java文档打包成压缩包并且下载
需求,根据产品ID查询产品详情,产品详情会返回产品的一些文案,以及图片的url。需要做成,将文案信息记录在一个txt文档中,然后图片下载到文件夹,最后下载到本地,下载后自动删除刚才生成的文件夹以及文件夹生成的压缩包等。
例如压缩包打开是这样的:
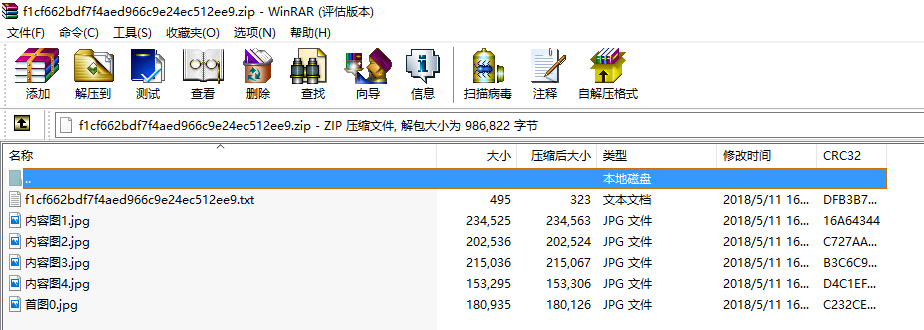
txt文档是这样的:
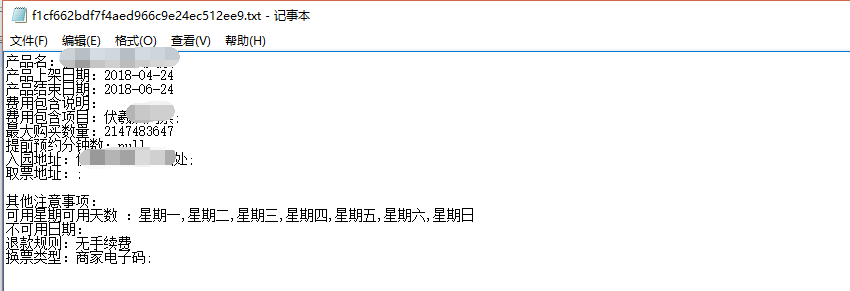
需求已明了,现在开始从页面点击下载开始action层:
由于我是每次用户点击页面下载时,生成文件到一个压缩包,压缩包存在项目的路径下的,下载成功后删除文件以及压缩包。
/**
* 获取当前产品的文案
*
* @return
* @throws IOException
*/
public Resolution getZip() throws IOException {
HttpServletResponse response = getContext().getResponse();
Integer i = Integer.valueOf(gysupplierproducts.getProd_code());//
JSONArray recal = getDealInfo.getDealInfoForOne(i);//得到产品信息json串
String url = "";
String name = "";
String fileDir = "";
for (int n = 0; n < recal.size(); n++) {
Map<String, Object> returnMap = gysupplierproductsService.saveZip(recal.get(n).toString());//解析json串
url = returnMap.get("url").toString();
name = returnMap.get("name").toString();
fileDir = url;
try {
url = url+".zip";
try {
File file = new File(url);
File file2 = new File(fileDir);
name = name+".zip";
response.setCharacterEncoding("UTF-8");
response.setHeader("Content-Disposition",
"attachment; filename=" + new String(name.getBytes("ISO8859-1"), "UTF-8"));
response.setContentLength((int) file.length());
response.setContentType("application/zip");// 定义输出类型
FileInputStream fis = new FileInputStream(file);
BufferedInputStream buff = new BufferedInputStream(fis);
byte[] b = new byte[1024];// 相当于我们的缓存
long k = 0;// 该值用于计算当前实际下载了多少字节
OutputStream myout = response.getOutputStream();// 从response对象中得到输出流,准备下载
// 开始循环下载
while (k < file.length()) {
int j = buff.read(b, 0, 1024);
k += j;
myout.write(b, 0, j);
}
myout.flush();
buff.close();
file.delete();//删除生成的压缩包文件
ZipUtils.delAllFile(fileDir);//文件夹下面还有东西,需要全部删除。
file2.delete(); //删除生产的文件
} catch (Exception e) {
System.out.println(e);
} } catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
service层,解析JSONArry,记录文本信息到txt,下载图片到指定文件夹下。
省略一解析部分:
public Map<String,Object> saveZip(String delStr) throws IOException{
Map<String,Object> returnMap = new HashMap<String, Object>();
returnMap.put("url", "");
returnMap.put("name", "");
JSONObject dealInfo = JSONObject.fromObject(delStr);
File directory = new File("");// 参数为空
String courseFile = directory.getCanonicalPath();
//I:\workspace\qhzn-fxxt
String fileName = Comb.getComb().replaceAll("-","");
courseFile = courseFile+"\\webapp\\zip\\"+fileName;
//I:\workspace\qhzn-fxxt/webapp/zip/425a0c0490704706813593d080329037
System.out.println(courseFile);
File dirFile = new File(courseFile);
dirFile.mkdir();//创建文件夹
DealBaseInfo baseInfo = (DealBaseInfo)JSONObject.toBean(dealInfo.getJSONObject("baseInfo"), DealBaseInfo.class) ;
String title = baseInfo.getTitle();//产品名称
JSONArray inageArray = JSONArray.fromObject(baseInfoObj.get("imgInfos"));
List<ImageInfo> inageList = JSONArray.toList(inageArray, new ImageInfo(), new JsonConfig());
// List<ImageInfo> inageList = baseInfo.getImgInfos();
for (int i = 0; i < inageList.size(); i++) {
Integer frontImage =inageList.get(i).getFrontImage();
String imgName = "";
if(1==frontImage){
//首图
imgName = "首图"+i;
this.downloadPicture(inageList.get(i).getImageUrl(), courseFile,imgName);
