【论文笔记】ResNet深度残差网络
【深度学习】总目录
深度残差网络(ResNet)由微软研究院的何恺明、张祥雨、任少卿、孙剑提出。研究动机是为了解决深度网络的退化问题,不同于过去的网络是通过学习去拟合一个分布,ResNet通过学习去拟合相对于上一层输出的残差。实验表明,ResNet能够通过增加深度来提升性能,而且易于优化,参数量更少,在许多常用数据集上有非常优秀的表现。ResNet 在2015 年的ILSVRC中取得了冠军。
论文链接:ResNet Deep Residual Learning for Image Recognition
1 Motivation
深度卷积网络整合了特征层和分类层进行端到端的训练,堆叠的层数越多,提取的特征越丰富。许多非凡的视觉识别任务都得益于非常深(16-30层)的网络。堆叠的层数越多网络学习的效果越好吗?并不是,如下图所示,56层的网络再训练集和测试集上的表现都不如20层的网络。

- 梯度消失/爆炸会影响梯度的收敛。但是,权重的初始化,以及中间的归一化层已经很大程度上解决了梯度问题,使得网络能够收敛。这种退化不是梯度消失/爆炸导致的。
- 过拟合是训练误差很小,而测试误差很大,这种退化也不是过拟合导致的。
对于退化问题,既然浅层网络的性能优于深度网络,那么不妨做这样的一个假设:有一个浅层网络和一个对应的深层网络,深层网络就是在浅层网络后面多加了几层。深层网络的效果是不应该比浅层的差的,当前面的层是已经学好的浅层网络,而添加的层都是恒等映射。但是,事实证明找不到这样一个看上去比较优的解。即实际上较深模型后面添加的不是恒等映射,而是一些非线性层。因此,退化问题也表明了:通过多个非线性层来近似恒等映射可能是困难的。
2 Architectural Details
Residual Learning
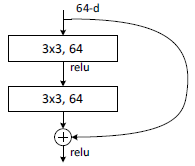
论文引入深度残差学习框架来解决网络退化问题。让新堆叠的层直接拟合残差取代拟合底层映射,用H(x)表示所需的底层映射,利用堆叠的非线性层拟合F(x)=H(x)-x,原始映射将被重铸为F(x)+x。当输入已经足够好,残差块输出为0。这种恒等映射可以被看作是神经网络的shortcut,它不会增加参数和计算复杂度,用常规的库就可以简单地实现。
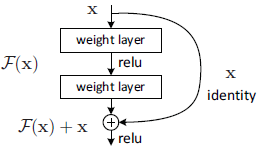
残差结构比正常的结构多了右侧的曲线,这个曲线也叫作shortcut connection,通过跳接在激活函数前,将上一层(或几层)的输出与本层输出相加,将求和的结果输入到激活函数作为本层的输出。
Identity vs. Projection Shortcuts.
短接有三种方法(A)升维时补零填充,所有的短接都不会增加参数(B)升维时利用1×1的卷积投影,维度相同时使用Identity (C) 所有短接都用投影
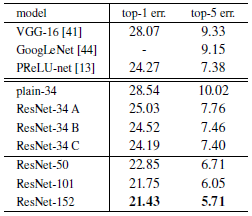
从上图可以看出,C的效果最好,我们将其归因于额外的参数。A/B/C的微小不同表明了,投影并不是解决网络退化问题的关键,因此为了减少计算复杂度和模型的尺寸,我们不用C,用B。
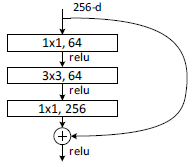
Deeper Bottleneck Architectures.
