PyTorch视觉模型库torchvision.models介绍
安装pytorch时我们一般都是会一并选择安装自带的视觉模型库 torchvision , 该库不仅有经典的视觉模型结构同时还提供了对应参数的下载功能,可以说torchvision库是十分方便于研究视觉的pytorch使用者来使用的。
给出pytorch的视觉库torchvision的GitHub地址:
https://github.com/pytorch/vision
该库中提供的模型结构定义文件:
pytorch官方也给出了对应torchvision库的一些介绍和使用说明:
https://pytorch.org/vision/stable/models.html

使用随机权重的torchvision中的视觉模型:
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()
efficientnet_b0 = models.efficientnet_b0()
efficientnet_b1 = models.efficientnet_b1()
efficientnet_b2 = models.efficientnet_b2()
efficientnet_b3 = models.efficientnet_b3()
efficientnet_b4 = models.efficientnet_b4()
efficientnet_b5 = models.efficientnet_b5()
efficientnet_b6 = models.efficientnet_b6()
efficientnet_b7 = models.efficientnet_b7()
regnet_y_400mf = models.regnet_y_400mf()
regnet_y_800mf = models.regnet_y_800mf()
regnet_y_1_6gf = models.regnet_y_1_6gf()
regnet_y_3_2gf = models.regnet_y_3_2gf()
regnet_y_8gf = models.regnet_y_8gf()
regnet_y_16gf = models.regnet_y_16gf()
regnet_y_32gf = models.regnet_y_32gf()
regnet_x_400mf = models.regnet_x_400mf()
regnet_x_800mf = models.regnet_x_800mf()
regnet_x_1_6gf = models.regnet_x_1_6gf()
regnet_x_3_2gf = models.regnet_x_3_2gf()
regnet_x_8gf = models.regnet_x_8gf()
regnet_x_16gf = models.regnet_x_16gf()
regnet_x_32gf = models.regnet_x_32gf()
使用torchvision给出的权重及torchvision中的视觉模型:
import torchvision.models as models resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
efficientnet_b0 = models.efficientnet_b0(pretrained=True)
efficientnet_b1 = models.efficientnet_b1(pretrained=True)
efficientnet_b2 = models.efficientnet_b2(pretrained=True)
efficientnet_b3 = models.efficientnet_b3(pretrained=True)
efficientnet_b4 = models.efficientnet_b4(pretrained=True)
efficientnet_b5 = models.efficientnet_b5(pretrained=True)
efficientnet_b6 = models.efficientnet_b6(pretrained=True)
efficientnet_b7 = models.efficientnet_b7(pretrained=True)
regnet_y_400mf = models.regnet_y_400mf(pretrained=True)
regnet_y_800mf = models.regnet_y_800mf(pretrained=True)
regnet_y_1_6gf = models.regnet_y_1_6gf(pretrained=True)
regnet_y_3_2gf = models.regnet_y_3_2gf(pretrained=True)
regnet_y_8gf = models.regnet_y_8gf(pretrained=True)
regnet_y_16gf = models.regnet_y_16gf(pretrained=True)
regnet_y_32gf = models.regnet_y_32gf(pretrained=True)
regnet_x_400mf = models.regnet_x_400mf(pretrained=True)
regnet_x_800mf = models.regnet_x_800mf(pretrained=True)
regnet_x_1_6gf = models.regnet_x_1_6gf(pretrained=True)
regnet_x_3_2gf = models.regnet_x_3_2gf(pretrained=True)
regnet_x_8gf = models.regnet_x_8gf(pretrained=True)
regnet_x_16gf = models.regnet_x_16gf(pretrained=True)
regnet_x_32gf = models.regnet_x_32gf(pretrained=True)
有一点需要注意,那就是这些模型的预训练参数都是对数据进行正则化后再进行训练的,官方具体说明:

不过对于为什么要采用该种方式进行正则数据只给出了简单解释,这里我们暂且可以认为该种正则方式是习惯操作或惯例操作。
import torch
from torchvision import datasets, transforms as T transform = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
dataset = datasets.ImageNet(".", split="train", transform=transform) means = []
stds = []
for img in subset(dataset):
means.append(torch.mean(img))
stds.append(torch.std(img)) mean = torch.mean(torch.tensor(means))
std = torch.mean(torch.tensor(stds))
官方给出的解释是当时他们最原始编写代码时计算了一下数据集的均值与方差,然后并一直用这个数字来进行计算了。
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
从代码:
transform = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
dataset = datasets.ImageNet(".", split="train", transform=transform)
中可以看到官方原始操作时是将数据集中的数据进行resize,crop操作后在进行均值和方差计算的。
for img in subset(dataset):
means.append(torch.mean(img))
stds.append(torch.std(img))
分别求每张图片R G B三色中每一色像素的均值与方差。
mean = torch.mean(torch.tensor(means))
std = torch.mean(torch.tensor(stds))
对所有图片的R G B均值与方差求数据集范围的统计均值,最终得到:
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
官方给出补充解释:
Unfortunately, the concrete subset that was used is lost. For more information see this discussion or these experiments.
