Spark 2.x Troubleshooting Guide
IBM在spark summit上分享的内容,包括编译spark源码,运行spark时候常见问题(缺包、OOM、GC问题、hdfs数据分布不均匀等),spark任务堆/thread dump
目录

编译spark的问题
1.正确配置相关环境,如Maven,JRE
2.显示指定你要集成的功能
3.编译速度比较慢的话,可以根据自己的环境设置多core提高速度


spark运行时遇到的问题
1.在不清楚spark某些配置时候,可以在spark-submit时候使用--verbose打印出当前环境具体信息

2.缺少外部jar包问题,可以使用--packages参数指定缺失的jar包,--packages会先到本地maven仓库中找指定的jar包,如果本地仓库没有,就需要外部maven仓库下载。
所以一般在生成环境,--packages不一定合适。在jar包比较少的情况下,可以通过--jars指定,比较多的话,也可以通过指定class path。这两种方式都是比较合适的

2.Spark Driver OOM,默认driver内存一般都比较小(512M),建议自己指定。这个要根据实际情况设置

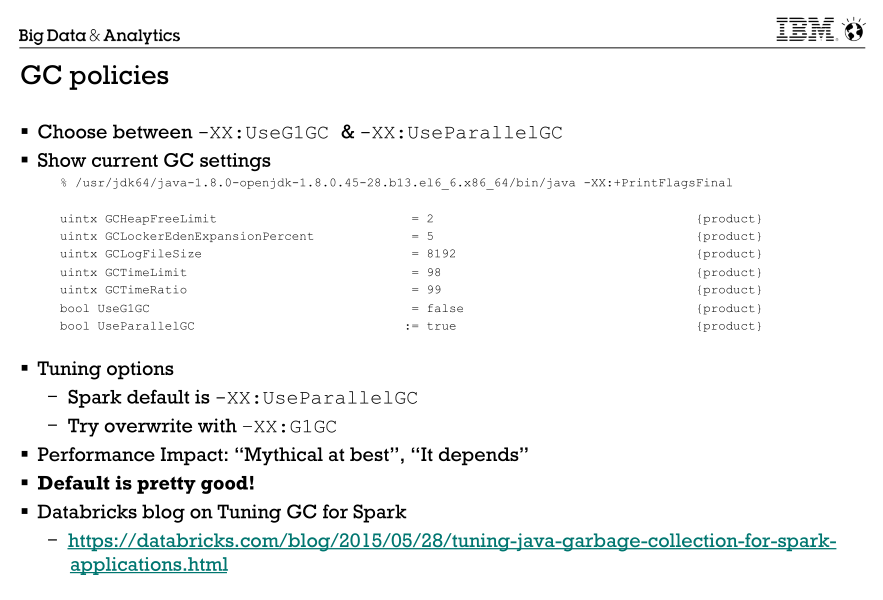
3.GC时间过长,首先应该从代码逻辑判断是否有问题,然后考虑内存是否太小,最后考虑GC算法,目前来说G1 GC是针对大堆(4G以上)首选的GC算法,databricks有一遍关于spark任务优化G1 GC的文章写的很不错,链接在下面。


