,以及本次分支预测的结构。下一次,在那条转移指令实际执行前,处理器会查找 BTB,看有没有最近的转移记录。如果能找到对应的条目,则推测执行和上一次相同的分支,把该分支的指令送入流水线。
当该指令实际执行时,如果预测是失败的,那么,清空流水线,同时刷新 BTB 中的记录。这个代价较大。
3. 32位模式的指令系统
3.1 32位处理器的寻址方式
如果处理器在16位模式下,没有指令前缀0x66,则认为指令是传统的16位寻址方式,如果有指令前缀0x66,则是32位寻址方式,在32位模式下,没有指令前缀0x66,则认为指令是传统的32位寻址方式,如果有指令前缀0x66,则是16位寻址方式。指令默认使用32位宽度的寄存器和32位的立即数,如果存在内存寻址,则偏移量也是32位的。
32位模式下,内存寻址可以使用全部的32位通用寄存器作为基址寄存器,还可以加上一个除了ESP的32位通用寄存器作为变址寄存器,变址寄存器还可以允许乘以1,2,4和8作为比例因子。最后还可以在加上一个8位或者32位的偏移量。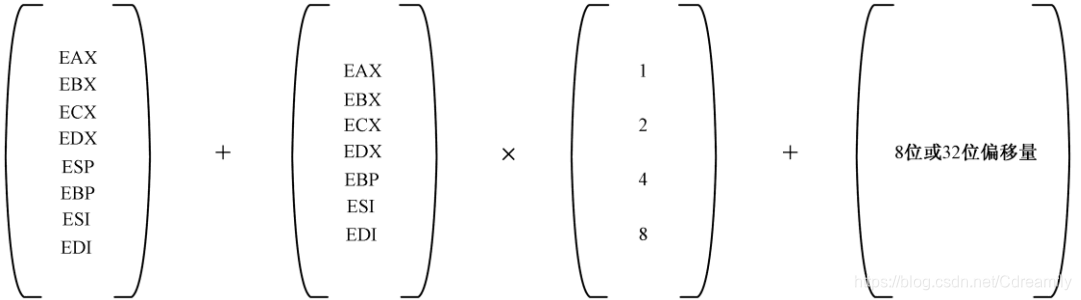
3.2 操作数大小的指令前缀
每一条处理器指令都可以拥有前缀,比如重复前缀(REP/REPE/ REPNE)、段超越前缀(如 ES:)、总线封锁前缀(LOCK)等。前缀是可选的,每个前缀的长度是 1 字节,每条指令可以有 1~4 个前缀,或者不使用前缀。

为了指明程序的默认运行环境,编译器提供了伪指令 bits,用于指明其后的指令应该被编译成 16 位的,还是 32 位的。
3.3 一般指令的扩展
由于 32 位的处理器都拥有 32 位的寄存器和算术逻辑部件,而且同内存芯片之间的数据通路至少是 32 位的,因此,所有以寄存器或者内存单元为操作数的指令都被扩充,以适应 32 位的算术逻辑操作。而且,这些扩展的操作即使是在 16 位模式下(实模式和 16 位保护模式)也是可用的。
32位处理器的栈允许压入双子操作数。特别是,它现在支持立即数压栈操作。通用寄存器可以不用关键字byte,word,dword修饰,内存单元一定要关键字byte,word,dword修饰,处理器压入内存操作行为和压入立即数的行为是一样的。
- 如果压入一个字节,必须使用byte来修饰,但是,他执行是,无论在什么时候,处理器都不会真的压入一个字节,会将该字节操作符号位扩展到高24位,压栈时使用ESP寄存器,且先将ESP的内容减去4。
- 如果压入一个字,必须使用word来修饰,压入的扩展到高16位,且先将ESP的内容减去4。
- 如果要压入一个双字立即数,则无论是在16位模式下或者是32位模式下,一定要使用dword,而且栈指针寄存器(SP或者ESP)都要减去4。
- 压入段寄存器操作比较特殊,在 16 位模式下,先将 SP 的内容减去 2,然后直接压入段寄存器的内容;在 32 位模式下,要先将段寄存器的内容用零扩展到 32 位,即高 16 位为全零。然后,将 ESP 的内容减去 4,再压入扩展后的 32 位值。
32位x86处理器编程架构的更多相关文章
- x86-1-32位x86 处理器编程架构
x86(32位)-1-32位x86 处理器编程架构 Intel 32 位处理器架构简称IA-32(Intel Architecture,32-bit) x86是指intel的86系列的CPU统称,比如 ...
- 32位x86处理器编程导入——《x86汇编语言:从实模式到保护模式》读书笔记08
在说正题之前,我们先看2个概念. 1.指令集架构(ISA) ISA 的全称是 instruction set architecture,中文就是指令集架构,是指对程序员实际"可见" ...
