MyBatis 的缓存处理
作为常见的 ORM 框架,在使用 MyBatis 的过程中可以针对相关的查询进行缓存处理以提高查询的性能。本文将简要介绍一下 MyBatis 中默认的一级缓存和二级缓存,以及自定义缓存的处理
MyBatis 中存在的缓存结构如下图所示:
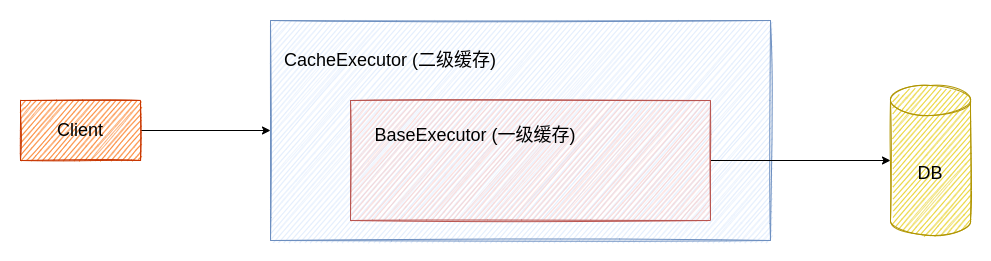
一级缓存
MyBatis 默认开启一级缓存,在对应的配置类中即存在默认的属性值,因此一般情况下不需要手动开启一级缓存:
package org.apache.ibatis.session;
public class Configuration {
protected boolean cacheEnabled = true; // 默认开启缓存
protected LocalCacheScope localCacheScope = LocalCacheScope.SESSION; // 缓存范围为会话级别
}
然而,有时可能需要手动更改默认的缓存会话级别,对于基于 XML 的 MyBatis 配置来讲,需要在 <settings></settings> 标签中加入如下的配置:
<settings>
<!-- 将缓存作用范围缩小到语句级别 -->
<setting name="localCacheScope" value="STATEMENT"/>
</settings>
对于集成到 Spring 环境中的 MyBatis 来讲,需要在对应的配置文件中执行类似下面的配置:
mybatis:
configuration:
local-cache-scope: statement # 缩小缓存范围到语句
cache-enabled: true # 开启缓存
假设现在我们创建了如下的表,结构如下:
CREATE TABLE rate_info
(
id BIGINT NOT NULL COMMENT '利率记录 id'
PRIMARY KEY,
rate_name VARCHAR(32) NULL COMMENT '利率名称',
rate_val DECIMAL NULL COMMENT '利率值',
created_user VARCHAR(32) NULL COMMENT '创建这条记录的用户名称',
created_time DATETIME NULL COMMENT '这条记录的创建时间',
updated_user VARCHAR(32) NULL COMMENT '更新这条记录的用户名称',
updated_time DATETIME NULL COMMENT '这条记录最近的更新时间'
)
COMMENT '利率信息表';
默认的缓存
在不做任何配置的情况下(即开启默认的一级缓存配置),执行如下的几次查询:
RateInfoMapper mapper = sqlSession.getMapper(RateInfoMapper.class);
RateInfo info = mapper.selectById(1L);
System.out.println(info);
System.out.println(info);
System.out.println(info);
可以看到执行的查询情况如下:
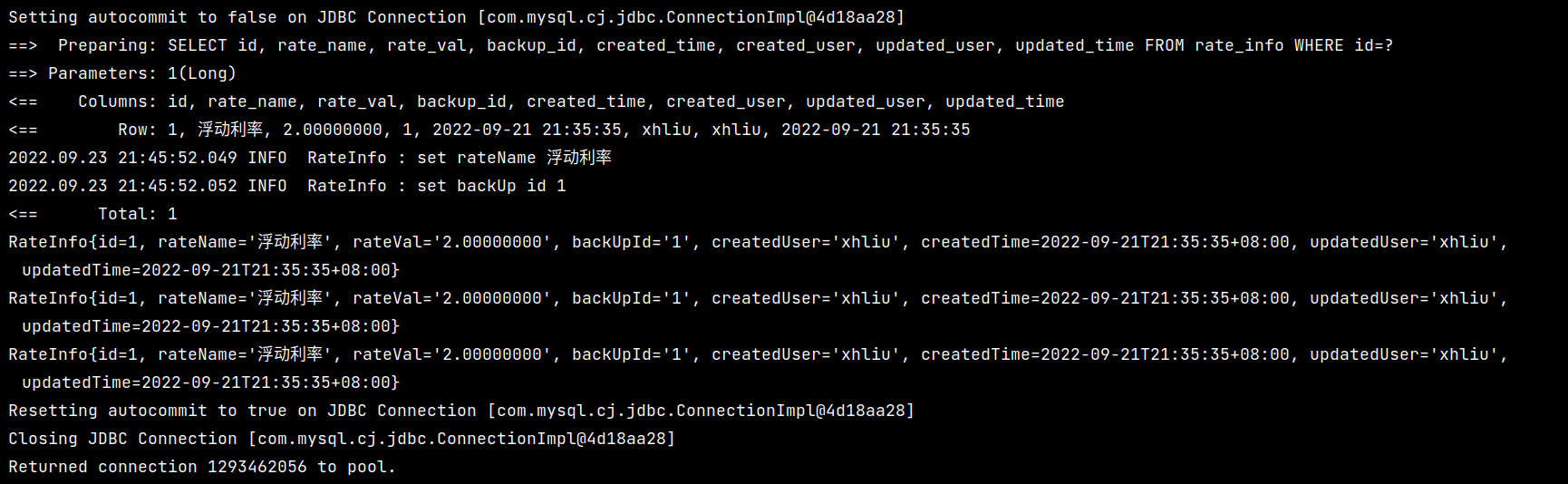
可以看到,只有在第一次执行查询的时候真正执行了 SQL 语句的查询
缓存的更新
为了验证缓存是否会被刷新,可以在执行第一次查询之后插入或者更新一条数据,检查是否会刷新缓存,对应的代码如下:
RateInfoMapper mapper = sqlSession.getMapper(RateInfoMapper.class);
RateInfo info = mapper.selectById(1L);
System.out.println(info);
info.setRateVal(new BigDecimal("3.14"));
info.initUpdate();
mapper.update(info);
sqlSession.commit();