也就是原始数据集已经找不到了,但是我们即使使用其他数据集也已然按照惯例使用这个均值与方差,如果自己的数据集本身过小那么自己重新求这个均值与方差可能导致泛化性降低,而如果使用大数据集的话进行如此计算也十分耗计算资源,这可能也是领域内现在也惯例使用这个均值方差来进行数据正则的原因。
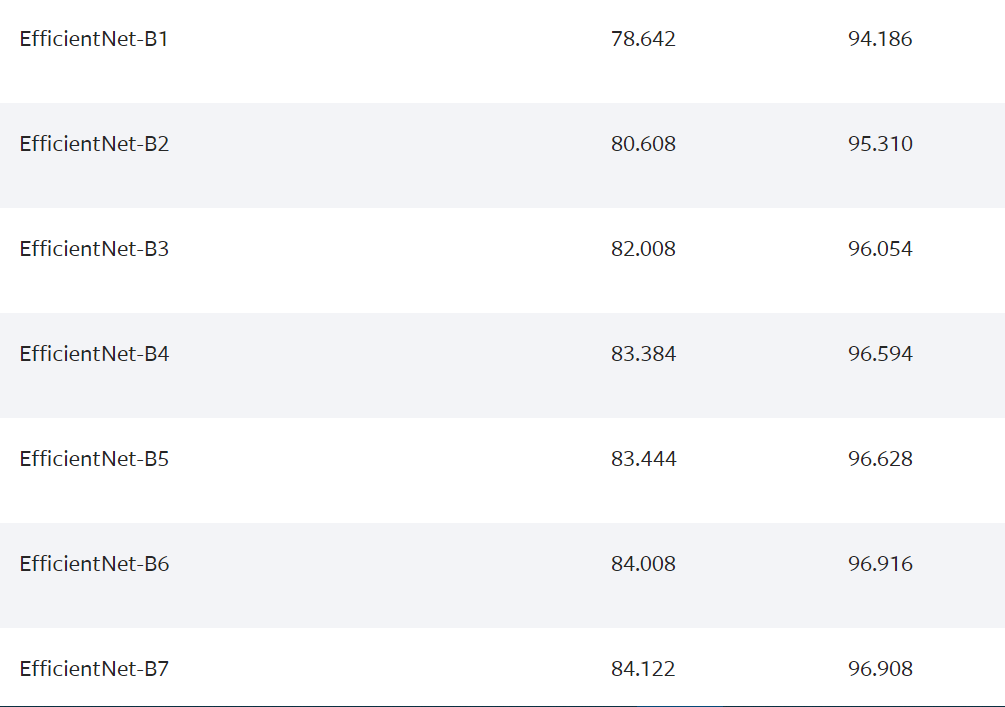
官方给出说明,对于 EfficientNet 网络来说模型的尺寸与变量有关。不过个人解读就是不同版本的EfficientNet模型其crop及input的size也是不同的,具体的size如下给出:
The sizes of the EfficientNet models depend on the variant. For the exact input sizes check here
例子中的代码设置:

====================================================
PyTorch视觉模型库torchvision.models介绍的更多相关文章
- PyTorch源码解读之torchvision.models(转)
原文地址:https://blog.csdn.net/u014380165/article/details/79119664 PyTorch框架中有一个非常重要且好用的包:torchvision,该包 ...
- 0702-计算机视觉工具包torchvision
0702-计算机视觉工具包torchvision 目录 一.torchvision 概述 二.通过 torchvision 加载模型 三.通过 torchvision 加载并处理数据集 四.通过 to ...
- 【小白学PyTorch】5 torchvision预训练模型与数据集全览
文章来自:微信公众号[机器学习炼丹术].一个ai专业研究生的个人学习分享公众号 文章目录: 目录 torchvision 1 torchvision.datssets 2 torchvision.mo ...