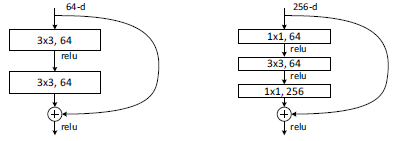
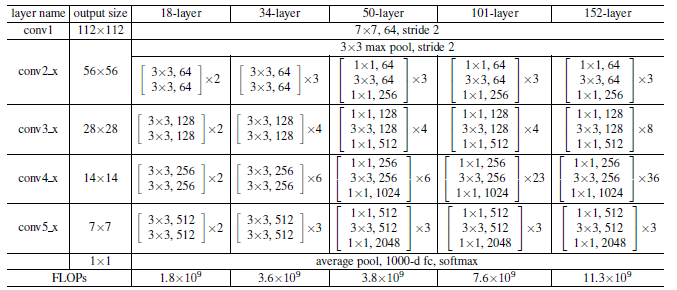
对于更深的网络,我们引入bottleneck的设计。下图左边为34-layer网络的一个block,右边为bottleneck block。当输入为m×m×256,像左边一样做两个3×3的卷积,计算复杂度为64-d时的16倍,计算量为m×m×256×3×3×256×2。而先利用1×1的卷积降维再做一个3×3的卷积,再升维,计算量为m×m×256×1×1×64+m×m×64×3×3×64+m×m×64×1×1×256,和之前的64-d的计算量差不多。因为bottleneck的设计,50-layer的网络,虽然通道数增加了4倍,但是计算量差不多。
3 ResNet网络架构
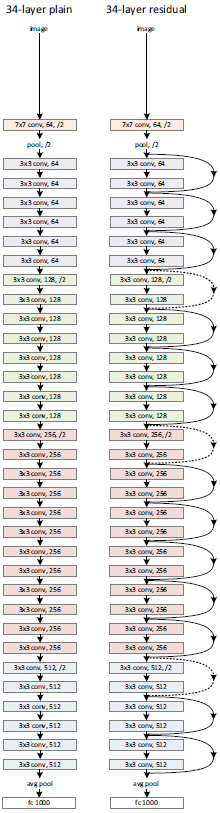
左边为Plain Networks,遵循两个设计原则:(1)每个block内filter个数不变(不同颜色表示不同的block) (2)feature map大小减半时,filter个数加倍。VGG中用池化下采样,我们用步长为2的卷积执行下采样,同时用全局平均池化代替全连接(更少的参数量和计算量,防止过拟合),最后接softmax。
右边为残差网络,在Plain Networks的基础上增加shortcut。当输入和输出维度一样时,可以直接相加。当维度增加(残差分支出现下采样)时,(A)对多出来的通道补零填充(B)利用1×1的卷积升维。不管采取哪种方案,第一个卷积用的都是步长为2的卷积。

从上图可以看出:
- 粗的线条时验证集上的,细的线条是训练集误差。一开始训练集的误差要比验证集上大,因为做了一些数据增强,噪声比较大。
- 有残差的网络收敛要快一些。
- 没有残差的网络,18-layer的误差比34-layer少,而有残差的网络,34-layer的误差小于18-layer。
事实证明:(1)深度残差网络易于优化,而对应的plain网络随着网络的加深错误率增加。(2)深度残差网络随着深度增加准确率也会增加。
为什么ResNet训的动,训的快?
