039 hive中关于数据库与表等的基本操作
一:基本用法
1.新建数据库

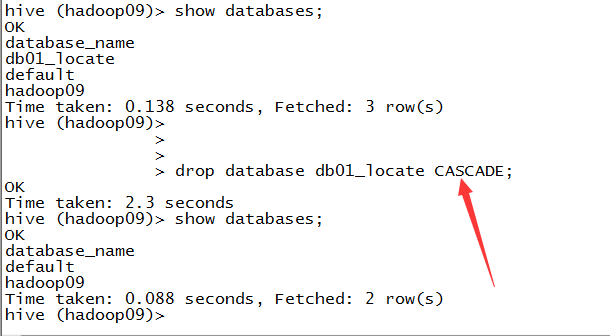
2.删除数据库

3.删除非空的数据库
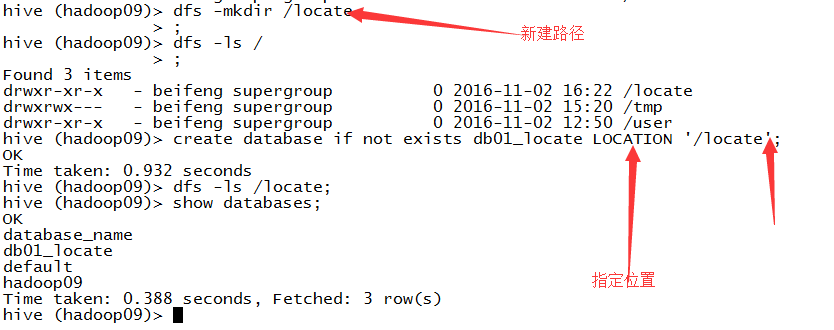
4.指定数据库的位置
LOCATION:指定数据库的位置,不会在系统的默认文件下。
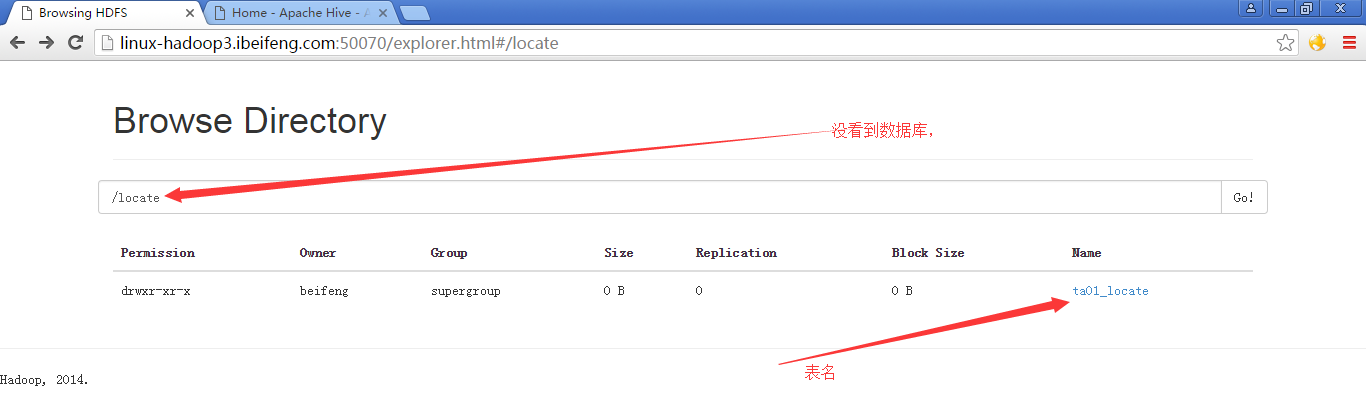
5.在指定数据库中新建表(验证在指定的数据库中可以建表)

6.在页面上观看表
可以看到在指定的目录下有一张新建的表。
但是,没有看到指定的数据库。
7.新建表

8.删除一张表
drop table if exists student;

