K-Means & Sequential Leader Clustering
2017-12-31 19:08:37
k-平均算法源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。k-means的目的是:把样本划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
这个问题在计算上是困难的(NP困难),不过存在高效的启发式算法。一般情况下,都使用效率比较高的启发式算法,它们能够快速收敛于一个局部最优解。这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)。
K-means比较适合数据类型是球状的数据,也就是不同的簇的形状是一球一球的。
一、簇评估
聚类问题由于是无监督的问题,可以说是没有什么标准答案的,也就是说怎么分类都是可能的。

另外坐标的变换也是会影响最终的结果的:
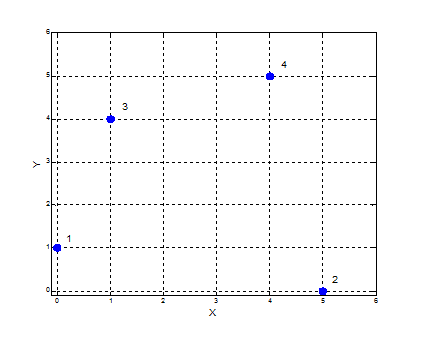
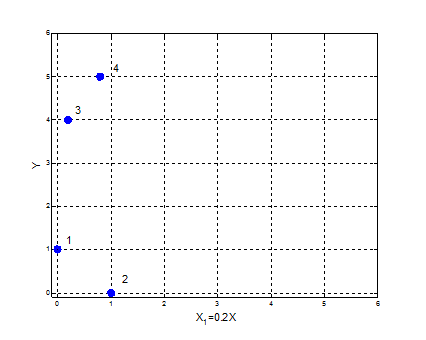
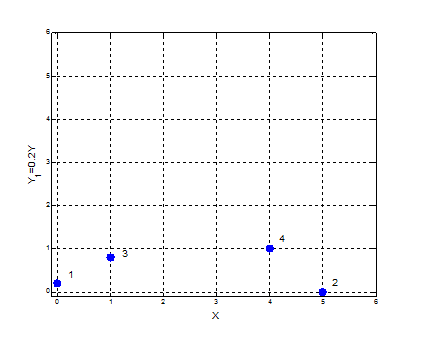
那么该如何对聚类的结果进行评判呢?
- 计算类似聚合度的概念

也就是通过计算每个数据和他到其类均值的距离平方,最后再求和得到最后的数值,显然,数值越低表征聚类效果越好。同样的,这种判断方法也是针对一团一团的数据比较好用。
- Silhouette

对每个数据点计算s(i)的值,其中b(i)表示其到数据点i到各个其他类的距离的均值的最小值,a(i)则表示数据点i到自身这个类的距离的均值。
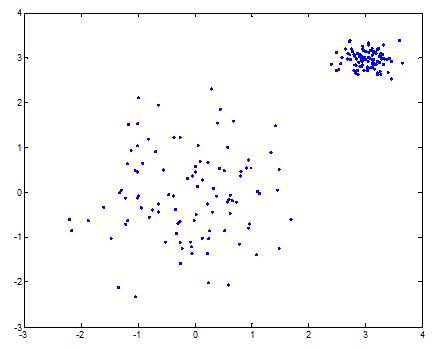
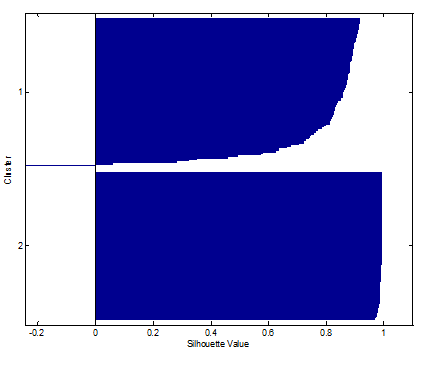
对于聚合程度高的类他的S图是比较规整的,对于分散的则是比较参差不齐的。
二、K-Means算法
K-Means顾名思义就是k个均值的意思,K-Means算法本质上也是一种EM算法思想的应用。
该算法非常形象的表述了如何计算收敛到k个类的一个过程:
首先生成k个类(也就是随机生成k个中心);
然后通过k个均值,得到属于他们的数据点;
通过得到的中心点重新计算其k个均值;
loop第二步,第三步直到k个均值保持不变。

