使用Pandas和NumPy实现数据获取
以某城市地铁数据为例,通过提取每个站三个月15分钟粒度的上下客量数据,展示Pandas和Numpy的案例应用。
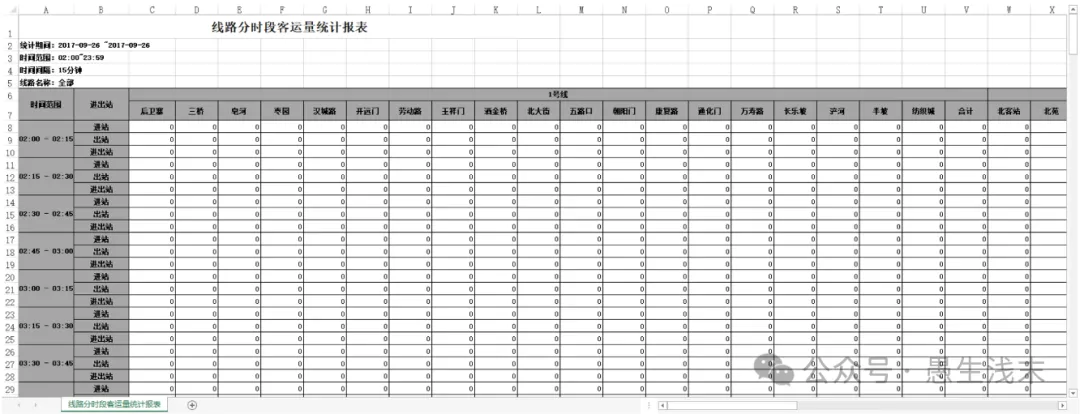
初步发现数据有三个特点::1、地铁数据的前五行是无效的,第七行给出了每个站点的名字;2、每个车站是按照15分钟粒度统计客流,给出了进站、出战、进出站客流;3、运营时间是从2:00-23:59,与地铁实际运营时间5:30-23:00不同,需要调整。
# 导入模块
import os
from pathlib import Path
import pandas as pd
import numpy as np
导入成功后,先获取目标文件夹下(data)的文件名,存入filenames变量中。
# 获取文件名
path = "./data"
filenames = os.listdir(path)
filenames
获取每个车站所对应的列号,确定pdd.read_excel(usecols)中usecols的参数
# 筛选掉 “合计”无用项,并设置target_col存储目标项
name = filenames[0]
f = "./data/" + name
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3)
tarr = file.values
print(tarr[3])
test = tarr[0]
target_col = []
for i in range(len(test)):
tmp = test[i]
if tmp != '合计':
target_col.append(i)
print(target_col)

获取车站名和车站编号:
# 获取车站名和车站编号
nfile = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arrt = nfile.values
stations_name = []
stations_index = []
for i in range(2,len(arrt[0])):
stations_index.append(i)
stations_name.append(arrt[0][i])
print(stations_name)
print(stations_index)

接下来定义两个函数,我们希望把所有的数据都写入两个文件夹,一个是”in.csv”存储每个站的进站数据,一个是”out.csv”存储每个站的出站数据。如果目标文件不存在,代码如下:
def process_not_exists(f):
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arr = file.values
# 构造一个字典先存储数据
d_in = {}
d_out = {}
for i in stations_index:
# 存储第i个车站的上下客流数据
d_in[i] = []
d_out[i] = []
# 5:30 之后的数据是从excel的50行开始,处理后的数据应从43行开始
for i in range(43,len(arr)):
l = arr[i] # 获取第i行的数据
# 通过条件直接筛选掉“进出站”
if l[1] == '进站':
# 进站处理
for j in range(2,len(l)):
d_in[j].append(l[j])
if l[1] == '出站':
# 出站处理
for j in range(2,len(l)):
d_out[j].append(l[j])
in_list = [] # 存储进站数据
out_list = [] # 存储出站数据
for key in d_in:
# d_in 与 d_out 的key均为车站的index
in_list.append(d_in[key])
out_list.append(d_out[key])
df_in = pd.DataFrame(in_list)
df_in.to_csv("./data/in.csv", header = True, index = None)
df_out = pd.DataFrame(out_list)
df_out.to_csv("./data/out.csv", header = True, index = None)
如果目标文件存在,读取部分与目标文件不存在时相同,在处理输出时要进行修改,代码如下:
# 目标文件存在时
def process_exists(f,target_file_in,target_file_out):
infile = pd.read_csv(target_file_in)
outfile = pd.read_csv(target_file_out)
in_arr = infile.values.tolist()
out_arr = outfile.values.tolist()
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arr = file.values
# 构造一个字典先存储数据
d_in = {}
d_out = {}
for i in stations_index:
# 存储第i个车站的上下客流数据
d_in[i] = []
d_out[i] = []
# 5:30 之后的数据是从excel的50行开始,处理后的数据应从43行开始
for i in range(43,len(arr)):
l = arr[i] # 获取第i行的数据
# 通过条件直接筛选掉“进出站”
if l[1] == '进站':
# 进站处理
for j in range(2,len(l)):
d_in[j].append(l[j])
if l[1] == '出站':
# 出站处理
for j in range(2,len(l)):
d_out[j].append(l[j])
in_list = [] # 存储进站数据
out_list = [] # 存储出站数据
for key in d_in:
# d_in 与 d_out 的key均为车站的index
in_list.append(d_in[key])
out_list.append(d_out[key])
#合并原有数据
for i in range(len(in_arr)):
in_arr[i] += in_list[i]
out_arr[i] += out_list[i]
# in_file
df_in = pd.DataFrame(in_arr)
df_in.to_csv("./data/in_test.csv",mode = 'r+', header = True, index = None)
# out_file
df_out = pd.DataFrame(out_arr)
df_out.to_csv("./data/out_test.csv",mode = 'r+', header = True, index = None)
对于DataFrame中的数据获取方法有两种:第一种为通过file.iloc[i,j]的方式定位第i行第j列的数据;第二种为通过file.values将file转换为ndarray的数据格式,由于可以事先知道数据每一列的具体含义,直接通过整数下标的方式访问数据。
代码中使用的是第二种方式,这是由于DataFrame的iloc[]函数访问效率低,当数据体量很大时,遍历整个表格的速度会非常慢,而将DataFrame转换为ndarray后,遍历整个表格的数据效率会有显著提升。
下面是主函数,即可完成所有数据的提取。
for name in filenames:
f = "./data/" + name
target_file_in = "./data/in_test.csv"
target_file_out = "./data/out_test.csv"
# 若文件已存在
if Path(target_file_in).exists() and Path(target_file_out).exists():
print("exist")
process_exists(f,target_file_in,target_file_out)
#break
else:
print("not exist")
process_not_exists(f)
print("done")
使用Pandas和NumPy实现数据获取的更多相关文章
- 数据分析之Pandas和Numpy学习笔记(持续更新)<1>
pandas and numpy notebook 最近工作交接,整理电脑资料时看到了之前的基于Jupyter学习数据分析相关模块学习笔记.想着拿出来分享一下,可是Jupyter导出来h ...
