自然语言处理(NLP) - 前预训练时代的自监督学习
前预训练时代的自监督学习自回归、自编码预训练的前世

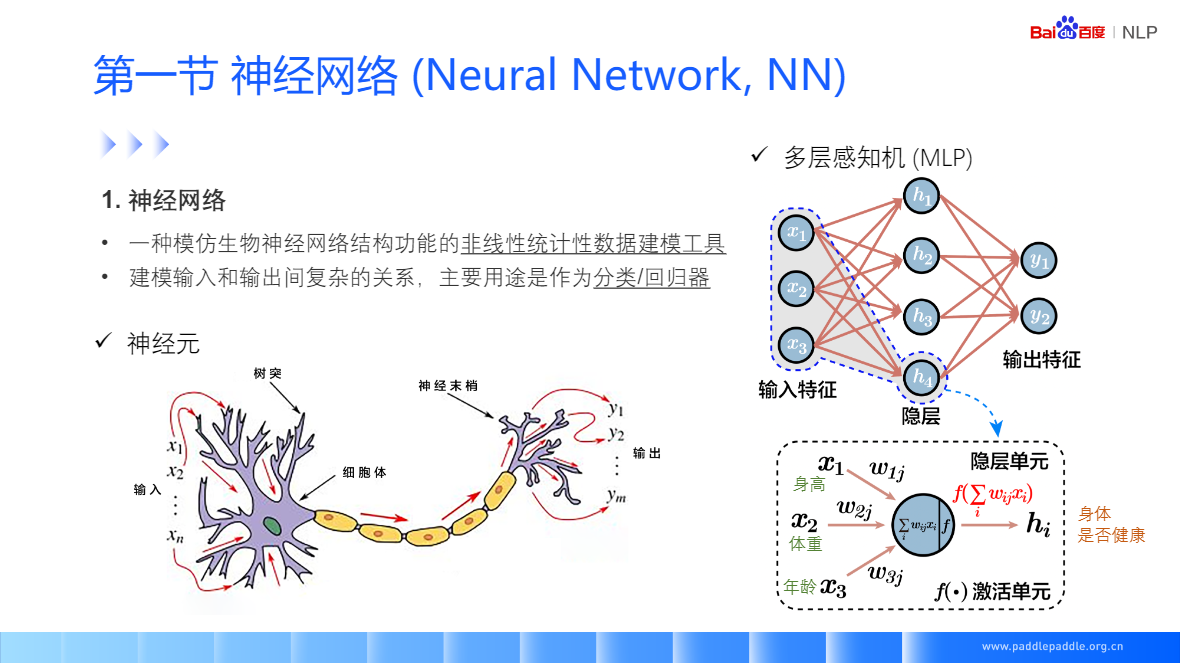
神经网络(Neural Network, NN)
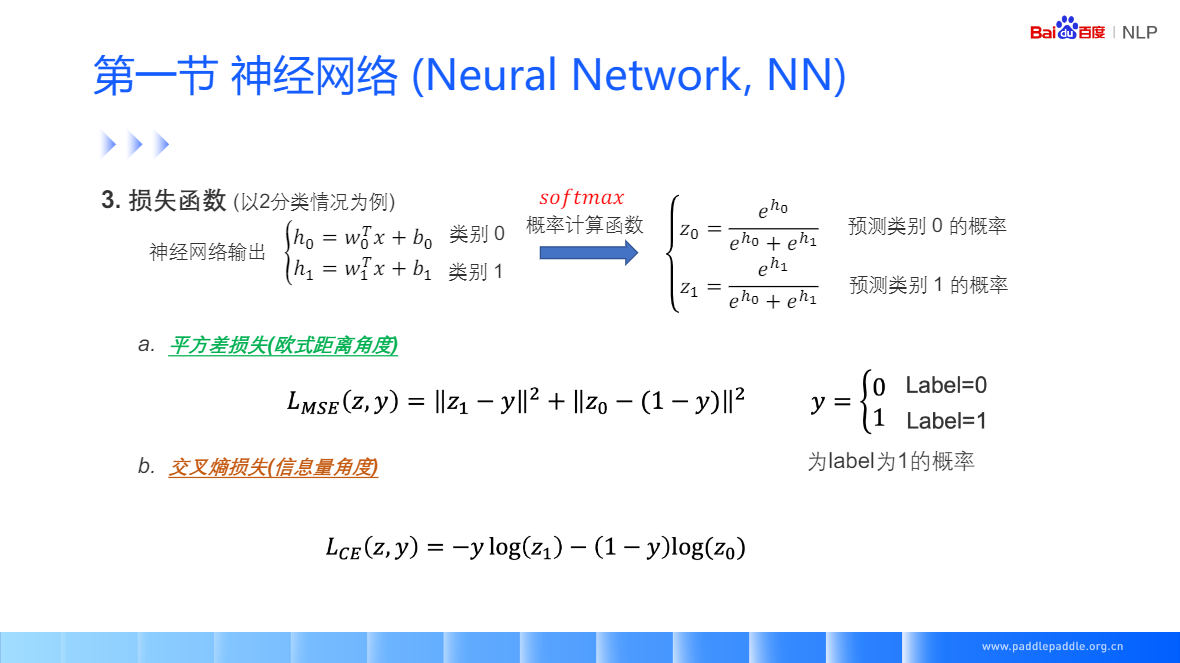
损失函数,度量神经网络的预测结果和真实结果相差多少
- 平方差损失(欧式距离角度)预测概率分部和实际标签概率的欧式距离
- 交叉熵损失(信息量角度)预测概率分部和真实概率分部的差异,指导神经网络学习时,更加稳定
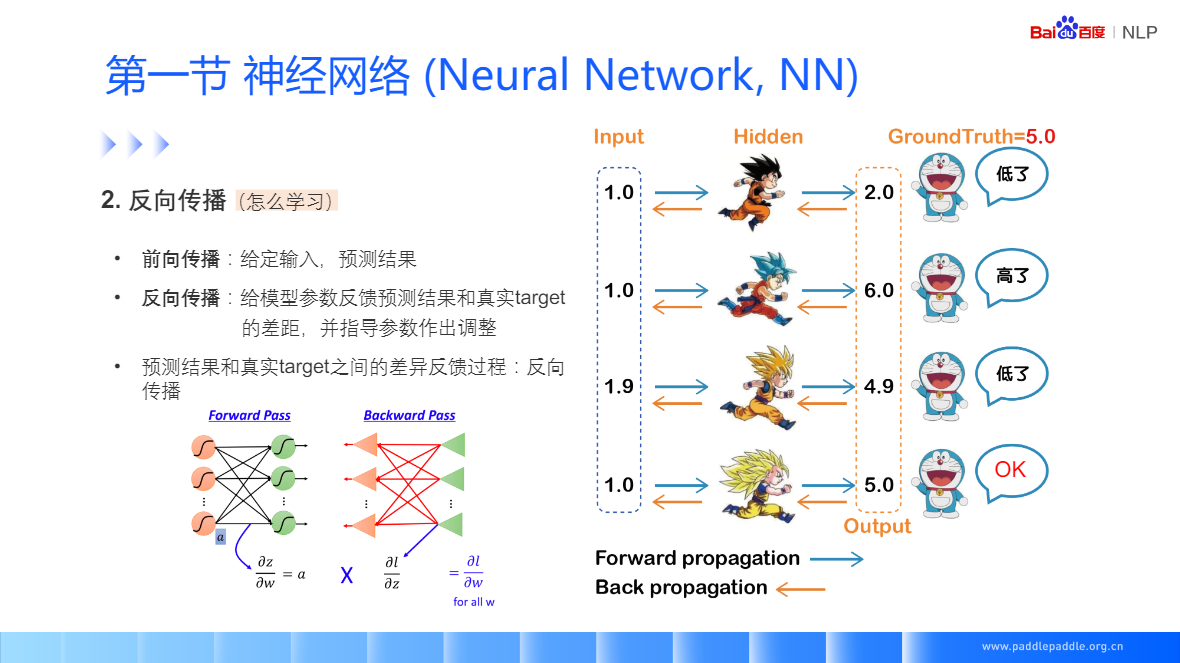
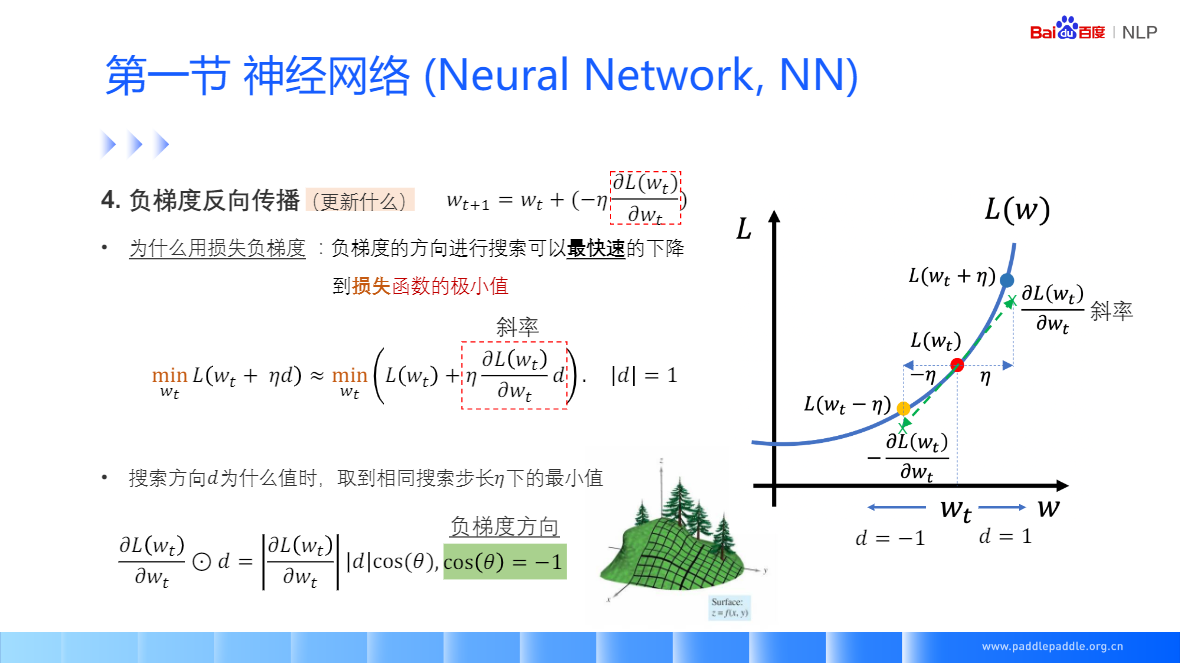
对参数W更新损失的负梯度
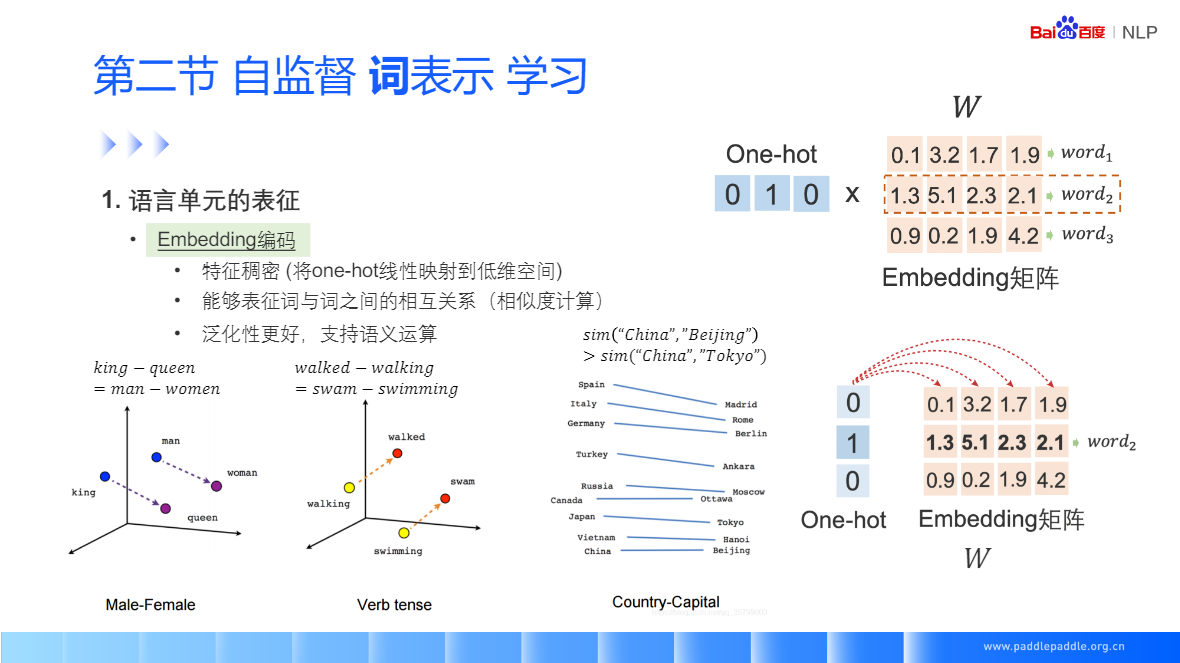
