Java日志系列:Log4j使用和原理分析
一、简介
Log4j是Apache下的一款开源的日志框架,通过在项目中使用 Log4J,我们可以控制日志信息输出到控制台、文件、甚至是数据库中。我们可以控制每一条日志的输出格式,通过定义日志的输出级别,可以更灵活的控制日志的输出过程。方便项目的调试。
官方网站: http://logging.apache.org/log4j/1.2/
二、使用
建立maven工程
添加依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
- java代码
package com.mcode.log4j;
import org.apache.log4j.BasicConfigurator;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.junit.Test;
/**
* ClassName: Log4jTest
* Package: com.mcode.log4j
* Description:
*
* @Author: robin
* @Create: 2023/8/16 - 9:05 PM
* @Version: v1.0
*/
public class Log4jTest {
/**
* 快速使用
* @throws Exception
*/
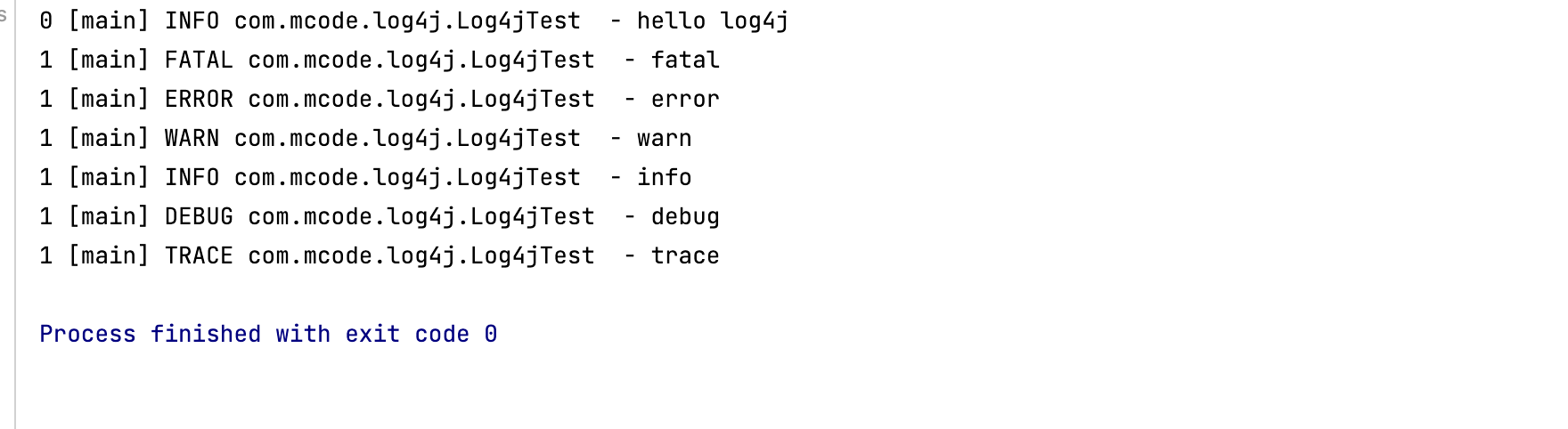
@Test
public void testQuick() throws Exception{
// 初始化系统配置,不需要配置文件
BasicConfigurator.configure();
// 创建日志记录器对象
Logger logger = Logger.getLogger(Log4jTest.class);
// 日志记录输出
logger.info("hello log4j");
// 日志级别
logger.fatal("fatal"); // 严重错误,一般会造成系统崩溃并终止运行
logger.error("error"); // 错误信息,不会影响系统运行
logger.warn("warn"); // 警告信息,可能会发生问题
logger.info("info"); // 运行信息,数据连接、网络连接、IO 操作等等
logger.debug("debug"); // 调试信息,一般在开发中使用,记录程序变量参数传递信息等等
logger.trace("trace"); // 追踪信息,记录程序所有的流程信息
}
}

三、日志级别
每个Logger都被了一个日志级别(log level),用来控制日志信息的输出。日志级别从高到低分为:
fatal 指出每个严重的错误事件将会导致应用程序的退出。
error 指出虽然发生错误事件,但仍然不影响系统的继续运行。
warn 表明会出现潜在的错误情形。
info 一般和在粗粒度级别上,强调应用程序的运行全程。
debug 一般用于细粒度级别上,对调试应用程序非常有帮助。 (默认级别)
trace 是程序追踪,可以用于输出程序运行中的变量,显示执行的流程。
还有两个特殊的级别:
OFF,可用来关闭日志记录。
ALL,启用所有消息的日志记录。
