Python多进程共享numpy 数组
引用:https://zhuanlan.zhihu.com/p/32513483
共享 numpy 数组
需要用到 numpy 时往往是数据量较大的场景,如果直接复制会造成大量内存浪费。共享 numpy 数组则是通过上面一节的 Array 实现,再用 numpy.frombuffer 以及 reshape 对共享的内存封装成 numpy 数组,代码如下:
# encoding:utf8
import ctypes
import os
import multiprocessing import numpy as np NUM_PROCESS = multiprocessing.cpu_count() def worker(index):
main_nparray = np.frombuffer(shared_array_base, dtype=ctypes.c_double)
main_nparray = main_nparray.reshape(NUM_PROCESS, 10)
pid = os.getpid()
main_nparray[index, :] = pid
return pid if __name__ == "__main__":
shared_array_base = multiprocessing.Array(
ctypes.c_double, NUM_PROCESS * 10, lock=False)
pool = multiprocessing.Pool(processes=NUM_PROCESS)
result = pool.map(worker, range(NUM_PROCESS))
main_nparray = np.frombuffer(shared_array_base, dtype=ctypes.c_double)
main_nparray = main_nparray.reshape(NUM_PROCESS, 10)
print( main_nparray )
运行结果:

===============================================================
多进程共享较大数据,如numpy数组的情况下我们需要使用multiprocessing下面的Value , Array从而实现多进程的共享,但是还有一个重要的问题就是数据的读写方式,由于CPython是在语言的数据结构上进行再次包装的,所以对于数据的读写是需要进行翻译的,也就是说对数据读写是需要对Python数据类型下对应的C类型的数据结构进行读写的,也正是因为这种数据读写方式所以对Python数据进行操作要比对C类型数据进行读写操作要慢上很多。
numpy数据的底层同样也是C类型的数据结构,同时numpy下面的数据操作很多都是可以直接对numpy类型下的底层数据结构来操作的,这样也就会省掉数据结构转换的时间花销,只要不把numpy数据转为Python类型数据,都是可以在numpy下对底层数据进行直接操作的。
虽然mulprocessing模块提供了共享数据类型,但是不同进程对共享数据的读写本身也会存在数据类型的转换。
用更直接的话来说,虽然mutprocessing提供了共享数据类型Value和Array,但是不同进程其实也是无法直接对其进行操作的,子进程如果要读取或写入共享数据Value和Array就需要将共享数据转为可以进行操作的Python数据类型或numpy数据类型,否则就难以直接对共享数据进行直接操作,这时候numpy.frombuffer函数就派上用场了,numpy.frombuffer函数可以直接读取Python数据类型、numpy数据类型和共享数据类型的底层数据类型,即C数据类型,这样的话使用numpy.frombuffer函数就会省去数据类型转换这一环节。numpy.frombuffer可以直接读取共享数据类型Value和Array,因为Value和Array的底层实现就是C数据类型。
下面给出几种多进程共享数据的读写方式代码,以验证最佳的多进程大数据量数据的共享方式。
运行环境介绍:
软件:Ubuntu18.04系统、python3.7.5
硬件:intel i7-8700 cpu,6物理核心12逻辑核心
1. 使用multiprocessing.Value / multiprocessing.Array + numpy.frombuffer方式:
(使用numpy.frombuffer 对数据的读写不需要类型的转换可以直接对数据进行读写操作)