}else{
//
imgName = "内容图"+i;
this.downloadPicture(inageList.get(i).getImageUrl(), courseFile,imgName);
}
}
StringBuffer buffer = new StringBuffer();
buffer.append("产品名:"+title+"\r\n");
buffer.append("可用星期可用天数 :"+this.strToWeek(validWeekRule)+"\r\n");
//将解析的文字记录到txt
FileMT.saveFile(fileName, buffer.toString(),courseFile);
//压缩文件 courseFile
FileOutputStream fos1 = new FileOutputStream(new File(courseFile+".zip"));
ZipUtils.toZip(courseFile, fos1, false);
returnMap.put("url", courseFile);//返回生成的文件夹名称和路径
returnMap.put("name", fileName);
return returnMap;
}
用到的公共方法:在解析周的时候,做了特殊处理,因为产品信息返回的周例如:"1101000"表示周一周二和周四可用,所以我们给用户展现需要转换过来。
一下是用到了方法:1101000转换星期
public static String strToWeek(String str){
String week="";
String[] weekArr={"星期一","星期二","星期三","星期四","星期五","星期六","星期日"};
for(int i=0;i<str.length();i++){
String curStr=str.substring(i, i+1);
if("1".equals(curStr)){
week+=weekArr[i]+",";
}
}
if(StringUtils.isNotBlank(week)){
week=week.substring(0,week.length()-1);
}
return week;
}
下载网络图片:
/***
*urlList == 网络路径;path===下载存放的位置;imgName==图片名称
**/
private static void downloadPicture(String urlList,String path,String imgName) {
URL url = null;
try {
url = new URL(urlList);
DataInputStream dataInputStream = new DataInputStream(url.openStream()); FileOutputStream fileOutputStream = new FileOutputStream(new File(path+"\\"+imgName+".jpg"));
ByteArrayOutputStream output = new ByteArrayOutputStream(); byte[] buffer = new byte[1024];
int length; while ((length = dataInputStream.read(buffer)) > 0) {
output.write(buffer, 0, length);
}
fileOutputStream.write(output.toByteArray());
dataInputStream.close();
fileOutputStream.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
FileMT类,保存成txt文本。
public static String saveFile(String fileName,String content,String url){
String result="";
try {
contentToTxt(url+"/"+fileName+".txt", content);
result="1";
} catch (Exception e) {
result="2";
e.printStackTrace();
}
return result;
}
public static void contentToTxt(String filePath, String content) {
String str = new String();
String s1 = new String();
try {
File f = new File(filePath);
File parent = f.getParentFile();
if(parent!=null&&!parent.exists()){
parent.mkdirs();
}
f.createNewFile();
if (f.exists()) {
System.out.print("文件存在");
} else {
System.out.print("文件不存在");
f.createNewFile();
}
BufferedReader input = new BufferedReader(new FileReader(f));
while ((str = input.readLine()) != null) {
s1 +="";
}
input.close();
content= new String(content.getBytes("UTF-8"),"UTF-8");
s1 += content;
BufferedWriter output = new BufferedWriter(new FileWriterWithEncoding(f, "utf-8"));
output.write(s1);
output.close();
} catch (Exception e) {
e.printStackTrace();
}
}
ZipUtils类,主要是压缩文件和删除文件夹工具类:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream; import com.tmwsoft.util.EncryptPassword; public class ZipUtils { private static final int BUFFER_SIZE = 2 * 1024; /**
* 压缩成ZIP 方法1
*
* @param srcDir
* 压缩文件夹路径
* @param out
* 压缩文件输出流
* @param KeepDirStructure
* 是否保留原来的目录结构,true:保留目录结构;
* false:所有文件跑到压缩包根目录下(注意:不保留目录结构可能会出现同名文件,会压缩失败)
* @throws RuntimeException
* 压缩失败会抛出运行时异常
*/