9.清空一张表

10.加载数据
1)从本地加载

2)从HDFS上加载

3)区别:
移动。

11.查询

12.描述一张表
一张表的一些信息。

13.查看方法

14.描述方法

二:hive的参数的用法
1.到指定的数据库

2.命令行执行SQL

3.执行文件里的sql

4.启动时指定hive的陪置

5.查看当前的配置,更可以更改配置

三.hive shell中常用的操作
1.访问本地文件系统

2.访问hdfs

四.hive中表的使用
1.创建表的三种方式
1)第一种方式:普通方式

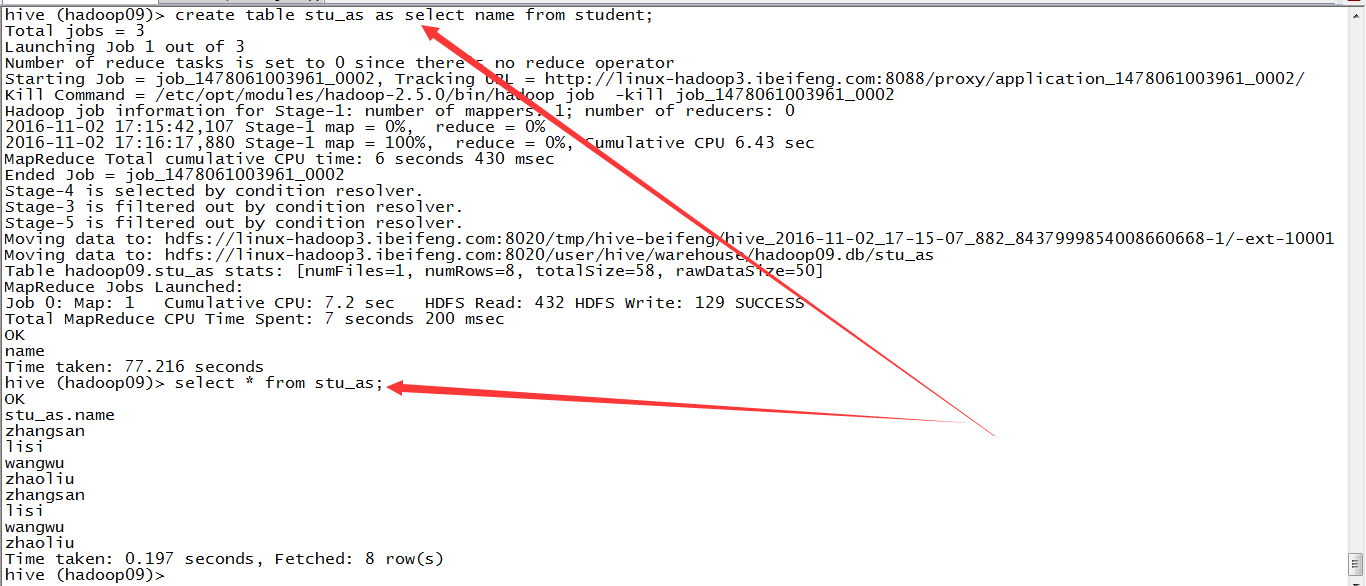
2)第二种方式:as select ,子查询方式
特点:将子查询的数据和结构复制给新的表。
3)第三种方式:like
特点:复制表的结构。

2.表的类型
1)新建员工表

2)新建部门表

3)默认表的类型:管理表
4)问题:文件还有一份,多人使用时,可以通过location指定创建多张表

看在HDFS中的效果

没有加载数据,但是依旧可以使用emp的数据,因为使用的目录。

如果这时候删除掉emp1:
这时,会删除掉元数据的信息,同时删除在HDFS中表的两个文件夹emp与emp1,但是hive中还保留着emp。
5)解决方案
使用外部表。
3.创建外部表
这时,在HDFS上依旧只有一张dept的元数据表。
两个地方:external,location。

4.EXCERANL新建的是外部表
可以看描述信息。

5.外部表的好处
这时,删掉dept_ext,dept表的元数据依然还在。
6.管理表与外部表的区别
管理表的删除操作:先删除元数据,然后删除表的文件夹
外部表的删除操作:只删除元数据
五:分区表
1.分区表需求
当前的web服务器上的log文件,需求是对前一天日志进行分析:
20161019.log
20161020.log
20161021.log
20161022.log
第一种: /logs/20161019.log
20161020.log
20161021.log
20161022.log
select * from logs where date='20161022';
这种情况是:先加载再过滤,其实意思是,这些数据会全部加载到mapreduce,然后才选择自己需要的数据。
第二种: /logs/20161019/20161019.log
/20161020/20161020.log
select * from logs where date='20161022';
这种情况是:会直接加载加载相应的文件到mapreduce。
2.新建分区表
其中,by后面的字段是一个逻辑字段,在表中是没有的。
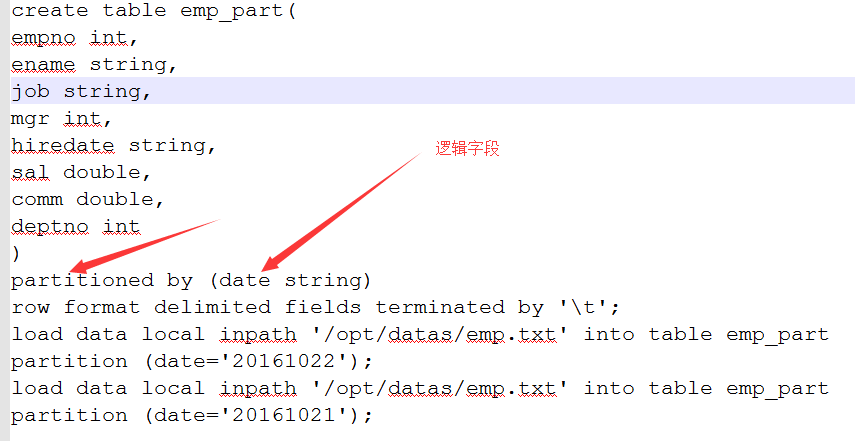
这时,HDFS上出现字段。这个情况是必须加载完数据才会出现的情况,不然没有分区的字段值。