One-hot 人为规定,不需要学习,在推荐里有非常多的用处,(可以理解成完全命中)

词向量需要学习,可以很好的泛化结果,泛化性能比 one-hot 更好(可以理解成泛化关系的建模)
评估模型的好坏:有全体指标,以及一些公开的数据集,去评估词向量的相关性

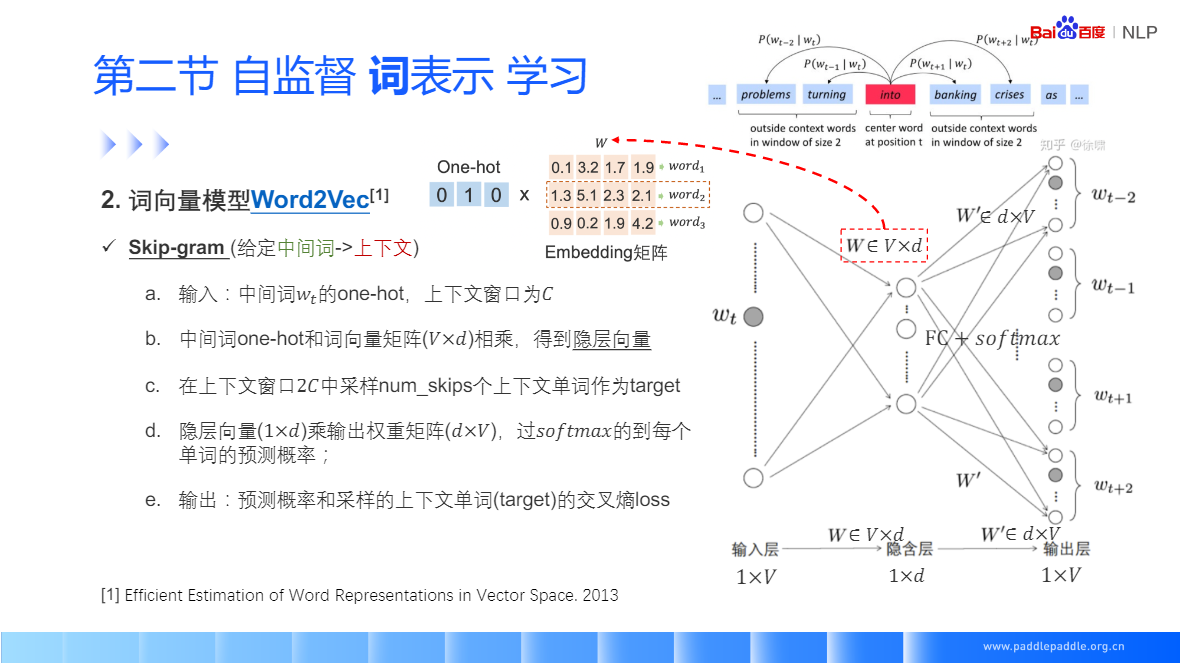
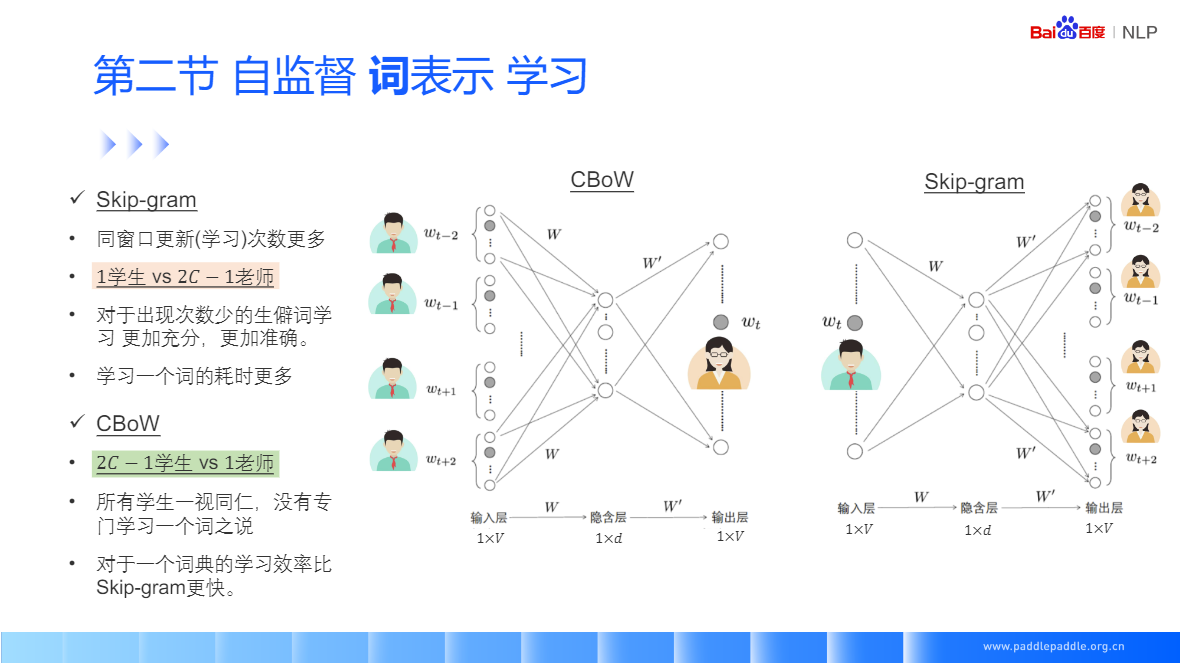
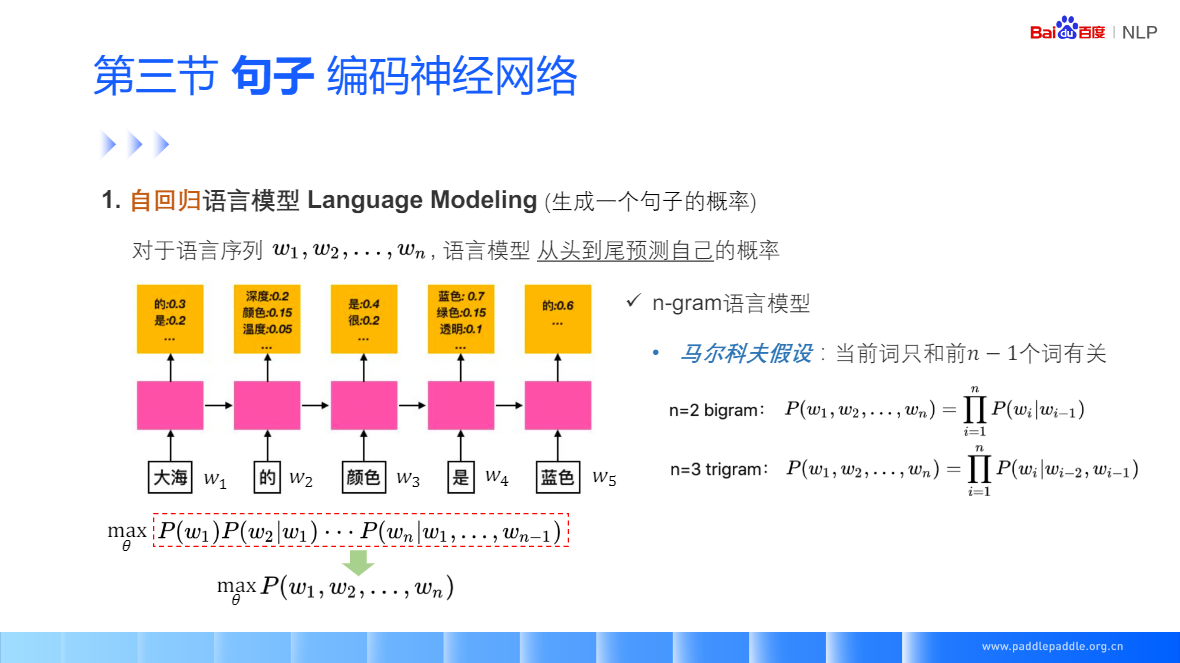
Skip-gram: 给定一个中间值,预测上下文窗口中的一个词

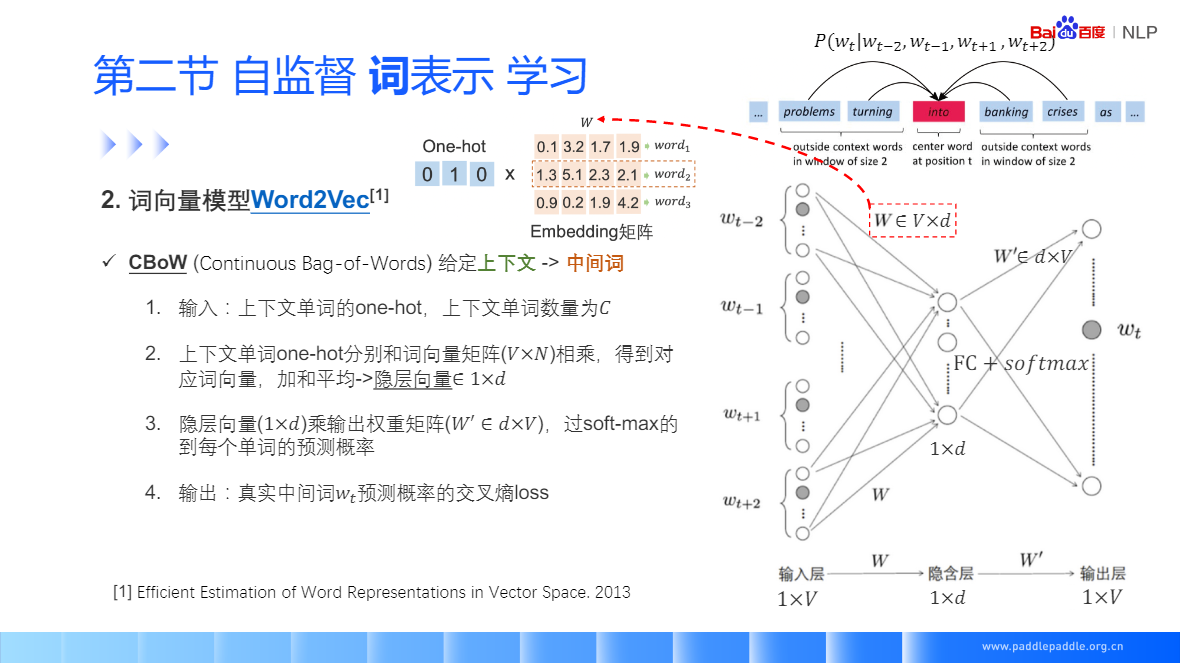
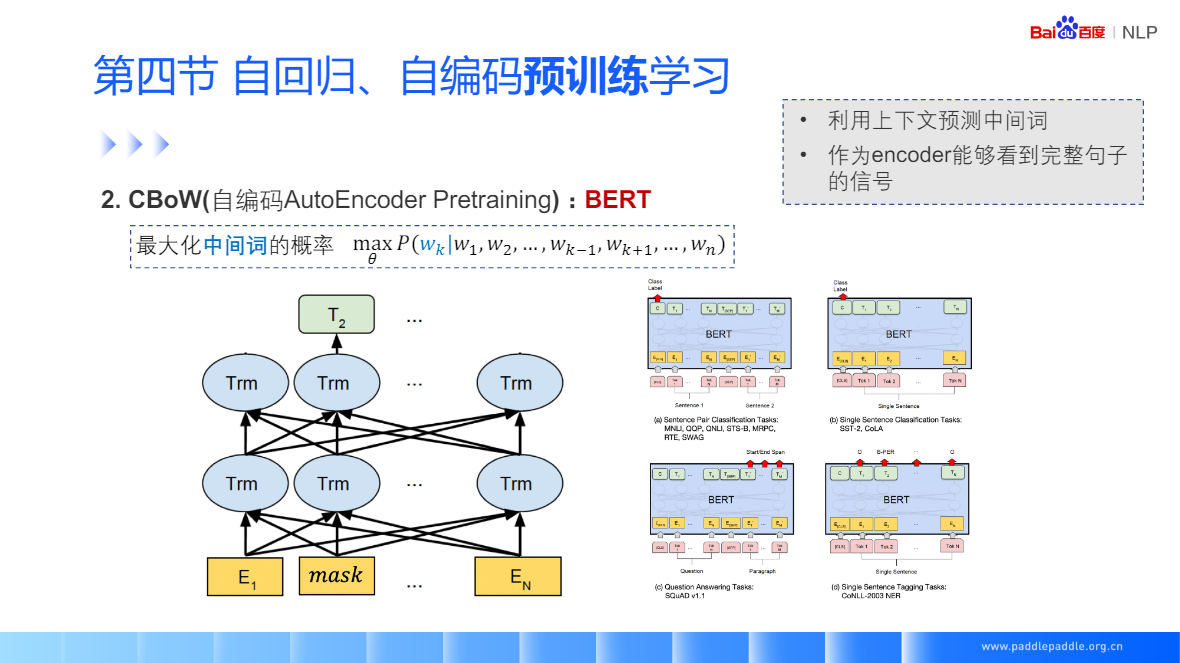
CBoW:给定一个上下文词,预测中间值
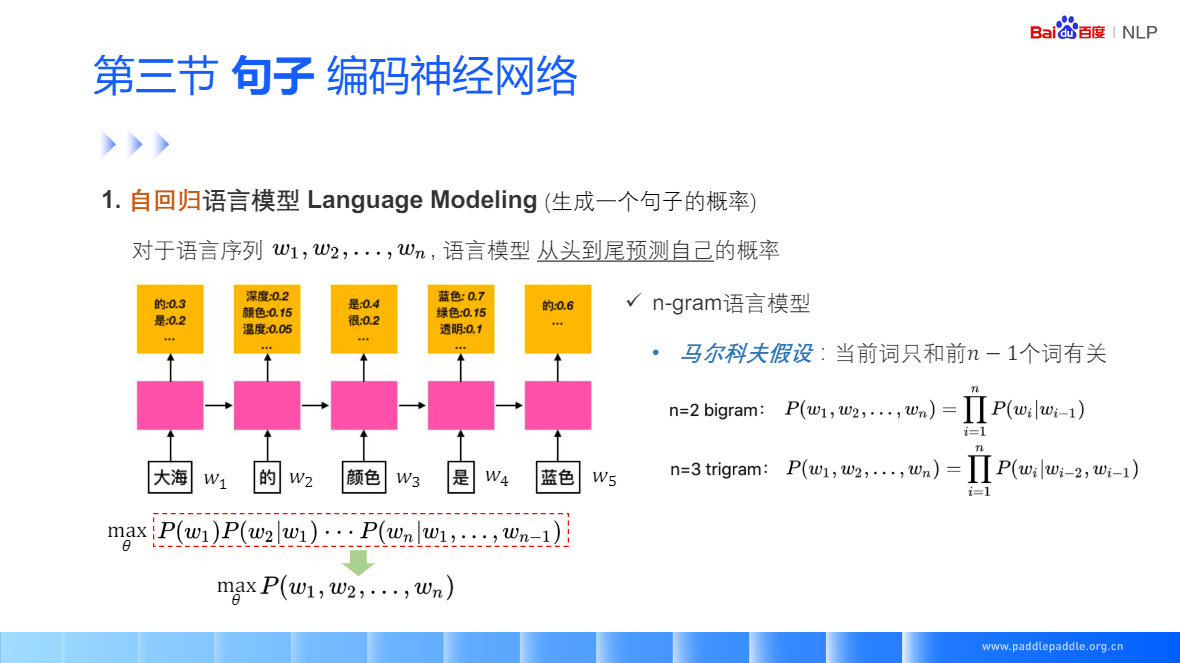
