[python]使用diagrams绘制架构图
简介
diagrams是python的一个第三方库,用于实现使用代码绘制架构图。
安装
依赖于 Graphviz,安装diagrams之前需要先安装 Graphviz(下载压缩包后,将bin目录添加到系统环境变量Path里即可)。
python3 -m pip install diagrams
快速入门
- main.py
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
with Diagram("Web Service", show=False):
ELB("lb") >> EC2("web") >> RDS("userdb")
- 运行
python main.py
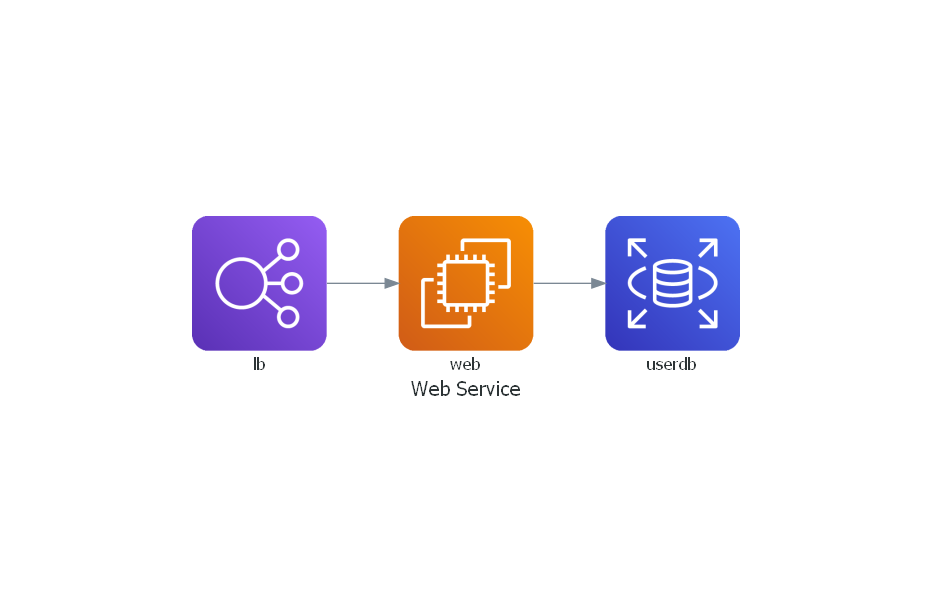
示例
简单的应用组
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
with Diagram("Grouped Workers", show=False, direction="TB"):
ELB("lb") >> [EC2("worker1"),
EC2("worker2"),
EC2("worker3"),
EC2("worker4"),
EC2("worker5")] >> RDS("events")
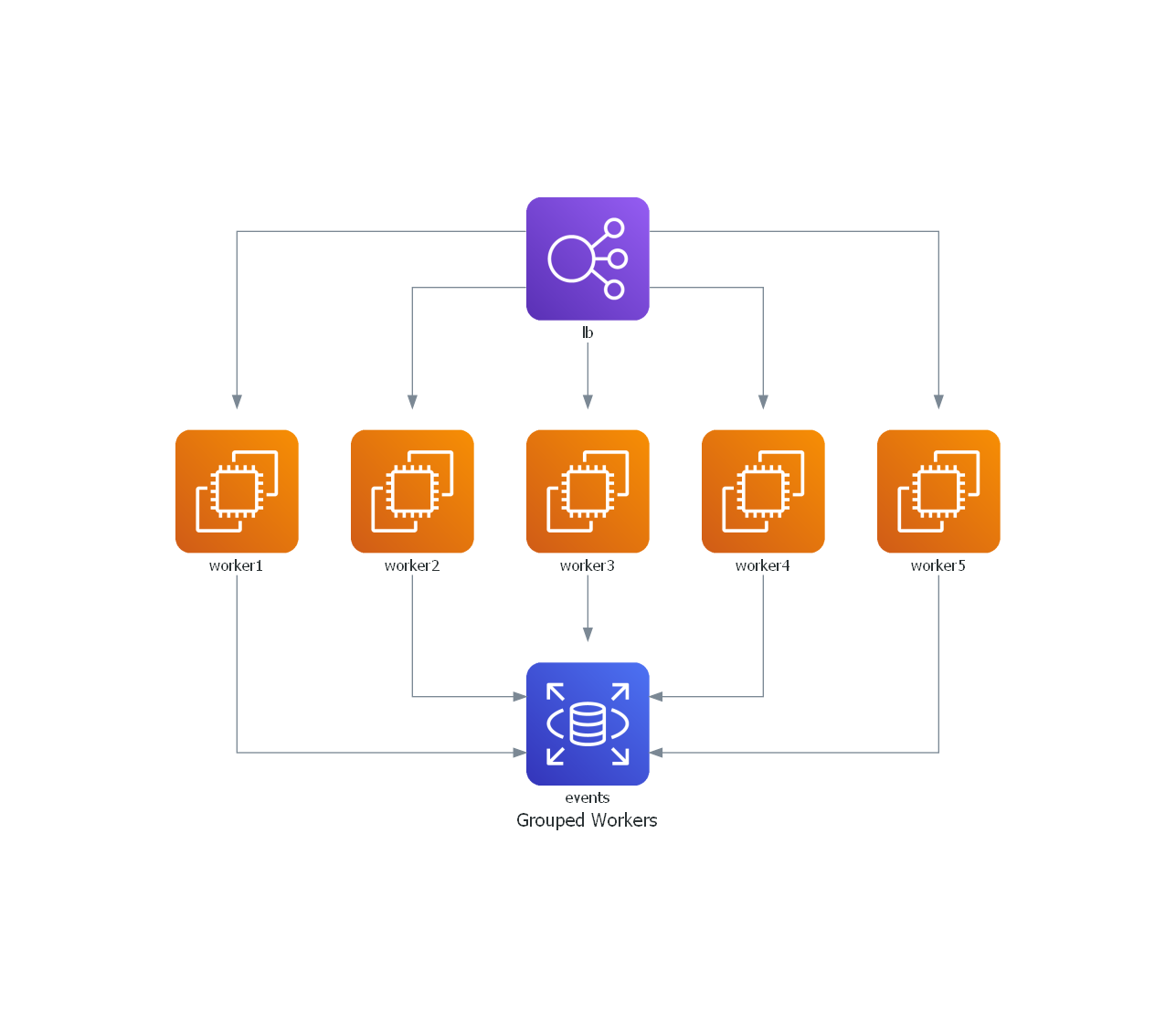
web 服务集群
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS
from diagrams.aws.database import ElastiCache, RDS
from diagrams.aws.network import ELB
from diagrams.aws.network import Route53
graph_attr = {
"bgcolor": "transparent" # 透明背景
}
with Diagram("Web 服务集群", show=False, filename="3", graph_attr=graph_attr):
