Flink(三) —— 运行架构
Flink运行时组件
- JobManager 作业管理器
- TaskManager 任务管理器
- ResourceManager 资源管理器
- Dispatcher 分发器
任务提交流程
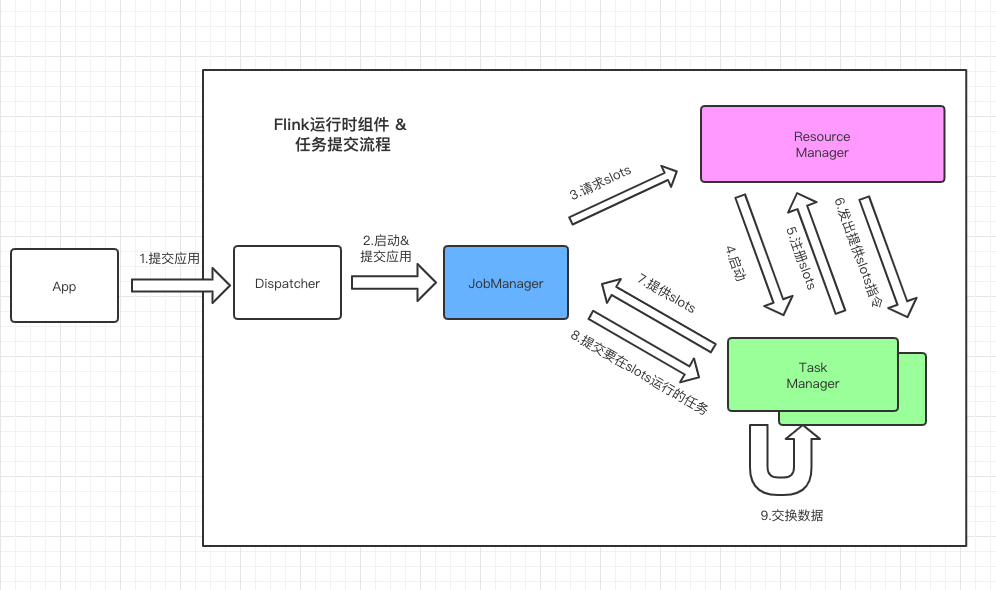
任务调度原理
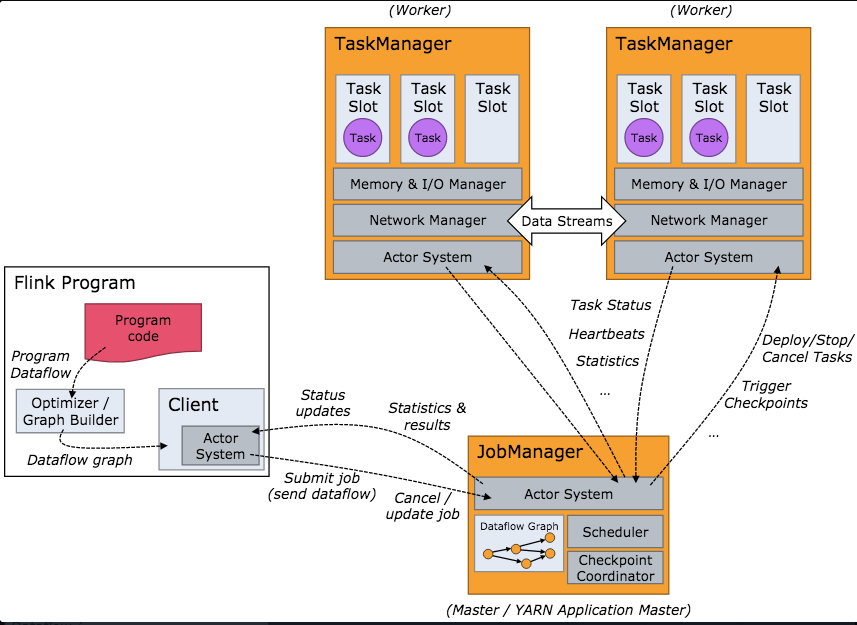
Job Managers, Task Managers, Clients
The Flink runtime consists of two types of processes:
The JobManagers (also called masters) coordinate the distributed execution. They schedule tasks, coordinate checkpoints, coordinate recovery on failures, etc.
There is always at least one Job Manager. A high-availability setup will have multiple JobManagers, one of which one is always the leader, and the others are standby.
