机器学习 Logistic 回归
Logistic regression
适用于二分分类的算法,用于估计某事物的可能性。
logistic分布表达式
$ F(x) = P(X<=x)=\frac{1}{1+e^{\frac{-(x-\mu)}{\gamma}}} $
$ f(x) = F{'}(x)=\frac{e{\frac{-(x-\mu)}{\gamma}}}{\gamma(1+e{\frac{-(x-\mu)}{\gamma}}){2}} $
函数图像
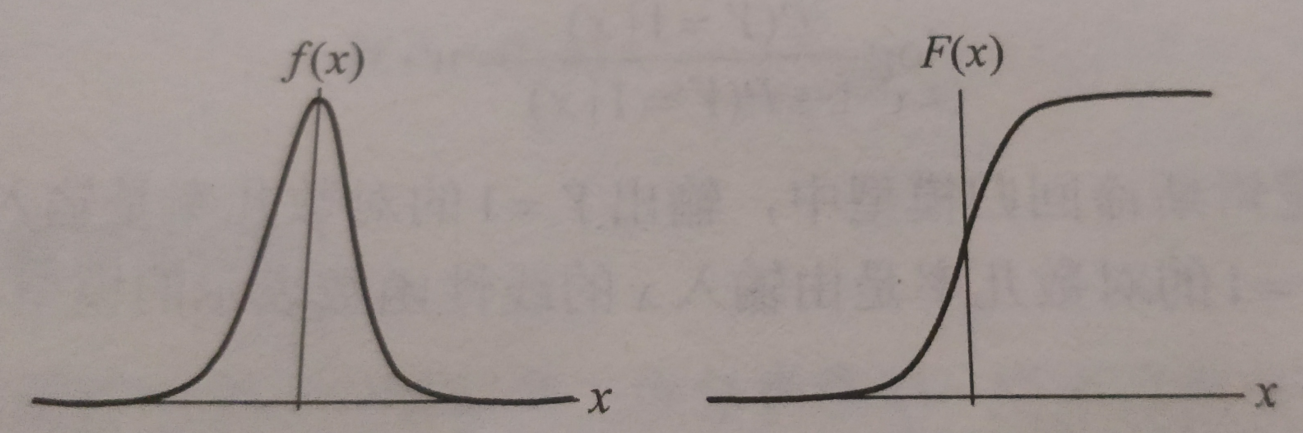
分布函数属于逻辑斯谛函数,以点 \((\mu,\frac{1}{2})\) 为中心对称
逻辑回归是一种学习算法,用于有监督学习问题时,输出y都是0或1。逻辑回归的目标是最小化预测和训练数据之间的误差。
公式推导

代码实现
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
return data[:, :2], data[:, -1]
class LogisticRegressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.01, random_state=4):
self.max_iter = max_iter
self.learning_rate = learning_rate
self.weights = None
def sigmoid(self, x):
return 1 / (1 + exp(-x))
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d])
return data_mat
def fit(self, X, y):
data_mat = self.data_matrix(X)
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]])
print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter))
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
if __name__ == '__main__':
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
lr_clf = LogisticRegressionClassifier()
lr_clf.fit(X_train, y_train)
print('the score = {}'.format(lr_clf.score(X_test, y_test)))
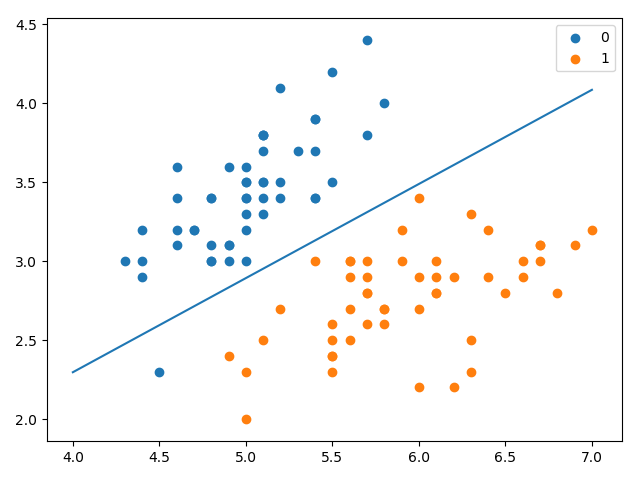
x_ponits = np.arange(4, 8)
y_ = -(lr_clf.weights[1] * x_ponits + lr_clf.weights[0]) / lr_clf.weights[2]
plt.plot(x_ponits, y_)
# lr_clf.show_graph()
plt.scatter(X[:50, 0], X[:50, 1], label='0')
plt.scatter(X[50:, 0], X[50:, 1], label='1')
plt.legend()
plt.show()
LogisticRegression Model(learning_rate=0.01,max_iter=200)
the score = 0.9666666666666667
sklearn中的logistic regression
sklearn.linear_model.LogisticRegression
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=200, multi_class='warn',
n_jobs=None, penalty='l2', random_state=None, solver='liblinear',
tol=0.0001, verbose=0, warm_start=False)
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=200,solver='liblinear')
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
print(clf.coef_, clf.intercept_)
输出
0.9666666666666667
[[ 1.96863514 -3.31358598]] [-0.36853861]
机器学习 Logistic 回归的更多相关文章
- 机器学习——Logistic回归
1.基于Logistic回归和Sigmoid函数的分类 2.基于最优化方法的最佳回归系数确定 2.1 梯度上升法 参考:机器学习--梯度下降算法 2.2 训练算法:使用梯度上升找到最佳参数 Logis ...