public static void toZip(String srcDir, OutputStream out, boolean KeepDirStructure) throws RuntimeException {
long start = System.currentTimeMillis();
ZipOutputStream zos = null;
try {
zos = new ZipOutputStream(out);
File sourceFile = new File(srcDir);
compress(sourceFile, zos, sourceFile.getName(), KeepDirStructure);
long end = System.currentTimeMillis();
System.out.println("压缩完成,耗时:" + (end - start) + " ms");
} catch (Exception e) {
throw new RuntimeException("zip error from ZipUtils", e);
} finally {
if (zos != null) {
try {
zos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} } /**
* 递归压缩方法
*
* @param sourceFile
* 源文件
* @param zos
* zip输出流
* @param name
* 压缩后的名称
* @param KeepDirStructure
* 是否保留原来的目录结构,true:保留目录结构;
* false:所有文件跑到压缩包根目录下(注意:不保留目录结构可能会出现同名文件,会压缩失败)
* @throws Exception
*/
private static void compress(File sourceFile, ZipOutputStream zos, String name, boolean KeepDirStructure)
throws Exception {
byte[] buf = new byte[BUFFER_SIZE];
if (sourceFile.isFile()) {
// 向zip输出流中添加一个zip实体,构造器中name为zip实体的文件的名字
zos.putNextEntry(new ZipEntry(name));
// copy文件到zip输出流中
int len;
FileInputStream in = new FileInputStream(sourceFile);
while ((len = in.read(buf)) != -1) {
zos.write(buf, 0, len);
}
// Complete the entry
zos.closeEntry();
in.close();
} else {
File[] listFiles = sourceFile.listFiles();
if (listFiles == null || listFiles.length == 0) {
// 需要保留原来的文件结构时,需要对空文件夹进行处理
if (KeepDirStructure) {
// 空文件夹的处理
zos.putNextEntry(new ZipEntry(name + "/"));
// 没有文件,不需要文件的copy
zos.closeEntry();
} } else {
for (File file : listFiles) {
// 判断是否需要保留原来的文件结构
if (KeepDirStructure) {
// 注意:file.getName()前面需要带上父文件夹的名字加一斜杠,
// 不然最后压缩包中就不能保留原来的文件结构,即:所有文件都跑到压缩包根目录下了
compress(file, zos, name + "/" + file.getName(), KeepDirStructure);
} else {
compress(file, zos, file.getName(), KeepDirStructure);
} }
}
}
} public static boolean delAllFile(String path) {
boolean flag = false;
File file = new File(path);
if (!file.exists()) {
return flag;
}
if (!file.isDirectory()) {
return flag;
}
String[] tempList = file.list();
File temp = null;
for (int i = 0; i < tempList.length; i++) {
if (path.endsWith(File.separator)) {
temp = new File(path + tempList[i]);
} else {
temp = new File(path + File.separator + tempList[i]);
}
if (temp.isFile()) {
temp.delete();
}
if (temp.isDirectory()) {
delAllFile(path + "/" + tempList[i]);// 先删除文件夹里面的文件
delFolder(path + "/" + tempList[i]);// 再删除空文件夹
flag = true;
}
}
return flag;
} public static void delFolder(String folderPath) {
try {
delAllFile(folderPath); // 删除完里面所有内容
String filePath = folderPath;
filePath = filePath.toString();
java.io.File myFilePath = new java.io.File(filePath);
myFilePath.delete(); // 删除空文件夹
} catch (Exception e) {
e.printStackTrace();
}
} public static void main(String[] args) throws FileNotFoundException {
/** 测试压缩方法1 */
FileOutputStream fos1 = new FileOutputStream(new File("f:/新建文本文档.zip"));
ZipUtils.toZip("f:/新建文本文档.txt", fos1, true); } }
最后来个声明,以上所有资料都是我在网上找的别人的文章,然后复制代码变成我的了,已经找不到具体哪一篇。
java文档打包成压缩包并且下载的更多相关文章
- JAVAWEB使用FreeMarker利用ftl把含有图片的word模板生成word文档,然后打包成压缩包进行下载
这是写的另一个导出word方法:https://www.cnblogs.com/pxblog/p/13072711.html 引入jar包,freemarker.jar.apache-ant-zip- ...