3.分区表查询
分区表的全部查询:
select * from emp;
然后可以根据字段进行过滤:
select * from emp where date='20161021';
为啥可以这么做?因为,在全部的查询中,会发现多了一个date的字段,所以可以作为条件进行过滤。
4.多级分区

5.多级分区的效果

039 hive中关于数据库与表等的基本操作的更多相关文章
- hive中关于数据库与表等的基本操作
一:基本用法 1.新建数据库 2.删除数据库 3.删除非空的数据库 4.指定数据库的位置 LOCATION:指定数据库的位置,不会在系统的默认文件下. 5.在指定数据库中新建表(验证在指定的数据库中可 ...
- Hive中的数据库、表、数据与HDFS的对应关系
1.hive数据库 我们在hive终端,查看数据库信息,可以看出hive有一个默认的数据库default,而且我们还知道hive数据库对应的是hdfs上面的一个目录,那么默认的数据库default到底 ...
- Hive中的数据库(Database)和表(Table)
在前面的文章中,介绍了可以把Hive当成一个"数据库",它也具备传统数据库的数据单元,数据库(Database/Schema)和表(Table). 本文介绍一下Hive中的数据库( ...
- SQL Server中查询数据库及表的信息语句
/* -- 本文件主要是汇总了 Microsoft SQL Server 中有关数据库与表的相关信息查询语句. -- 下面的查询语句中一般给出两种查询方法, -- A方法访问系统表,适应于SQL 20 ...
- SQL中查看数据库各表的大小
SQL中查看数据库各表的大小 编写人:CC阿爸 2014-6-17 在日常SQL数据库的操作中,如何快速的查询数据库中各表中数据的大小. 以下有两种方法供参考: 第一种: create table # ...
- impala不能查询hive中新增加的表问题
使用Cloudera Manager部署安装的CDH和Impala,Hive中新增加的表,impala中查询不到,其原因是/etc/impala/conf下面没有hadoop和hive相关的 ...
- hive中与hbase外部表join时内存溢出(hive处理mapjoin的优化器机制)
与hbase外部表(wizad_mdm_main)进行join出现问题: CREATE TABLE wizad_mdm_dev_lmj_edition_result as select * from ...
- hive中使用正則表達式不当导致执行奇慢无比
业务保障部有一个需求,须要用hive实时计算上一小时的数据.比方如今是12点,我须要计算11点的数据,并且必须在1小时之后执行出来.可是他们用hive实现的时候发现就单个map任务执行都超过了1小时, ...
- 在hive中查询导入数据表时FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
当我们出现这种情况时 FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least ...
随机推荐
- bzoj1477: 青蛙的约会(exgcd)
昨天打code+的时候发现自己已经不大会exgcd了..赶紧复习一下QAQ 求$ax+by=gcd(a,b)$的解 初始条件 $gcd(a, 0)=a$ $x=1,y=0$ 推导过程 $gcd(a,b ...
- POJ1751 Highways【最小生成树】
题意: 给你N个城市的坐标,城市之间存在公路,但是由于其中一些道路损坏了,需要维修,维修的费用与公路长成正比(公路是直的). 但现有M条公路是完整的,不需要维修,下面有M行,表示不需要维修的道路两端的 ...
- POJ1287 Networking【最小生成树】
题意: 给出n个节点,再有m条边,这m条边代表从a节点到b节点电缆的长度,现在要你将所有节点都连起来,并且使长度最小 思路: 这是个标准的最小生成树的问题,用prim的时候需要注意的是他有重边,取边最 ...
- c#将前端传来的Json解析成对象
描述:因工作中需要将C#中的Json字符串转换为对象,对此记录下. 解决办法: 1.前端传过来的Json字符串,OrderAppModuleJson即前端传递到后端的Json字符串 string st ...
- 记录一个PHP安装redis扩展时的问题
安装过程:https://www.cnblogs.com/pengyunjing/p/8688320.html 由于我之前安装过该扩展,重新安装时没有执行make clean命令,所以安装好出现了下面 ...
- Mask RCNN 简单使用
涉及到的知识点补充: FasterRCNN:https://www.cnblogs.com/wangyong/p/8513563.html RoIPooling.RoIAlign:https://ww ...
- Jetson tk1 安装 usbtoserials 驱动(重新刷机)
一.tk1驱动包,文件系统和源码下载 截止2016年9月1号,tk1最版本为R21.5. (以下三个文件放在同一个文件夹下) 1.driver package(驱动包,相当于安装程序) https:/ ...
- llinux除了软连接本地文件夹同步:mount
mount --bind /srv/dir1 /srv/dir2dir1:被共享的文件夹dir2:需要同步的文件夹
- window系统下远程部署Tomcat
远程访问windows系统,在windows系统上启动tomcat,发布项目.1.拨VPN2.远程桌面连接,cmd --> mstsc 回车,弹出远程桌面连接窗口 3.输入计算机IP:132.2 ...
- [bzoj3123][洛谷P3302] [SDOI2013]森林(树上主席树+启发式合并)
传送门 突然发现好像没有那么难……https://blog.csdn.net/stone41123/article/details/78167288 首先有两个操作,一个查询,一个连接 查询的话,直接 ...