原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我
注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的。
爬虫目标网站:http://jandan.net/ooxx/ #如有侵权请联系我
代码如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib.request
import base64
import time url_a = 'http://jandan.net/ooxx/'#网站前一部分
need = '20200217-'#后一部分
need_a = 147#后一部分的后一部分 def base(word):#base64编码
outcome = base64.b64encode(word.encode("utf-8"))#编码后
url = url_a + outcome.decode('utf-8') + '#comments'
web(url) def web(url):
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
a = html.find('<img src="//')#从这个下标开始
i = 0#用来区别文件名
while a != -1:
b = html.find('.jpg',a,a+250)#到这个下标为止
if b != -1:
c = 'http://' + html[a+12:b+4]#图片网址
name = 'picture\\' + str(i) + str(need_a) + '.jpg'#文件名
get_jpg(c,name)
else:
b = a + 12
a = html.find('<img src="//',b)#循环查找
i += 1 def get_jpg(address,filename):
get = urllib.request.urlopen(address)#打开新网址
jpg = get.read()
with open(filename,'wb') as f:#写入图片
f.write(jpg)
print("Succeed!") while need_a >=100:#逐减
addition = need + str(need_a)
base(addition)
need_a -= 1
time.sleep(10)#停顿防止被反爬
效果图:
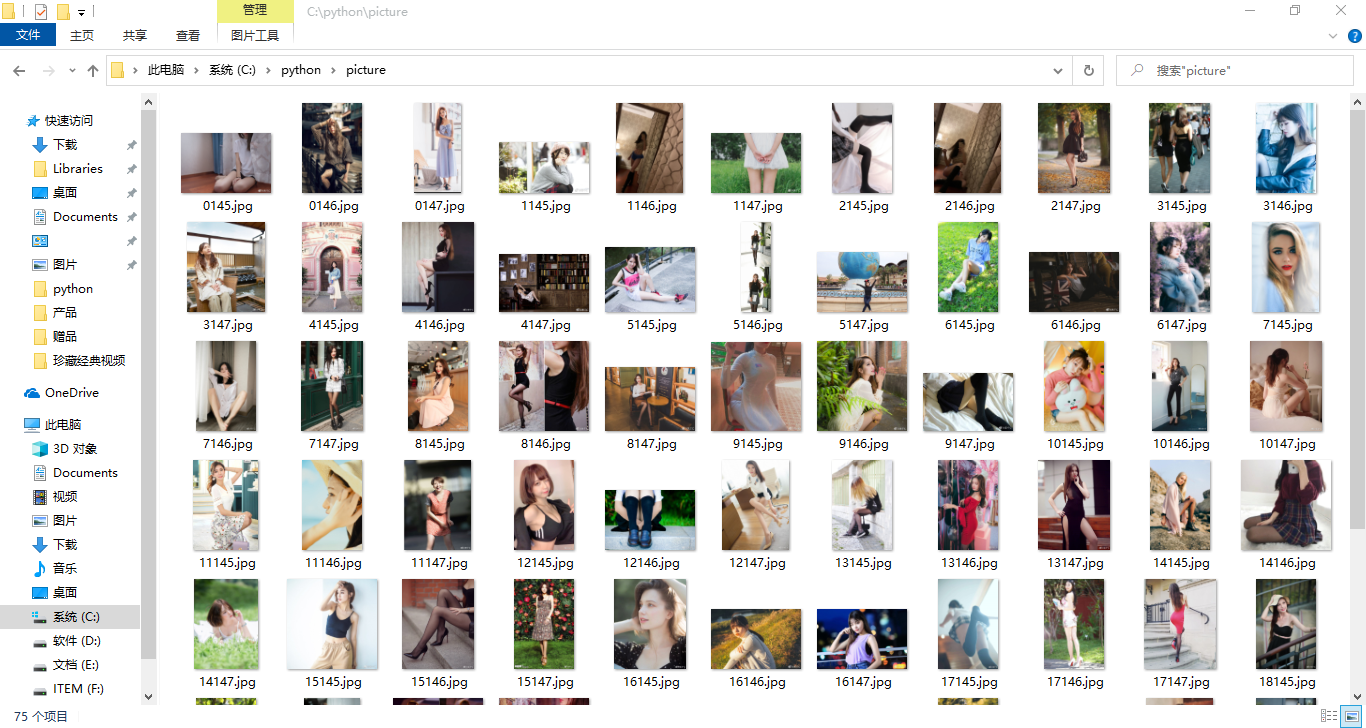
未经博主允许,不得转载
原创:Python爬虫实战之爬取美女照片的更多相关文章
- 原创:Python爬虫实战之爬取代理ip
编程的快乐只有在运行成功的那一刻才知道QAQ 目标网站:https://www.kuaidaili.com/free/inha/ #若有侵权请联系我 因为上面的代理都是http的所以没写这个判断 代 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python 爬虫实战1 爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 抓取糗事百科热门段子 过滤带有图片的段子 实现每按一次回车显示一个段子的发布时间,发布人 ...