dns = Route53("DNS")
lb = ELB("网关")
with Cluster("Services"):
svc_group = [ECS("web1"),
ECS("web2"),
ECS("web3")]
with Cluster("数据库集群"):
db_primary = RDS("主库")
db_primary - [RDS("只读从库")]
memcached = ElastiCache("memcached")
dns >> lb >> svc_group
svc_group >> db_primary
svc_group >> memcached
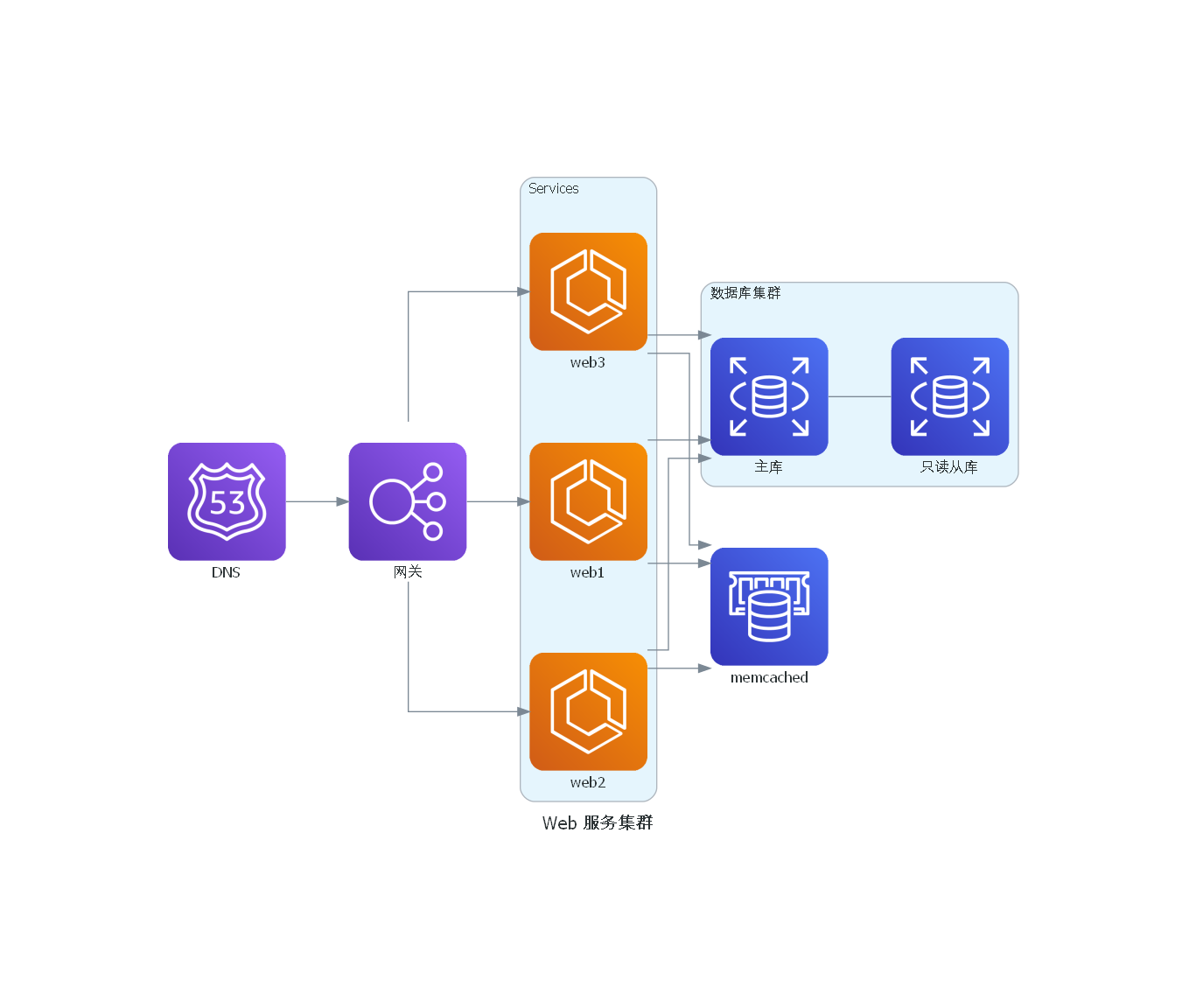
事件处理队列
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS, EKS, Lambda
from diagrams.aws.database import Redshift
from diagrams.aws.integration import SQS
from diagrams.aws.storage import S3
with Diagram("事件处理", show=False, filename="4"):
source = EKS("k8s source")
with Cluster("事件流"):
with Cluster("Event Workers"):
workers = [ECS("worker1"),
ECS("worker2"),
ECS("worker3")]
queue = SQS("event 队列")
with Cluster("处理器"):
handlers = [Lambda("proc1"),
Lambda("proc2"),
Lambda("proc3")]
store = S3("事件存储")
dw = Redshift("analytics")
source >> workers >> queue >> handlers
handlers >> store
handlers >> dw

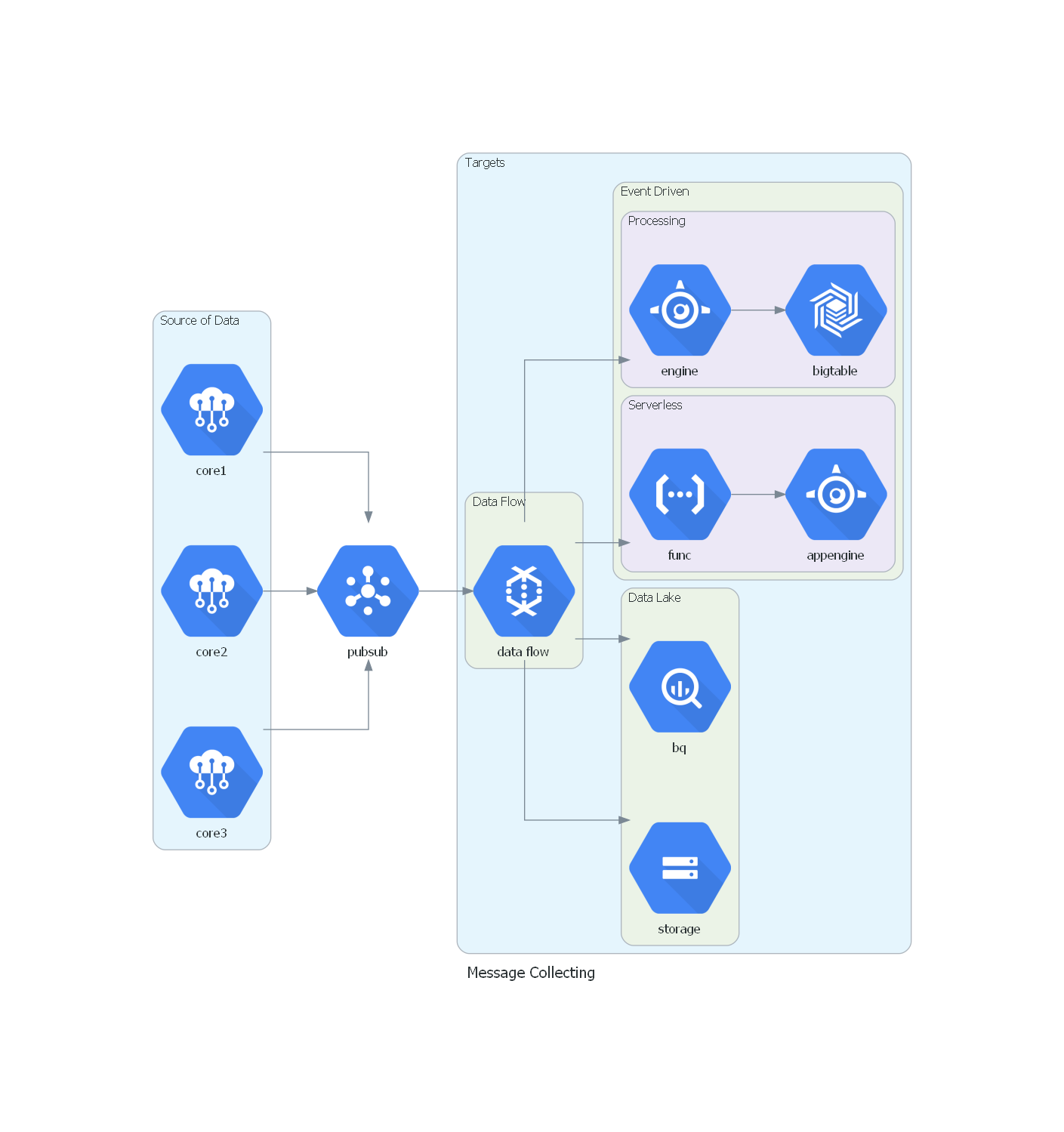
