java读源码 之 list源码分析(LinkedList)
文章目录
LinkedList:
继承关系分析:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
这里的Cloneable,Serializable,List这三个接口就不多赘述了,之前在介绍ArrayList的时候已经说过了。主要分析下AbstractSequentialList跟Deque
AbstractSequentialList
AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)这些函数。LinkedList是双向链表;既然它继承于AbstractSequentialList,就相当于已经实现了“get(int index)这些接口”
Deque
实现了Deque接口,代表LinkedList能被当作双端队列使用
字段分析:
// 长度
transient int size = 0;
// 头节点
transient Node<E> first;
// 尾节点
transient Node<E> last;
// 继承了AbstractSequentialList,AbstractSequentialList又继承了AbstractList
protected transient int modCount = 0;
构造函数分析:
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
方法分析:
add,我们主要看这两个重载的方法
// 往末尾添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
// 往头部添加
public void addFirst(E var1) {
this.linkFirst(var1);
}
// 往指定位置添加元素
public void add(int index, E element) {
// 判断角标是否越界
checkPositionIndex(index);
// 说明是往尾部添加元素
if (index == size)
linkLast(element);
else
// 往集合中添加元素
linkBefore(element, node(index));
}
跟踪方法到,linkLast(e)。
void linkLast(E e) {
// 申明一个Node,保存last的引用
final Node<E> l = last;
// 创建一个新节点,pre指向集合的last,next指针指向null,也即是集合的尾指针
final Node<E> newNode = new Node<>(l, e, null);
// 集合的尾指针指向新节点
last = newNode;
if (l == null)
// 说明集合刚刚初始化,一个元素都没有,添加的是第一个元素
first = newNode;
else
// 集合中原来的最后一个节点的next指针指向了新节点
l.next = newNode;
// 集合长度加1
size++;
// 集合修改次数加1
modCount++;
}
用图形的方式我们分析下这个过程:
假设我们现在有一个三个元素的集合,如下:
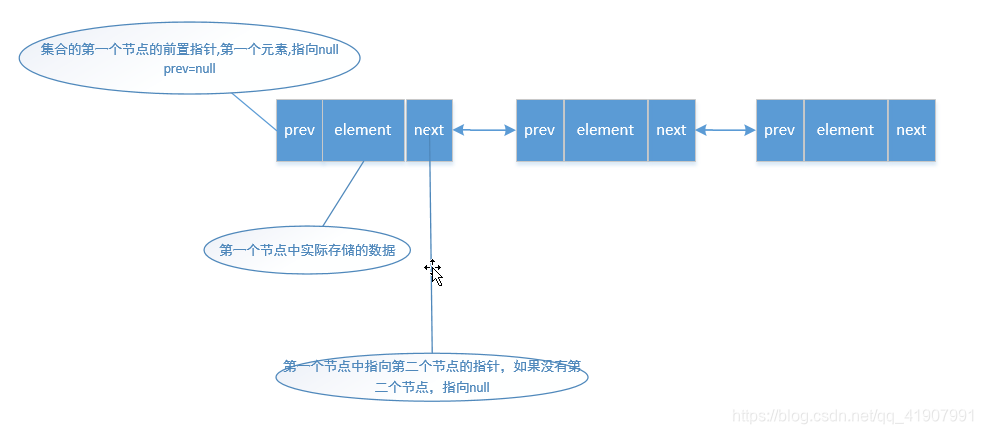
现在我们要调用add方法往集合的尾部添加一个元素:
- 创建一个节点
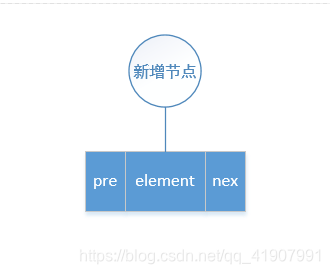
- 需要将这个节点的pre指针指向当前集合的最后一个元素,同时将当前集合的最后一个元素的next指针指向这个新增的节点
- 创建一个节点
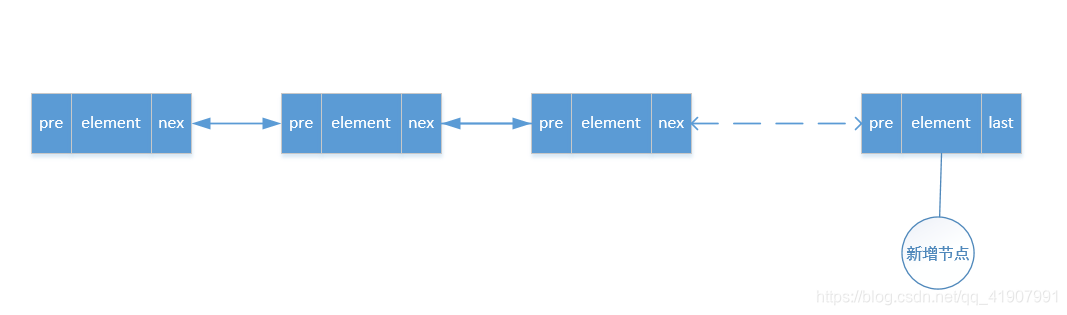
- 不要忘了,在添加后,我们集合的last指针也变成了我们新增的这个元素的next指针
上面我们分析了往尾部添加一个元素的情况,往头部添加一个元素就不多追诉了,那么往集合中添加一个元素呢?