import ctypes
import time
import multiprocessing
import numpy as np NUM_PROCESS = multiprocessing.cpu_count() size = 1000000 def worker(index):
main_nparray = np.frombuffer(shared_array_base[index], dtype=ctypes.c_double)
for i in range(10000):
main_nparray[:] = index + i
return index if __name__ == "__main__":
shared_array_base = []
for _ in range(NUM_PROCESS):
shared_array_base.append(multiprocessing.Array("d", size, lock=False)) pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b-a)
#print(result) for i in range(NUM_PROCESS):
main_nparray = np.frombuffer(shared_array_base[i], dtype=ctypes.c_double)
print(main_nparray)
print(type(main_nparray))
print(main_nparray.shape) # 73.216189146
# 73.2605750561
# 73.3307318687
# 73.4090409279
# 73.4219110012
运行时间:
73.216189146
73.2605750561
73.3307318687
73.4090409279
73.4219110012
运行过程中各进程CPU使用率情况:
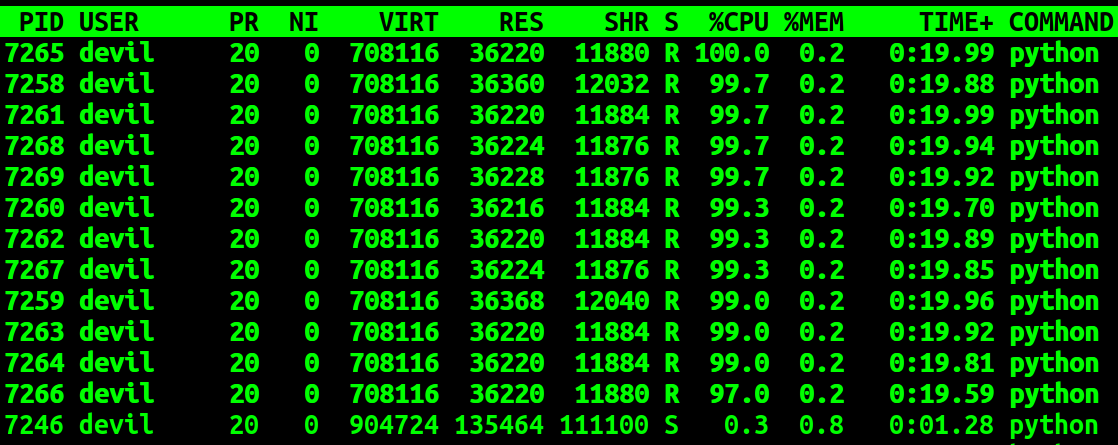
可以看到在运行过程中12个子进程的使用率为100%,而主进程的使用率为0.3%,可以看到使用 multiprocessing.Value / multiprocessing.Array + numpy.frombuffer 的方式各子进程在读写共享空间内容基本是不需要太多等待的,可以保证子进程基本以全速进行运行,而且主进程基本不参与计算(cpu利用率:0.3%)。也就是说采用该种方式各子进程操作父进程中的共享数据可以和操作自身进程空间内的数据达到基本一致的速度,为证明给出下面代码:
import multiprocessing import numpy as np NUM_PROCESS = multiprocessing.cpu_count() size = 1000000
def worker(index):
main_nparray = np.zeros(size)
for i in range(10000):
main_nparray[:] = index + i
return index if __name__ == "__main__":
pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b-a)
运行时间:
73.0335
73.2103
73.1925
73.1642
73.2643
也就是说使用该种方式,各子进程对父进程中的共享内存的操作其性能与操作自己进程空间下内存基本一致,没有什么性能损耗。
=======================================================================
2. 使用multiprocessing.Manger方式:
(共享数据,隐式的、自动的进行数据类型的转换)
from multiprocessing import Process, Manager
import multiprocessing
import numpy as np
import time NUM_PROCESS = multiprocessing.cpu_count()
size = 1000000 def worker(index):
shared_array_base[index][0] = np.zeros(shape=size)
shared_array_base[index][0] += index
for i in range(10000):