System.out.println(info);
System.out.println(info);
对应的执行结果如下:
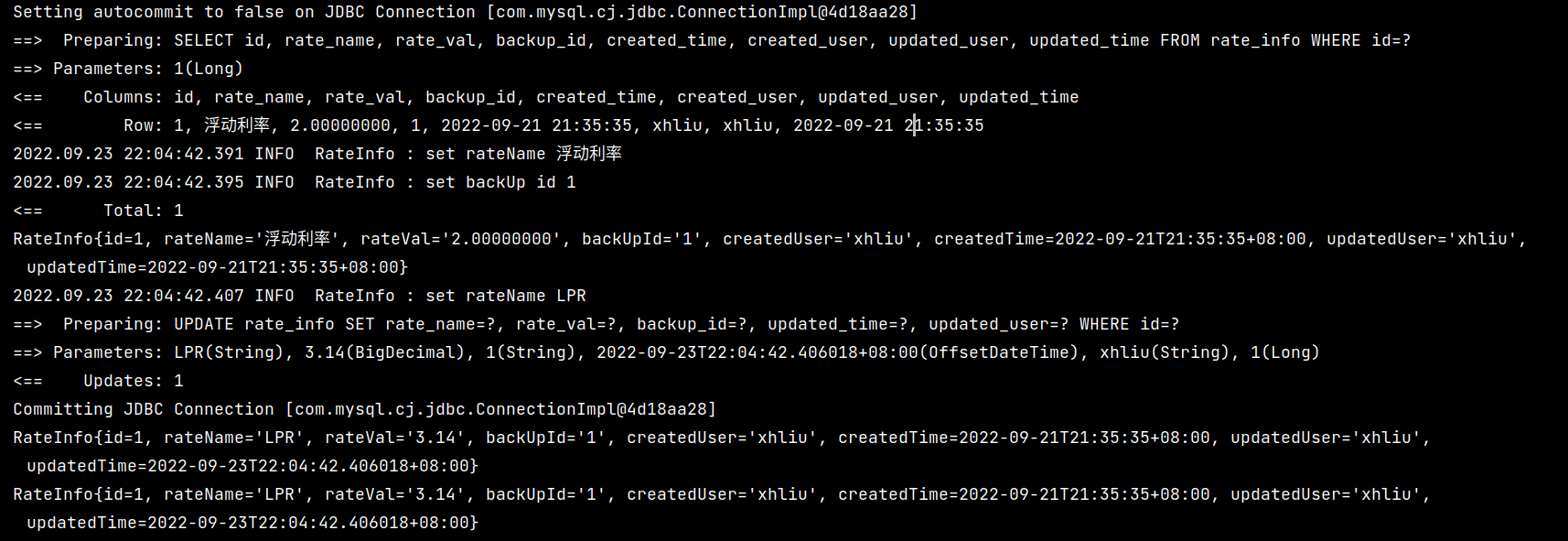
可以看到,在执行完数据的更新操作后,后续的查询将会再次查询一次数据库
不同 Session 中的缓存
当存在多个 SqlSession 执行相同的查询时,可能会导致一些异常的情况,以下面的例子为例:
try (
// 打开两个 SqlSession,使得具备两个 Session 上下文
SqlSession sqlSession1 = openSqlSession();
SqlSession sqlSession2 = openSqlSession()
) {
RateInfoMapper mapper1 = sqlSession1.getMapper(RateInfoMapper.class);
RateInfoMapper mapper2 = sqlSession2.getMapper(RateInfoMapper.class);
// 两个 Session 分别执行第一次查询
RateInfo info1 = mapper1.selectById(1L);
RateInfo info2 = mapper2.selectById(1L);
System.out.println("info1: " + info1);
System.out.println("info2: " + info2);
// session1 执行数据的更新操作
RateInfo data = new RateInfo();
data.setId(1L);
data.setRateName("LPR");
data.setRateVal(new BigDecimal("3.141"));
mapper1.update(data);
sqlSession1.commit();
System.out.println("sqlSession1 完成数据的更新");
// 更新完成之后两个 Session 再分别执行一次数据的查询
info1 = mapper1.selectById(1L);
info2 = mapper2.selectById(1L);
System.out.println("info1: " + info1);
System.out.println("info2: " + info2);
}
查询结果如下:
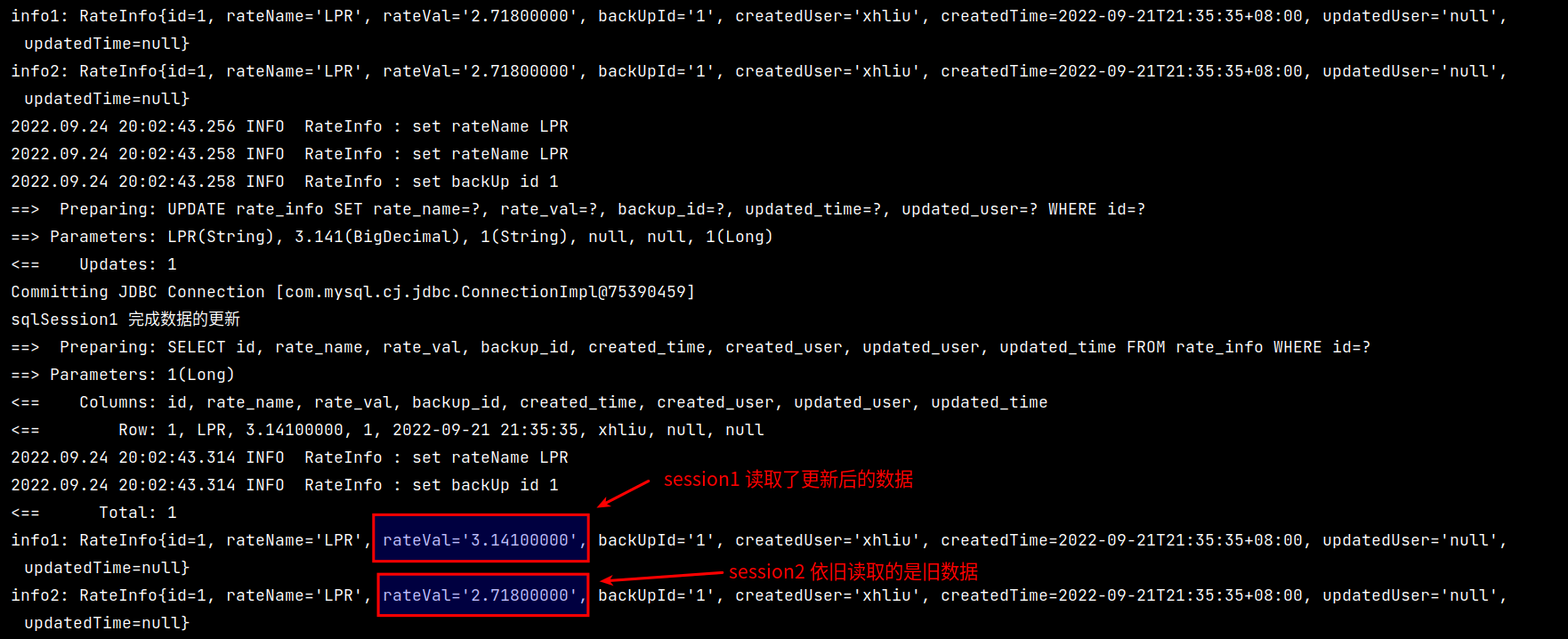
可以看到,在 session1 中更新的数据无法在 session2 中及时被读取,导致读取的数据为脏数据
源码分析
为了了解 MyBatis 一级缓存中出现的这些行为,最好的方式就是直接从源码的角度入手了及相关的处理逻辑
Executor的实例化
首先分析一下 openSession 中创建 session 的处理逻辑:
public class DefaultSqlSessionFactory implements SqlSessionFactory {
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
// 这里的 execType 默认为 ExecutorType.SIMPLE
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
由于 SqlSession 最终会将数据操作的逻辑委托给 Executor 类进行处理,因此我们在这里主要关心 Executor 的实例化过程,具体的实例化过程在 Configuration 中实现,对应的实例化逻辑如下所示:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
// 默认为 SIMPLE,因此会实例化 SimpleExecutor 作为底层数据操作的实现类
executor = new SimpleExecutor(this, transaction);
}