- 机器学习——Logistic回归
参考<机器学习实战> 利用Logistic回归进行分类的主要思想: 根据现有数据对分类边界线建立回归公式,以此进行分类. 分类借助的Sigmoid函数: Sigmoid函数图: Sigmo ...
- 机器学习——logistic回归,鸢尾花数据集预测,数据可视化
0.鸢尾花数据集 鸢尾花数据集作为入门经典数据集.Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理.Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集.数据集包含150个数 ...
- 机器学习--Logistic回归
logistic回归 很多时候我们需要基于一些样本数据去预测某个事件是否发生,如预测某事件成功与失败,某人当选总统是否成功等. 这个时候我们希望得到的结果是 bool型的,即 true or fals ...
- coursera机器学习-logistic回归,正则化
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 机器学习-- Logistic回归 Logistic Regression
转载自:http://blog.csdn.net/linuxcumt/article/details/8572746 1.假设随Tumor Size变化,预测病人的肿瘤是恶性(malignant)还是 ...
- 吴恩达-机器学习+Logistic回归分类方案
- 机器学习简易入门(四)- logistic回归
摘要:使用logistic回归来预测某个人的入学申请是否会被接受 声明:(本文的内容非原创,但经过本人翻译和总结而来,转载请注明出处) 本文内容来源:https://www.dataquest.io/ ...
- 机器学习(4)之Logistic回归
机器学习(4)之Logistic回归 1. 算法推导 与之前学过的梯度下降等不同,Logistic回归是一类分类问题,而前者是回归问题.回归问题中,尝试预测的变量y是连续的变量,而在分类问题中,y是一 ...
随机推荐
- vue学习起步:了解下
渐进式 有这么一句话,vue是渐进式框架. 抽取“渐进式框架”和“自底向上增量开发的设计”这两个概念是什么?中的解释: 渐进式代表的含义是:主张(主张指使用时的硬性要求)最少.来个对比就知道什么叫主张 ...
- Toy Train(贪心)
题目链接:http://codeforces.com/contest/1130/problem/D1 题目大意:给你n个点,然后m条运输任务,然后问你从每个点作为起点是,完成这些运输任务的最小花费?每 ...
- SpringBoot注解把配置文件自动映射到属性和实体类实战
SpringBoot注解把配置文件自动映射到属性和实体类实战 简介:讲解使用@value注解配置文件自动映射到属性和实体类 1.配置文件加载 方式一 1.Controller上面配置 @Propert ...
- ubuntu14.04下 Kinect V2+Ros接口安装
1. 首先git下载代码,放到主文件夹下面 git clone https://github.com/OpenKinect/libfreenect2.git 2. 然后安装依赖项如下,最好事先编译安装 ...
- 如何在linux下检测内存泄漏(转)
本文转自:http://www.ibm.com/developerworks/cn/linux/l-mleak/ 本文针对 linux 下的 C++ 程序的内存泄漏的检测方法及其实现进行探讨.其中包括 ...
- MySQL 误操作后数据恢复(update,delete忘加where条件)【转】
在数据库日常维护中,开发人员是最让人头痛的,很多时候都会由于SQL语句 写的有问题导致服务器出问题,导致资源耗尽.最危险的操作就是在做DML操作的时候忘加where条件,导致全表更新,这是作为运维或者 ...
- phantomjs 解码url
以下为部分代码: var htmlnodeInfo=(allADUrlElements.snapshotItem(i).getAttribute("href").match(/\* ...
- 【转】Visual Studio——多字节编码与Unicode码
多字节字符与宽字节字符 1) char与wchar_t 我们知道C++基本数据类型中表示字符的有两种:char.wchar_t. char叫多字节字符,一个char占一个字节,之所以叫多字节字符是因为 ...
- centos6.5环境下zookeeper-3.4.6集群环境部署及单机部署详解
centos6.5环境下Zookeeper-3.4.6集群环境部署 [系统]Centos 6.5 集群部署 [软件]准备好jdk环境,此次我们的环境是open_jdk1.8.0_101 zookeep ...
- ajax post 传参数加引号和不加引号的区别
1.前言 用ajax技术,type:post,data:参数列表.参数列表就是一个JSON数据,但key可以加引号,也可以不加引号,那总有区别的. 2.区别 var d2 = "two&qu ...