因为k-means比较简单,所以得到了非常广泛的使用,其有如下的优点和缺点。
优点:
- 收敛迅速,简单高效,适用于一团一团的数据;
- 算法复杂度O(tkn),t是迭代次数,k类的个数,n数据点的个数;
缺点:
- k值的选择,初始点的选择都会产生迥异的结果;
- 对噪点敏感,因为使用的是均值;
- 对奇怪的形状适用性较差;
三、Sequential Leader Clustering
Sequential Leader Clustering可以处理流数据。K-Means如果看成是把一群人聚集到教室再进行分类的话,那Sequential Leader Clustering就是对每一个进来的同学进行一个分类,所以Sequential Leader Clustering不需要迭代运算,只需要遍历一遍数据集就可以了,值得一提的是这种算法不需要设定k值。
Sequential Leader Clustering需要手动设置一个阈值。
算法流程:

n {\displaystyle n} 
K-Means & Sequential Leader Clustering的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 【CV论文阅读】Unsupervised deep embedding for clustering analysis
Unsupervised deep embedding for clustering analysis 偶然发现这篇发在ICML2016的论文,它主要的关注点在于unsupervised deep e ...
- [C8] 聚类(Clustering)
聚类(Clustering) 非监督学习:简介(Unsupervised Learning: Introduction) 本章节介绍聚类算法,这是我们学习的第一个非监督学习算法--学习无标签数据,而不 ...
- 论文解读SDCN《Structural Deep Clustering Network》
前言 主体思想:深度聚类需要考虑数据内在信息以及结构信息. 考虑自身信息采用 基础的 Autoencoder ,考虑结构信息采用 GCN. 1.介绍 在现实中,将结构信息集成到深度聚类中通常需要解决以 ...
- 论文解读(DFCN)《Deep Fusion Clustering Network》
Paper information Titile:Deep Fusion Clustering Network Authors:Wenxuan Tu, Sihang Zhou, Xinwang Liu ...
- 论文解读(CGC)《CGC: Contrastive Graph Clustering for Community Detection and Tracking》
论文信息 论文标题:CGC: Contrastive Graph Clustering for Community Detection and Tracking论文作者:Namyong Park, R ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
随机推荐
- pycharm 和 Anaconda 下的 opencv 安装
学习真的切忌三天打鱼两天晒网!! 一开始python下的opencv已经都弄好了,中间电脑坏了一次,好久没有接触这个,就全部都忘完了.深感惋惜. 今天又从新安装了一下opencv.在anaconda下 ...
- mysql数据库多源复制方案
概述 由于目前生产环境的mysql数据库分布在两台服务器,若从单一主从来看,配置很简单,但是需要将两台服务器的数据库同步到一台从库上面,需要进行更多配置和注意事项.多源复制有两种方案,Binlog+P ...
- 【css flex】将多个<div>放在同一行
使用style里的flex属性 默认情况下,一个div独占一行 使用css选择器给外层div加上以下flex属性,则该div的子div可以在同一行中显示, .runs-paginator-flex-c ...
- cocos2d动作
1.动作的基类是CCAction,通过继承它可以实现很多不同的动作,主要分为三大类: (1)CCFiniteTimeAction(有限次动作执行类) (2)CCSpeed(节点执行速度类) (3)CC ...
- [golang note] 工程组织
golang项目目录结构 <golang_proj> ├─README ├─AUTHORS ├─<bin> ...
- (2)Mac环境搭建
创建HelloWorld项目 将刚才下载的压缩包解压到你指定的文件夹里. 进入到目录cocos2d-x-3.2alpha0/tools/cocos2d-console/bin/cocos.py 打开终 ...
- onsubmit不起作用的原因
使用form表单,添加onsubmit="return check()",来实现提交前进行相关验证功能时,有时会出现js函数不起作用的情况, 此时可以检查相应的js函数check( ...
- uva1452
这题说的是给了一个序列1到n然后你从1 位置开始数k个删除,直到最后每个数都被删除了.我们考虑1个数在被删除前后的位置,比如现在在i位置那么 回到删除当前的最后一个是 (i+k)L 了为删除前 的 个 ...
- Tomcat环境变量设置
tomcat环境变量配置 CATALINA_HOME:D:\server\apache-tomcat-8.5.32 //安装目录 CATALINA_BASE:D:\server\ap ...
- springcloud6---Eureka的配置:
Eureka的配置: 自我保护:表示eureka进入了自我保护模式,eureka启动的时候会从高可用其他节点获取注册表信息,eureka client会每30秒发送心跳,如果eureka server ...