HDFS文件系统基操--Java实现
Java实现对HDFS文件系统的基本操作
1.准备好jar包

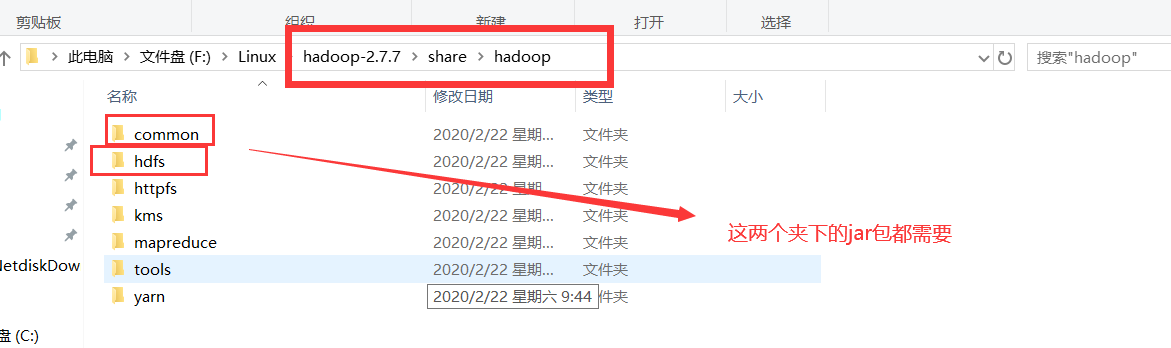
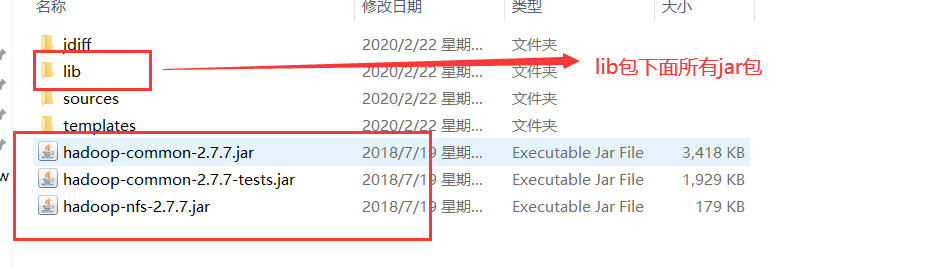
2.创建一个类
1. 测试连接
@Test //测试是否连接成功
public void test() {
//添加配置 ==> core-site.xml
Configuration conf = new Configuration();
//配置默认地址端口
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
//加载配置
FileSystem fs = FileSystem.get(conf);
//获取目标状态 注意:要用绝对路径,且路径都要用Path包起来
FileStatus fst = fs.getFileStatus(new Path("/hello"));
System.out.println(fst.isDirectory()); //是否是文件夹
System.out.println(fst.isFile()); // 是否是文件
System.out.println(fst.getLen()); // 获取长度
System.out.println(fst.getPath()); // 获取路径
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
2. 在文件系统下创建文件夹
@Test //hdfs文件系统中创建文件夹
public void mkdirsFile() {
//添加配置 ==> core-site.xml
Configuration conf = new Configuration();
//配置默认地址端口
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
//加载配置
FileSystem fs = FileSystem.get(conf);
//创建文件夹 注意:要用绝对路径,且路径都要用Path包起来
boolean mkdirs = fs.mkdirs(new Path("/other/test/jdk"));
System.out.print(mkdirs);
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试时,发现出错了,用户Administator在hadoop上执行写操作时被权限系统拒绝,百度(https://blog.csdn.net/xiaoshunzi111/article/details/52062640)发现,解决有三个办法:
1、在hdfs的配置文件中,将dfs.permissions修改为False
2、执行这样的操作 hadoop fs -chmod 777 /user/hadoop
3、在系统的环境变量里面添加HADOOP_USER_NAME=root(HDFS上的有权限的用户,具体看自己的情况),插入代码实现 System.setProperty("HADOOP_USER_NAME", "root");
前两个不太安全,我选用第三个,重启就可以。
3.递归查看文件夹
@Test //hdfs文件系统中遍历文件夹
public void ls() {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
FileStatus[] fls = fs.listStatus(new Path("/"));
for(FileStatus fst:fls) {
judge(fs,fst);
}
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public void judge(FileSystem fs,FileStatus fst) {
String name = fst.getPath().toString().split("hdfs://192.168.1.105:9000/")[1];
if(fst.isDirectory()) {
System.out.println("d: "+name);
try {
FileStatus[] fls = fs.listStatus(new Path("/"+name));
for(FileStatus fst2:fls) {
judge(fs,fst2);
}
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}else {
System.out.println("f: "+name);
}
}

4.上传
@Test //上传文件到hdfs文件系统 通过io流
public void rz() {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//输出流
FSDataOutputStream create = fs.create(new Path("/other/hadoop-2.7.7.tar.gz"));
//输入流
FileInputStream fis = new FileInputStream(new File("F:\\Linux\\hadoop-2.7.7.tar.gz"));
int len = 0;
//定义一个byte类型的数组,数组的大小表示每次从文件中读取出来的数据量
byte[] b = new byte[1024];
//循环读取数据,如果fis.read没有读到就数据返回-1
while((len = fis.read(b))!=-1) {
//输入到输出
create.write(b, 0, len);
}
fis.close();
create.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test //上传文件到hdfs文件系统 通过核心类FileSystem提供的方法
public void rz1() {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//前为需要上传的文件地址,后为hdfs存放地址
fs.copyFromLocalFile(new Path("F:\\Linux\\hadoop-2.7.7.tar.gz"), new Path("/other/hadoop-2.7.7.tar.gz"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
5.下载
@Test //下载到本地 通过io流