shared_array_base[index][0] += 1
#1246.2459
#1226.7996
#1238.3933
#1241.1819
#print(shared_array_base[index][0])
return index if __name__ == '__main__':
shared_array_base = []
manager = Manager() # 字典方式
for _ in range(NUM_PROCESS):
shared_array_base.append(manager.dict()) pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b - a) for index in range(NUM_PROCESS):
print(shared_array_base[index][0])
运行时间:
1246.2459
1226.7996
1238.3933
1241.1819
1241.2889
运行时个子进程CPU利用率:
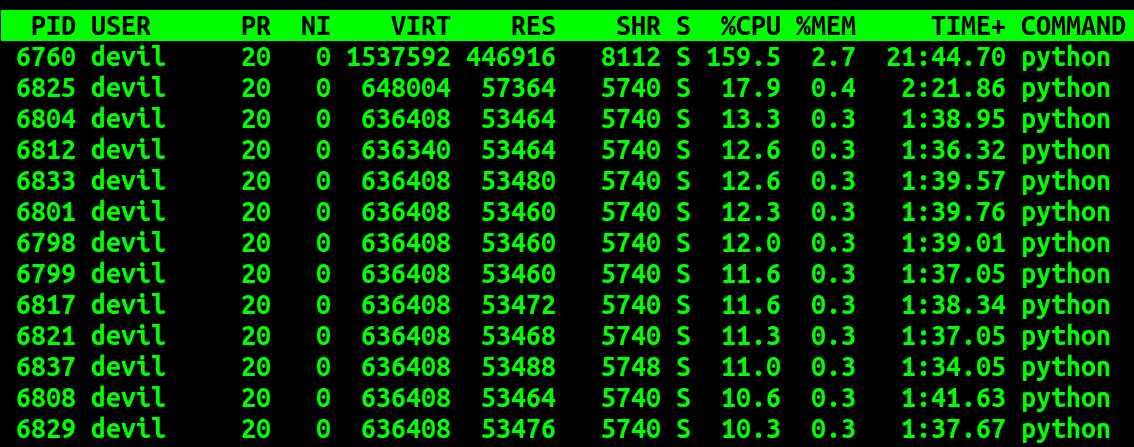
可以看到使用Manger的方式虽然可以实现共享内存的操作,但是该种方式需要父进程进行参与,随着子进程数量的增多父进程的负担也就越重,同时各子进程需要等待的时间也就越多。从运行时间上可以看到使用Manger的方式对共享内存进行操作整体性能下降了十多倍,其性能远低于Value/Array+numpy.frombuffer方式。
使用Manger方式对共享内存的操作是需要父进程参与的,这一点和Value/Array方式不同,同时使用Manger方式各子进程需要对共享数据进行类型转换而这又进一步的影响性能表现。
如果上面代码修改为:
#encoding:UTF-8
from multiprocessing import Process, Manager
import multiprocessing
import numpy as np
import time NUM_PROCESS = multiprocessing.cpu_count()
#NUM_PROCESS = 1 #125.9360 125.2017 118.3942 133.9661 99.3769 118.5580
size = 1000000 def worker(index):
shared_array_base[index][0] = np.zeros(shape=size)
shared_array_base[index][0] += index
for i in range(10000):
shared_array_base[index][0][:] = index+i #wrong result
###shared_array_base[index][0] += 1
#1246.2459
#1226.7996
#1238.3933
#1241.1819
#1241.2889
#print(shared_array_base[index][0])
return index if __name__ == '__main__':
shared_array_base = []
manager = Manager() # 字典方式
for _ in range(NUM_PROCESS):
shared_array_base.append(manager.dict()) pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b - a) for index in range(NUM_PROCESS):
print(shared_array_base[index][0])
运行结果:
672.297180891037
[0. 0. 0. ... 0. 0. 0.]
[1. 1. 1. ... 1. 1. 1.]
[2. 2. 2. ... 2. 2. 2.]
[3. 3. 3. ... 3. 3. 3.]
[4. 4. 4. ... 4. 4. 4.]
[5. 5. 5. ... 5. 5. 5.]
[6. 6. 6. ... 6. 6. 6.]
[7. 7. 7. ... 7. 7. 7.]
[8. 8. 8. ... 8. 8. 8.]
[9. 9. 9. ... 9. 9. 9.]
[10. 10. 10. ... 10. 10. 10.]
[11. 11. 11. ... 11. 11. 11.]