消息收集系统
from diagrams import Cluster, Diagram
from diagrams.gcp.analytics import BigQuery, Dataflow, PubSub
from diagrams.gcp.compute import AppEngine, Functions
from diagrams.gcp.database import BigTable
from diagrams.gcp.iot import IotCore
from diagrams.gcp.storage import GCS
with Diagram("Message Collecting", show=False, filename="5"):
pubsub = PubSub("pubsub")
with Cluster("Source of Data"):
[IotCore("core1"),
IotCore("core2"),
IotCore("core3")] >> pubsub
with Cluster("Targets"):
with Cluster("Data Flow"):
flow = Dataflow("data flow")
with Cluster("Data Lake"):
flow >> [BigQuery("bq"),
GCS("storage")]
with Cluster("Event Driven"):
with Cluster("Processing"):
flow >> AppEngine("engine") >> BigTable("bigtable")
with Cluster("Serverless"):
flow >> Functions("func") >> AppEngine("appengine")
pubsub >> flow
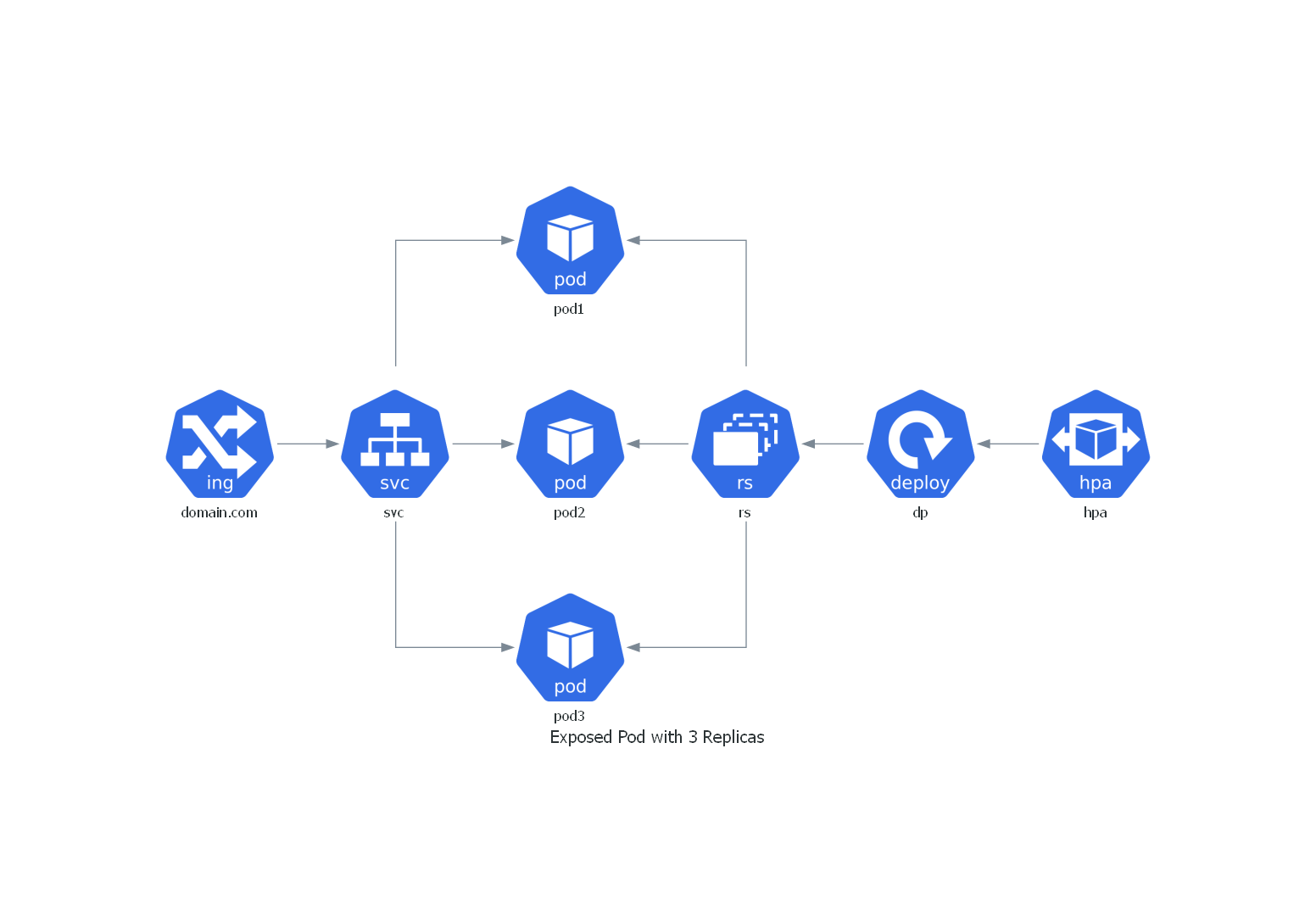
k8s中3副本pod
from diagrams import Diagram
from diagrams.k8s.clusterconfig import HPA