// 默认为 true,这里会将上面创建的 Executor 进行一次包装(装饰器模式)
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
其中,这几个根据 ExecutorType 创建的 Executor 的关系如下图所示:
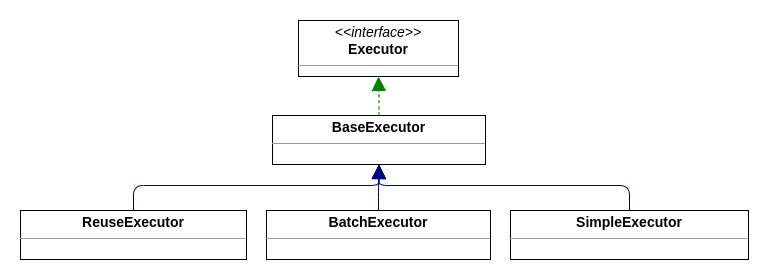
现在可以确认,我们默认的一级缓存执行数据操作的默认实现类为 CachingExecutor,同时此时的 localCacheScope 默认为 session
缓存键的处理
按照 MyBatis 的执行流程,在走完代理类的调用方法之后将会调用 Executor 中对于数据操作的方法,对于上文我们提到的查询单条记录的情况来讲,我们最终会执行 query 方法,对应的源码如下:
public class CachingExecutor implements Executor {
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
}
暂且忽略 SQL 的相关处理,现在我们的主要目的是探索缓存的处理逻辑。在 query 方法中真正执行查询之前会根据现有的执行 SQL 创建对应的 key 来标识特定的查询,创建 key 对应的源码如下:
public class CachingExecutor implements Executor {
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
/*
delegate 具体表示的是创建 `CachingExecutor` 时的被包装类,按照上文我们的分析,被包装的类型是 `SimpleExecutor`
*/
return delegate.createCacheKey(ms, parameterObject, rowBounds, boundSql);
}
}
createCacheKey 由 BaseExecutor 定义,根据继承关系,会调用 BaseExecutor 中的 createCacheKey 方法,对应的源码如下:
public abstract class BaseExecutor implements Executor {
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
}
首先查看一下 CacheKey 的定义:
public class CacheKey implements Cloneable, Serializable {
private static final int DEFAULT_MULTIPLIER = 37;
private static final int DEFAULT_HASHCODE = 17;
private final int multiplier;
private int hashcode;
private long checksum;
private int count;
private List<Object> updateList;
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLIER;
this.count = 0;
this.updateList = new ArrayList<>();
}
/**
* 这里 hashCode 的计算规则和一般的 hashCode 的计算类似,都是通过将之前的 hash 值乘上一个质数再加上当前待计算
* 的对象的 hashCode 值作为更新后的 hashCode,这样计算出来的 hashCode 可以提供较好的分散性
*/
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
/**
* 这里的 equals 方法比较关键,因为计算的 hashCode 在一定程度上可能会发生冲突,因此需要进一步地检查存储的缓存 key 是否是要查找的 key,
* 这也是 Object 中 hashCode 方法和 equals 方法的规范
