Spark 2.x Troubleshooting Guide
IBM在spark summit上分享的内容,包括编译spark源码,运行spark时候常见问题(缺包、OOM、GC问题、hdfs数据分布不均匀等),spark任务堆/thread dump
目录

编译spark的问题
1.正确配置相关环境,如Maven,JRE
2.显示指定你要集成的功能
3.编译速度比较慢的话,可以根据自己的环境设置多core提高速度


spark运行时遇到的问题
1.在不清楚spark某些配置时候,可以在spark-submit时候使用--verbose打印出当前环境具体信息

2.缺少外部jar包问题,可以使用--packages参数指定缺失的jar包,--packages会先到本地maven仓库中找指定的jar包,如果本地仓库没有,就需要外部maven仓库下载。
所以一般在生成环境,--packages不一定合适。在jar包比较少的情况下,可以通过--jars指定,比较多的话,也可以通过指定class path。这两种方式都是比较合适的

2.Spark Driver OOM,默认driver内存一般都比较小(512M),建议自己指定。这个要根据实际情况设置

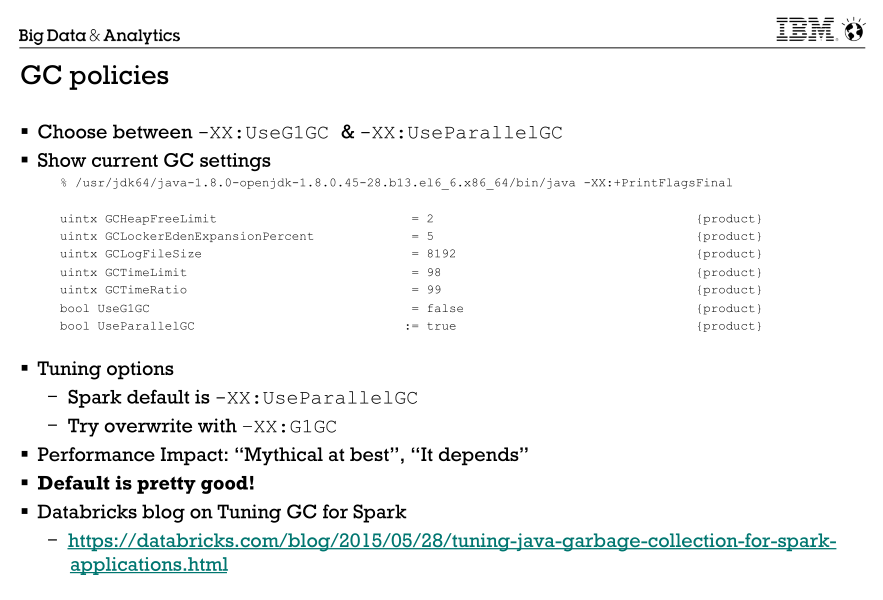
3.GC时间过长,首先应该从代码逻辑判断是否有问题,然后考虑内存是否太小,最后考虑GC算法,目前来说G1 GC是针对大堆(4G以上)首选的GC算法,databricks有一遍关于spark任务优化G1 GC的文章写的很不错,链接在下面。


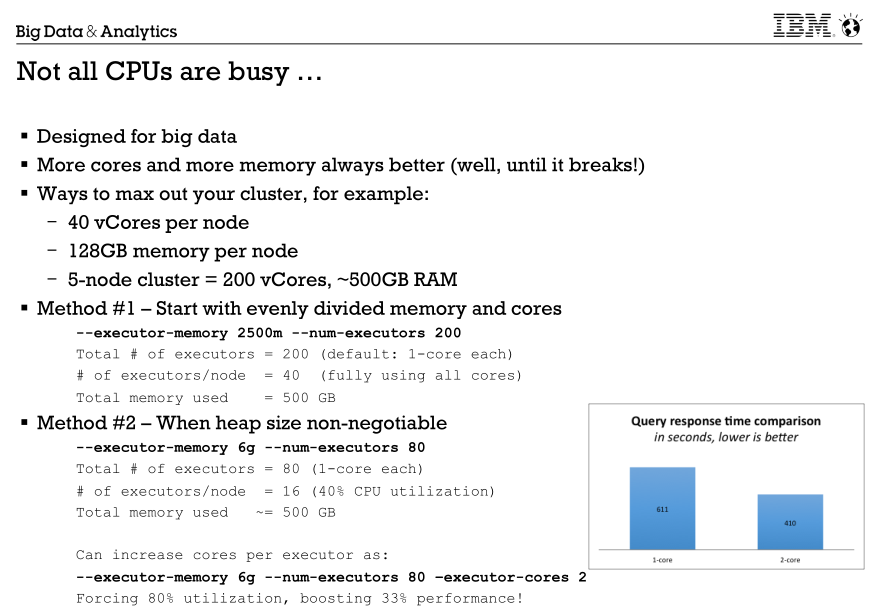
4.关于spark任务资源的问题,如何最大化利用资源
5.关于spark的"scratch" ,尽量不要使用默认的/tmp,图中描述的比较详细了。