- 32位x86处理器架构
我们看看32 位 x86 处理器的基本架构特点.这些处理器包括了 Intel IA-32 系列中的成员和所有 32 位 AMD 处理器. 操作模式 x86 处理器有三个主要的操作模式:保护模式.实地址 ...
- ASM:《X86汇编语言-从实模式到保护模式》第10章:32位x86处理器的编程架构
★PART1:32位的x86处理器执行方式和架构 1. 寄存器的拓展(IA-32) 从80386开始,处理器内的寄存器从16位拓展到32位,命名其实就是在前面加上e(Extend)就好了,8个通用寄存 ...
- 【电脑常识】如何查看电脑是32位(X86)还是64位(X64),如何知道硬件是否支持64位系统
开始->运行->输入cmd确定->输入systeminfo 回车 待加载完成,就会看到如下信息(不同版本略有差异): 一.如何查看电脑是32位(X86)还是64位(X64) 方法2: ...
- 16位模式/32位模式下PUSH指令探究——《x86汇编语言:从实模式到保护模式》读书笔记16
一.Intel 32 位处理器的工作模式 如上图所示,Intel 32 位处理器有3种工作模式. (1)实模式:工作方式相当于一个8086 (2)保护模式:提供支持多任务环境的工作方式,建立保护机制 ...
- 32位汇编第一讲x86和8086的区别,以及OllyDbg调试器的使用
32位汇编第一讲x86和8086的区别,以及OllyDbg调试器的使用 一丶32位(x86也称为80386)与8086(16位)汇编的区别 1.寄存器的改变 AX 变为 EAX 可以这样想,16位通 ...
- 32位嵌入式微处理器(processor)一览
32位嵌入式微处理器(processor)一览 由于嵌入式系统的专用型与定制性,与全球PC市场不同,没有一种微处理器或者微处理器公司可以主导嵌入式系统.本文分析了当前市场上主流的一些32位嵌入式微处理 ...
- 32位JDK和64位JDK
32位和64位系统在计算机领域中常常提及,但是仍然很多人不知道32位和64位的区别,所以本人在网上整理了一些资料,并希望可以与大家一起分享.对于32位和64位之分,本文将分别从处理器,操作系统,JVM ...
- linux arch目录下处理器体系架构介绍
alpha 处理器Alpha 处理器最早由美国DEC 公司设计制造,在Compaq (康柏)公司收购DEC 之后,Alpha 处理器继续得到发展,并且应用于许多高档的Compaq 服务器上,HP (惠 ...
随机推荐
- JavaScript 的新数组分组方法
对数组中的项目进行分组,你可能已经做过很多次了.每次都会手动编写一个分组函数,或者使用 lodash 的 groupBy 函数. 好消息是,JavaScript 现在有了分组方法,所以你再也不必这样做 ...
- Spring源码之-AOP
目录 一.大话AOP 1.AOP的概念 2.必要的准备工作 什么是代理模式? 3.大话AOP 那么AOP 具体是什么呢? 实现AOP的方式 二.动态AOP自定义标签 1.JDK动态代理 2.CGLIB ...
- std::vector<std::string> 与 char** 的转换
vecotr 容器中插入多条字符串,再将 vector 的地址转换为 char** 代码如下: #include <stdio.h> #include <string> #in ...
- cronet 的简单学习
官方的解释 "Cronet is the networking stack of Chromium put into a library for use on mobile. This is ...
- Alpine安装gcc g++ make编译环境
apk add gcc g++ make cmake gfortran libffi-dev openssl-dev libtool
- rpm的一些命令
rpm -q xx #查询当前的包是否安装 rpm -qi xx # 查询当前包的详细信息 rpm -qpi 包文件路径 # 没装之前先查看包的信息 rpm -qpl 包文件路径 # 预计装上后会在系 ...
- 08-Redis系列之-Redis布隆过滤器,MySQL主从,Django读写分离
Redis实现布隆过滤器 前言 布隆过滤器使用场景 比如有如下几个需求: 原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中? 解决办法一:将10亿个号码存 ...
- 一: Mysql字符集问题
## Mysql 字符集问题 1 修改MySQL5.7字符集 1.1 修改步骤 在MySQL 8.0版本之前,默认字符集为 latin1 ,utf8字符集指向的是 utf8mb3 .网站开发人员在数据 ...
- Codeforces Round 113 (Div. 2)E. Tetrahedron(dp、递推)
目录 题面 链接 题意 题解 代码 总结 题面 链接 E. Tetrahedron 题意 从一个顶点出发走过路径长度为n回到出发点的方案总数 题解 考虑dp \(f[i][0|1|2|3]\):走了i ...
- [VueJsDev] 基础知识 - AutoNumber VsCode 插件开发
[VueJsDev] 目录列表 https://www.cnblogs.com/pengchenggang/p/17037320.html AutoNumber VsCode插件开发 ::: deta ...