运行时CPU使用率:
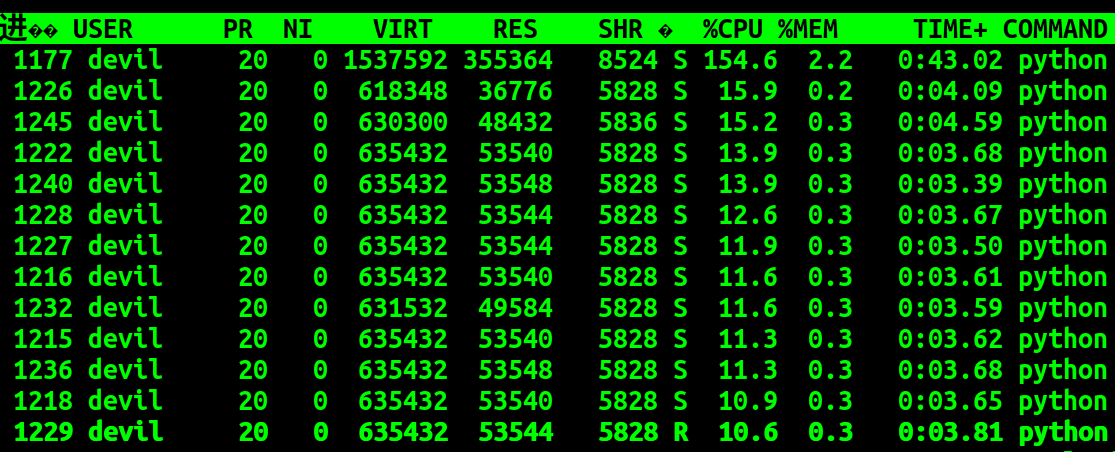
可以看到:
语句:
shared_array_base[index][0] += index
可以实现对共享内存的写操作。
语句:
shared_array_base[index][0][:] = index+i #wrong result
并不能实现对共享内存的写操作。
而即使不对共享内存进行写操作其运行时间也只是缩减了一半,与Value/Array+numpy.frombuffer方式相比使用Manager的方式操作共享内存即使是只进行读操作也是一种很耗费父进程计算资源的事情。使用Manager的方式各子进程读取共享内存中的数据也是需要对共享数据进行格式转换的,而这部分工作也是需要父进程参与的,因此使用Manager的方式并不能达到较好的性能表现。
如果使用单子进程的话:
代码:
#encoding:UTF-8
from multiprocessing import Process, Manager
import multiprocessing
import numpy as np
import time #NUM_PROCESS = multiprocessing.cpu_count()
NUM_PROCESS = 1 #125.9360 125.2017 118.3942 133.9661 99.3769 118.5580
size = 1000000 def worker(index):
shared_array_base[index][0] = np.zeros(shape=size)
shared_array_base[index][0] += index
for i in range(10000):
shared_array_base[index][0] += 1
#1246.2459
#1226.7996
#1238.3933
#1241.1819
#1241.2889
#print(shared_array_base[index][0])
return index if __name__ == '__main__':
shared_array_base = []
manager = Manager() # 字典方式
for _ in range(NUM_PROCESS):
shared_array_base.append(manager.dict()) pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b - a) for index in range(NUM_PROCESS):
print(shared_array_base[index][0])
运行时间:
125.9360
125.2017
118.3942
133.9661
99.3769
118.5580
123.2825
运行时cpu使用率:

这充分说明子进程对父进程的共享内存进行读写操作是需要父进程参与的,而这部分需要父进程参与的工作就是共享内存数据的类型转换工作。随着子进程数量的增加会加重父进程的负担,从而导致各子进程均难以获得较好的性能表现。
=========================================================================
3. 只使用multiprocessing.Value / multiprocessing.Array 方式:
(共享数据,使用中间数据进行操作后再直接赋值给共享数据:因为没有进行数据类型转换的共享数据难以直接进行读写操作)
代码:
import numpy as np
import multiprocessing
import time
import ctypes NUM_PROCESS = multiprocessing.cpu_count() size = 1000000 def worker(index):
temp = shared_array_base[index]
temp2 = np.zeros(size)+index for i in range(100*100):
temp2 += 1
temp[:] = temp2[:]
###2129.3716
###2253.2248
###2127.4056
###2128.4252 return index if __name__ == '__main__':
shared_array_base = []
for _ in range(NUM_PROCESS):
shared_array_base.append(multiprocessing.Array(ctypes.c_double, size, lock=False)) pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b-a) for i in range(NUM_PROCESS):
main_nparray = np.frombuffer(shared_array_base[i], dtype=ctypes.c_double)
print(main_nparray)
print(type(main_nparray))
print(main_nparray.shape)
运行时间:
2129.3716
2253.2248
2127.4056
2128.4252
