Django ORM操作数据库常用API
昨天晚上,我们完成了一个简单的实例来对数据库表进行操作。今天,我们要熟悉更多的API,实现更复杂的功能。这一步完成了,我们对小型数据的操作问题也就不大了。
现在,我们还是参考django官方文档,来进行学习
1.构造数据表
把以下内容,拷贝到你的朋友charm中,然后执行migrate命令
class Blog(models.Model):
name = models.CharField(max_length=100)
tagline = models.TextField()
def __str__(self): # __unicode__ on Python 2
return self.name
class Author(models.Model):
name = models.CharField(max_length=200)
email = models.EmailField()
def __str__(self): # __unicode__ on Python 2
return self.name
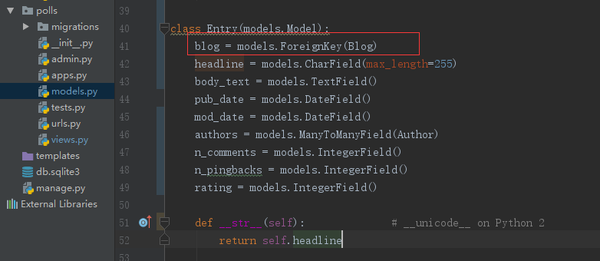
class Entry(models.Model):
blog = models.ForeignKey(Blog)
headline = models.CharField(max_length=255)
body_text = models.TextField()
pub_date = models.DateField()
mod_date = models.DateField()
authors = models.ManyToManyField(Author)
n_comments = models.IntegerField()
n_pingbacks = models.IntegerField()
rating = models.IntegerField()
def __str__(self): # __unicode__ on Python 2
return self.headline
2.创建对象
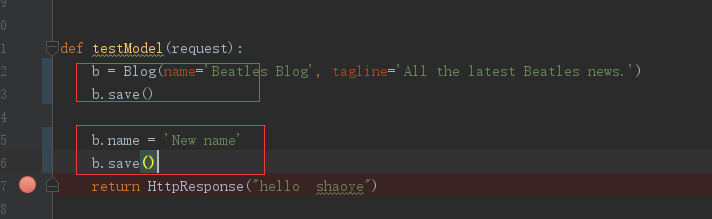
b = Blog(name='Beatles Blog', tagline='All the latest Beatles news.')
b.save()
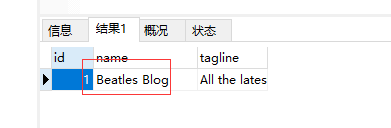
这样,我们就把数据存进去了
同一个对象,保存之后重新赋值,就会执行修改操作
3.保存 ForeignKey 和 ManyToManyField 字段
现在,我们数据已经保存了,并已经建立了关联
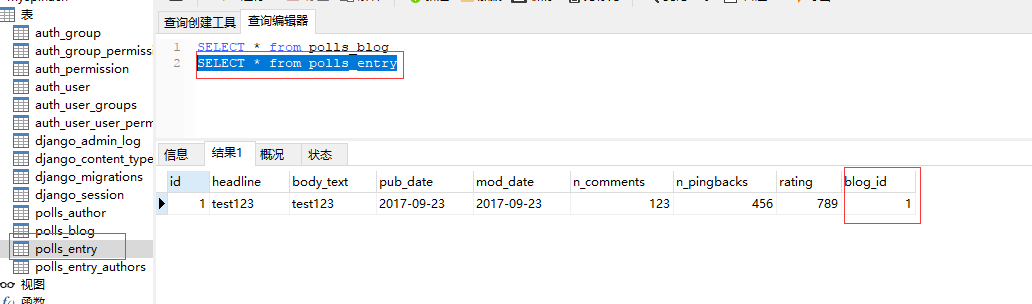
在model中,Entry关联了外键Blog(ForeignKey )
所以在创建Entry的时候,要先获取一个Blog对象,给Entry赋值之后,才执行保存数据库的操作
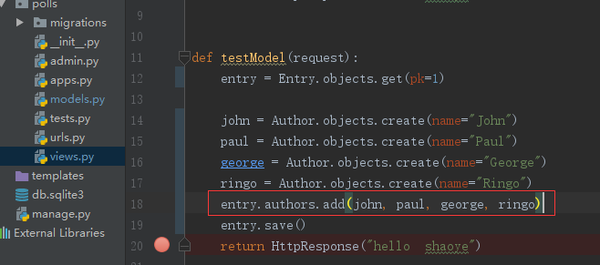
entry = Entry(headline='test123', body_text='test123', pub_date=datetime.datetime.now(),
mod_date=datetime.datetime.now(), n_comments=123, n_pingbacks=456, rating=789)
cheese_blog = Blog.objects.get(name="Beatles Blog")
entry.blog = cheese_blog
entry.save()
现在处理ManyToManyField 的情况
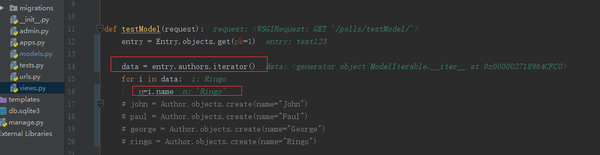
存进去了,还得能取出来:
data = entry.authors.iterator()
直接访问属性,并把查询集转为可迭代
4.查询对象
all_entries = Entry.objects.all()
5.按条件查询
filter(**kwargs) 返回一个新的匹配查询参数后的QuerySet
exclude(**kwargs) 返回一个新的不匹配查询参数后的QuerySet
Entry.objects.filter(pub_date__year=2006)
q2 = q1.exclude(pub_date__gte=datetime.date.today())
6.链接查询
Entry.objects.filter(headline__startswith='What')
.exclude(pub_date__gte=datetime.now())
.filter(pub_date__gte=datetime(2005, 1, 1))
7.延迟查询
创建QuerySets不会触及到数据库操作,你可以多个过滤合并到一起,直到求值的时候django才会开始查询
q = Entry.objects.filter(headline__startswith="What")
q = q.filter(pub_date__lte=datetime.now())
q = q.exclude(body_text__icontains="food")
8.检索单个对象
one_entry = Entry.objects.get(pk=1)
9.限制查询:分页/排序查询
Entry.objects.all()[:5]
Entry.objects.order_by('headline')[0:1].get()
10.字段查询
Entry.objects.filter(pub_date__lte='2006-01-01')
转换成SQL:
SELECT * FROM blog_entry WHERE pub_date <= '2006-01-01';