注:一般只使用4个级别,优先级从高到低为 ERROR > WARN > INFO > DEBUG
四、组件说明
Log4J 主要由 Loggers (日志记录器)、Appenders(输出端)和 Layout(日志格式化器)组成。其中Loggers 控制日志的输出级别与日志是否输出;Appenders 指定日志的输出方式(输出到控制台、文件等);Layout 控制日志信息的输出格式。
Loggers
日志记录器,负责收集处理日志记录,实例的命名就是类“XX”的full quailied name(类的全限定名),Logger的名字大小写敏感,其命名有继承机制:例如:name为org.apache.commons的logger会继承name为org.apache的logger。
Log4J中有一个特殊的logger叫做“root”,他是所有logger的根,也就意味着其他所有的logger都会直接或者间接地继承自root。root logger可以用Logger.getRootLogger()方法获取。
但是,自log4j 1.2版以来, Logger 类已经取代了 Category 类。对于熟悉早期版本的log4j的人来说,Logger 类可以被视为 Category 类的别名。
Appenders
Appender 用来指定日志输出到哪个地方,可以同时指定日志的输出目的地。Log4j 常用的输出目的地有以下几种:
| 输出端类型 | 作用 |
|---|---|
| ConsoleAppender | 将日志输出到控制台 |
| FileAppender | 将日志输出到文件中 |
| DailyRollingFileAppender | 将日志输出到一个日志文件,并且每天输出到一个新的文件 |
| RollingFileAppender | 将日志信息输出到一个日志文件,并且指定文件的尺寸, 当文件大小达到指定尺寸时,会自动把文件改名,同时产生一个新的文件 |
| JDBCAppender | 把日志信息保存到数据库中 |
Layouts
布局器 Layouts用于控制日志输出内容的格式,让我们可以使用各种需要的格式输出日志。Log4j常用的Layouts:
| 格式化器类型 | 作用 |
|---|---|
| HTMLLayout | 格式化日志输出为HTML表格形式 |
| SimpleLayout | 简单的日志输出格式化,打印的日志格式为(info - message) |
| PatternLayout | 最强大的格式化期,可以根据自定义格式输出日志,如果没有指定转换格式, 就是用默认的转换格式 |
五、配置
加载初始化配置
Log4j 需要编写配置文件才能正常使用,不过在没有提供配置文件的时候,Log4j 自带了一个基本配置,在代码中加载该基本配置,即可使用 Log4j 的日志记录器。
不配置默认会报错

配置
BasicConfigurator.configure();

可以观察到基本配置所作的事:向root日志记录器添加Appender,所添加的Appender是一个ConsoleAppender,并且该Appender设置了一个Layout,该Layout是一个PatternLayout。
该基本配置的加载也表明了使用Log4j完成日志记录的三要素:Logger, Appender, Layout.