我们先看下源码:
首先调用了node方法
Node<E> node(int index) {
// 这里主要是判断是离头部比较近还是离尾部比较近
// 如果头部比较近就从头节点开始搜索,否则就尾节点开始搜索
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
// 一直搜索到指定位置
x = x.next;
// 然后返回这个指定位置上的元素
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
之后调用linkBefore方法
// e:要添加的节点
// succ: 当前位置上的节点
// 这个方法主要就是将e添加到succ节点的前一个节点位置上
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// 用pred指针指向succ的前一个节点
final Node<E> pred = succ.prev;
// 创建一个新节点,pre指针指向succ的前一个节点,next指针指向succ,节点元素为e
final Node<E> newNode = new Node<>(pred, e, succ);
// succ的pre指针指向新增的节点
succ.prev = newNode;
// 如果succ.prev==null,说明succ是头节点,所以添加后,我们新增的节点就是头节点
if (pred == null)
first = newNode;
else
// 否则的话,就将succ的前一个节点的next指针指向新增的节点
pred.next = newNode;
// 集合长度+1
size++;
// 修改次数加+1
modCount++;
}
我们也用图形的方式来描述下这个过程:
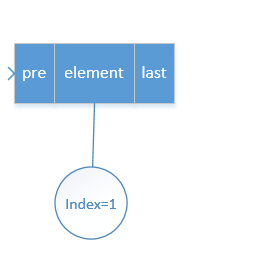
假设我们现在有一个三个元素的集合,如下: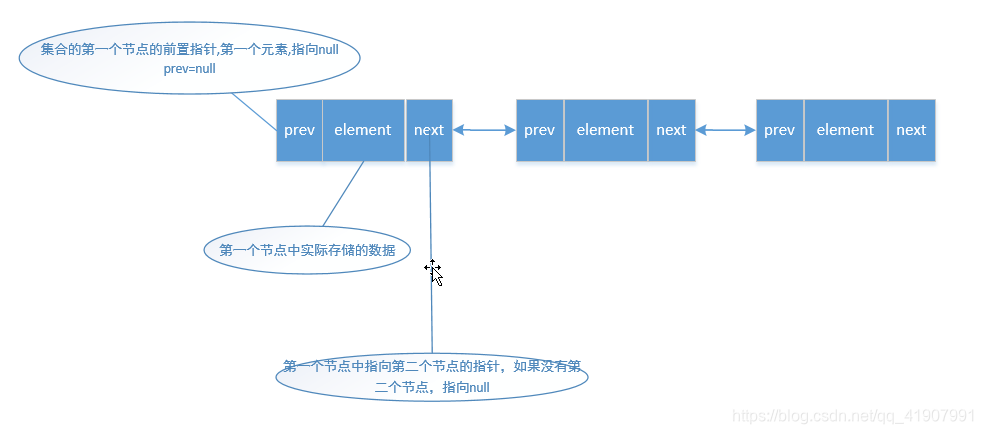
我们要在index=1的位置上新增一个元素,也就是调用add(1,“新元素”)
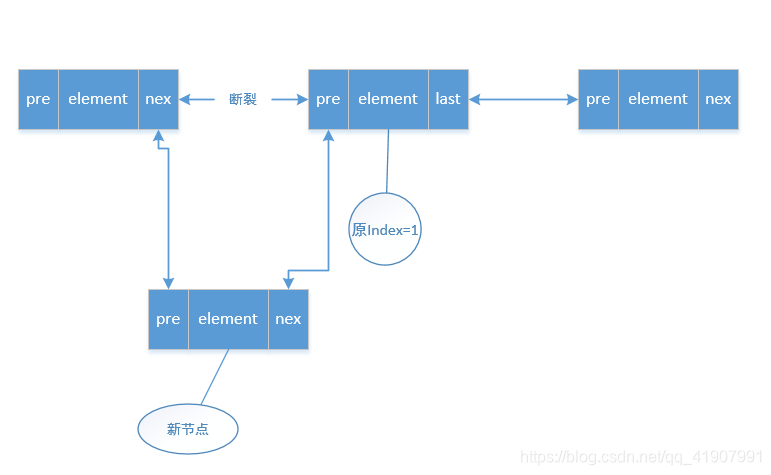
我们要获取到index=1的这个位置上的元素,通过源码我们知道,会通过头节点遍历到第二个节点后,返回给我们这个节点,也就是node方法
因为我们要在index=1的位置上插入元素,所以,我们要将index=0位置上的元素的next指针指向我们新增的元素,同时我们要新增的节点的pre指针指向头节点,另外,新增节点的next指针指向原index=1上位置的节点,index=1位置上的节点的pre指针指向我们新增的节点
get方法
public E get(int index) {
checkElementIndex(index);
// get就是调用我们之前分析过的node方法
// 获取指定位置上的节点,然后返回节点保存的元素
return node(index).item;
}
对比ArrayList我们也分析下迭代器
跟踪源码我们可以发现,核心就是下面这个内部类
private class ListItr implements ListIterator<E> {
// 记录当前迭代器最后一个返回的节点
private Node<E> lastReturned;
// 下一个迭代的节点
private Node<E> next;
// 下一个迭代的节点的索引位置
private int nextIndex;
// 快速失败机制
private int expectedModCount = modCount;
// 创建一个从指定位置开始迭代的迭代器
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
} public boolean hasNext() {