11.exact
Entry.objects.get(headline__exact="Man bites dog")
转换成SQL:
SELECT ... WHERE headline = 'Man bites dog';
12.iexact——忽略大小写
Blog.objects.get(name__iexact="beatles blog")
13.contains——包含查询,区分大小写
Entry.objects.get(headline__contains='Lennon')
转换成SQL:
SELECT ... WHERE headline LIKE '%Lennon%';
icontains 不区分大小写
startswith,endswith,istartswith,iendswith
前后模糊查询
14.连接查询
查询blog__name匹配的,返回Entry
Entry.objects.filter(blog__name__exact='Beatles Blog')
查询entry__headline匹配的,返回Blog
Blog.objects.filter(entry__headline__contains='Lennon')
如果跨越多层关系查询,中间模型没有值,django会作为空对待不会发生异常
Blog.objects.filter(entry__author__name='Lennon');
Blog.objects.filter(entry__author__name__isnull=True);
Blog.objects.filter(
entry__author__isnull=False,
entry__author__name__isnull=True);
15.F对象,对字段进行操作。就像SQL中,A列+B列。F对象很少用
from django.db.models import F
Entry.objects.filter(n_pingbacks__lt=F('n_comments'))
列加减乘除都可以
Entry.objects.filter(n_pingbacks__lt=F('n_comments') * 2)
Entry.objects.filter(rating__lt=F('n_comments') + F('n_pingbacks'))
Entry.objects.filter(author__name=F('blog__name'))
16.like语句转义百分号
Entry.objects.filter(headline__contains='%')
转义为:
SELECT ... WHERE headline LIKE '%\%%';
17.删除
q = Entry.objects.filter(headline__startswith="What")
q.delete()
18.批量修改
Entry.objects.filter(pub_date__year=2007).update(headline='Everything is the same')
一次性修改所有的Entry的blog属性指向
b = Blog.objects.get(pk=1)
Entry.objects.all().update(blog=b)
update也可以使用F()
Entry.objects.update(headline=F('blog__name'))
19.One-to-many关系
e = Entry.objects.get(id=2)
print e.blog # Hits the database to retrieve the associated Blog
e = Entry.objects.select_related().get(id=2)
print e.blog # 不会在向数据库取; 使用缓存中的值.
b = Blog.objects.get(id=1)
b.entry_set.all() # 返回所有blog的关联对象.
# b.entry_set is a Manager that returns QuerySets.
b.entry_set.filter(headline__contains='Lennon')
b.entry_set.count()
b = Blog.objects.get(id=1)
b.entries.all() # 返回所有blog的关联对象
# b.entries is a Manager that returns QuerySets.
b.entries.filter(headline__contains='Lennon')
b.entries.count()
add(obj1, obj2, ...) 把多个对象建立连接
create(**kwargs) 建立新对象
remove(obj1, obj2, ...) 移除多个关系对象
clear() 清理所有关系对象
20.Many-to-many关系
e = Entry.objects.get(id=3)
e.authors.all() # 返回Entry所有authors
e.authors.count()
e.authors.filter(name__contains='John')
a = Author.objects.get(id=5)
a.entry_set.all() # 返回Author所有entry
21.One-to-one关系
要在定义模型的时候设置
class EntryDetail(models.Model):
entry = models.OneToOneField(Entry)
details = models.TextField()
ed = EntryDetail.objects.get(id=2)
ed.entry # 返回 Entry 对象.
