使用Pandas和NumPy实现数据获取
以某城市地铁数据为例,通过提取每个站三个月15分钟粒度的上下客量数据,展示Pandas和Numpy的案例应用。
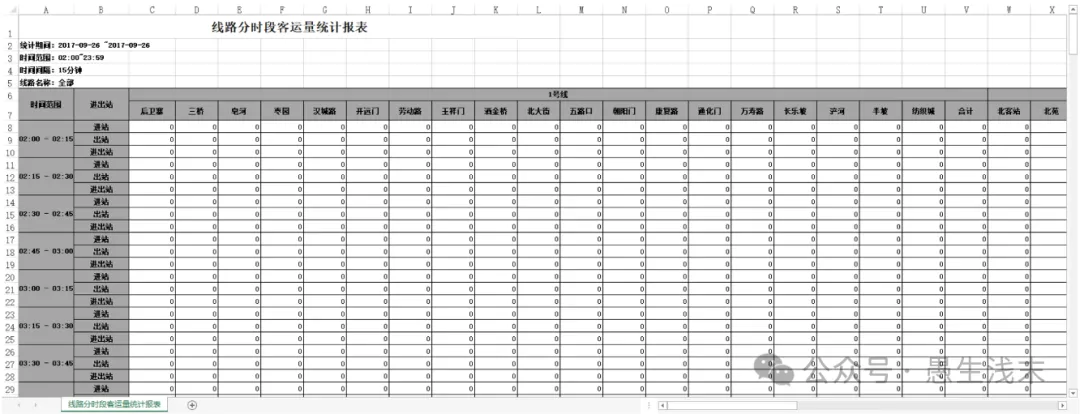
初步发现数据有三个特点::1、地铁数据的前五行是无效的,第七行给出了每个站点的名字;2、每个车站是按照15分钟粒度统计客流,给出了进站、出战、进出站客流;3、运营时间是从2:00-23:59,与地铁实际运营时间5:30-23:00不同,需要调整。
# 导入模块
import os
from pathlib import Path
import pandas as pd
import numpy as np
导入成功后,先获取目标文件夹下(data)的文件名,存入filenames变量中。
# 获取文件名
path = "./data"
filenames = os.listdir(path)
filenames
获取每个车站所对应的列号,确定pdd.read_excel(usecols)中usecols的参数
# 筛选掉 “合计”无用项,并设置target_col存储目标项
name = filenames[0]
f = "./data/" + name
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3)
tarr = file.values
print(tarr[3])
test = tarr[0]
target_col = []
for i in range(len(test)):
tmp = test[i]
if tmp != '合计':
target_col.append(i)
print(target_col)

获取车站名和车站编号:
# 获取车站名和车站编号
nfile = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arrt = nfile.values
stations_name = []
stations_index = []
for i in range(2,len(arrt[0])):
stations_index.append(i)
stations_name.append(arrt[0][i])
print(stations_name)
print(stations_index)

接下来定义两个函数,我们希望把所有的数据都写入两个文件夹,一个是”in.csv”存储每个站的进站数据,一个是”out.csv”存储每个站的出站数据。如果目标文件不存在,代码如下:
def process_not_exists(f):
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arr = file.values
# 构造一个字典先存储数据
d_in = {}
d_out = {}
for i in stations_index:
# 存储第i个车站的上下客流数据
d_in[i] = []
d_out[i] = []
# 5:30 之后的数据是从excel的50行开始,处理后的数据应从43行开始
for i in range(43,len(arr)):
l = arr[i] # 获取第i行的数据
# 通过条件直接筛选掉“进出站”
if l[1] == '进站':
# 进站处理
for j in range(2,len(l)):
d_in[j].append(l[j])
if l[1] == '出站':
# 出站处理
for j in range(2,len(l)):
d_out[j].append(l[j])
in_list = [] # 存储进站数据
out_list = [] # 存储出站数据
for key in d_in:
# d_in 与 d_out 的key均为车站的index
in_list.append(d_in[key])
out_list.append(d_out[key])
df_in = pd.DataFrame(in_list)
df_in.to_csv("./data/in.csv", header = True, index = None)
df_out = pd.DataFrame(out_list)
df_out.to_csv("./data/out.csv", header = True, index = None)
如果目标文件存在,读取部分与目标文件不存在时相同,在处理输出时要进行修改,代码如下:
# 目标文件存在时
def process_exists(f,target_file_in,target_file_out):
infile = pd.read_csv(target_file_in)
outfile = pd.read_csv(target_file_out)