运行时CPU使用率:
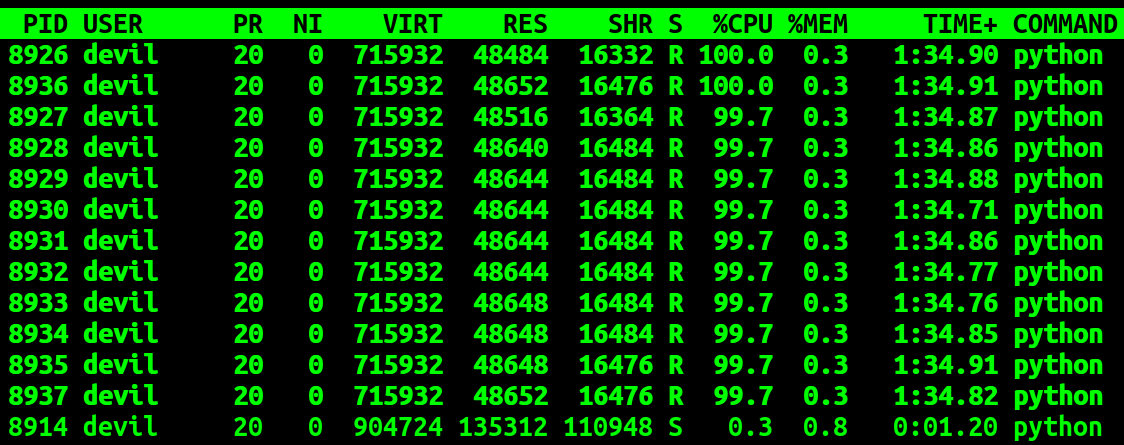
为估计该种形式下读写共享数据的耗时,给出下面代码:
import numpy as np
import multiprocessing
import time
import ctypes NUM_PROCESS = multiprocessing.cpu_count() size = 1000000 def worker(index):
temp = shared_array_base[index]
temp2 = np.zeros(size)+index for i in range(100*100):
temp2 += 1
###temp[:] = temp2[:]
###2129.3716
###2253.2248
###2127.4056
###2128.4252 return index if __name__ == '__main__':
shared_array_base = []
for _ in range(NUM_PROCESS):
shared_array_base.append(multiprocessing.Array(ctypes.c_double, size, lock=False)) pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b-a) for i in range(NUM_PROCESS):
main_nparray = np.frombuffer(shared_array_base[i], dtype=ctypes.c_double)
print(main_nparray)
print(type(main_nparray))
print(main_nparray.shape)
运行时间:
75.1454
75.0409
75.0613
74.9661
75.3398
74.6730
从上面的代码的运行时间上我们可以看出如果我们只使用multiprocessing.Value / multiprocessing.Array而不使用numpy.frombuffer函数的话也难以取得很好的性能表现,其中对共享数据的读写耗时大致需要2000秒以上,也就是说对共享数据的读操作如果不使用numpy.frombuffer的方式直接对数据底层进行操作,而是进行手动的类型转换,其耗时是巨大的,而如果使用nump.frombuffer的方式对共享数据进行读写其耗时是几乎可以不计的。同时我们也可以看到使用multiprocessing.Value / multiprocessing.Array方式子进程对父进程的共享数据进行读写操作是不需要父进程参与的,其中读写共享数据时进行的数据类型转换的工作都是在子进程内进行的。
同时可以看到如果不使用numpy.frombuffer方式直接对共享数据底层操作而是进行数据转换的话,Manager的方式要比手动转换性能高。
=================================================
最终结论就是在Python中如果多进程对共享内存操作的话,最佳性能的实现是使用multiprocessing.Value / multiprocessing.Array + numpy.frombuffer方式 。
以上功能使用Structure结构编写:
import time
import ctypes
from ctypes import *
import multiprocessing
import numpy as np NUM_PROCESS = multiprocessing.cpu_count()
size = 1000000 class Test(Structure):
pass Test._fields_ = [(str(i), c_double*(size)) for i in range(NUM_PROCESS)] data = multiprocessing.Value(Test, lock=False) # all zero init def worker(index):
main_nparray = np.frombuffer(data, 'd', size, index*size*sizeof(ctypes.c_double))
for i in range(10000):
#print(index, main_nparray)
main_nparray[:] = index + i
return index pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b - a) nparray = np.frombuffer(data, 'd', NUM_PROCESS*size, 0)
nparray.resize(NUM_PROCESS, size)
print("result:")
#print(nparray.shape)
print(nparray)
Python多进程共享numpy 数组的更多相关文章
- Python数据分析之numpy数组全解析
1 什么是numpy numpy是一个在Python中做科学计算的基础库,重在数值计算,也是大部分Python科学计算库的基础库,多用于大型.多维数据上执行数值计算. 在NumPy 中,最重要的对象是 ...