*/
public boolean equals(Object object) {
// 省略部分检验。。。。。。
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
@Override
public int hashCode() {
return hashcode;
}
// 省略部分方法
}
通过分析可以看到,只有当 CacheKey 中 updateList 的所有对象都相同时才会判定为相同,而结合上下文 createCacheKey 方法的对应逻辑,可以得到以下结论:
只有当 Statement Id、offset、limit、执行的 SQL 以及对应的查询参数完全一致时,才会判定为是同一个
CacheKey
缓存的实际存储
按照执行流程继续向下执行,首先会先检查是否存在对应的缓存,然后再对查询做相关的处理:
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
可以看到,只有当缓存中不存在数据时,才会考虑从数据库中获取数据。同样地,我们目前关心的是对缓存的处理,即 localCache,可以发现它的具体类型为 PerpetualCache,是一个 Cache 类型的类
MyBatis 中 Cache 的实现结构如下图所示:
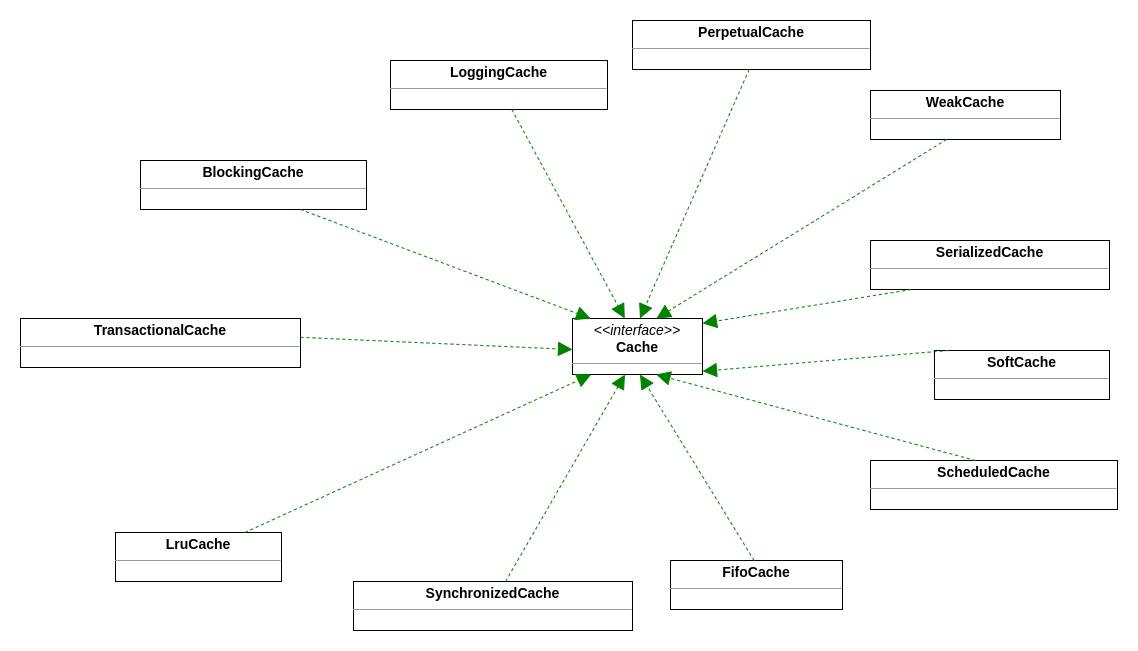
对于当前 BaseExecutor 中的 Cache 来说,我们可以查看相关的类定义:
public class PerpetualCache implements Cache {
private final String id;
private final Map<Object, Object> cache = new HashMap<>();
// ………………
}
可以看到,实际的存储的缓存就是一个 HashMap 对象,其中,key 在当前的上下文环境中就是我们提到的 CacheKey
在 query 方法的最后,会对 localCacheScope 执行一次判断,当 scope 为 STATEMENT 时则会清除当前的缓存,这也就是为什么将 scope 设置为 STATMENT 时能够避免读取到脏数据的原因:
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 检查 scope,判断是否要清除缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
缓存的更新
当执行数据更新的操作时(修改、删除、插入),都会导致缓存被刷新,按照 MyBatis 的执行流程,所有数据更新的操作最终都会调用 Executor 的 update 方法,针对当前的一级缓存,在 BaseExecutor 中存在以下的逻辑:
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache(); // 执行之前会清空缓存
return doUpdate(ms, parameter);
}
二级缓存
二级缓存对应的是 Mapper 相关的缓存,即二级缓存作用于 Mapper 级别。如果需要开启二级缓存,那么需要在映射文件中添加 <cache /> 标签来开启二级缓存,cache 标签中的可选配置如下:
type:缓存的实现类,默认为PerpetualCacheeviction:过期策略,默认为LRUflushInterval:缓存的刷新间隔,单位为 ms,默认为 0 mssize:最多缓存的对象个数readOnly:缓存是否只读,默认为false。若配置可读写,则需要对应的实体类能够序列化blocking:若缓存中找不到对应的 key,是否会一直阻塞,直到有对应的数据进入缓存。默认为false
由于存在多表查询的情况,因此如果希望当其它表的数据刷新时同时刷新缓存,那么可以添加 <cache-ref /> 标签来使得两个 Mapper 共享同一个 Cache 来使得缓存能够及时刷新:
<cache-ref namespace="com.example.mapper.UserInfoMapper" />
事务与二级缓存
现在来体验一下二级缓存的使用,在使用之前需要确保对应的实体类实现了 Serializable 接口(尽管并不推荐实现这个接口)。由于一级缓存的存在,因此我们需要两个 SqlSession 来验证二级缓存的功能:
try (
SqlSession sqlSession1 = openSqlSession();
SqlSession sqlSession2 = openSqlSession()
) {
RateInfoMapper mapper1 = sqlSession1.getMapper(RateInfoMapper.class);
RateInfoMapper mapper2 = sqlSession2.getMapper(RateInfoMapper.class);
System.out.println("session1 第一次查询:" + mapper1.selectById(1L));
System.out.println("session2 第一次查询:" + mapper2.selectById(1L));
}
执行结果如下图所示:
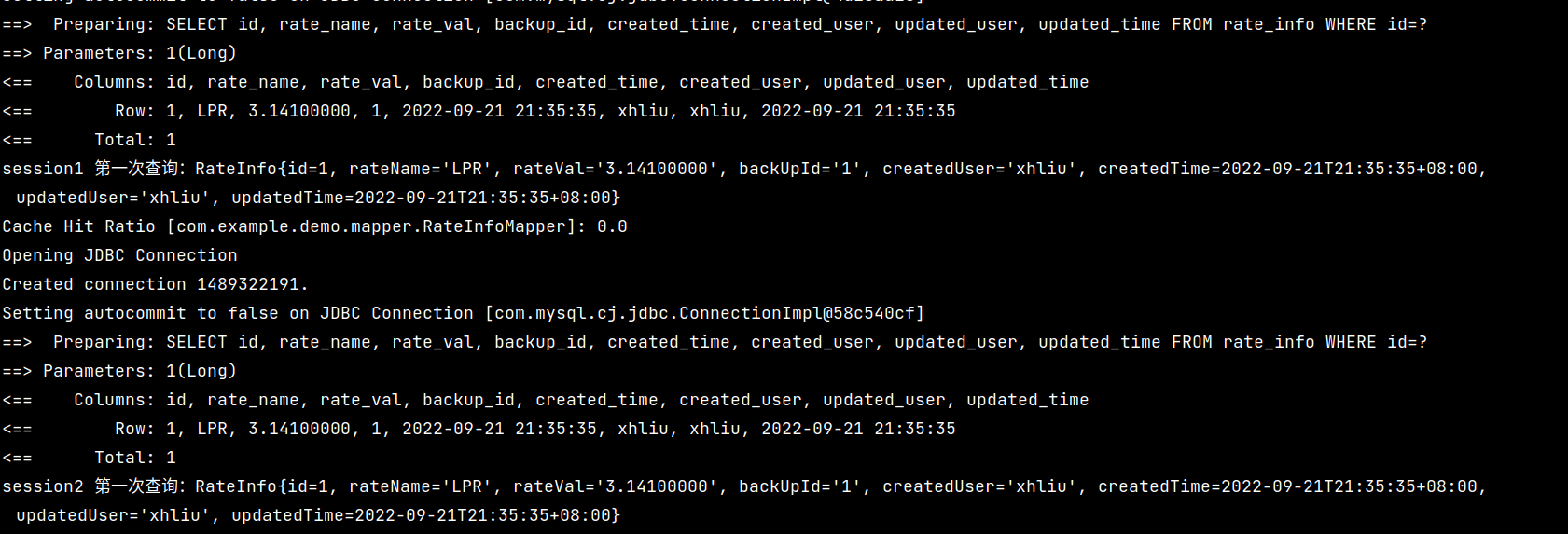
可以看到,在没有提交事务之前,两个 SqlSession 之间的查询依旧是独立的,并没有使用到二级缓存。现在,我们在第一次查询之后手动提交事务:
System.out.println("session1 第一次查询:" + mapper1.selectById(1L));
sqlSession1.commit();
System.out.println("session1 提交事务");
System.out.println("session2 第一次查询:" + mapper2.selectById(1L));
此时的执行情况如下图所示:
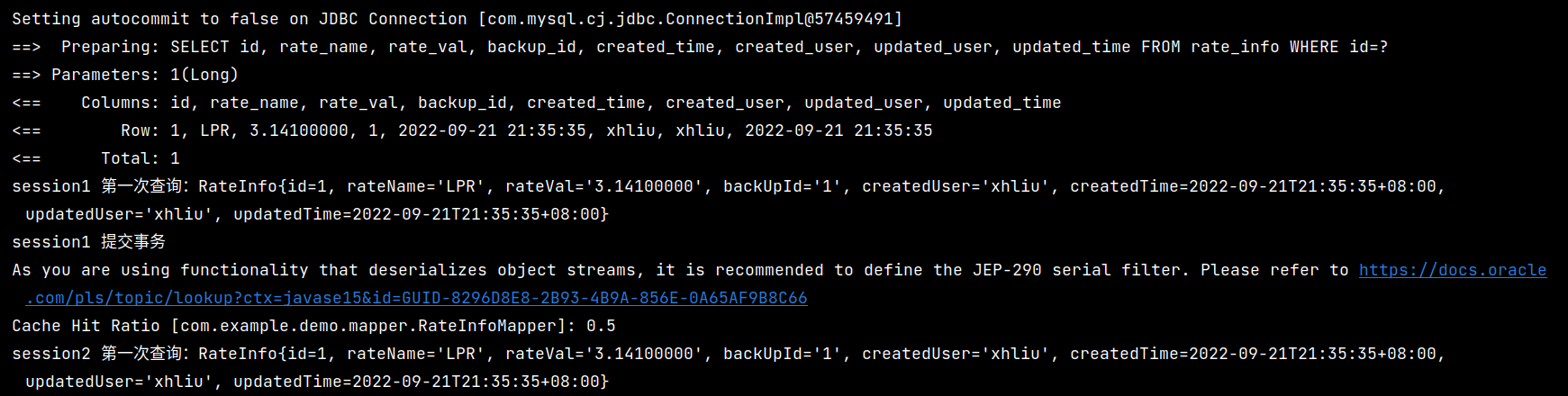
可以看到,在手动提交事务之后,session2 能够使用缓存查询到对应的数据
源码分析
按照本文开头给出的缓存结构图,二级缓存会在处理一级缓存之前完成二级缓存的任务,也就是说,一级缓存依旧生效,二级缓存是附加功能
二级缓存的处理对应 CachingExecutor,其中包含了以下的一些属性:
public class CachingExecutor implements Executor {
private final Executor delegate; // 被装饰的 Executor 类(BaseExecutor)
// 实际的缓存对象
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
}
依旧是通过查询接口来分析处理逻辑,在查询时最终会走到如下方法:
public class CachingExecutor implements Executor {
// ……………………
public <E> List<E> query(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
}
其中,ms.getCache() 会获取到通过配置文件创建的 Cache 对象,这实际上也是 “装饰器” 模式的使用,具体的装饰链路为:
SynchronizedCache—>LoggingCache—>SerializedCache—>LruCache—>PerpetualCache
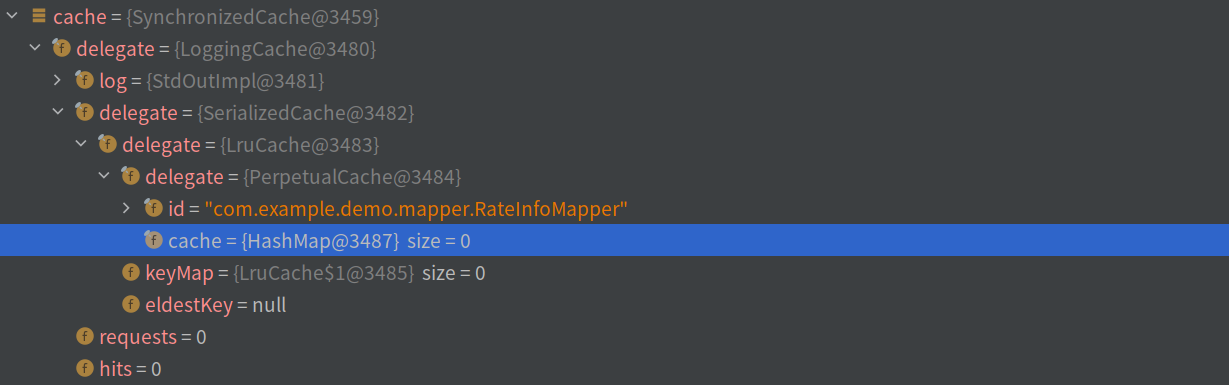
每个 Cache 的功能大致如下:
SynchronizedCache:同步Cache的操作,所有的操作方法都被synchronized修饰LoggingCache:提供日志功能,主要目的是打印缓存的命中率SerializedCache:提供缓存的序列化功能,主要目的是将查询的对象序列化并进行缓存。(反序列化时会得到一个新的实例对象,这在一定程度上保证了线程安全)LruCache:实现了LRU算法的CachePerpetualCache:简单的映射关系用于保存CacheKey和相关对象的关联关系