in_arr = infile.values.tolist()
out_arr = outfile.values.tolist()
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arr = file.values
# 构造一个字典先存储数据
d_in = {}
d_out = {}
for i in stations_index:
# 存储第i个车站的上下客流数据
d_in[i] = []
d_out[i] = []
# 5:30 之后的数据是从excel的50行开始,处理后的数据应从43行开始
for i in range(43,len(arr)):
l = arr[i] # 获取第i行的数据
# 通过条件直接筛选掉“进出站”
if l[1] == '进站':
# 进站处理
for j in range(2,len(l)):
d_in[j].append(l[j])
if l[1] == '出站':
# 出站处理
for j in range(2,len(l)):
d_out[j].append(l[j])
in_list = [] # 存储进站数据
out_list = [] # 存储出站数据
for key in d_in:
# d_in 与 d_out 的key均为车站的index
in_list.append(d_in[key])
out_list.append(d_out[key])
#合并原有数据
for i in range(len(in_arr)):
in_arr[i] += in_list[i]
out_arr[i] += out_list[i]
# in_file
df_in = pd.DataFrame(in_arr)
df_in.to_csv("./data/in_test.csv",mode = 'r+', header = True, index = None)
# out_file
df_out = pd.DataFrame(out_arr)
df_out.to_csv("./data/out_test.csv",mode = 'r+', header = True, index = None)
对于DataFrame中的数据获取方法有两种:第一种为通过file.iloc[i,j]的方式定位第i行第j列的数据;第二种为通过file.values将file转换为ndarray的数据格式,由于可以事先知道数据每一列的具体含义,直接通过整数下标的方式访问数据。
代码中使用的是第二种方式,这是由于DataFrame的iloc[]函数访问效率低,当数据体量很大时,遍历整个表格的速度会非常慢,而将DataFrame转换为ndarray后,遍历整个表格的数据效率会有显著提升。
下面是主函数,即可完成所有数据的提取。
for name in filenames:
f = "./data/" + name
target_file_in = "./data/in_test.csv"
target_file_out = "./data/out_test.csv"
# 若文件已存在
if Path(target_file_in).exists() and Path(target_file_out).exists():
print("exist")
process_exists(f,target_file_in,target_file_out)
#break
else:
print("not exist")
process_not_exists(f)
print("done")
使用Pandas和NumPy实现数据获取的更多相关文章
- 数据分析之Pandas和Numpy学习笔记(持续更新)<1>
pandas and numpy notebook 最近工作交接,整理电脑资料时看到了之前的基于Jupyter学习数据分析相关模块学习笔记.想着拿出来分享一下,可是Jupyter导出来h ...
- Python Pandas与Numpy中axis参数的二义性
Stackoverflow.com是程序员的好去处,本公众号将以pandas为主题,开始一个系列,争取做到每周一篇,翻译并帮助pandas学习者一起理解一些有代表性的案例.今天的主题就是Pandas与 ...
- 用豆瓣加速安装pandas、numpy、matplotlib(画图)
安装pandas.numpy会同时被安装 #pthony2.x,用豆瓣加速安装pandas pip install -i https://pypi.doubanio.com/simple/ panda ...
- Pandas和Numpy的一些金融相关的操作(一)
Pandas和Numpy的一些金融相关的操作 给定一个净值序列,求出最大回撤 # arr是一个净值的np.ndarray i = np.argmax( (np.maximum.acumulate(ar ...