假设原始网络输出为g(x),在此基础上再加一些层,输出变为f(g(x)),对它进行求导df(g(x))/dx=df(g(x))/dg(x)·dg(x))/dx。新加的层数越多,矩阵的乘法就越多,因为梯度比较小,乘来乘去就变为0了,也就是梯度消失。但是如果加了ResNet,此时输出为f(g(x))+g(x),对它进行求导df(g(x))/dx+dg(x))/dx,df(g(x))/dx很小没有关系,来自浅层网络的dg(x))/dx相对来说会大一些。
4 代码
Block实现
class BasicBlock(nn.Module):
scale = 1 def __init__(self, in_channels, out_channels, stride=1, downsample=False):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
# -------------------------------------------------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# -------------------------------------------------------------------------------
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, stride=2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.downsample = downsample def forward(self, x):
identity = x
if self.downsample:
identity = self.conv(x)
x = self.relu(self.bn1(self.conv1(x)))
x = self.bn2(self.conv2(x))
x = x + identity
return self.relu(x)
18层和34层的ResNet用的普通的block:
- 当输入层数和输出层数不一样时,要对右边的shortcut进行1×1卷积的升维(下采样),在conv3_x,conv4_x,con5_x的第一个block都需要进行升维
- 升维后不需要relu,但需要bn层
- 在每个block内通道数不会改变,所以scale为1
- 卷积后都有bn层,所以bias=False
Bottleneck实现
class Bottleneck(nn.Module):
scale = 4 def __init__(self, in_channels, out_channels, stride=1, downsample=False):
super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
# ------------------------------------------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# ------------------------------------------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels * self.scale,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.scale)
# -------------------------------------------------------------------------
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels * self.scale,
kernel_size=1, stride=stride, bias=False)
self.bn = nn.BatchNorm2d(out_channels * self.scale)
self.downsample = downsample
# -------------------------------------------------------------------------
self.relu = nn.ReLU(inplace=True) def forward(self, x):
identity = x
if self.downsample:
identity = self.conv(x)
x = self.relu(self.bn1(self.conv1(x)))
x = self.relu(self.bn2(self.conv2(x)))
x = self.bn3(self.conv3(x))
x = x + identity
return x
- 每个block的第一个卷积核的个数和最后卷积核的个数都相差四倍,scale=4
- 在conv3_x,conv4_x,con5_x的第一个block都需要下采样,因此在block中的第二个卷积中stride=2
- 在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,这么做的好处是能够在top1上提升大概0.5%的准确率。
Block重复叠加
def make_layers(self, block, block_number, channels, stride):
layers = []
downsample = False
if self.inchannels != channels * block.scale:
downsample = True
layers.append(block(self.inchannels, channels, stride, downsample))
for i in range(1, block_number):
layers.append(block(channels * block.scale, channels, 1, False))
self.inchannels = channels * block.scale
return nn.Sequential(*layers)
block:在ResNet18中用BasicBlock,在ResNet18中用Bottleneck
block_number:block重复的次数
channels:每个block中第一个卷积核的个数,channels*scale就是该block的输出通道数
stride:在conv2_x的stride为1,其余都为2
5 迁移学习
1. 下载预训练模型
import torchvision.models.resnet,点击resnet进入,链接如下
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-f37072fd.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-b627a593.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-0676ba61.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-63fe2227.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-394f9c45.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
2.读取预训练模型,将全连接层的输出改为想要的类别数
model = resnet34()
model.load_state_dict(torch.load("resnet34-b627a593.pth"),strict=False)
inchannel = model.fc.in_features
model.fc = nn.Linear(inchannel,2)
【论文笔记】ResNet深度残差网络的更多相关文章
- Resnet——深度残差网络(一)
我们都知道随着神经网络深度的加深,训练过程中会很容易产生误差的积累,从而出现梯度爆炸和梯度消散的问题,这是由于随着网络层数的增多,在网络中反向传播的梯度会随着连乘变得不稳定(特别大或特别小),出现最多 ...
- Resnet——深度残差网络(二)
基于上一篇resnet网络结构进行实战. 再来贴一下resnet的基本结构方便与代码进行对比 resnet的自定义类如下: import tensorflow as tf from tensorflo ...
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
- Dual Path Networks(DPN)——一种结合了ResNet和DenseNet优势的新型卷积网络结构。深度残差网络通过残差旁支通路再利用特征,但残差通道不善于探索新特征。密集连接网络通过密集连接通路探索新特征,但有高冗余度。
如何评价Dual Path Networks(DPN)? 论文链接:https://arxiv.org/pdf/1707.01629v1.pdf在ImagNet-1k数据集上,浅DPN超过了最好的Re ...