from diagrams.k8s.compute import Deployment, Pod, ReplicaSet
from diagrams.k8s.network import Ingress, Service
with Diagram("Exposed Pod with 3 Replicas", show=False, filename="6"):
net = Ingress("domain.com") >> Service("svc")
net >> [Pod("pod1"),
Pod("pod2"),
Pod("pod3")] << ReplicaSet("rs") << Deployment("dp") << HPA("hpa")
k8s有状态架构
from diagrams import Cluster, Diagram
from diagrams.k8s.compute import Pod, StatefulSet
from diagrams.k8s.network import Service
from diagrams.k8s.storage import PV, PVC, StorageClass
with Diagram("Stateful Architecture", show=False, filename="7"):
with Cluster("Apps"):
svc = Service("svc")
sts = StatefulSet("sts")
apps = []
for _ in range(3):
pod = Pod("pod")
pvc = PVC("pvc")
pod - sts - pvc
apps.append(svc >> pod >> pvc)
apps << PV("pv") << StorageClass("sc")

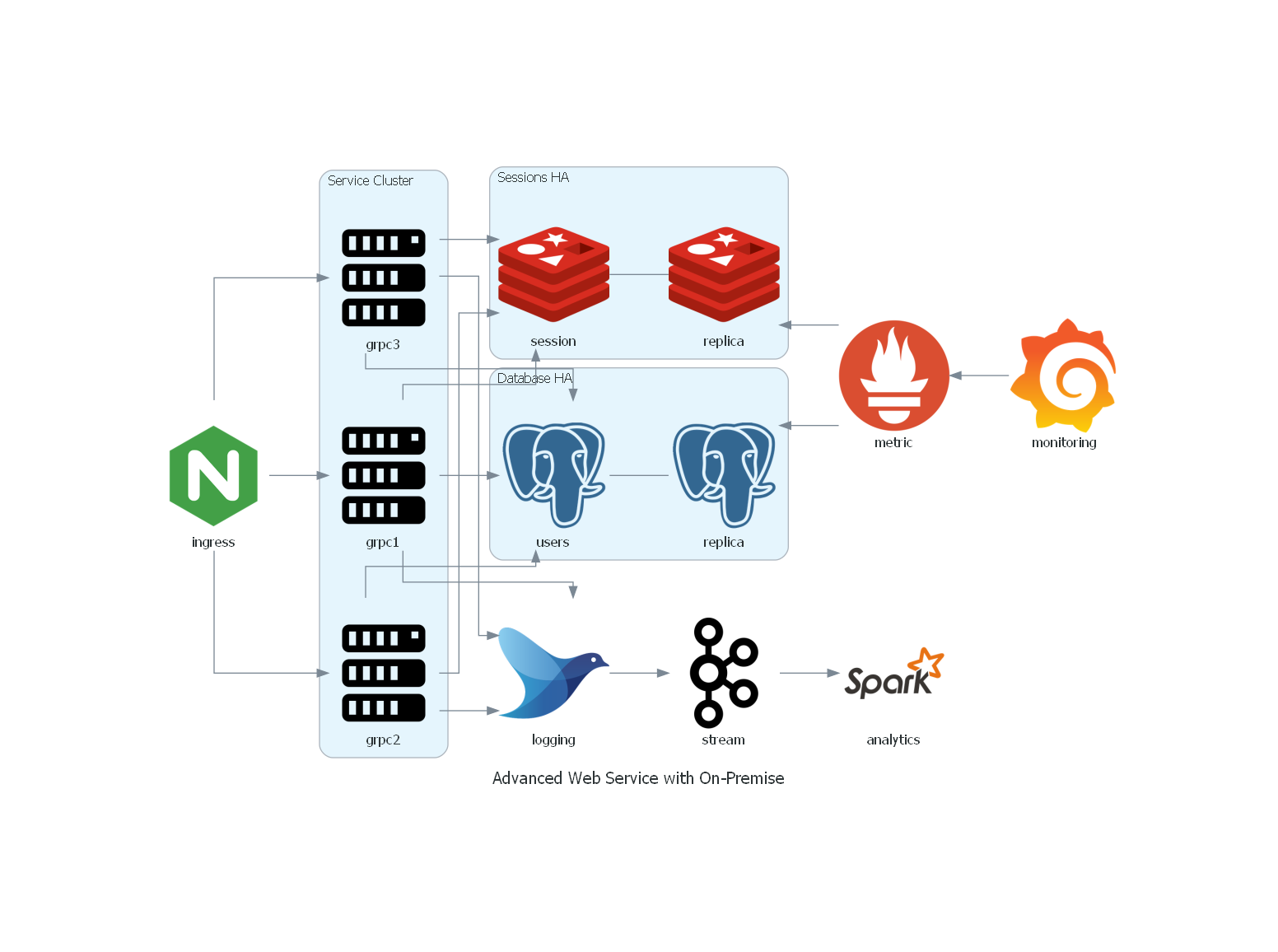
高级web服务架构
from diagrams import Cluster, Diagram
from diagrams.onprem.analytics import Spark
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.aggregator import Fluentd