- Python Pandas与Numpy中axis参数的二义性
Stackoverflow.com是程序员的好去处,本公众号将以pandas为主题,开始一个系列,争取做到每周一篇,翻译并帮助pandas学习者一起理解一些有代表性的案例.今天的主题就是Pandas与 ...
- 用豆瓣加速安装pandas、numpy、matplotlib(画图)
安装pandas.numpy会同时被安装 #pthony2.x,用豆瓣加速安装pandas pip install -i https://pypi.doubanio.com/simple/ panda ...
- Pandas和Numpy的一些金融相关的操作(一)
Pandas和Numpy的一些金融相关的操作 给定一个净值序列,求出最大回撤 # arr是一个净值的np.ndarray i = np.argmax( (np.maximum.acumulate(ar ...
- 【强化学习】用pandas 与 numpy 分别实现 q-learning, saras, saras(lambda)算法
本文作者:hhh5460 本文地址:https://www.cnblogs.com/hhh5460/p/10159331.html 特别感谢:本文的三幅图皆来自莫凡的教程 https://morvan ...
- 利用pandas对numpy数组进行简单的科学计算
二维数组转换为DataFrame pandas可直接进行科学计算形式: import numpy as np import pandas as pd a = [1,2,3] b = [4,5,6] # ...
- 利用pandas将numpy数组导出生成excel
代码 # -*- coding: utf- -*- """ Created on Sun Jun :: @author: Bruce Lau ""&q ...
- ubuntu下python安装pandas和numpy等依赖库版本不兼容的问题RuntimeWarning: numpy.dtype size changed
习惯了linux下用pip install numpy及pip install pandas命令了.折腾了好久了. 上来先在python3中pip3 install numpy装了numpy,然后再p ...
- 利用pandas和numpy计算表中每一列的均值
import numpy as np import pandas as pd df = pd.DataFrame({'var1':np.random.rand(100), #生成100个0到1之间的随 ...
- Pandas 与 Numpy 常用方法总结
Lambda 函数实现 简单的说,lambda 就是一个函数,但是这个函数没有名字,所以我们介绍一下这个函数的调用形式,参数与返回值的实现. lambda 的格式如下: lambda [arg1 [, ...
随机推荐
- 跟我一起学习和开发动态表单系统-前端用vue、elementui实现方法(3)
基于 Vue.Element UI 和 Spring Boot + MyBatis 的动态表单系统前端实现解析 在现代企业信息系统中,动态表单是一种非常常见的功能.它可以根据业务需求灵活地调整表单结构 ...
- VUE手稿1
- SpringBoot 日志文件 logback-spring.xml
日志文件 将logback-spring.xml配置文件,放到:/src/main/resources中 <?xml version="1.0" encoding=" ...
- SQL Thinking
s2下半年我在内部有一次部门级别的技术分享会,以本文内容分享为主. 其实有很多人问过我相同的问题,遇到需要改写的慢sql,不知道怎么改,改好了以后也不知道等不等价?不等价了也不知道错在哪?这个要怎么破 ...
- [oeasy]python0132_[专业选修]utf-8_unicode_transformation_format_8_编码方式
utf-8 回忆上次内容 上次再次输出了大红心<span style="color:red"></span> 找到了红心对应的编码 黑红梅方都对应有编码 ...
- 用ssh同时push 项目到github和gitee的方法
分别为两个网站声称pubkey cd ./ssh ssh-keygen -t rsa -C "oeasy@oeasy.org" -f "github_id_rsa&q ...
- Jmeter函数助手22-V
V函数用于执行变量名.嵌套函数.类似eval函数 Name of variable (may include variable and function references):必填,填入变量名称或者 ...
- 如何配置docker pull代理
参考: https://blog.csdn.net/vic_qxz/article/details/130061661 经过验证确实有效.
- 如何在anaconda环境中安装cuda.h和cuda_runtime.h
在前面的文章(几年前的文章)中我们介绍了在anaconda中安装cuda.cudnn后,有介绍了如何在anaconda中安装nvcc.nccl等NVIDIA的各种编译器和库,本文介绍如何在anacon ...
- 如何在python同一应用下的多模块中共享变量
最近在考虑编码风格的问题,突然想到如何在一个python应用下的多个模块中共享一个变量.最早接触python还是在python2.5版本左右,那个时候由于python的import规则设定的问题导致本 ...