- python:将numpy数组写入csv文件
import numpy as np np.savetxt('E:\\forpython\\featvector.csv',data_to_save,delimiter=',')
- python 多进程共享全局变量之Manager()
Manager支持的类型有list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和A ...
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- python numpy 数组拼接
我就写一下我遇到的,更多具体的请看Python之Numpy数组拼接,组合,连接 >>> aarray([0, 1, 2], [3, 4, 5], [6, 7, ...
- python : 将txt文件中的数据读为numpy数组或列表
很多时候,我们将数据存在txt或者csv格式的文件里,最后再用python读取出来,存到数组或者列表里,再做相应计算.本文首先介绍写入txt的方法,再根据不同的需求(存为数组还是list),介绍从tx ...
- Python数据分析工具库-Numpy 数组支持库(一)
1 Numpy数组 在Python中有类似数组功能的数据结构,比如list,但在数据量大时,list的运行速度便不尽如意,Numpy(Numerical Python)提供了真正的数组功能,以及对数据 ...
- numpy数组与python的list互转,然后用json写入文件与c交互
1.对于numpy的tofile方法,一个一维数组可以直接写成二进制形式,用c语言或者numpy.fromfile()可以读出来内容.而如果数组超过一维,tofile并不区分,也就是arr1=[1,2 ...
- 【Python】numpy 数组拼接、分割
摘自https://docs.scipy.org 1.The Basics 1.1 numpy 数组基础 NumPy’s array class is called ndarray. ndarray. ...
- Python:numpy数组转换为json格式
在python中,如何将一个numpy数组转换为json格式? 这是最近遇到的一个问题,做个笔记. 假设arr为numpy数组,将其转换为json格式: 总体思想是①首先转换为python的list, ...
随机推荐
- Nuxt.js 深入浅出:目录结构与文件组织详解
title: Nuxt.js 深入浅出:目录结构与文件组织详解 date: 2024/6/18 updated: 2024/6/18 author: cmdragon excerpt: 摘要:本文详述 ...
- java基础-匿名类/对象
最近有同事问我,以下这个语句是什么意思? MqMessge<MqMessgeThink> mm= JSON.parseObject(message.toString(),new TypeR ...
- 掉了两根头发后,我悟了!vue3的scoped原来是这样避免样式污染(上)
前言 众所周知,在vue中使用scoped可以避免父组件的样式渗透到子组件中.使用了scoped后会给html增加自定义属性data-v-x,同时会给组件内CSS选择器添加对应的属性选择器[data- ...
- 如何解决jenkins插件下载过慢的问题
1.修改/var/lib/jenkins/updates目录下的default.json文件 通过sed命令将插件的下载地址替换成国内的地址: sed -i 's#http:\/\/updates.j ...
- 【ClickHouse】3:clickhouse基本操作一 用户权限管理
背景介绍: 有三台CentOS7服务器安装了ClickHouse HostName IP 安装程序 程序端口 centf8118.sharding1.db 192.168.81.18 clickhou ...
- python3 安装pymssql失败 pip3 install pymssql
python3 安装pymssql失败 报错信息: AttributeError: module 'platform' has no attribute 'linux_distribution' 解决 ...
- Polar靶场web刷题记录
Polar靶场 web刷题记录 简单部分 swp 考点:敏感文件.preg_match()函数绕过 根据题目名提示 访问 /.index.php.swp 可以用代码格式化工具美化一下 function ...
- VulnHub-DC-7渗透流程
DC-7 kali:192.168.157.131 靶机:192.168.157.151 信息收集 nmap -sV -A -p- 192.168.157.151 虽然有robots.txt等敏感文件 ...
- 从Java开发者到.NET Core初级工程师学习路线:C#语言基础
1. C#语言基础 1.1 C#语法概览 欢迎来到C#的世界!对于刚从Java转过来的开发者来说,你会发现C#和Java有很多相似之处,但C#也有其独特的魅力和强大之处.让我们一起来探索C#的基本语法 ...
- PHP中引用的详解(引用计数、写时拷贝)
转载:https://blog.csdn.net/ljguo212/article/details/8972865 1. PHP中引用的特性 PHP中引用意味着用不同的名字访问同一个变量内容,引用不是 ...