from diagrams.onprem.monitoring import Grafana, Prometheus
from diagrams.onprem.network import Nginx
from diagrams.onprem.queue import Kafka
with Diagram("Advanced Web Service with On-Premise", show=False, filename="8"):
ingress = Nginx("ingress")
metrics = Prometheus("metric")
metrics << Grafana("monitoring")
with Cluster("Service Cluster"):
grpcsvc = [
Server("grpc1"),
Server("grpc2"),
Server("grpc3")]
with Cluster("Sessions HA"):
primary = Redis("session")
primary - Redis("replica") << metrics
grpcsvc >> primary
with Cluster("Database HA"):
primary = PostgreSQL("users")
primary - PostgreSQL("replica") << metrics
grpcsvc >> primary
aggregator = Fluentd("logging")
aggregator >> Kafka("stream") >> Spark("analytics")
ingress >> grpcsvc >> aggregator
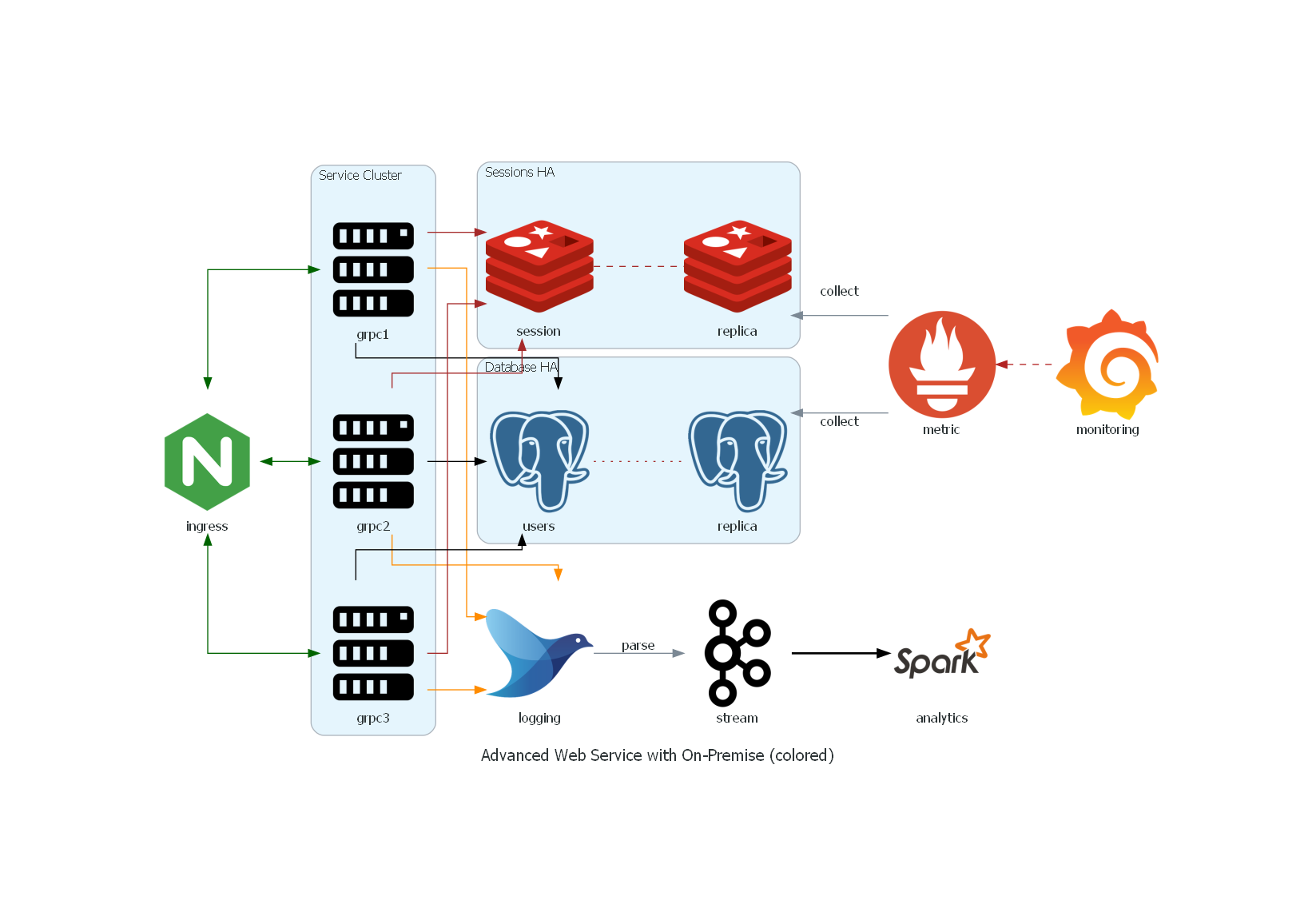
高级web服务架构2
from diagrams import Cluster, Diagram, Edge
from diagrams.onprem.analytics import Spark
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.aggregator import Fluentd