return nextIndex < size;
}
// 返回准备迭代的元素
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
// 记录返回的节点
lastReturned = next;
// 记录迭代器将要迭代的下一个节点
next = next.next;
// 索引+1
nextIndex++;
return lastReturned.item;
} public boolean hasPrevious() {
return nextIndex > 0;
} public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException(); lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
} public int nextIndex() {
return nextIndex;
} public int previousIndex() {
return nextIndex - 1;
}
// 分析下这个方法中的unlink方法
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException(); Node<E> lastNext = lastReturned.next;
// 移除上一次迭代的节点
unlink(lastReturned);
// 说明通过previous()方法迭代
if (next == lastReturned)
// 这个时候nextIndex不用发生变化
next = lastNext;
else
// 因为移除了一个元素,所以nextIndex需要减1
nextIndex--;
lastReturned = null;
expectedModCount++;
} public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
} public void add(E e) {
// 快速失败机制检查
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
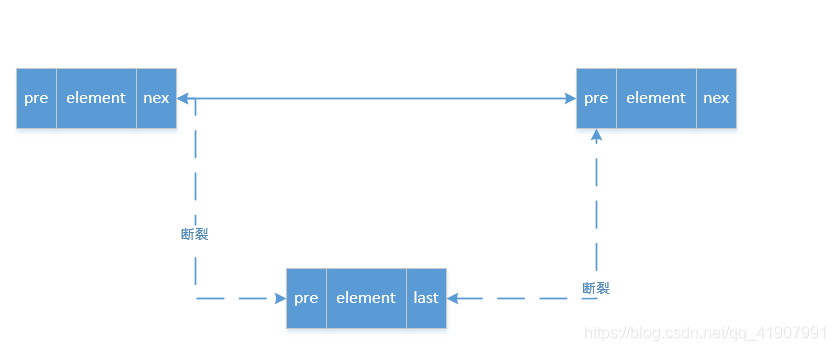
// 用于将元素从集合中移除
// 其实做的就是,将这个节点的pre指针指向的节点的next指针指向这个节点的next指针指向的节点
// 同时将这个节点的next指针指向的节点的pre指针指向这个节点的pre指针指向的节点
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev; if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
} if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
} x.item = null;
size--;
modCount++;
return element;
}
图片描述如下:
java读源码 之 list源码分析(LinkedList)的更多相关文章
- Java并发指南10:Java 读写锁 ReentrantReadWriteLock 源码分析
Java 读写锁 ReentrantReadWriteLock 源码分析 转自:https://www.javadoop.com/post/reentrant-read-write-lock#toc5 ...
- Java读源码之ReentrantLock
前言 ReentrantLock 可重入锁,应该是除了 synchronized 关键字外用的最多的线程同步手段了,虽然JVM维护者疯狂优化 synchronized 使其已经拥有了很好的性能.但 R ...