配置文件加载
LogManager 定义了Log4j 使用的配置文件名。最常使用是名为"log4j.properties" 的配置文件。
配置文件是在LogManager的静态代码块中被加载的。在LogManager的静态代码块中,log4j.properties 文件在maven工程的resources 文件夹下被搜寻, 并由类 PropertyConfigurator 完成加载。
根据PropertyConfigurator中的方法,可以推测出配置文件的编写方式,下面给出配置文件的最简示例:
# 指定 RootLogger 顶级父元素默认配置信息
# 指定日志级别=trace,使用的 apeender 为=myAppender
log4j.rootLogger = trace,console
# 指定控制台日志输出的 appender
log4j.appender.myAppender = org.apache.log4j.ConsoleAppender
# 指定消息格式 layout
log4j.appender.myAppender.layout = org.apache.log4j.SimpleLayout
查看日志记录器的详细信息
我们使用日志记录器来记录应用程序的信息,Log4j使用LogLog对象记录日志框架本身的详细信息。
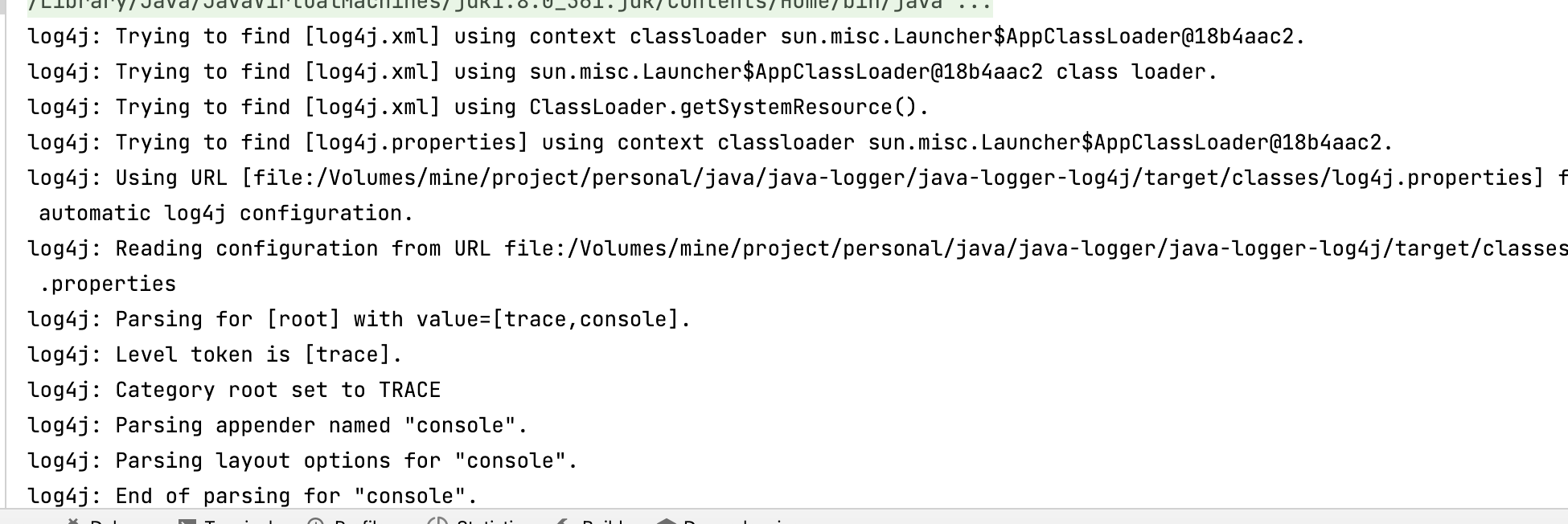
所以,开启LogLog对象的调试标志,就能看到日志框架本身的详细信息:
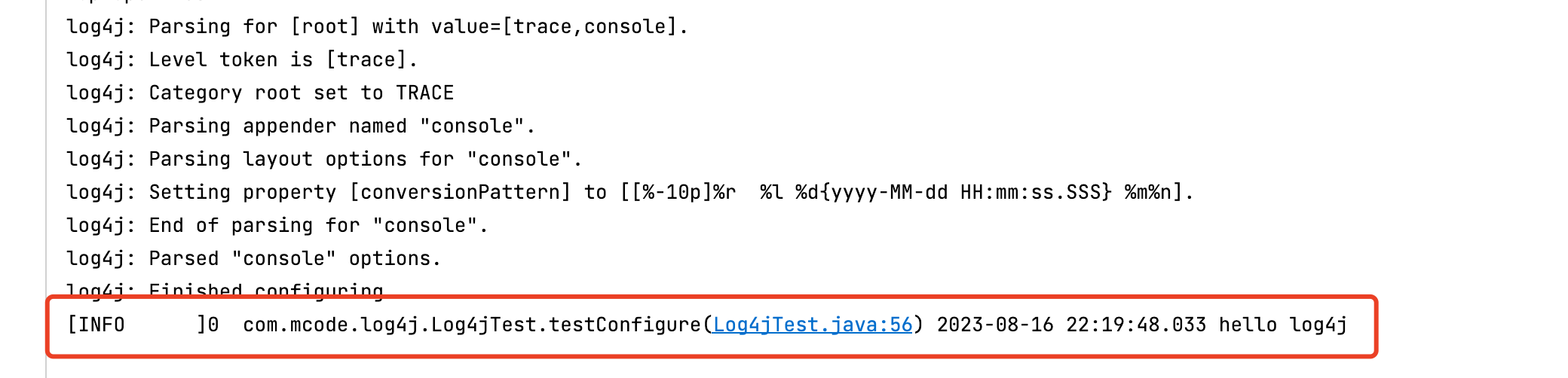
@Test
public void testConfigure() throws Exception {
//当配置了log4j.properties的时候不需要默认的配置
//BasicConfigurator.configure();
// 开启 log4j 内置调试日志记录
LogLog.setInternalDebugging(true);
// 创建日志记录器对象
Logger logger = Logger.getLogger(Log4jTest.class);
logger.info("hello log4j");
}
六、Layout的格式
各个Appender可以设置以下Layout,用于定义日志信息输出格式。
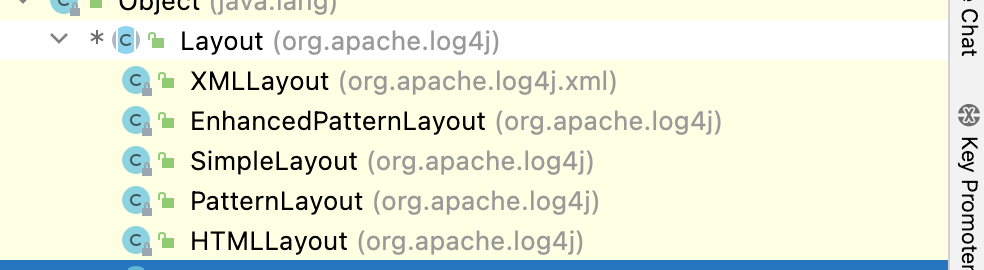
虽然log4j提供了多种日志输出格式,不过,最常用的日志输出格式是PatternLayout。
在 log4j.properties 配置文件中,我们定义了日志输出级别与输出端,在输出端中分别配置日志的输出格式。
* log4j 采用类似 C 语言的 printf 函数的打印格式格式化日志信息,具体的占位符及其含义如下:
%m 输出代码中指定的日志信息
%p 输出优先级,及 DEBUG、INFO 等
%n 换行符(Windows平台的换行符为 "\n",Unix 平台为 "\n")
%r 输出自应用启动到输出该 log 信息耗费的毫秒数
%c 输出打印语句所属的类的全名
%t 输出产生该日志的线程全名
%d 输出服务器当前时间,默认为 ISO8601,也可以指定格式,如:%d{yyyy年MM月dd日 HH:mm:ss}
%l 输出日志时间发生的位置,包括类名、线程、及在代码中的行数。如: Test.main(Test.java:10)
%F 输出日志消息产生时所在的文件名称
%L 输出代码中的行号 %% 输出一个 "%" 字符
* 可以在 % 与字符之间加上修饰符来控制最小宽度、最大宽度和文本的对其方式。如:
%5c 输出category名称,最小宽度是5,category<5,默认的情况下右对齐
%-5c 输出category名称,最小宽度是5,category<5,"-"号指定左对齐,会有空格
%.5c 输出category名称,最大宽度是5,category>5,就会将左边多出的字符截掉,<5不 会有空格
%20.30c category名称<20补空格,并且右对齐,>30字符,就从左边交远销出的字符截掉
log4j.properties
# 指定 RootLogger 顶级父元素默认配置信息
# 指定日志级别=trace,使用的 apeender 为=console
log4j.rootLogger = trace,console
# 指定控制台日志输出的 appender
log4j.appender.console = org.apache.log4j.ConsoleAppender