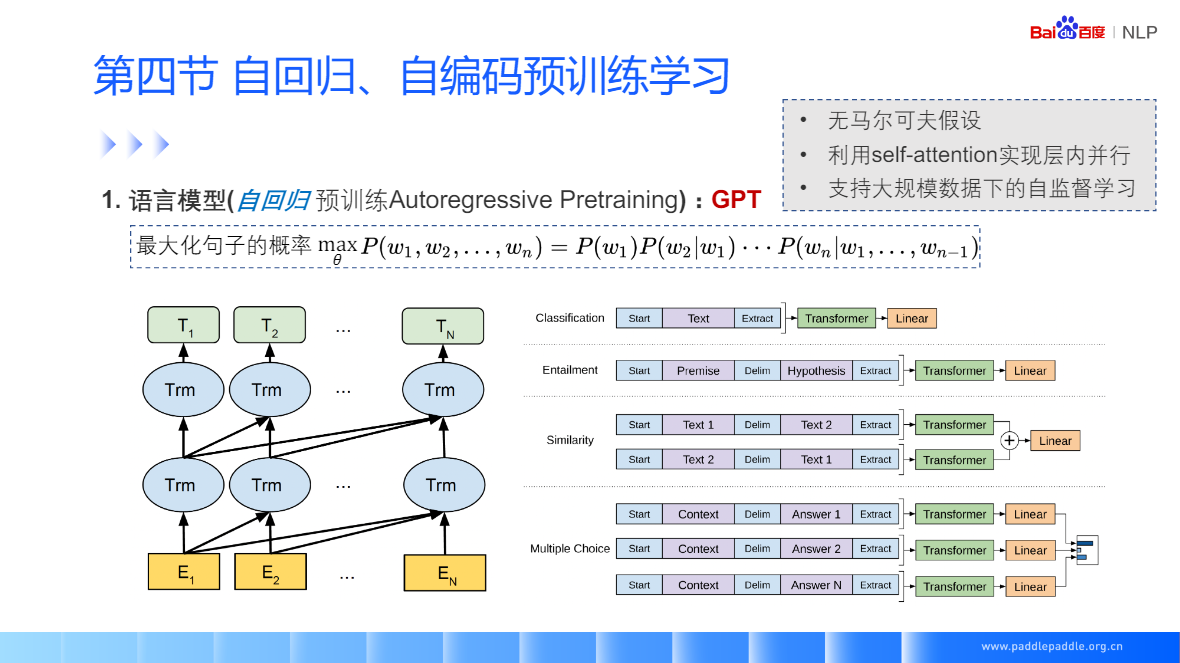
RNN 抛开马尔科夫假设,
Self-Attention:每个单词和整句所有话进行匹配,来获取当前单词对每个单词的重视程度,利用这个重视程序,对整句话的每个单词进行加权,加权的结果用于表示当前这个单词
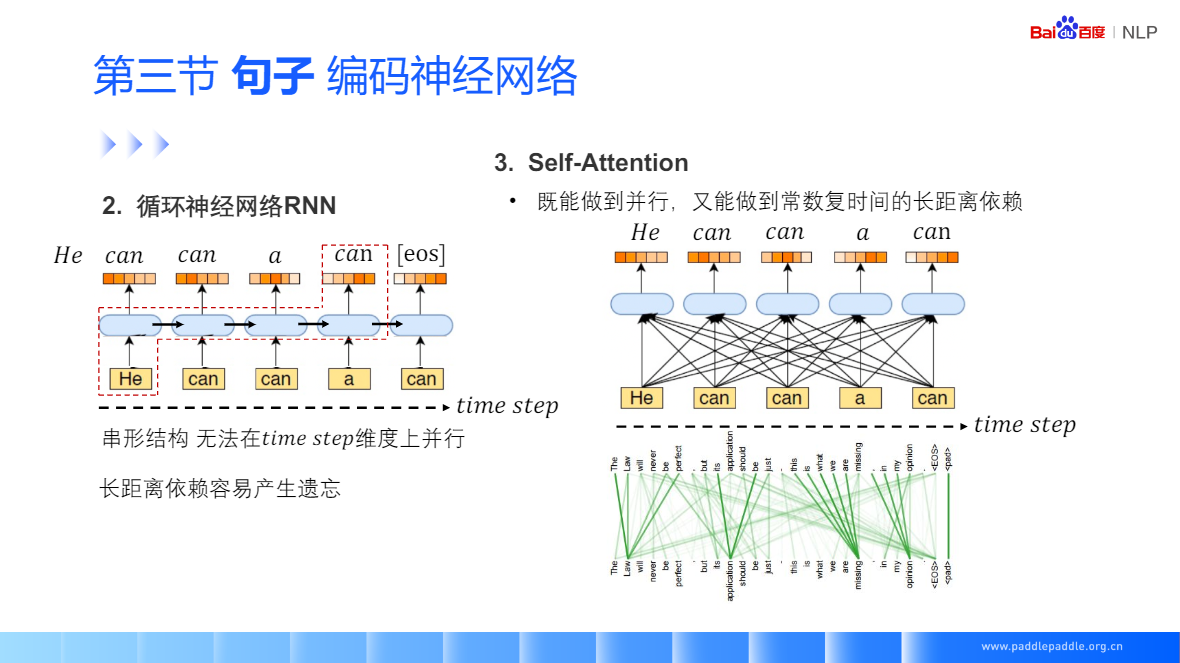
Self-Attention:也是非常流行的 Transformer 的核心模块,
Seft-Attention 没有考虑单词的顺序,所以为了更精装的表示位置信息,需要对句子的输入加个位置的序号 Positional Embedding
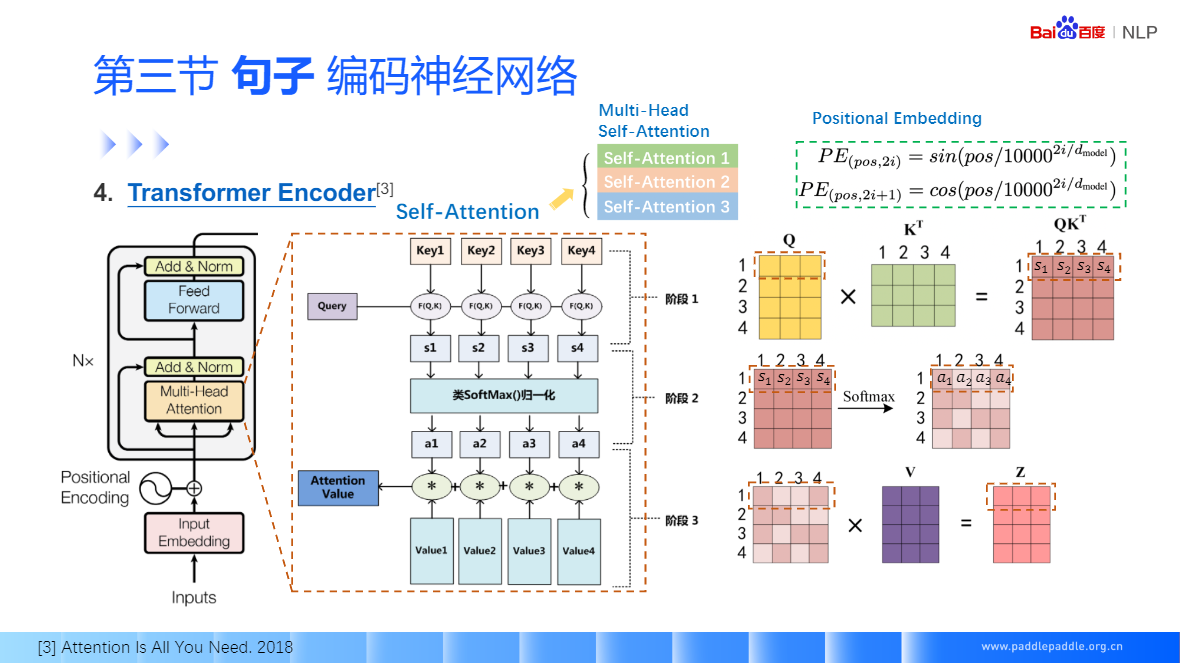
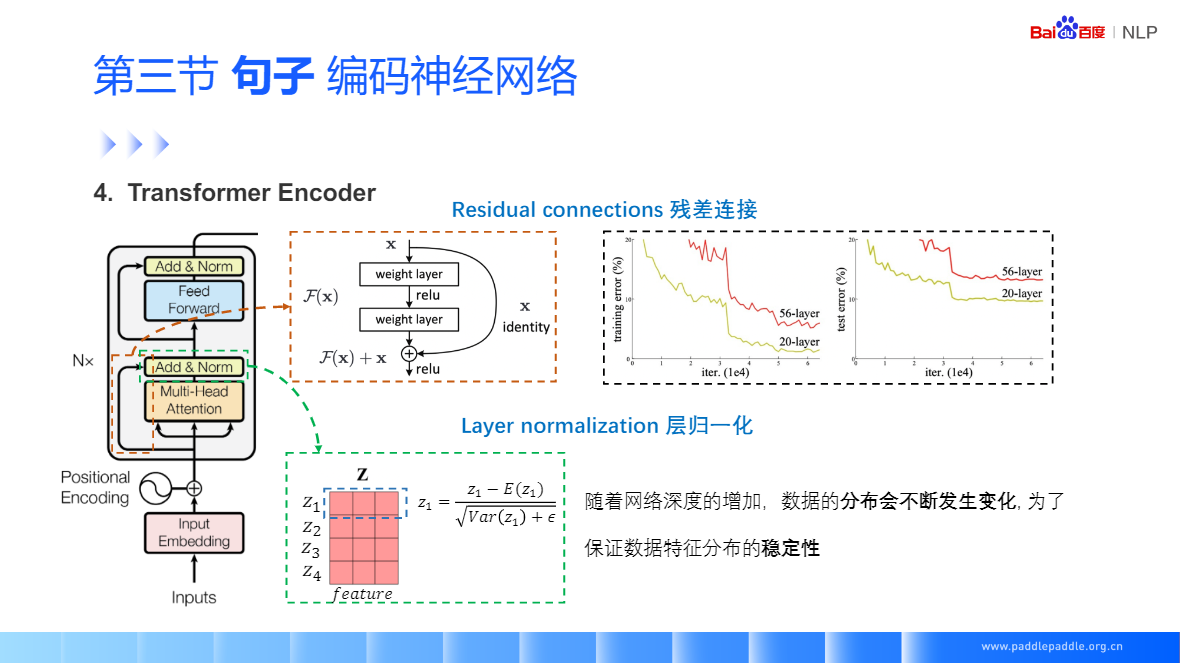
残差连接,很好的缓解梯度消失的问题,包括映射和直连接部分