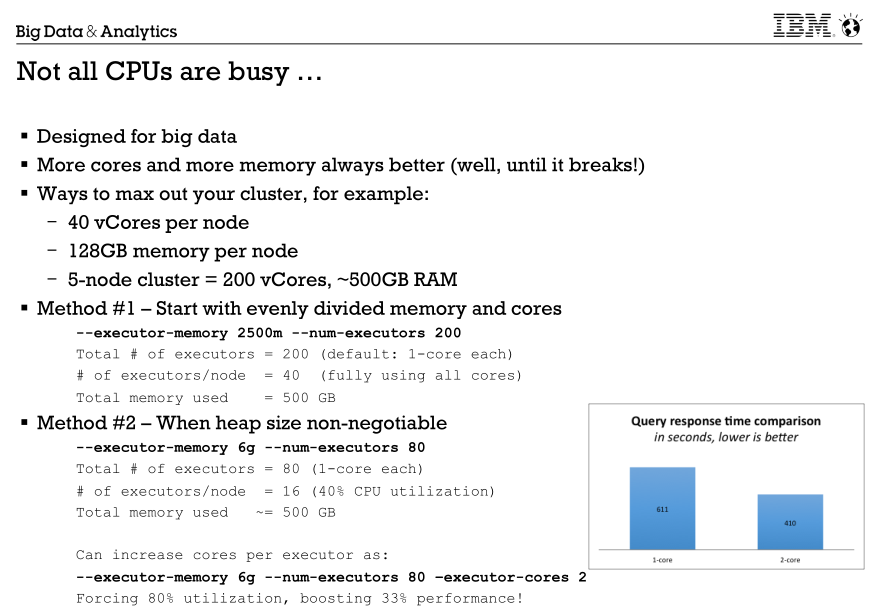
4.关于spark任务资源的问题,如何最大化利用资源
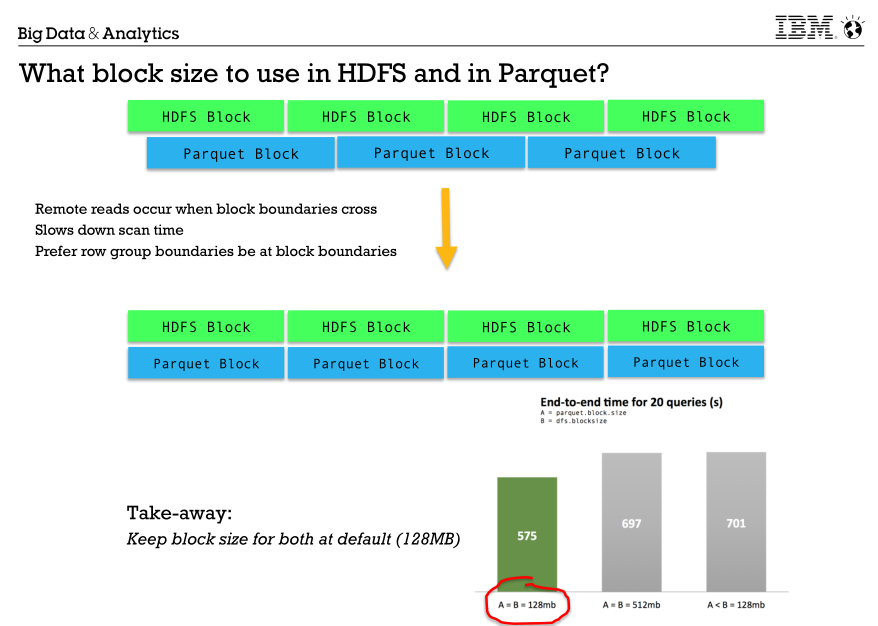
5.关于spark的"scratch" ,尽量不要使用默认的/tmp,图中描述的比较详细了。

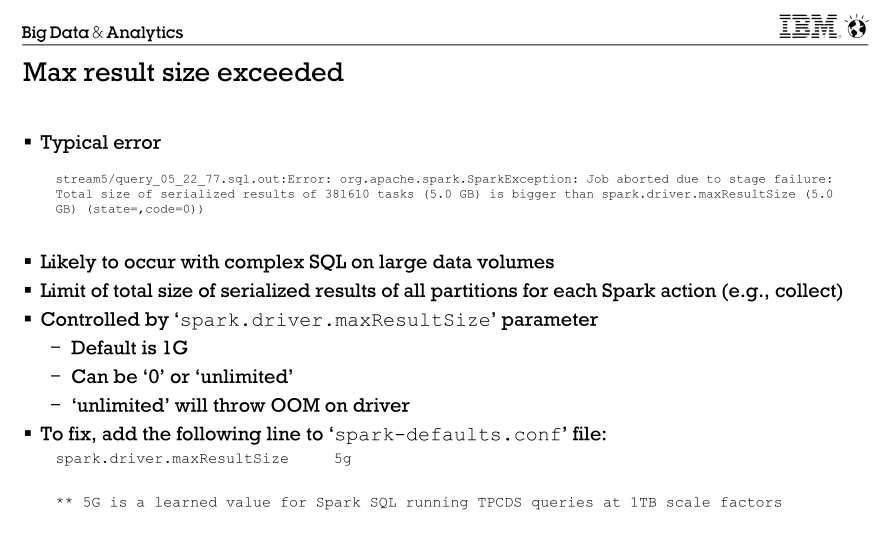
6.这种问题一般是用户在spark-sql中直接查询返回的数据量过大造成。也可能是用户应用中使用了拉取数据到driver端的API(例如:collect、show)。
解决方法:用户应该考虑拉取数据到driver端是否合理?如果不合理,增加过滤条件或者采用insert overwrite directory命令解决;如果合理,则适当增加spark.driver.maxResultSize的大小。