- JAVA:借用OpenOffice将上传的Word文档转换成Html格式
为什么会想起来将上传的word文档转换成html格式呢?设想,如果一个系统需要发布在页面的文章都是来自word文档,一般会执行下面的流程:使用word打开文档,Ctrl+A,进入发布文章页面,Ctrl ...
- java将office文档pdf文档转换成swf文件在线预览
第一步,安装openoffice.org openoffice.org是一套sun的开源office办公套件,能在widows,linux,solaris等操作系统上执行. 主要模块有writer(文 ...
- java项目采用exe4j打包成exe档
java项目采用exe4j打包成exe档 前言:我们都知道java是平台无关性.能够打包成jar文件,到不论什么操作系统有jre环境的电脑都能够同意!可是我们打包成exe文件就相当于舍弃了这一大优势, ...
- java将XML文档转换成json格式数据
功能 将xml文档转换成json格式数据 说明 依赖包:1. jdom-2.0.2.jar : xml解析工具包;2. fastjson-1.1.36.jar : 阿里巴巴研发的高性能json工具包 ...
- 用java将简单的word文档换成pdf文档
用java将简单的word文档换成pdf文档的方式很多,因为很多都没有实际测试过,所以这里就先泛泛的说一下 整体上来看分两种: 1.纯java代码实现,有很多优秀的开源软件可以用,比如poi,itex ...
- JAVA基础学习之命令行方式、配置环境变量、进制的基本转换、排序法、JAVA文档生成等(1)
1.命令行方式 dos命令行,常见的命令: dir:列出当前目录下的文件以及文件夹 md:创建目录 rd:删除目录 cd:进入指定目录 cd..:退回到上一级目录 cd/:退回到根目录 del:删除文 ...
- OpenOffice Word文档转换成Html格式
为什么会想起来将上传的word文档转换成html格式呢?设想,如果一个系统需要发布在页面的文章都是来自word文档,一般会执行下面的流程:使用word打开文档,Ctrl+A,进入发布文章页面,Ctrl ...
- Java 学习(20):Java Applet 基础 & Java 文档注释
-- Java Applet 基础 -- Java 文档注释 Java Applet 基础 Applet 是一种 Java 程序.它一般运行在支持 Java 的 Web 浏览器内.因为它有完整的 Ja ...
随机推荐
- java并发编程之一--Semaphore的使用
1.介绍 Semaphore 中文的含义 信号,信号系统,此类的只要作用就是限制线程的并发的数量. Semaphore内部主要通过AQS(AbstractQueuedSynchronizer)实现线程 ...
- 第8课 goto和void分析
遭人遗弃的goto: C语言是一种面向过程的结构化语言,其中主要结构有三种,顺序执行.选择执行.循环执行.再复杂的程序也是由这三种结构组合而成的. goto破坏了结构化特性,使程序以第四种方式执行,结 ...
- c++ 读取所有图片
copyright by Jun Yang, SUN YAT-SEN UNIVERSITY //FileList.h ///////////////////////////////////////// ...
- 谷歌浏览器怎么调试js 谷歌浏览器调试javascript教程
谷歌浏览器是一款由谷歌公司开发的浏览器.谷歌浏览器是一款基于其他开源软件所撰写的.下面小编为大家分享一篇谷歌浏览器调试javascript的教程,希望帮助大家 首先我们打开开发者工具,你可以直接在页面 ...
- IDEA 使用generator逆向工程生成pojo,mapper
1.新建立一个MAVEN项目 2.在pom.xml增加配置 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns: ...
- flask第二十六篇——模板【控制语句】【2】
如果你也在学flask,就请加船长的公众号:自动化测试实战 我们先补充一下for循环的知识,我们之前说过,flask是由Jinja2+sqlAlchemy+werkzeug组成的,我们现在学的控制语句 ...
- 每天进步一点点——Linux中的线程局部存储(一)
转载请说明出处:http://blog.csdn.net/cywosp/article/details/26469435 在Linux系统中使用C/C++进行多线程编程时,我们遇到最多的就是对同 ...
- 用Keras 和 DDPG play TORCS(1)
用Keras 和 DDPG play TORCS(环境配置篇) 原作者Using Keras and Deep Deterministic Policy Gradient to play TORCS ...
- MySQL This function has none of DETERMINISTIC, NO SQL...错误1418 的原因分析及解决方法
MySQL开启bin-log后,调用存储过程或者函数以及触发器时,会出现错误号为1418的错误: ERROR 1418 (HY000): This function has none of DETER ...
- debian7配置iptables
vim /etc/iptables.rule 文件内容如下 *filter # Allows all loopback (lo0) traffic and drop all traffic to / ...