public void sz() {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
FSDataInputStream create = fs.open(new Path("/other/hadoop-2.7.7.tar.gz"));
FileOutputStream fis = new FileOutputStream(new File("F:\\hadoop-2.7.7.tar.gz"));
int len = 0;
byte[] b = new byte[1024];
while((len = create.read(b))!=-1) {
fis.write(b, 0, len);
}
fis.close();
create.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test //下载到本地 通过核心类FileSystem提供的方法
public void sz1() {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//前为hdfs中的文件,后为存放地址
fs.copyToLocalFile(new Path("/other/hadoop-2.7.7.tar.gz"),new Path("F:\\hadoop-2.7.7.tar.gz"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
6.重命名
@Test //重命名
public void rename() {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.105:9000");
try {
FileSystem fs = FileSystem.get(conf);
//前为原名,后为修改名
boolean rename = fs.rename(new Path("hello"), new Path("hello01"));
System.out.println(rename);
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}HDFS文件系统基操--Java实现的更多相关文章
- hadoop学习(三)HDFS常用命令以及java操作HDFS
一.HDFS的常用命令 1.查看根目录下的信息:./hadoop dfs -ls 2.查看根目录下的in目录中的内容:./hadoop dfs -ls in或者./hadoop dfs -ls ./i ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- HDFS的java接口——简化HDFS文件系统操作
今天闲来无事,于是把HDFS的基本操作用java写出简化程序出来给大家一些小小帮助! package com.quanttech; import org.apache.hadoop.conf.Conf ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- HDFS文件系统基本文件命令、编程读写HDFS
基本文件命令: 格式为:hadoop fs -cmd <args> cmd的命名通常与unix对应的命令名相同.例如,文件列表命令: hadoop fs -ls 1.添加目录和文件 HDF ...
- HDFS文件系统的JAVA-API操作(一)
使用java.net.URL访问HDFS文件系统 HDFS的API使用说明: 1.如果要访问HDFS,HDFS客户端必须有一份HDFS的配置文件 也就是hdfs-site.xml,从而读取Nameno ...
- hdfs shell命令及java客户端编写
一. hdfs shell命令 可以通过hadoop fs 查看所有的shell命令及其用法. 传文件到hdfs: hadoop fs -put /home/koushengrui/Downloads ...
随机推荐
- 吴裕雄--天生自然python学习笔记:python爬虫PM2.5 实时监测显示器
PM2.5 对人体的健康影响很大,所以空气中的 PM2.5 实时信息受到越来越多的关注. Python 的 Pandas 套件不但可以自动读取网页中的表格 数据 , 还可对数据进行修改.排序等处理,也 ...
- 吴裕雄--天生自然 HADOOP大数据分布式处理:CenterOS 7 多台物理机、虚拟机相互桥连接ping通,并且能够成功连接外网
选择用于桥接模式下的虚拟交换机,并且要选择对应的有线或者无线的网卡,如果主机是插网线联网的,那就选择有线网卡,如果主机是连无线网络的就选择无线网卡.Realtek PCIe GBE Family Co ...
- 树剖想法题——BZOJ3626
本来是打算作为树剖练习的最后一题的,结果一直WA. 本来以为是自己写的太丑. 最后发现5w的数据 我开了10w的数组 然而有一个数组要×2 哦,好棒棒. #include<cstring> ...
- 十、RPC(远程过程调用)
相关概念 RPC,是Remote Procedure Call的简称,即远程过程调用.它是一种通过网络从远程计算机上请求服务,而不需要了解底层网络的技术.RPC的主要功用是让构建分布式计算更容易,在提 ...
- [LC] 14. Longest Common Prefix
Write a function to find the longest common prefix string amongst an array of strings. If there is n ...
- node+express+MongoDB实现小商城服务端
https://blog.csdn.net/qq_28027903/article/details/82868313
- IO流框架
目录 IO流框架总结 字节流 字符流 IO流框架总结 普通IO / NIO 字节流 字节流是万能流,但是在处理字符方面有时候不太方便,一般用来处理二进制文件 字节输入流 InputStream int ...
- SpringMVC学习笔记一:采用注解式搭建简单springMVC环境
搭建的环境使用的是maven项目 项目目录树: 搭建环境使用的jar包,pom.xml文件 <project xmlns="http://maven.apache.org/POM/4. ...
- js中的call
//例1 <script> window.color = 'red'; document.color = 'yellow'; var s1 = {color: 'blue' }; func ...
- 吴裕雄--天生自然KITTEN编程:拾金币