Spark 2.x Troubleshooting Guide的更多相关文章
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
- FNDCPASS Troubleshooting Guide For Login and Changing Applications Passwords
In this Document Goal Solution 1. Error Starting Application Services After Changing APPS Pass ...
- What To Do When MySQL Runs Out of Memory: Troubleshooting Guide
In this article, I will show you how to use the new version of MySQL (5.7+) and how to troubleshoot ...
- Spark SQL and DataFrame Guide(1.4.1)——之DataFrames
Spark SQL是处理结构化数据的Spark模块.它提供了DataFrames这样的编程抽象.同一时候也能够作为分布式SQL查询引擎使用. DataFrames DataFrame是一个带有列名的分 ...
- Spark Streaming + Kafka Integration Guide原文翻译及解析
前面写了关于kafka和spark streaming的结合使用(https://www.cnblogs.com/qfxydtk/p/11662591.html),其具体使用用法其实来自于原文:htt ...
- Java troubleshooting guide
http://www.oracle.com/technetwork/java/javase/toc-135973.html --不同的 OutOfMemoryError/内存溢出,以及相关的解决
- Troubleshooting Guide for ORA-12541 TNS: No Listener
Server side checks (not platform specific): 1) Check the result on the server using tnsping to the ...
- spark第六篇:Spark Streaming Programming Guide
预览 Spark Streaming是Spark核心API的扩展,支持高扩展,高吞吐量,实时数据流的容错流处理.数据可以从Kafka,Flume或TCP socket等许多来源获取,并且可以使用复杂的 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
随机推荐
- linux磁盘扩容常见问题
1.对于云主机可以对硬盘进行在线扩容,如果不方便重启服务器,可以键入以下命令系统能够马上识别新增空间: echo '1' > /sys/class/scsi_disk/0\:0\:0\:0/de ...
- ORM常用字段及查询
目录 ORM常用字段及参数 创建表 ORM常用字段 ORM字段参数 ORM表关系创建 ForeignKey OneToOneField ManyToManyField 多对多三种创建方式 单表查询 q ...
- java并发AtomicIntegerFieldUpdater
java并发AtomicIntegerFieldUpdater 支持对象的成员变量原子操作类由AtomicIntegerFieldUpdater,AtomicLongFieldUpdater, Ato ...
- 学会使用Google hacking
https://klionsec.github.io/2014/12/14/search-hacking/ 熟练利用Google hacking 来辅助我们快速渗透 http://www.sec-re ...
- 学习SpringBoot零碎记录——配置应用URL名称
学习SpringBoot配置应用名称,结果发现坑 到网上找 到 https://blog.csdn.net/qq_40087415/article/details/82497668 server: p ...
- android 根据res文件夹下(如res/raw)文件名获取其id
android 根据res文件夹下(如res/raw)文件名获取其id //测试是否能够获取其资源ID int treeId = mv.getResources().getIdentifier(fil ...
- 安装oracle客户端后,怎样设置电脑的环境变量?
安装配置参考: http://www.haodaima.net/art/2854001 设置环境变量(修改PATH和TNS_ADMIN环境变量): 对于NLS_LANG环境变量, 最好设置成和数据库端 ...
- 严重: Exception loading sessions from persistent storage
2011-11-24 10:05:00| 分类: java学习|举报|字号 订阅 当tomcat启动的时候出现下面错误: [ERROR] org.apache.catalina.sessio ...
- 发送短信-----用restful 校验规则
我们的需求如下 1. 获取手机号 . 手机格式校验 . 生成随机验证码 . 验证码发送到手机上 . 把验证码+手机号保留(30s过期) 复习 我们在有表的情况下的序列化 class MessageSe ...
- 蓝桥杯 能量项链 (区间dp)
问题描述 在Mars星球上,每个Mars人都随身佩带着一串能量项链.在项链上有N颗能量珠.能量珠是一颗有头标记与尾标记的珠子,这些标记对应着某个正整数.并且,对于相邻的两颗珠子,前一颗珠子的尾标记一定 ...