- Java读源码之ReentrantLock(2)
前言 本文是 ReentrantLock 源码的第二篇,第一篇主要介绍了公平锁非公平锁正常的加锁解锁流程,虽然表达能力有限不知道有没有讲清楚,本着不太监的原则,本文填补下第一篇中挖的坑. Java读源 ...
- Java读源码之CountDownLatch
前言 相信大家都挺熟悉 CountDownLatch 的,顾名思义就是一个栅栏,其主要作用是多线程环境下,让多个线程在栅栏门口等待,所有线程到齐后,栅栏打开程序继续执行. 案例 用一个最简单的案例引出 ...
- 源码分析— java读写锁ReentrantReadWriteLock
前言 今天看Jraft的时候发现了很多地方都用到了读写锁,所以心血来潮想要分析以下读写锁是怎么实现的. 先上一个doc里面的例子: class CachedData { Object data; vo ...
- 【转载】深度解读 java 线程池设计思想及源码实现
总览 开篇来一些废话.下图是 java 线程池几个相关类的继承结构: 先简单说说这个继承结构,Executor 位于最顶层,也是最简单的,就一个 execute(Runnable runnable) ...
- Java并发指南12:深度解读 java 线程池设计思想及源码实现
深度解读 java 线程池设计思想及源码实现 转自 https://javadoop.com/2017/09/05/java-thread-pool/hmsr=toutiao.io&utm_ ...
- 转:微信开发之使用java获取签名signature(贴源码,附工程)
微信开发之使用java获取签名signature(贴源码,附工程) 标签: 微信signature获取签名 2015-12-29 22:15 6954人阅读 评论(3) 收藏 举报 分类: 微信开发 ...
- java基础进阶一:String源码和String常量池
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/8046564.html 邮箱:moyi@moyib ...
- Java禁止浏览器有缓存的源码
Java禁止浏览器有缓存的源码 import java.io.IOException; import javax.servlet.Filter; import javax.servlet.Filter ...
随机推荐
- Win8.1/Win10在某些程序输入中文变成问号的解决方法
之前我是使用Win8.1,在某些软件上输入中文,却显示问号,换输入法也没用,当时也没用太在意,后来升级到Win10还是一样.同样的软件在其它Win8.1/Win10电脑却可以正常显示中文. 解决方法如 ...
- x聊之后,又一波新的诈骗套路
前些天刚看到,x聊勒索诈骗套路,骗子的套路可以说是花样百出,这不又一网友深受其害. 事情经过是这样的 某被骗网友由于工资微薄一直想找副业增加收入,关注和加了很多群. 注意群里都是有偏亮头像的”小姐姐” ...
- 关于《Python自动化测试实战》
作者有话说 笔者写这本书的初心是想通过自身经验分享一些在自动化测试领域中的实用技术,能够帮助那些正在从事自动化测试相关工作或者准备转型自动化测试的测试人员.任何一门技术涵盖的知识点都是非常广泛的,可能 ...
- AJ学IOS(53)多线程网络之NSOperation简介
AJ分享,必须精品 一:简单介绍 1:NSOperation的作⽤使用步骤: 配合使用NSOperation和NSOperationQueue也能实现多线程编程. NSOperation和NSOper ...
- threejs点击事件
示例浏览地址:https://ithanmang.gitee.io/threejs/home/201807/20180703/02-raycasterDemo.html 双击鼠标左键选中模型并显示信息 ...
- E. Max Gcd
单点时限: 2.0 sec 内存限制: 512 MB 一个数组a,现在你需要删除某一项使得它们的gcd最大,求出这个最大值. 输入格式 第一行输入一个正整数n,表示数组的大小,接下来一行n个数,第i个 ...
- Python - 实现文件名自动更改,避免同名文件被覆盖的两个解决方法
[原创]转载请注明作者Johnthegreat和本文链接. 在一些不多的数据下载和生成的时候,我们倾向于直接保存为文件,当我们修改某些参数后再一次运行时,之前运行时生成的文件就被覆盖了.为了解决这个问 ...
- AOP-SheepAspect
转载https://www.cnblogs.com/InCsharp/p/5902133.html SheepAspect 简介以及代码示列: SheepAspect是一个AOP框架为.NET平台,深 ...
- tf.keras的模块
- 23-Java-Spring框架(一)
一.Spring框架了解 Spring框架是一个开源的框架,为JavaEE应用提供多方面的解决方案,用于简化企业级应用的开发,相当于是一种容器,可以集成其他框架(结构图如下). 上图反映了框架引包的依 ...