如果此时能够从缓存中查询到数据,那么首先会检查是否需要刷新缓存,默认 SELECT 语句不会刷新缓存:
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
结合上文提到的 CachingExecutor 的结构,我们比较关心的是 tcm 中的相关处理,继续查看 TransactionalCache 中的定义:
public class TransactionalCacheManager {
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
}
打住,现在理清一下思路,CachingExecutor 中持有一个 tcm,而这个 tcm 中持有一个 Map 结构,这个 Map 结构中存储的是 Cache 到 TransactionalCache 的映射关系
继续查询 TransactionalCache 中的相关定义:
public class TransactionalCache implements Cache {
private final Cache delegate; // 默认是我们上文分析的最外层装饰器类 SynchronizedCache
private boolean clearOnCommit;
private final Map<Object, Object> entriesToAddOnCommit; // 当提交事务时需要刷新到缓存的数据对象
private final Set<Object> entriesMissedInCache; // 在缓存中不存在的数据对象
public TransactionalCache(Cache delegate) {
this.delegate = delegate;
this.clearOnCommit = false;
this.entriesToAddOnCommit = new HashMap<>();
this.entriesMissedInCache = new HashSet<>();
}
// ……………………
}
当提交事务时,在 CachingExecutor 会调用到 commit 方法来显式地提交事务:
public class CachingExecutor implements Executor {
public void commit(boolean required) throws SQLException {
delegate.commit(required);
tcm.commit();
}
}
而对于 tcm 属性来讲,继续调用 TransactionalCacheManager 的 commit 方法:
public class TransactionalCacheManager {
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
}
调用当前存储的所有 TransactionalCache 值的 commit 方法:
public class TransactionalCache implements Cache {
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
// 将当前事务未提交的缓存刷新到被包装的 Cache 中
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
}
也就是说,只有当我们提交事务的时候,我们通过查询创建的缓存才真正被放入到了缓存对象中,这也就是为什么我们一开始未手动提交事务继续查询时会无法读取二级缓存的原因
对于查询时得到的缓存对象,实际上存储在 tcm 中,而 tcm 并不是实际存储缓存的对象,实际缓存对象的功能由具体的被包装类实现,具体在 tcm 的 getObject 方法中可以看到:
public class TransactionalCacheManager {