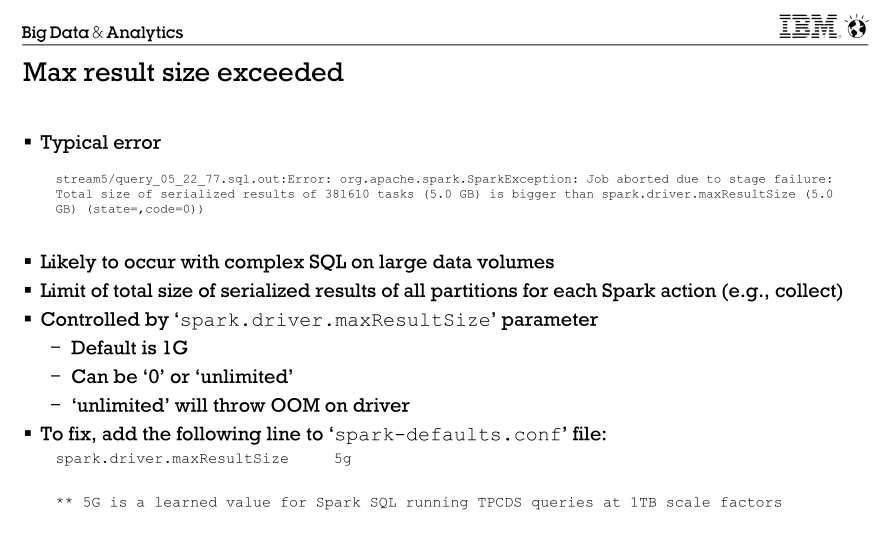
6.这种问题一般是用户在spark-sql中直接查询返回的数据量过大造成。也可能是用户应用中使用了拉取数据到driver端的API(例如:collect、show)。
解决方法:用户应该考虑拉取数据到driver端是否合理?如果不合理,增加过滤条件或者采用insert overwrite directory命令解决;如果合理,则适当增加spark.driver.maxResultSize的大小。