- 关于torchvision.models中VGG的笔记
VGG 主要有两种结构,分别是 VGG16 和 VGG19,两者并没有本质上的区别,只是网络深度不一样. 对于给定的感受野,采用堆积的小卷积核是优于采用大的卷积核的,因为多层非线性层可以增加网络深度来 ...
- 【Unity Shaders】Lighting Models 介绍
本系列主要参考<Unity Shaders and Effects Cookbook>一书(感谢原书作者),同时会加上一点个人理解或拓展. 这里是本书所有的插图.这里是本书所需的代码和资源 ...
- Django的models介绍
我们一般会在创建表的类中写一个__str__方法,就会为为了打印这个对象不会打印一大堆的对象的内存地址,而是我们想要他返回的信息,方便我们更直观的知道这个对象是谁,方便显示.比如下面的例子 from ...
- [Pytorch框架] 5.1 kaggle介绍
文章目录 5.1 kaggle介绍 5.1.1 Kaggle 平台简介 比赛介绍 5.1.2 Kaggle板块介绍 Data Rules Team Kernels Discussion Leaderb ...
- PyTorch DataSet Normalization torchvision.transforms.Normalize()
特征缩放, 在这种情况下,我们不仅仅考虑是一个值的数据集,我们考虑的是具有多个特征和相关的值的样本或元素的数据集. 假如正在处理一个人的数据集, 归一化数据集有许多不同的 ...
- 【pytorch报错解决】expected input to have 3 channels, but got 1 channels instead
遇到的问题 数据是png图像的时候,如果用PIL读取图像,获得的是单通道的,不是多通道的.虽然使用opencv读取图片可以获得三通道图像数据,如下: def __getitem__(self, idx ...
- torchvision.transforms模块介绍
torchvision.transforms模块 官网地址:https://pytorch.org/docs/stable/torchvision/transforms.html# torchvisi ...
随机推荐
- 有点东西,template可以直接使用setup语法糖中的变量原来是因为这个
前言 我们每天写vue3代码的时候都会使用到setup语法糖,那你知道为什么setup语法糖中的顶层绑定可以在template中直接使用的呢?setup语法糖是如何编译成setup函数的呢?本文将围绕 ...
- 使用GET方法访问网站
使用GET方法访问网站 服务器接收get参数 server.py import flask app = flask.Flask(__name__) @app.route('/') def index( ...
- python重拾第六天-面向对象基础
本节内容: 面向对象编程介绍 为什么要用面向对象进行开发? 面向对象的特性:封装.继承.多态 类.方法. 引子 你现在是一家游戏公司的开发人员,现在需要你开发一款叫做<人狗大战>的 ...
- Debezium-Flink-Hudi:实时流式CDC
1. 什么是Debezium Debezium是一个开源的分布式平台,用于捕捉变化数据(change data capture)的场景.它可以捕捉数据库中的事件变化(例如表的增.删.改等),并将其转为 ...
- MerkleTree in BTC
Merkle 树是一种用于高效且安全地验证大数据结构完整性和一致性的哈希树.它在比特币网络中起到至关重要的作用.Merkle 树是一种二叉树结构,其中每个叶子节点包含数据块的哈希值,每个非叶子节点包含 ...
- 修改Jenkins默认管理员admin密码
1.删除Jenkins目录下config.xml文件中下面代码,并保存文件. <useSecurity>true</useSecurity><authorizationS ...
- ABC361-C题解
背景 昨天打比赛的时候查了中考分,心快停跳了. 题意 从 \(n\) 个数字中删除 \(k\) 个数字,问剩下的数字中极差的最小值. 分析 首先把这 \(n\) 个数字排序,然后问题就可以转化为求这 ...
- 渐变边框文字效果?CSS 轻松拿捏!
今天,有个群友问了我这么一个问题,如果不想切图,是否有办法实现带渐变边框的字体效果?如下所示: 本文,就将尝试一下,在 CSS 中,我们可以如何尽可能的实现这种渐变边框字体效果. 元素叠加 首先,比较 ...
- C# EPPlus帮助类(EPPlusExcelHelper)
public class EPPlusExcelHelper : IDisposable { public ExcelPackage ExcelPackage { get; private set; ...
- NIO的三大核心组件详解,充分说明为什么NIO在网络IO中拥有高性能!
一.写在开头 我们在上一篇博文中提到了Java IO中常见得三大模型(BIO,NIO,AIO),其中NIO是我们在日常开发中使用比较多的一种IO模型,我们今天就一起来详细的学习一下. 在传统的IO中, ...