The TaskManagers (also called workers) execute the tasks (or more specifically, the subtasks) of a dataflow, and buffer and exchange the data streams.
There must always be at least one TaskManager.
The JobManagers and TaskManagers can be started in various ways: directly on the machines as a standalone cluster, in containers, or managed by resource frameworks like YARN or Mesos. TaskManagers connect to JobManagers, announcing themselves as available, and are assigned work.
The client is not part of the runtime and program execution, but is used to prepare and send a dataflow to the JobManager. After that, the client can disconnect, or stay connected to receive progress reports. The client runs either as part of the Java/Scala program that triggers the execution, or in the command line process ./bin/flink run ....
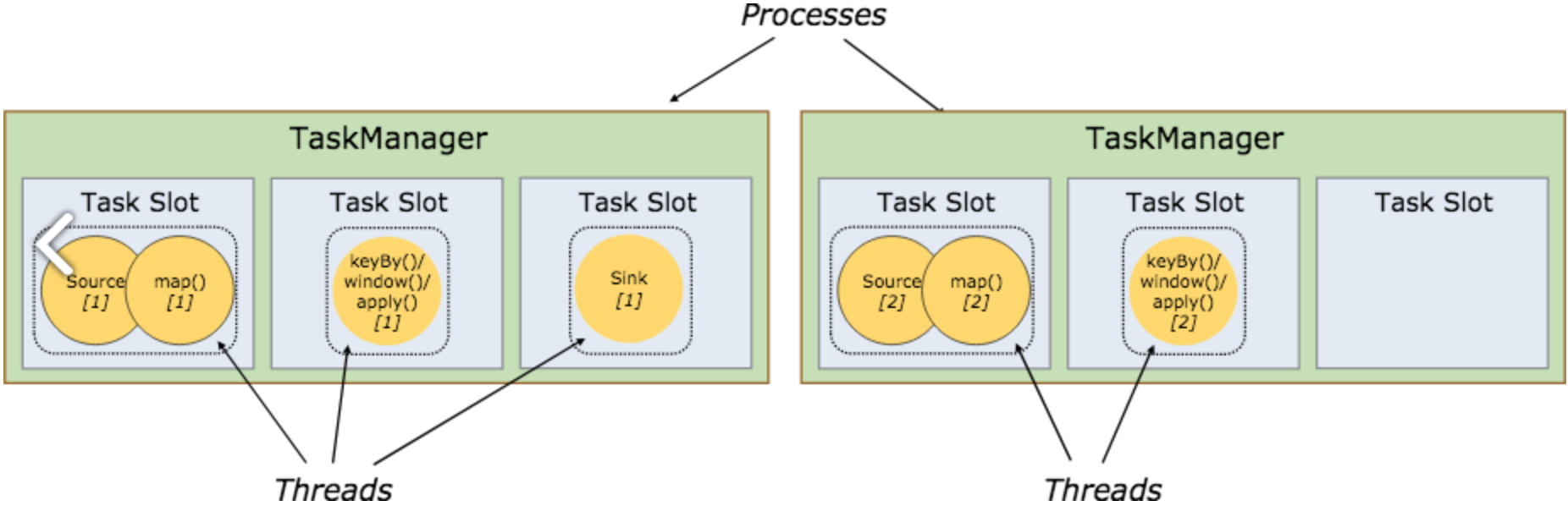
Task Slots and Resources
Each worker (TaskManager) is a JVM process, and may execute one or more subtasks in separate threads. To control how many tasks a worker accepts, a worker has so called task slots (at least one).
每个TaskManager都是一个JVM进程,可以在独立的线程中执行一个或多个子任务。TaskManager有Task Slots来控制可以接收多少个任务(一个TaskManager至少有一个Task Slot)。
Each task slot represents a fixed subset of resources of the TaskManager. A TaskManager with three slots, for example, will dedicate 1/3 of its managed memory to each slot. Slotting the resources means that a subtask will not compete with subtasks from other jobs for managed memory, but instead has a certain amount of reserved managed memory. Note that no CPU isolation happens here; currently slots only separate the managed memory of tasks.
By adjusting the number of task slots, users can define how subtasks are isolated from each other. Having one slot per TaskManager means each task group runs in a separate JVM (which can be started in a separate container, for example). Having multiple slots means more subtasks share the same JVM. Tasks in the same JVM share TCP connections (via multiplexing) and heartbeat messages. They may also share data sets and data structures, thus reducing the per-task overhead.