from diagrams.onprem.monitoring import Grafana, Prometheus
from diagrams.onprem.network import Nginx
from diagrams.onprem.queue import Kafka
with Diagram(name="Advanced Web Service with On-Premise (colored)", show=False, filename="9"):
ingress = Nginx("ingress")
metrics = Prometheus("metric")
metrics << Edge(color="firebrick", style="dashed") << Grafana("monitoring")
with Cluster("Service Cluster"):
grpcsvc = [
Server("grpc1"),
Server("grpc2"),
Server("grpc3")]
with Cluster("Sessions HA"):
primary = Redis("session")
primary - Edge(color="brown", style="dashed") - Redis("replica") << Edge(label="collect") << metrics
grpcsvc >> Edge(color="brown") >> primary
with Cluster("Database HA"):
primary = PostgreSQL("users")
primary - Edge(color="brown", style="dotted") - PostgreSQL("replica") << Edge(label="collect") << metrics
grpcsvc >> Edge(color="black") >> primary
aggregator = Fluentd("logging")
aggregator >> Edge(label="parse") >> Kafka("stream") >> Edge(color="black", style="bold") >> Spark("analytics")
ingress >> Edge(color="darkgreen") << grpcsvc >> Edge(color="darkorange") >> aggregator
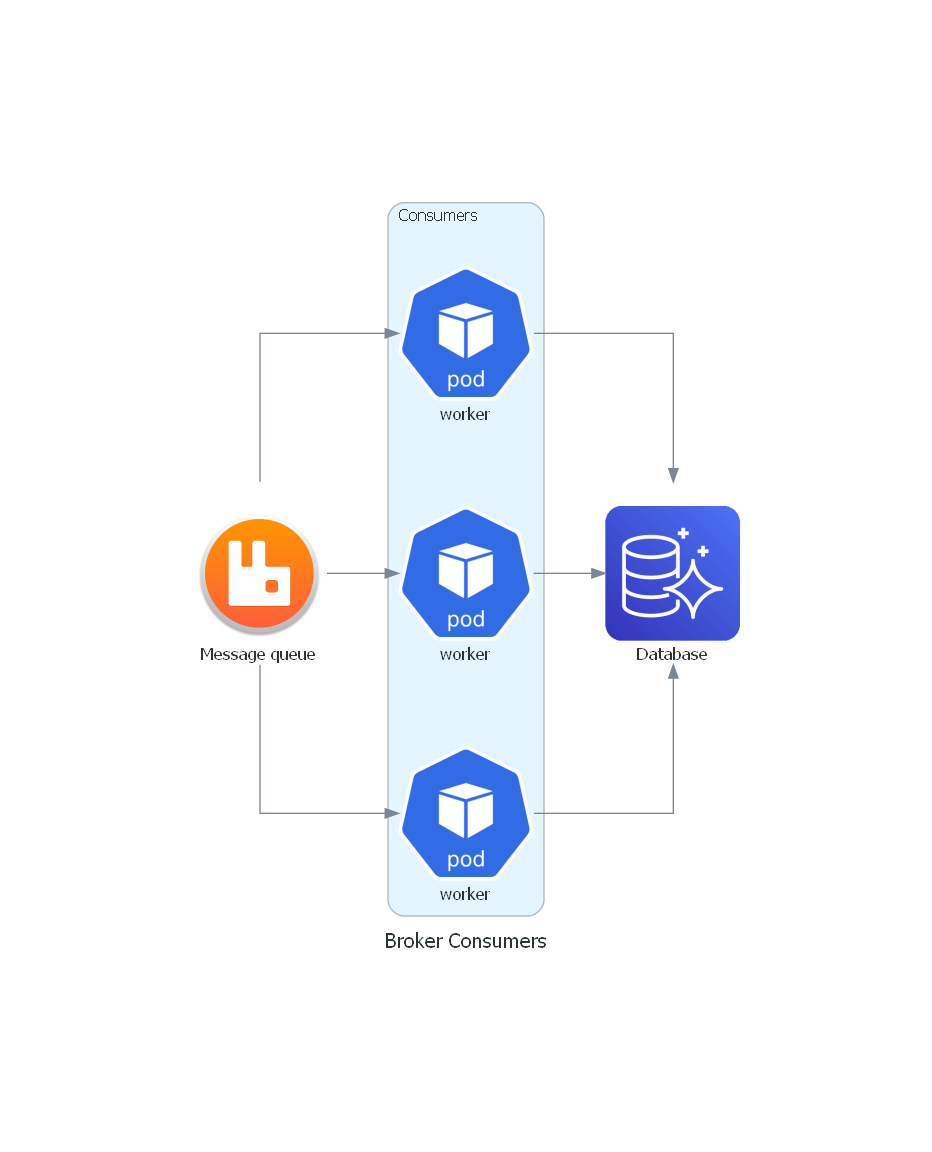
使用自定义的图标
from urllib.request import urlretrieve
from diagrams import Cluster, Diagram
from diagrams.aws.database import Aurora
from diagrams.custom import Custom
from diagrams.k8s.compute import Pod
# Download an image to be used into a Custom Node class
rabbitmq_url = "https://jpadilla.github.io/rabbitmqapp/assets/img/icon.png"
rabbitmq_icon = "rabbitmq.png"
urlretrieve(rabbitmq_url, rabbitmq_icon)
with Diagram("Broker Consumers", show=False, filename="10"):
with Cluster("Consumers"):
consumers = [
Pod("worker"),
Pod("worker"),
Pod("worker")]
queue = Custom("Message queue", rabbitmq_icon)
queue >> consumers >> Aurora("Database")
参考
[python]使用diagrams绘制架构图的更多相关文章
- graphviz 绘制架构图
架构图: 1.依赖调用关系.(类似文献引用关系, graphviz 自动将每一次调用升一次层级) 2.依赖调用可能是上下层级调用,也可能是同层级引用. 需人工去梳理出这些关系 3. 引用多的用颜色标识 ...