# 指定消息格式 layout
log4j.appender.console.layout = org.apache.log4j.PatternLayout
# 指定消息格式的内容
log4j.appender.console.layout.conversionPattern = [%-10p]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS} %m%n
七、Appender的输出
FileAppender
通过FileAppender,可以将日志输出到文件
查看类FileAppender,可以发现FileAppender独有的配置信息:
- fileAppend —— 是否以追加的形式记录日志;
- fileName —— 文件路径;
- bufferedIO —— 是否设置缓冲区;
- bufferSize —— 缓冲区大小;
这里值得注意的是fileAppend属性,默认是以“追加”的形式记录日志的。
下面给出将日志输出到文件的配置文件示例
# 指定 RootLogger 顶级父元素默认配置信息
# 指定日志级别=trace,使用的 apeender 为=file
log4j.rootLogger = trace,file
# 日志文件输出的 appender 对象
log4j.appender.file = org.apache.log4j.FileAppender
# 指定消息格式 layout
log4j.appender.file.layout = org.apache.log4j.PatternLayout
# 指定消息格式的内容
log4j.appender.file.layout.conversionPattern = [%-10p]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS} %m%n
# 指定日志文件保存路径
log4j.appender.file.file = logs/log4j.log
# 指定日志文件的字符集
log4j.appender.file.encoding = UTF-8
默认在项目目录下

RollingFileAppender
RollingFileAppender 同样把日志输出到文件,但是会对文件按大小进行拆分。
protected long maxFileSize = 10485760L;
protected int maxBackupIndex = 1;
RollingFileAppender 是 FileAppender 的子类,拥有 FileAppender 的所有配置,此外还多了如下几个配置选项。
- maxFileSize —— 日志文件的内容大小上限;
- maxBackIndex —— 日志文件数量上限;
# 指定 RootLogger 顶级父元素默认配置信息
# 指定日志级别=trace,使用的 apeender 为=file
log4j.rootLogger = trace,file
# 日志文件输出的 appender 对象
log4j.appender.file = org.apache.log4j.RollingFileAppender
# 指定消息格式 layout
log4j.appender.file.layout = org.apache.log4j.PatternLayout
# 指定消息格式的内容
log4j.appender.file.layout.conversionPattern = [%-10p]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS} %m%n
# 指定日志文件保存路径
log4j.appender.file.file = logs/log4j.log
# 指定日志文件的字符集
log4j.appender.file.encoding = UTF-8
#设置最大文件大小
log4j.appender.file.maxFileSize = 1M
#设置日志文件数量上限
log4j.appender.file.maxBackIndex = 10
DailyRollingFileAppender
DailyRollingFileAppender 也是 FileAppender 的子类,按照时间进行日志文件的拆分。
private String datePattern = "'.'yyyy-MM-dd";
DailyRollingFileAppender 使用 datePattern 属性指示的形式,定义轮转日志的文件名,该形式可以自由指定,但是必须遵循相应的规则。