https://aistudio.baidu.com/aistudio/education/lessonvideo/1451160
自然语言处理(NLP) - 前预训练时代的自监督学习的更多相关文章
- NLP之预训练
内容是结合:https://zhuanlan.zhihu.com/p/49271699 可以直接看原文 预训练一般要从图像处理领域说起:可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预 ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 预训练中Word2vec,ELMO,GPT与BERT对比
预训练 先在某个任务(训练集A或者B)进行预先训练,即先在这个任务(训练集A或者B)学习网络参数,然后存起来以备后用.当我们在面临第三个任务时,网络可以采取相同的结构,在较浅的几层,网络参数可以直接加 ...
- BERT总结:最先进的NLP预训练技术
BERT(Bidirectional Encoder Representations from Transformers)是谷歌AI研究人员最近发表的一篇论文:BERT: Pre-training o ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- NLP中的预训练语言模型(一)—— ERNIE们和BERT-wwm
随着bert在NLP各种任务上取得骄人的战绩,预训练模型在这不到一年的时间内得到了很大的发展,本系列的文章主要是简单回顾下在bert之后有哪些比较有名的预训练模型,这一期先介绍几个国内开源的预训练模型 ...
- NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa. 一,SpanBERT 论文:SpanBERT: Improving Pre-training by Represe ...