- 【强化学习】用pandas 与 numpy 分别实现 q-learning, saras, saras(lambda)算法
本文作者:hhh5460 本文地址:https://www.cnblogs.com/hhh5460/p/10159331.html 特别感谢:本文的三幅图皆来自莫凡的教程 https://morvan ...
- 利用pandas对numpy数组进行简单的科学计算
二维数组转换为DataFrame pandas可直接进行科学计算形式: import numpy as np import pandas as pd a = [1,2,3] b = [4,5,6] # ...
- 利用pandas将numpy数组导出生成excel
代码 # -*- coding: utf- -*- """ Created on Sun Jun :: @author: Bruce Lau ""&q ...
- ubuntu下python安装pandas和numpy等依赖库版本不兼容的问题RuntimeWarning: numpy.dtype size changed
习惯了linux下用pip install numpy及pip install pandas命令了.折腾了好久了. 上来先在python3中pip3 install numpy装了numpy,然后再p ...
- 利用pandas和numpy计算表中每一列的均值
import numpy as np import pandas as pd df = pd.DataFrame({'var1':np.random.rand(100), #生成100个0到1之间的随 ...
- Pandas 与 Numpy 常用方法总结
Lambda 函数实现 简单的说,lambda 就是一个函数,但是这个函数没有名字,所以我们介绍一下这个函数的调用形式,参数与返回值的实现. lambda 的格式如下: lambda [arg1 [, ...
随机推荐
- P6626 题解
有一个很暴力的解法,就是以询问点为根 DFS. 考虑优化,我们考虑优化换根. 当根节点从父亲移动到它的某个孩子时,孩子的子树内所有点深度减 \(1\) 其余点深度加 \(1\). 同理,当根节点从某个 ...
- 韦东山freeRTOS系列教程之【第九章】任务通知(Task Notifications)
目录 系列教程总目录 概述 9.1 任务通知的特性 9.1.1 优势及限制 9.1.2 通知状态和通知值 9.2 任务通知的使用 9.2.1 两类函数 9.2.2 xTaskNotifyGive/ul ...
- SpringCloud 微服务简介
一.认识微服务随着互联网行业的发展,对服务的要求也越来越高,服务架构也从单体架构逐渐演变为现在流行的微服务架构.这些架构之间有怎样的差别呢? 1.单体架构:将业务的所有功能集中在一个项目中开发,打成一 ...
- tp6 uniapp跨越问题
自己写一个简单的中间件
- oeasy教您玩转vim - 13 - # 大词小词
大词小词 回忆上节课内容 我们上次学习了 e e 代表 end 词尾 自有跳跃 还可以成倍次数的跳跃 但其实我是想以一个一个属性地跳跃,有没有方法呢? 查询帮助 没思路的话我们还是得继续查询 :h w ...
- Pandas库学习笔记(1)
参考:菜鸟教程 pandas库使用了NumPy的大多数功能.建议您先阅读有关NumPy的教程,然后再继续本教程. Pandas 适用于处理以下类型的数据: 与 SQL 或 Excel 表类似的,含异构 ...
- Ubuntu 20.04 双系统安装完整教程
1.查看电脑的信息 1.1 查看BIOS模式 "win+r"快捷键进入"运行",输入"msinfo32"回车,出现以下界面,可查看BIOS模 ...
- 11、Git之自建项目托管平台(GitLab极狐)
11.1.简介 Github 是国外的项目托管平台,由于网络问题,在国内访问和使用不是很方便. Gitee 是国内的项目托管平台,虽然在访问和使用上挺方便的,但依然让人担忧项目代码可能会被泄露. 因此 ...
- 【HTML】hr标签 分割线 自定义样式
参考: https://blog.csdn.net/weixin_40716682/article/details/90064473 默认是有边框线的 删除边框线,设置高度和背景色即可 backgro ...
- 【Mybatis-Plus】04 AR (Active Record)
AR模式,全称激活记录 具体操作更接近Hibernate一样的OOP操作方式影响数据库记录 比Hibernate操作更灵活更方便 上手: 首先User实体类需要继承Model类并泛型注入User类型 ...