- 芝麻HTTP:Python爬虫实战之爬取百度贴吧帖子
本篇目标 1.对百度贴吧的任意帖子进行抓取 2.指定是否只抓取楼主发帖内容 3.将抓取到的内容分析并保存到文件 1.URL格式的确定 首先,我们先观察一下百度贴吧的任意一个帖子. 比如:http:// ...
随机推荐
- Kubernetes系列:故障排查之Pod状态为CreateContainerError
查看pod状态如下图所示,当前状态为CreateContainerError. 通过kube describe命令去查看Pod的状态发现没有提示任何错误.但是当通过命令kube logs查看pod的日 ...
- IIS设置禁止某个IP或IP段访问网站的方法
网站被刷,对话接不过来 打开IIS,选中禁IP的站点,找到“ip地址和域限制”这个功能,如果没有安装,打开服务器管理器,点击角色,窗口右边找到添加角色服务,找到“IP和域限制”并勾选安装. 打开ip地 ...
- Opencv笔记(十八)——轮廓的更多函数及其层次结构
凸缺陷 前面我们已经学习了轮廓的凸包,对象上的任何凹陷都被成为凸缺陷.OpenCV 中有一个函数 cv.convexityDefect() 可以帮助我们找到凸缺陷.函数调用如下: hull = cv2 ...
- vbox NAT 设置端口映射(NAT+8080端口转发)
VirtualBox的提供了四种网络接入模式,它们分别是: 1.NAT 网络地址转换模式(NAT,Network Address Translation) 2.Bridged Adapter 桥接模式 ...
- 吴裕雄--天生自然 JAVA开发学习:发送邮件
import java.util.*; import javax.mail.*; import javax.mail.internet.*; import javax.activation.*; pu ...
- scala slick mysql utf8mb4 支持
语言 scala sql包 slick 3.2.0 数据库 mysql https://stackoverflow.com/questions/36741141/scala-slick-jdbc ...
- qsub|pasta|
cd /xxx/genome_stat/Annotation ln -s /xxx/02.annotation/gff_v2/*.homolog.v2.gff /xxx/genome_stat/Ann ...
- IO概念和五种IO模型
一.什么是IO? 我们都知道unix世界里.一切皆文件.而文件是什么呢?文件就是一串二进制流而已.不管socket.还是FIFO.管道.终端.对我们来说.一切都是文件.一切都是流.在信息交换的过程中. ...
- Git教程 - 远程仓库
到目前为止,我们已经掌握了如何在Git仓库里对一个文件进行时光穿梭,你再也不用担心文件备份或者丢失的问题了. 可是有用过集中式版本控制系统SVN的童鞋会站出来说,这些功能在SVN里早就有了,没看出Gi ...
- [LC] 82. Remove Duplicates from Sorted List II
Given a sorted linked list, delete all nodes that have duplicate numbers, leaving only distinct numb ...