参考文档
Flink Distributed Runtime Environment
Flink(三) —— 运行架构的更多相关文章
- Flink 的运行架构详细剖析
1. Flink 程序结构 Flink 程序的基本构建块是流和转换(请注意,Flink 的 DataSet API 中使用的 DataSet 也是内部流 ).从概念上讲,流是(可能永无止境的)数据记录 ...
- Flink| 运行架构
1. Flink运行时组件 作业管理器(JobManager) 任务管理器(TaskManager) 资源管理器(ResourceManager) 分发器(Dispatcher) 2. 任务提交流程 ...
- hadoop记录-[Flink]Flink三种运行模式安装部署以及实现WordCount(转载)
[Flink]Flink三种运行模式安装部署以及实现WordCount 前言 Flink三种运行方式:Local.Standalone.On Yarn.成功部署后分别用Scala和Java实现word ...
- 01-Flink运行架构
1.flink运行时的组件 Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作: 作业管理器(JobManager).资源管理器(ResourceManager). ...
- Flink(二)【架构原理,组件,提交流程】
目录 一.运行架构 1.架构 2.组件 二.核心概念 TaskManager . Slots Parallelism(并行度) Task .Subtask Operator Chains(任务链) E ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- 【转载】Spark运行架构
1. Spark运行架构 1.1 术语定义 lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个 ...
- Apache Flink 分布式运行时环境
Tasks and Operator Chains(任务及操作链) 在分布式环境下,Flink将操作的子任务链在一起组成一个任务,每一个任务在一个线程中执行.将操作链在一起是一个不错的优化:它减少了线 ...
- 朱晔的互联网架构实践心得S1E8:三十种架构设计模式(下)
朱晔的互联网架构实践心得S1E8:三十种架构设计模式(下) [下载本文PDF进行阅读] 接上文,继续剩下的15个模式. 数据管理模式 16.分片模式:将数据存储区划分为一组水平分区或分片 一直有一个说 ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
随机推荐
- Essay写作的灵魂:内容
在国内大家也许不觉得时常要写essay,但在国外留学,时不时就会有一篇essay写作任务下来.而时常写文的同学们应当就会知道一篇文章中的介绍和结论有多么重要,甚至于当导师拿到你的essay,如果摘要没 ...
- shell教程<入门篇>
由于我平时的工作环境是linux,所以无可避免的经常使用命令行模式和shell脚本,而且有些命令行每天都要输好多遍,比如ssh登录之类的,所以干脆把平时常用的命令都写成脚本文件,所以特意开了一个she ...
- idea中maven下载jar包不完整问题
解决: 1.输入 mvn -U idea:idea 等1.都下载完毕后,在点击2.即Reimport
- 用Python在00:00给微信好友发元旦祝福语
2019年的元旦即将来临,这里用Python撸一串简单的代码来实现定点给微信里的所有小伙伴发祝福语 环境说明 Python版本: 不限 第三方库: itchat, schedule 注:所有祝福语来源 ...
- lvs和keepalived
LVS调度算法参考 RR:轮询 WRR :加权轮询 DH :目标地址哈希 SH:源地址hash LC:最少连接 WLC:加权最少连接,默认 SED:最少期望延迟 NQ:从不排队调度方法 LBLC:基于 ...
- 2020牛客寒假算法基础集训营4 H坐火车
题目描述 牛牛是一名喜欢旅游的同学,在来到渡渡鸟王国时,坐上了颜色多样的火车. 牛牛同学在车上,车上有 n 个车厢,每一个车厢有一种颜色. 他想知道对于每一个正整数 $ x \in [1,\ n] $ ...
- JetBrains系列-插件
插件官网:http://plugins.jetbrains.com 注意:网站有时不稳定,会造成打不开,属正常现象或许下一秒就好了,可以选择去git等方式下载 1.安装说明: 打开fil ...
- Cracking Digital VLSI Verification Interview 第一章
目录 Digital Logic Design Number Systems, Arithmetic and Codes Basic Gates Combinational Logic Circuit ...
- 吴裕雄--天生自然 JAVASCRIPT开发学习:Date(日期) 对象
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 201771010123汪慧和《面向对象程序设计JAVA》第七周实验总结
一.理论部分 1.继承 如果两个类存在继承关系,则子类会自动继承父类的方法和变量,在子类中可以调用父类的方法和变量,如果想要在子类里面做一系列事情,应该放在父类无参构造器里面,在java中,只允许单继 ...