【Kafka】监控及运维——kafka-eagle
简单介绍
概述
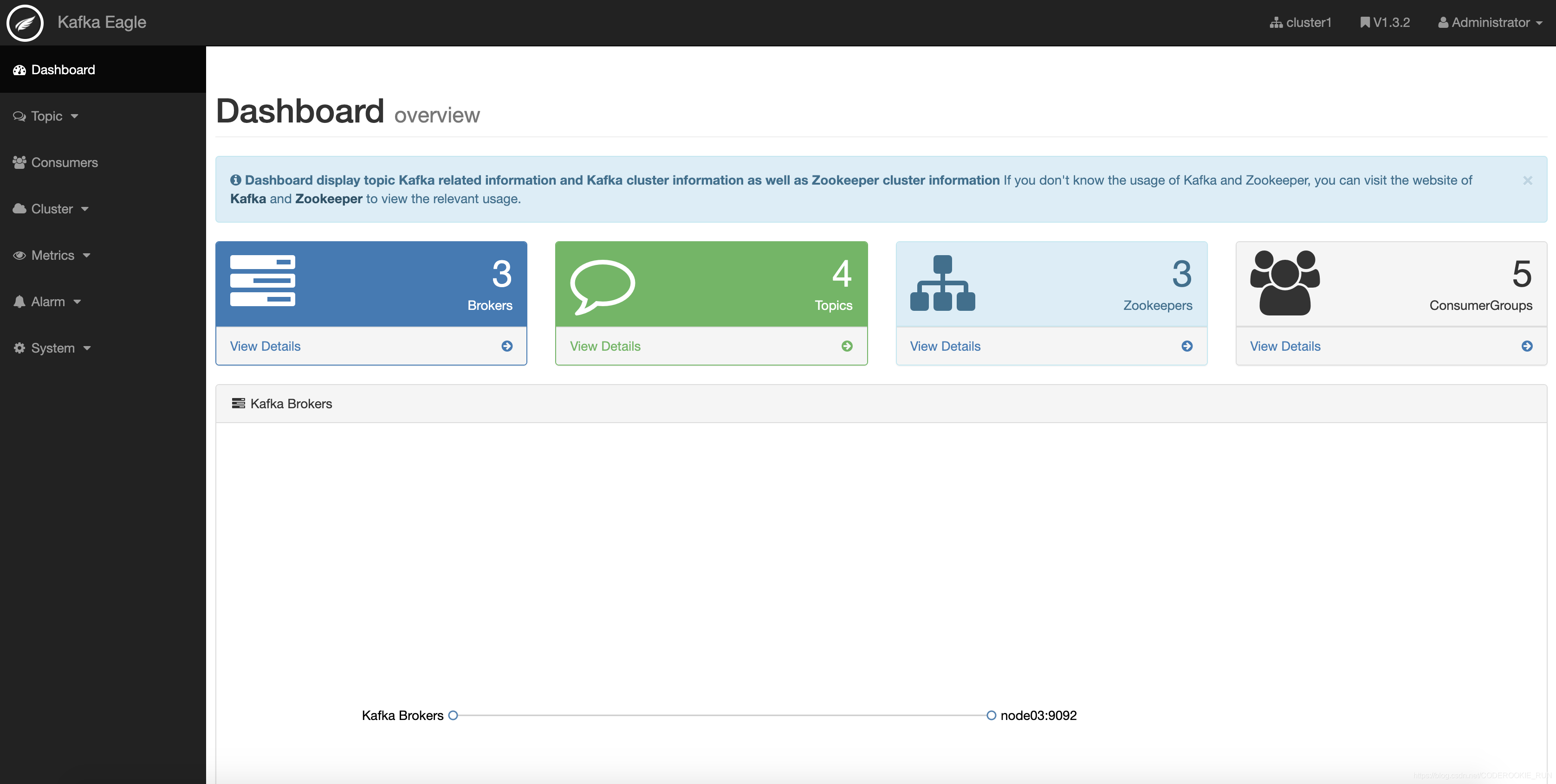
Kafka-eagle是一个为了简化开发者和服务工程师维护Kafka集群工作的监控管理工具。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具还可以快速浏览整个集群。
安装部署
一、环境要求
需要安装JDK、ZooKeeper和Kafka
二、下载源码包并解压
下载地址:http://download.kafka-eagle.org/
下载完成后上传到/export/softwares开始解压
tar -zxvf kafka-eagle-bin-1.3.2.tar.gz -C ../servers
cd /export/servers/kafka-eagle-bin-1.3.2/
tar -zxvf kafka-eagle-web-1.3.2-bin.tar.gz三、准备数据库
kafka-eagle需要使用一个数据库来保存元数据信息,用mysql数据库保存即可
mysql -uroot -p
CREATE DATABASE eagle;
四、修改配置文件
cd /export/servers/kafka-eagle-bin-1.3.2/kafka-eagle-web-1.3.2/conf/
vim system-config.propertieskafka.eagle.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=node01:2181,node02:2181,node03:2181
cluster2.zk.list=node01:2181,node02:2181,node03:2181 kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://node03:3306/eagle
kafka.eagle.username=root
kafka.eagle.password=123456
五、配置环境变量
vim /etc/profileexport KE_HOME=/export/servers/kafka-eagle-bin-1.3.2/kafka-eagle-web-1.3.2
export PATH=:$KE_HOME/bin:$PATH
source /etc/profile六、启动kafka-eagle
cd /export/servers/kafka-eagle-bin-1.3.2/kafka-eagle-web-1.3.2/bin/
chmod u+x ke.sh
./ke.sh start
七、成功运行
访问主界面:http://192.168.0.30:8048/ke/account/signin?/ke/
用户名:admin
密码:123456
【Kafka】监控及运维——kafka-eagle的更多相关文章
- 无监控不运维——使用 Python 写一个小小的项目监控
在公司里做的一个接口系统,主要是对接第三方的系统接口,所以,这个系统里会和很多其他公司的项目交互.随之而来一个很蛋疼的问题,这么多公司的接口,不同公司接口的稳定性差别很大,访问量大的时候,有的不怎么行 ...