- 深度残差网络(DRN)ResNet网络原理
一说起“深度学习”,自然就联想到它非常显著的特点“深.深.深”(重要的事说三遍),通过很深层次的网络实现准确率非常高的图像识别.语音识别等能力.因此,我们自然很容易就想到:深的网络一般会比浅的网络效果 ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 关于深度残差网络(Deep residual network, ResNet)
题外话: From <白话深度学习与TensorFlow> 深度残差网络: 深度残差网络的设计就是为了克服这种由于网络深度加深而产生的学习效率变低,准确率无法有效提升的问题(也称为网络退化 ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 深度残差网络(ResNet)
引言 对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多.当然收敛速度也就越慢,训练时间越长,然而深度到了一定程度之后就会发现越往深学习率越低的情况,甚至在一些场景下,网络层数越深反而降低了 ...
- [DeeplearningAI笔记]卷积神经网络2.3-2.4深度残差网络
4.2深度卷积网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 [残差网络]--He K, Zhang X, Ren S, et al. Deep Residual Learni ...
随机推荐
- HarmonyOS 性能优化
如何合理使用动效来获得更好的性能 组件转场动画使用 transition: 推荐使用转场动画(transition)而不是组件动画(animateTo),因为 transition 只需要在条件改变时 ...
- modbus通信案例简单介绍
介绍: 1.仪表等其他智能设备的modbus通信协议,确定其内部功能码地址.以型号U-MIK-P350-SCN2的杭州美控公司的压力变送器为例.查看对应手册20页.2.PLC端的编程配置.以西门子s7 ...
- 解析 RocketMQ 业务消息--“顺序消息”
简介: 本篇将继续业务消息集成的场景,从功能原理.应用案例.最佳实践以及实战等角度介绍 RocketMQ 的顺序消息功能. 作者:绍舒 引言 Apache RocketMQ 诞生至今,历经十余年大 ...
- dotnet 统信 UOS 运行 UNO FrameBuffer 应用错误 Failed to open FrameBuffer device
本文记录在 UOS 统信系统上运行 UNO 的基于 Skia 的 FrameBuffer 应用报错问题,错误提示是 Unhandled exception. System.InvalidOperati ...
- 2019-10-14-云之幻-UWP-视频教程
title author date CreateTime categories 云之幻 UWP 视频教程 lindexi 2019-10-14 21:8:26 +0800 2019-10-14 21: ...
- 如何拥有自己的专属GPT-本地部署目前最强大模型llama3
你是不是苦于没法使用ChatGPT?或者访问了ChatGPT却没法使用GPT4?现在一切问题都可以解决了! 4月18日,Meta发布两款开源Llama 3 8B与Llama 3 70B模型,供外部开发 ...
- 使用组合逻辑电路驱动VGA显示器
使用组合逻辑电路驱动VGA显示器 1. 概述 本文讲述一种不使用缓冲存储器驱动VGA显示的简单方法.其中,VGA分辨率采用DE10-Lite建议使用的640X480.像素的时钟25MHz,刷新率59. ...
- vue的三种组件传值方式
一.父传子 1.在父组件引入的子组件标签内给需要传递的值自定义名称 <AlertSzs :abc='gameType'></AlertSzs> 2.在子组件内用props接收 ...
- arduino uno+LCD12864(ST7735S)+蓝牙模块实现贪吃蛇
1.前言: 1.1本实验实现的贪吃蛇能穿越边界,结束游戏的唯一条件是贪吃蛇到达指定长度 1.2本实验所用LCD可能不是LCD12864,LCD12864所用库为u8glib,笔者在词库中并没有找到型号 ...
- OpenCV计算机视觉入门之图像色彩空间转换
目录 1. 引言 2. 概念 2.1 数字图像 2.2 色彩空间 3. 实践-图像读取 5. 完整代码 6. 总结 1. 引言 本文通过导入函数库.读取图像.转换图像色彩空间.缩放图像和保存图像五个步 ...