K-近邻
概述
KNN算法本身简单有效,是一种lazy-learning算法;
分类器不需要使用训练集进行训练,训练时间复杂度为0;
KNN分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么KNN的分类时间复杂度为O(n)。
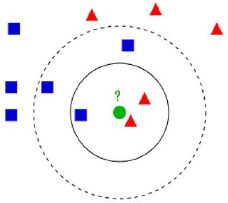
如果K = 3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K = 5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
对于未知类别属性数据集中的点
1.计算已知类别数据集中的点与当前点的距离
2.按照距离一次排序
3.选取与当前点距离最小的K个点
4.确定前K个点所在类别的出现概率
5.返回前K个点出现频率最高的类别作为当前点预测分类
三个基本要素
K值的选择,距离度量和分类决策规则
KNN在分类是主要的不足
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。不同的样本要给予不同权重项。
超参数
L1(Manhattan)distance
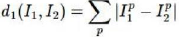
L2(Euclidean)distance
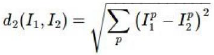
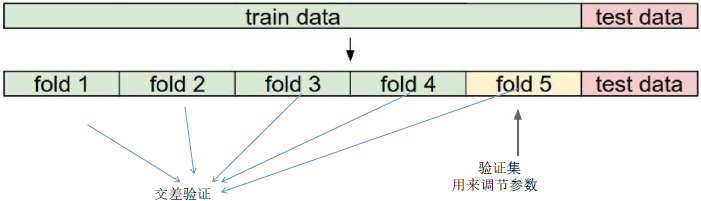
交叉验证
K-近邻注意事项
1、选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好那个;
2、如果训练数据量不够,使用交叉验证方法,它能帮助我们在选取最有超参数的时候减少噪音;
3、一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法;
4、最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试的时候过于耗费计算能力;
5、仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主题分类;
6、对数据进行预处理,对数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance);
7、如果数据是高维数据,考虑使用降维方法,比如PCA;
8、将数据随机分入训练集和验证集。按照一般规律,70%-90%数据作为训练集;
9、在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
K-近邻的更多相关文章
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- k近邻算法(knn)的c语言实现
最近在看knn算法,顺便敲敲代码. knn属于数据挖掘的分类算法.基本思想是在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别.俗话叫,"随大流&q ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- k近邻(KNN)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合内容: 1.算法概述 K近邻算法是一种基本分类和回归方法:分类时,根据其K个最近邻的训练实例的类 ...
- scikit-learn K近邻法类库使用小结
在K近邻法(KNN)原理小结这篇文章,我们讨论了KNN的原理和优缺点,这里我们就从实践出发,对scikit-learn 中KNN相关的类库使用做一个小结.主要关注于类库调参时的一个经验总结. 1. s ...
- 学习笔记——k近邻法
对新的输入实例,在训练数据集中找到与该实例最邻近的\(k\)个实例,这\(k\)个实例的多数属于某个类,就把该输入实例分给这个类. \(k\) 近邻法(\(k\)-nearest neighbor, ...
- k近邻
k近邻(k-NearestNeighbor)算法简称kNN.基本思想简单直接,对于一个需要分类的数据实例x,计算x与所有已知类别的样本点在特征空间中的距离.取与x距离最近的k个样本点,统计这些样本点所 ...
- K近邻分类法
K近邻法 K近邻法:假定存在已标记的训练数据集,分类时对新的实例根据其K个最近邻的训练实例的类别,通过多数表决等分类决策规则进行预测. k近邻不具有显示学习的过程,是“懒惰学习”(lazy learn ...
- 机器学习PR:k近邻法分类
k近邻法是一种基本分类与回归方法.本章只讨论k近邻分类,回归方法将在随后专题中进行. 它可以进行多类分类,分类时根据在样本集合中其k个最近邻点的类别,通过多数表决等方式进行预测,因此不具有显式的学习过 ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
随机推荐
- 华为手机安装 charles 证书
- Class__One HomeWork 实验报告
石家庄铁道大学信息科学与技术学院 实验报告 2018年----2019年 第一学期 题目: 四则运算和验证码 课程名称: JAVA语言程序设计 班 ...
- Linux基础命令---显示树形进程pstree
pstree pstree显示正在运行的进程的树形结构,树以PID为根:如果省略了pid则以init为根.如果指定了用户名,则显示根植于该用户拥有的进程的所有进程树.如果pstree被调用为pstre ...
- Java开发学习教程之对象的创建与使用
java面向对象中的对象创建与使用.类是对象的抽象,为对象定义了属性和行为,但类本身既不带任何数据,也不存在于内存空间中.而对象是类的一个具体存在,既拥有独立的内存空间,也存在独特的属性和行为,属性还 ...
- GoldenGate for bigdata 12.3.1.1
GoldenGate for big data 12.3.1.1在8.18已经发布,主要新特性如下: 1. 新目标:Amazon Kinesis 2. 新目标:使用Kafka Connect API及 ...
- li设置inline-block后,li左边出现空隙问题。
方法1:在ul设置font-size=0,然后再li再单独设置font-size 方法2:li连着写不要换行,也可以解决. <ul> <li>测试1</li>< ...
- Torch或Numpy
1.什么是NumpyNumpy系统是Python的一种开源的数值计算扩展,用python实现的科学计算包.这种工具可用来存储和处理大型矩阵,包括强大的N维数组对象Array,比较成熟的函数库等.num ...
- mysqldump进行复制数据导出导入时的问题
在执行数据导入到从库时,若使用mysqldump命令进行数据导出,应当一次性将需要同步的库导出. mysqldump -uroot -p --single-transaction --database ...
- P3243 [HNOI2015]菜肴制作(拓扑排序)
P3243 [HNOI2015]菜肴制作 题目误导你正着做拓扑排序,然鹅你可以手造数据推翻它.于是就只能倒着做 我们开个优先队列,每次把可填的最大的编号取出来搞,最后倒着输出拓扑序就好辣 #inclu ...
- 针对数据泵导出 (expdp) 和导入 (impdp)工具性能降低问题的检查表 (文档 ID 1549185.1)
针对数据泵导出 (expdp) 和导入 (impdp)工具性能降低问题的检查表 (文档 ID 1549185.1) 文档内容 适用于: Oracle Database – Enterprise Edi ...