- 基于Prometheus和Grafana的监控平台 - 运维告警
通过前面几篇文章我们搭建好了监控环境并且监控了服务器.数据库.应用,运维人员可以实时了解当前被监控对象的运行情况,但是他们不可能时时坐在电脑边上盯着DashBoard,这就需要一个告警功能,当服务器或 ...
- Linux、docker、kubernetes、MySql、Shell、kafka、RabbitMQ运维快餐
检查端口占用 lsof -i:[port] netstat -anp |grep [port] 监控网络客户TCP连接数 netstat -anp | grep tcp |wc -l 获取某进程中运行 ...
- 【kafka学习之三】kafka集群运维
kafka集群维护一.kafka集群启停#启动kafka/home/cluster/kafka211/bin/kafka-server-start.sh -daemon /home/cluster/k ...
- Jenkins用HTTP Request Plugin插件进行网站的监控(运维监控)
使用的插件: [HTTP Request Plugin] 思路: 说明:只能是网站是否正常打开,而不能是这个网站业务是否正常,如果是后者,则需要写特定的接口进行请求处理. 1.通过插件,发送GET请求 ...
- Redis缓存接入监控、运维平台CacheCloud
改造RedisConnectionFactory /** * 根据缓存策略的不同,RedisConnectionFactory不同 * 示例是单机模式. * * @return */@Beanpubl ...
- DataPipeline |《Apache Kafka实战》作者胡夕:Apache Kafka监控与调优
胡夕 <Apache Kafka实战>作者,北航计算机硕士毕业,现任某互金公司计算平台总监,曾就职于IBM.搜狗.微博等公司.国内活跃的Kafka代码贡献者. 前言 虽然目前Apache ...
- DataPipeline |ApacheKafka实战作者胡夕:Apache Kafka监控与调优
https://baijiahao.baidu.com/s?id=1610644333184173190&wfr=spider&for=pc DataPipeline |ApacheK ...
- [转] 运维知识体系 -v3.1 作者:赵舜东(赵班长)转载请注明来自于-新运维社区:https://www.unixhot.com
[From]https://www.unixhot.com/page/ops [运维知识体系]-v3.1 作者:赵舜东(赵班长) (转载请注明来自于-新运维社区:https://www.unixhot ...
随机推荐
- 记录d3.js 力导向图的平移缩放,类似地图导航点击某一项移动到当前位置
项目中有用到d3.js用于图结构的查询, 需求如下: 右上角有个模糊搜索功能,查询出来的结果用列表展示 点击列表的某一列,要求画布移动到当前选中的节点的位置,基于画布正中间 搜索出来的结果列表展示用的 ...
- 【three.js第四课】自定义材料、贴图。
1.先去下载6张不同的图片素材放到项目中. 2.在[three.js第三课]的代码基础上添加自定义的材料 //自定义材料 cubeMaterial 数组 //map:用于加载图片,THREE.Text ...
- 今天整理了几个在使用python进行数据分析的常用小技巧、命令。
提高Python数据分析速度的八个小技巧 01 使用Pandas Profiling预览数据 这个神器我们在之前的文章中就详细讲过,使用Pandas Profiling可以在进行数据分析之前对数据进行 ...
- Redisson 实现分布式锁的原理分析
写在前面 在了解分布式锁具体实现方案之前,我们应该先思考一下使用分布式锁必须要考虑的一些问题. 互斥性:在任意时刻,只能有一个进程持有锁. 防死锁:即使有一个进程在持有锁的期间崩溃而未能主动释放锁, ...
- C#开发BIMFACE系列34 服务端API之模型对比5:获取模型构件对比差异
系列目录 [已更新最新开发文章,点击查看详细] BIMFACE平台提供了服务端“获取修改构件属性差异”API,其返回的结果也是一个列表,仅针对修改的构件(不包含新增.删除的构件),是指对于一个 ...
- [PHP] 生成二维码(两种方法)
方法一:(调用google二维码接口,本人测试网不好,不好用!) <?php //1.封装生成二维码图片的函数(方法) /** *利用google api生成二维码图片 * $content:二 ...
- Spring5:概念
1.Spring优点 spring是一个开源的免费的框架 spring是一个轻量级的 非入侵式的框架 控制反转(IOC).面向切面(AOP) 支持事务的处理,对框架整合的支持 **总之:spring就 ...
- (第五篇)Linux操作系统基本结构介绍
Linux操作系统基本结构介绍 Linux系统一般有4个主要部分:内核.shell.文件系统和应用程序.内核.shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序.管理文件并使用 ...
- 2019-2020-1 20199310《Linux内核原理与分析》第五周作业
1.问题描述 在前面的文章中,已经了解了Linux内核源代码的目录结构,并在Oracle VM VirtualBox的Linux环境中构造一个简单的操作系统MenuOS,本文将学习系统调用的相关理论知 ...
- 如何优雅的维护 K8S Worker 节点
前言 正常维护工作节点的流程 当我们要进行 K8S 节点维护时往往需要执行 kubectl drain, 等待节点上的 Pod 被驱逐后再进行维护动作. 命令行如下: kubectl drain NO ...