- [python] 基于diagrams库绘制系统架构图
Python的Diagrams库允许通过简单的Python代码绘制云系统架构,实现对新的系统架构进行原型设计.Diagrams的官方仓库地址见:diagrams.Diagrams的官方文档和使用示例见 ...
- 五分钟!用python绘制漂亮的系统架构图
Diagrams 是一个基于Python绘制云系统架构的模块,它能够通过非常简单的描述就能可视化架构,并支持以下6个云产品的图标: AWS.Azure.GCP.K8s.阿里云 和 Oracle 云 基 ...
- 用ChatGPT,绘制一个账号系统的C4架构图
hi,我是熵减,见字如面. 昨天我们用ChatGPT来设计一个账号系统,并尝试输出:模型表,类关系图,序列图,状态图等常用的架构设计中常用的元素. 今天,我们继续向更高层级延伸一下,看ChatGPT能 ...
- Atitit jOrgChart的使用 组织架构图css html
Atitit jOrgChart的使用 组织架构图css html 1. 项目要做组织架构图,要把它做成自上而下的树形结构,于是决定1 2. Html导入 以来的css js1 2.1. 数据来源 ...
- 飞达资讯App总体介绍及关系架构图
飞达资讯App总体介绍: 下图为飞达资讯App的关系架构图: 该App关系架构图所需的图片云盘链接地址:http://pan.baidu.com/s/1gfHIe4b 提取密码:x1nr 该App的云 ...
- 关于SAP4.7的几个架构图
http://blog.itpub.net/92530/viewspace-154881/ 1.SAP基本架构图 2.SAP的应用层的工作进程架构图 3.SAP的内存类型图 4.SAP数据访问架构图 ...
- android系统架构图
android的系统架构和其操作系统一样,采用了分层的架构.从架构图看,android分为四个层,从高层到低层分别是应用程序层.应用程序框架层.系统运行库层和Linux核心层. 1.应用程序 Andr ...
- MyBatis架构图
MyBatis架构 MyBatis依赖的jar不多,而且代码行数也没多少,其中使用了大量的设计模式,值得好好学习.下图是MyBatis的一张架构图,来自Java框架篇—Mybatis 入门. Myba ...
- struts2原理架构图
struts2 原理架构图
随机推荐
- Axure 手机页面拖动效果
1.设置好上下固定们,中间放一个动态面板,如下图所示,(刚开始创建是没有图片的) 2.再状态1下再创建一个动态面板 命名为D2,如下图所示 3.在D2的状态1下新建一个宽370(大概手机宽)高1100 ...
- RestTemplate发送get请求并携带请求头
//设置请求头 HttpHeaders headers = new HttpHeaders(); headers.add("X-Access-Token", huaWenToken ...
- 【python爬虫】对站长网址中免费简历模板进行爬取
本篇仅在于交流学习 解析页面 可以采用xpath进行页面连接提取 进入页面 通过进入的页面可以得到下载地址 步骤: 提取表页面模板链接-->进入连接-->提取页面内下载地址连接--> ...
- Vue中使用富文本编辑器
原文链接:https://blog.csdn.net/qq_45695853/article/details/114635009
- 2020-12-08:TIME_WAIT的等待时间为什么是2MSL?
福哥答案2020-12-08:[答案来自此链接:](http://bbs.xiangxueketang.cn/question/646)这里假设主动关闭方为A,被动关闭方为B,TIME_WAIT状态是 ...
- 2022-06-10:薯队长从北向南穿过一片红薯地(南北长M,东西宽N),红薯地被划分为1x1的方格, 他可以从北边的任何一个格子出发,到达南边的任何一个格子, 但每一步只能走到东南、正南、西南方向的
2022-06-10:薯队长从北向南穿过一片红薯地(南北长M,东西宽N),红薯地被划分为1x1的方格, 他可以从北边的任何一个格子出发,到达南边的任何一个格子, 但每一步只能走到东南.正南.西南方向的 ...
- Django4全栈进阶之路19 项目实战(用户管理):user_delete.html用户删除画面设计
1.user_list.html删除按钮链接设置: <td> <a class="btn btn-danger btn-xs" href="{% url ...
- docker快速启动proxy_pool项目
docker快速启动proxy_pool项目 项目地址:https://github.com/jhao104/proxy_pool 0x01 搭建redis 该项目是基于redis的,所以我们首先需要 ...
- flex弹性布局模式下文字超出显示省略号
都知道flex弹性布局非常好用,会随分辨率不同,宽高自适,那怎么来设置在一定范围内的文字超出隐藏,显示省略号呢?其实也不难 看如下就是使用flex布局的 其实如上效果也同样离不开如下三句,只是用法不大 ...
- hvv蓝初面试常见漏洞问题(上)
1.SQL注入 漏洞成因: 可控变量 变量会带入数据库查询 变量不存在过滤或者变量过滤不严格 注入流程 判断是否有注入点 order by 判断字段数量 union select 报错查看注入点 使用 ...