Django ORM操作数据库常用API的更多相关文章
- Python Django orm操作数据库笔记之QuerySet API
什么时候Django会将QuerySet转换为SQL去执行: 根据Django的数据库机制,对于QuerySet来说,当QuerySet被第一次构建,然后又调用他的filter方法,接着在对其进行切片 ...
- Python Django orm操作数据库笔记之外键和表关系
外键 在MySQL中,表有两种引擎,一种是InnoDB,另外一种是myisam.如果使用的是InnoDB引擎,是支持外键约束的. 外键的使用 使用外键前需要先确保相应外键已存储在数据库中(flask中 ...
- java数据库 JDBC操作MySQL数据库常用API 部门表和员工表 创建表 添加数据 查询数据
package com.swift.department; import java.sql.Connection; import java.sql.PreparedStatement; import ...
- Django学习——静态文件配置、request对象方法、pycharm如何链接数据库、Django如何指定数据库、Django orm操作
静态文件配置 # 1.静态文件 网站所使用的已经提前写好的文件 css文件 js文件 img文件 第三方文件 我们在存储静态文件资源的时候一般默认都是放在static文件夹下 # 2.Django静态 ...
- [oldboy-django][2深入django]ORM操作
推荐学习博客:http://www.cnblogs.com/wupeiqi/articles/6216618.html 需求: 汇总django orm操作,代替原生mysql语句来操作数据库:里面内 ...
- JS操作DOM常用API总结
<JS高程>中的DOM部分写的有些繁琐,还没勇气整理,直到看到了这篇博文 Javascript操作DOM常用API总结,顿时有了一种居高临下,一览全局的感觉.不过有时间还是得自己把书里面的 ...
- 【repost】Javascript操作DOM常用API总结
Javascript操作DOM常用API总结 文本整理了javascript操作DOM的一些常用的api,根据其作用整理成为创建,修改,查询等多种类型的api,主要用于复习基础知识,加深对原生js的认 ...
- laravel使用ORM操作数据库
laravel使用ORM操作数据库 public function mode(){ //查询所有 $isok=Student::get(); 新增. (1) $isok=Student::create ...
- 数据库开发-Django ORM的数据库迁移
数据库开发-Django ORM的数据库迁移 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. Django 项目准备 1>.安装django包 pip install d ...
随机推荐
- 附014.Kubernetes Prometheus+Grafana+EFK+Kibana+Glusterfs整合解决方案
一 glusterfs存储集群部署 注意:以下为简略步骤,详情参考<附009.Kubernetes永久存储之GlusterFS独立部署>. 1.1 架构示意 略 1.2 相关规划 主机 I ...
- vscode 新建 springboot java项目
vscode 新建 springboot java项目 1. 安装javaJDK 软件下载 下载地址: https://www.oracle.com/technetwork/java/javase/d ...
- Flask-Sockets实时的监控画面
Ajax轮询是通过特定的的时间间隔(如每1秒),由浏览器对服务器发出HTTP请求,然后由服务器返回最新的数据给客户端的浏览器.这种简单粗暴模式有一个明显的缺点,就是浏览器需要不断的向服务器发出请求,H ...
- centOS6.5桌面版用不了中文输入法解决方案
1:centos6.5中 系统->首选项->输入法中选择“使用iBus(推荐)”,点击首选输入法n遍,没有任何效果. 2.我也弄了很多种方式包括用 yum install " ...
- org.apache.rocketmq.remoting.exception.RemotingTooMuchRequestException: sendDefaultImpl call timeout 和 RocketmqRemoting closeChannel: close the connection to remote address[] result: true
org.apache.rocketmq.remoting.exception.RemotingTooMuchRequestException: sendDefaultImpl call timeout ...
- Quantitative Proteomics of Enriched Esophageal and Gut Tissues from the Human Blood Fluke Schistosoma mansoni Pinpoints Secreted Proteins for Vaccine Development (解读人:张聪敏)
文献名:Quantitative Proteomics of Enriched Esophageal and Gut Tissues from the Human Blood Fluke Schist ...
- Python-String字符串操作
name='xioer-pipo' print(name.capitalize()) #第一个字符大写 print(name.expandtabs()) print(name.count('o')) ...
- CMDB资产采集方式
一:Agent方式 原理:在每台服务器装上agent客户端程序,定时向数据库发送指定的资产信息. 优点:速度快. 缺点:服务器上需要多装一个软件 import subprocess import re ...
- [离散化+树状数组]CodeForces - 652D Nested Segments
Nested Segments time limit per test 2 seconds memory limit per test 256 megabytes input standard inp ...
- CSS三角形/气泡的实现原理及应用
记得第一次面试,面试官问如何用css实现一个不规则三角形?好叭 ·-·,触及到知识盲区了,手动叹气(╥﹏╥),好在别的回答的还好,没挂