下面给出配置文件示例:
# 指定 RootLogger 顶级父元素默认配置信息
# 指定日志级别=trace,使用的 apeender 为=file
log4j.rootLogger = trace,file
# 日志文件输出的 appender 对象
log4j.appender.file = org.apache.log4j.DailyRollingFileAppender
# 指定消息格式 layout
log4j.appender.file.layout = org.apache.log4j.PatternLayout
# 指定消息格式的内容
log4j.appender.file.layout.conversionPattern = [%-10p]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS} %m%n
# 指定日志文件保存路径
log4j.appender.file.file = logs/log4j.log
# 指定日志文件的字符集
log4j.appender.file.encoding = UTF-8
#设置最大文件大小
log4j.appender.file.datePattern = '.'yyyy-MM-dd HH-mm-ss

JDBCAppender
JDBCAppender 用于将日志信息保存到数据库中,从类JDBCAppender的set方法中,可以得知JDBCAppender独有的属性设置:
- sql —— 将日志插入到数据库的sql语句;
- driver —— 数据库驱动类名;
- URL —— 数据库地址;
- user —— 数据库用户名;
- password —— 数据库密码;
- bufferSize —— 缓冲区大小
当然,为了完成数据插入,首先需要在数据库中建立相应的table,这里以mysql为例,展示JDBCAppender的用法。
CREATE TABLE `log` (
`log_id` int(11) NOT NULL AUTO_INCREMENT,
`project_name` varchar(255) DEFAULT NULL COMMENT '目项名',
`create_date` varchar(255) DEFAULT NULL COMMENT '创建时间',
`level` varchar(255) DEFAULT NULL COMMENT '优先级',
`category` varchar(255) DEFAULT NULL COMMENT '所在类的全名',
`file_name` varchar(255) DEFAULT NULL COMMENT '输出日志消息产生时所在的文件名称 ',
`thread_name` varchar(255) DEFAULT NULL COMMENT '日志事件的线程名',
`line` varchar(255) DEFAULT NULL COMMENT '号行',
`all_category` varchar(255) DEFAULT NULL COMMENT '日志事件的发生位置',
`message` varchar(4000) DEFAULT NULL COMMENT '输出代码中指定的消息',
PRIMARY KEY (`log_id`) );
添加pom依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
添加配置文件
在编写日志插入到数据库的sql语句的时候,注意到,可以使用PatternLayout的占位符完成sql语句的动态生成。
# 指定 RootLogger 顶级父元素默认配置信息
# 指定日志级别=trace,使用的 apeender 为=logDB
log4j.rootLogger = trace,logDB
#mysql
log4j.appender.logDB=org.apache.log4j.jdbc.JDBCAppender
log4j.appender.logDB.layout=org.apache.log4j.PatternLayout
log4j.appender.logDB.Driver=com.mysql.jdbc.Driver
log4j.appender.logDB.URL=jdbc:mysql://localhost:3306/test
log4j.appender.logDB.User=root