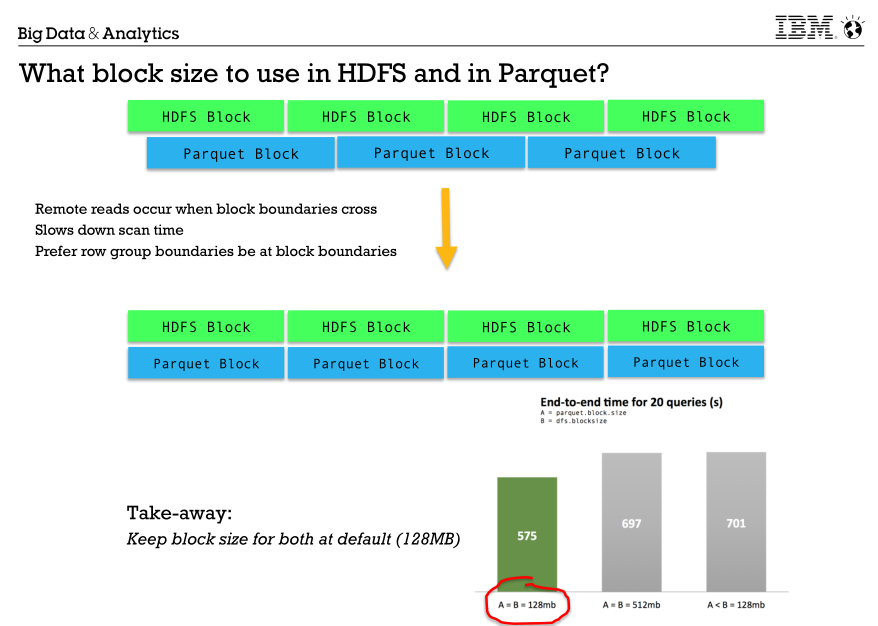


Spark 2.x Troubleshooting Guide的更多相关文章
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
- FNDCPASS Troubleshooting Guide For Login and Changing Applications Passwords
In this Document Goal Solution 1. Error Starting Application Services After Changing APPS Pass ...
- What To Do When MySQL Runs Out of Memory: Troubleshooting Guide
In this article, I will show you how to use the new version of MySQL (5.7+) and how to troubleshoot ...
- Spark SQL and DataFrame Guide(1.4.1)——之DataFrames
Spark SQL是处理结构化数据的Spark模块.它提供了DataFrames这样的编程抽象.同一时候也能够作为分布式SQL查询引擎使用. DataFrames DataFrame是一个带有列名的分 ...
- Spark Streaming + Kafka Integration Guide原文翻译及解析
前面写了关于kafka和spark streaming的结合使用(https://www.cnblogs.com/qfxydtk/p/11662591.html),其具体使用用法其实来自于原文:htt ...
- Java troubleshooting guide
http://www.oracle.com/technetwork/java/javase/toc-135973.html --不同的 OutOfMemoryError/内存溢出,以及相关的解决
- Troubleshooting Guide for ORA-12541 TNS: No Listener
Server side checks (not platform specific): 1) Check the result on the server using tnsping to the ...
- spark第六篇:Spark Streaming Programming Guide
预览 Spark Streaming是Spark核心API的扩展,支持高扩展,高吞吐量,实时数据流的容错流处理.数据可以从Kafka,Flume或TCP socket等许多来源获取,并且可以使用复杂的 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
随机推荐
- iis下发布MVC网站
1.首先检查有没有安装iis,没有的话先安装iis 2. 3.选择应用程序池的时候看有没有asp.net 4.0 如果没有先安装. 首先以管理员身份打开“运行”输入cd C:\Windows\Micr ...
- Python print()函数
#输出单个数据,会自动输出回车换行 print(1) print(2) #输出 1 2 #输出换行 print('\n') #防止换行 for x in range(0, 5): print(x, e ...
- Burp Suite Pro1.7.36破解版
百度网盘下载(H大会一直更新):链接: https://pan.baidu.com/s/1brjPKM7 密码: 9v4r 爱盘下载:https://down.52pojie.cn/Tools/Net ...
- MyBatisPlus代码生成 mvc项目
package com.test; import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus ...
- 洛谷 P1886 滑动窗口 /【模板】单调队列
纯板子题,入队时保证单调性,即单调栈,出队保证题目条件,本题即窗口长度k,在入队出队时都可以维护信息 ; int buf[maxm], maxq[maxm], minq[maxm], ans1[max ...
- 098、Java中String类之charAt()方法
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- eclipse Spring环境搭建 spring tool suite
1.期初用intellij社区版,发现收费版才能开发Java EE. 2.使用eclipse按照网上的教程,在help->eclipse marketplace中搜索sts安装spring工具套 ...
- 针对小文件的spark wholeTextFiles()
场景:推送过来的数据文件数量很多,并且每个只有10-30M的大小 spark读取hdfs一般都是用textfile(),但是对于这种情况,如果使用textFile默认产生的分区数将与文件数目一致,产生 ...
- Python学习笔记之基础篇(二)python入门
一.pycharm 的下载与安装: 使用教程:https://www.cnblogs.com/jin-xin/articles/9811379.html 破解的方法:http://xianchang. ...
- linux安装软件的几种方法----linux下编译安装软件的一般步骤
linux安装软件的几种方法: 一.rpm包安装方式步骤: 1.找到相应的软件包,比如soft.version.rpm,下载到本机某个目录: 2.打开一个终端,su -成root用户: 3.cd so ...