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
}
public class TransactionalCache implements Cache {
public Object getObject(Object key) {
// 尝试从被包装的 Cache 类中获取缓存数据
Object object = delegate.getObject(key);
// ………………
}
}
而对于 tcm 的 putObject 方法,实际上只是将数据对象放入了临时的缓存,在实际存储的缓存中并不会具备这些数据:
public class TransactionalCacheManager {
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
}
public class TransactionalCache implements Cache {
public void putObject(Object key, Object object) {
// entriesToAddOnCommit 存储的是提交事务时需要放入被包装 Cache 的数据
entriesToAddOnCommit.put(key, object);
}
}
自定义缓存
对于 MyBatis 的一级缓存和二级缓存来讲,都存在些许的局限性:一级缓存只能在同一个 SqlSeesion 中共享(STATMENT 模式将会清除缓存,没有解决共享失效的问题);二级缓存在多台机器上也表现地无能为力。因此,在某些特定的场景下可能需要我们使用自定义的缓存。
经过上文的分析,实际上的缓存就是一个 key-value 的键值对组合对象,当涉及到分布式应用时使用 Redis 作为缓存是一个很好的选择。幸运的是,Redissson 以及提供了 Redis 的缓存实现,只需要将对应 Mapper 中默认的 Cache 换成 RedissonCache 即可:
使用之前需要引入 Redissson 对应的依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-mybatis</artifactId>
<version>3.17.6</version>
</dependency>
替换原有 Mapper 中默认的 Cache 实现:
<!-- 使用 RedissonCache 替换现有的二级缓存实现 -->
<cache type="org.redisson.mybatis.RedissonCache">
<!-- 存活时间,即缓存对的有效时间 -->
<property name="timeToLive" value="10000" />
<!-- 最大空闲时间,超过这个时间没有被使用的缓存将会被清除 -->
<property name="maxIdleTime" value="5000" />
<!-- 缓存对的最大大小 -->
<property name="maxSize" value="100000" />
<!-- Redisson 配置文件 -->
<property name="redissonConfig" value="redisson.yaml" />
</cache>
之后便可以像使用二级缓存一样使用这个缓存,由于 Redis 并不是 MyBatis 的一部分,因此它可以在多个应用实例中能够共享相同的缓存
参考:
[1] https://tech.meituan.com/2018/01/19/mybatis-cache.html
[2] https://dzone.com/articles/caching-in-mybatis-with-redis
MyBatis 的缓存处理的更多相关文章
- 通过源码分析MyBatis的缓存
前方高能! 本文内容有点多,通过实际测试例子+源码分析的方式解剖MyBatis缓存的概念,对这方面有兴趣的小伙伴请继续看下去~ MyBatis缓存介绍 首先看一段wiki上关于MyBatis缓存的介绍 ...