log4j.appender.logDB.Password=123456
log4j.appender.logDB.Sql=INSERT INTO log(project_name,create_date,level,category,file_name,thread_name,line,all_category,message) values('mcode','%d{yyyy-MM-dd HH:mm:ss}','%p','%c','%F','%t','%L','%l','%m')
测试

八、日志记录器的层级关系
以上的日志配置都是针对rootLogger的,其它层级的日志默认继承rootLogger的配置。
可以对特定的日志进行配置,定制不同层级的日志记录的方案。
关于日志记录器的继承体系,有两点需要注意:
- 关于日志等级:以在继承体系中最靠近自身的日志等级为主;
- 关于日志输出:取继承体系中所有Appender的并集。
以如下场景举例:
配置文件log4j.properties:
# 指定 RootLogger 顶级父元素默认配置信息
# 指定日志级别=trace,使用的 apeender 为=console
log4j.rootLogger = trace,console
# 自定义 logger 对象设置
log4j.logger.com.mcode.log4j.Log4jTest = trace,console1
# 指定控制台日志输出的 appender
log4j.appender.console = org.apache.log4j.ConsoleAppender
# 指定消息格式 layout
log4j.appender.console.layout = org.apache.log4j.PatternLayout
# 指定消息格式的内容
log4j.appender.console.layout.conversionPattern = [console]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS} %m%n
# 指定控制台日志输出的 appender
log4j.appender.console1 = org.apache.log4j.ConsoleAppender
# 指定消息格式 layout
log4j.appender.console1.layout = org.apache.log4j.PatternLayout
# 指定消息格式的内容
log4j.appender.console1.layout.conversionPattern = [console1]%r %l %d{yyyy-MM-dd HH:mm:ss.SSS} %m%n
可以看到,在继承体系中,有两个appender,取并集,结果一条输出语句打印了两条日志。

Java日志系列:Log4j使用和原理分析的更多相关文章
- java多线程系列(九)---ArrayBlockingQueue源码分析
java多线程系列(九)---ArrayBlockingQueue源码分析 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 j ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- Java并发系列[5]----ReentrantLock源码分析
在Java5.0之前,协调对共享对象的访问可以使用的机制只有synchronized和volatile.我们知道synchronized关键字实现了内置锁,而volatile关键字保证了多线程的内存可 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- Java并发系列[3]----AbstractQueuedSynchronizer源码分析之共享模式
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取.在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快 ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- java多线程系列(六)---线程池原理及其使用
线程池 前言:如有不正确的地方,还望指正. 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 java多线程系列(三)之等待通知 ...
- Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析
学习Java并发编程不得不去了解一下java.util.concurrent这个包,这个包下面有许多我们经常用到的并发工具类,例如:ReentrantLock, CountDownLatch, Cyc ...
- 拨云见日,彻底弄清楚Java日志框架 log4j, logback, slf4j的区别与联系
log4j 以及 logback, slf4j 官网 日志框架的困惑 作为一个正常的项目,是必须有日志框架的存在的,没有日志,很难追踪一些奇奇怪怪的系统问题. 但是,我们经常在项目的依赖中,见到奇奇怪 ...
随机推荐
- 限速神器RateLimiter源码解析
作者:京东科技 李玉亮 目录指引 限流场景 软件系统中一般有两种场景会用到限流: •场景一.高并发的用户端场景. 尤其是C端系统,经常面对海量用户请求,如不做限流,遇到瞬间高并发的场景,则可能压垮系统 ...
- GRPC与 ProtoBuf 的理解与总结
转载请注明出处: 1.GRPC 官网:https://www.grpc.io/ gRPC 官方文档中文版:http://doc.oschina.net/grpc RPC 框架的目标就是让远程服务调用更 ...
- git解决一个电脑多用户情况(win7)
首先:在输入ssh-keygen -t rsa -C "注册邮箱"后不要急着按enter,此时输入秘钥对的文件名,不要跟默认文件重名(默认的是id_rsa)
- js有关dom操作学习
dom对象就是操作网页的document dom节点: 整个文档是一个文档节点(document对象) 每个 HTML 元素是元素节点(element 对象) HTML 元素内的文本是文本节点(tex ...
- 使用 conda 和 Jupyter 在 R 中实现数据科学分析
前两篇文章我们介绍了 Jupyter Notebook 的一些基础用法,今天我们来介绍一下如何使用 conda 和 Jupyter 在 R 中开始一个数据科学项目. 在开始之前我们先要明确一个概念:K ...
- 发现了阿里云 APP 的一个小 BUG
由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访问文中链接. 前几天在华为手机上使用阿里云 APP,从 oss bucket 中下载了一张图片,想要通过微信 ...
- Docker化Spring Boot应用
本文翻译自国外论坛 medium,原文地址:https://medium.com/@bubu.tripathy/dockerizing-your-spring-boot-application-75b ...
- 韩顺平Spring体系化笔记(内含ioc,aop,动态代理等底层原理)
Spring Spring 核心学习内容 IOC.AOP. JdbcTemplate.声明式事务 1.Spring 几个重要概念 Spring 可以整合其他的框架(Spring 是管理框架的框架) S ...
- 前端热力图组件heatMapGD中国地图 中国热力地图 广东省热力地图 广东省地图 地市选择
快速实现前端中国热力地图 广东省热力地图 广东省地图, 请访问uni-app插件市场地址:https://ext.dcloud.net.cn/plugin?id=12407 # china 广东省热力 ...
- React学习时,outlet配置(token判定,页面path监听)
尽管写过 outlet 路由的配置. 考虑到 token 判定和 路由页 变更,我不了解v6是不是有更详解的做法. 决定调一下配置,期望 在任何页面异步更新时,token 都可以在跳转前 被检测到,防 ...