随机推荐
- JVM Dump分析
Thread Dump介绍 Thread Dump是非常有用的诊断 Java应用问题的工具.每一个 Java虚拟机都有及时生成所有线程在某一点状态的 thread-dump的能力,虽然各个 Java虚 ...
- 【Visual Leak Detector】QT 中 VLD 输出解析(四)
说明 使用 VLD 内存泄漏检测工具辅助开发时整理的学习笔记. 目录 说明 1. 使用方式 2. 测试代码 3. 使用 32 bit 编译器时的输出 4. 使用 64 bit 编译器时的输出 5. 输 ...
- 快收藏!最全GO语言实现设计模式
https://segmentfault.com/a/1190000042859564
- Distinctive Image Features from Scale-Invariant Keypoints 论文解读
Distinctive Image Features from Scale-Invariant Keypoints 论文解读 著名的SIFT local feature提取方法 Scale-space ...
- docker中跑MySQL
mkdir xxx 创建一个目录 cd xxx 进入该目录 运行: sudo docker run -p 3306:3306 --name mymysql \ --restart=always -v ...
- wpf CommunityToolkit.Mvvm8.1 MVVM工具包安装引用指南
CommunityToolkit.Mvvm包(又名MVVM 工具包,以前名为 Microsoft.Toolkit.Mvvm)是一个现代.快速且模块化的 MVVM 库.它支持:.NET Standard ...
- 欢迎使用园子的 vscode 插件
为了方便大家通过 vscode 编辑博文,我们做了一个小插件,插件名称是"博客园Cnblogs客户端",插件列表中搜索"博客园"或者 "cnblogs ...
- 600 条最强 Linux 命令总结
600 条最强 Linux 命令总结 每博一文案 你有千万条微博想写,可有些根本不重要,后来你才懂那是你怕别人看穿你所以才把真话埋在日常里.你有千万句话想说,可点开那 个对话框,你根本打不出一个字.你 ...
- mysql导出csv
1.正常查询 SELECT a.emp_no '员工号',b.seq '文章序号' from vote_records a INNER JOIN vote_content b ON a.vote_co ...
- $el,$nextTick,$set
this.$el this.$el DOM的根元素 => 是一个完全唯一的 $el 直到组件挂载完成 (mounted) 之前都会是 undefined. 对于单一根元素的组件,$el 将会指向 ...