- MyBatis 一级缓存与二级缓存
MyBatis一级缓存 MyBatis一级缓存默认开启,一级缓存为Session级别的缓存,在执行以下操作时一级缓存会清空 1.执行session.clearCache(); 2.执行CUD操作 3. ...
- Mybatis学习记录(七)----Mybatis查询缓存
1. 什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存. 一级缓存是SqlSession级别的缓存.在操作数据库时需要构造 sql ...
- 八 mybatis查询缓存(一级缓存,二级缓存)和ehcache整合
1 查询缓存 1.1 什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存.
- MyBatis一级缓存引起的无穷递归
MyBatis一级缓存引起的无穷递归 引言: 最近在项目中参与了一个领取优惠劵的活动,当多个用户领取同一张优惠劵的时候,使用了数据库锁控制并发,起初的设想是:如果多个人同时领一张劵,第一个到达的人领取 ...
- Spring+SpringMVC+MyBatis深入学习及搭建(八)——MyBatis查询缓存
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/6956206.html 前面讲到:Spring+SpringMVC+MyBatis深入学习及搭建(七)——My ...
- 【MyBatis源码解析】MyBatis一二级缓存
MyBatis缓存 我们知道,频繁的数据库操作是非常耗费性能的(主要是因为对于DB而言,数据是持久化在磁盘中的,因此查询操作需要通过IO,IO操作速度相比内存操作速度慢了好几个量级),尤其是对于一些相 ...
- mybatis一级缓存二级缓存
一级缓存 Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言.所以在参数和SQL完全一样的情况下,我们使用同一个SqlSess ...
- 深入浅出mybatis之缓存机制
目录 前言 准备工作 MyBatis默认缓存设置 缓存实现原理分析 参数localCacheScope控制的缓存策略 参数cacheEnabled控制的缓存策略 总结 前言 提到缓存,我们都会不约而同 ...
- Mybatis的缓存
1.缓存是什么 在 Mybatis 里面,所谓的缓存就是将已经查询过的记录放在内存的缓冲区或文件上,这样如果再次查询,可以通过配置的策略,命中已经查询过的记录,从而提高查询的效率. Mybatis 的 ...
随机推荐
- SpringCloud-ZipKin搭建保姆级教程
服务链路追踪 一.服务追踪说明 微服务架构是通过业务来划分服务的,使⽤REST调⽤.对外暴露的⼀个接⼝,可能需要 很多个服务协同才能完成这个接⼝功能,如果链路上任何⼀个服务出现问题或者⽹络超 时,都会 ...
- 要知其然还要知其所以然printChar
虽然过渡与的追求细节不是好事, 但是现实社会逼迫我们不得不兼顾周全. 所以什么都是最好不仅要知其然还要知其所以然! public class printChar { public static voi ...
- ERROR: nginx-1.22.1 installation failed.
libraries. You can either do not enable the module or install the libraries.make: *** No rule to mak ...
- 重写equals方法的注意事项
重写equals方法的注意事项 一. 在重写equals方法时,要注意满足离散数学上的特性1 自反性:对任意引用值X,x.equals(x)的返回值一定为true.2 对称性:对于任何引用 ...
- 循序渐进介绍基于CommunityToolkit.Mvvm 和HandyControl的WPF应用端开发(7) -- 图标列表展示和选择处理
我们在WPF应用端的界面中,使用lepoco/wpfui 来做主要的入口框架,这个项目它的菜单内置了不少图标,我们需要在动态菜单的配置中,使用它作为图标的展示处理,本篇随笔介绍如何基于图标枚举集合进行 ...
- [ABC212E] Safety Journey 题解
Safety Journey 题目大意 给定一张缺少了 \(m\) 条边的 \(n\) 个点的完全图和一个正整数 \(k\),你需要求出满足以下条件的序列 \(A\) 的数量: \(A\) 的长度为 ...
- Chromium Mojo通信
Mojo 是一个跨平台 IPC 框架,它诞生于 chromium ,用来实现 chromium 进程内/进程间的通信.目前,它也被用于 ChromeOS. 在我们代码应用中,如何使用Mojo来作进程间 ...
- Vue之class的用法
Vue中class的使用总结如下: 使用形式v-bind:class 简写:class 1.在数组中使用一个class <!DOCTYPE html> <html lang=&qu ...
- Python 利用pandas和mysql-connector获取Excel数据写入到MySQL数据库
如何将Excel数据插入到MySQL数据库中 在实际应用中,我们可能需要将Excel表格中的数据导入到MySQL数据库中,以便于进行进一步的数据分析和处理.本文将介绍如何使用Python将Excel表 ...
- 关于PaddleOCR识别时中文路径导致报错/没输出结果
此处只做学习PaddleOCR时遇到的一些坑 一.Python版本与PaddleOCR兼容性问题 如果你在Python11的环境下安装PaddlePaddle,使用 paddleocr --image ...